
目标检测算法-YOLOV8解析(附论文和源码)
目标检测算法-YOLOV8解析(附论文和源码)
本篇文章首发于微信公众号:人工智能与图像处理
目标检测算法-YOLOV8解析(附论文和源码)
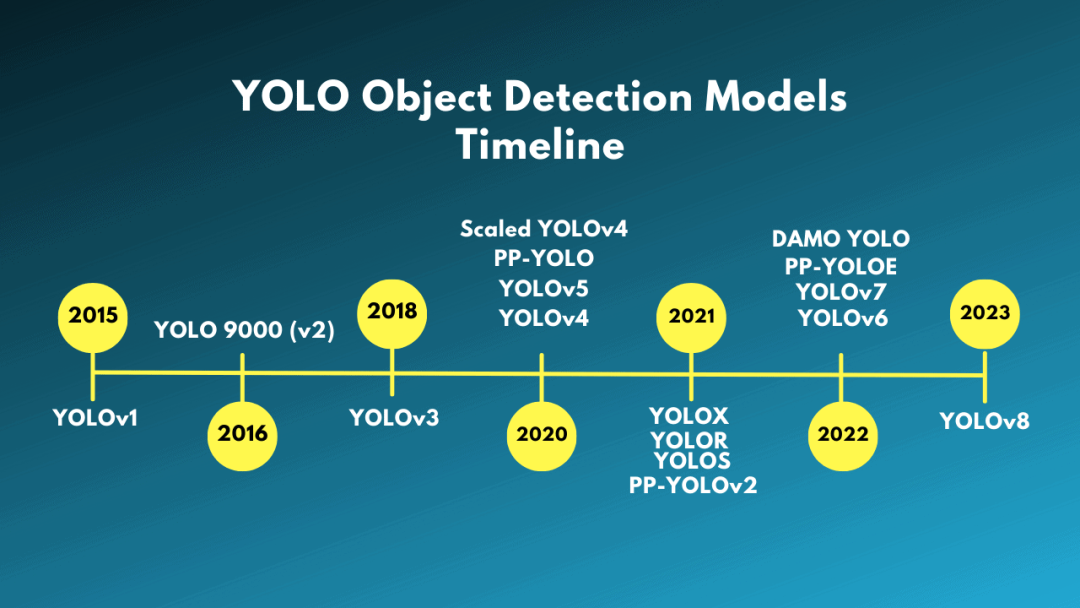
YOLO 目标检测模型的时间线
一,YOLOV8
1, YOLOv8 概述
YOLOv8 是ultralytics公司在 2023 年 1月 10 号开源的,是 YOLOv5 的下一个重大更新版本,目前支持图像分类、物体检测和实例分割任务,在还没有开源时就收到了用户的广泛关注。它是一个 SOTA 模型,建立在以前 YOLO 版本的成功基础上,并引入了新的功能和改进,以进一步提升性能和灵活性。具体创新包括一个新的骨干网络、一个新的 Ancher-Free 检测头和一个新的损失函数,可以在从 CPU 到 GPU 的各种硬件平台上运行。
ultralytics 并没有直接将开源库命名为 YOLOv8,而是直接使用 ultralytics 这个词,原因是 ultralytics 将这个库定位为算法框架,而非某一个特定算法,一个主要特点是可扩展性。其希望这个库不仅仅能够用于 YOLO 系列模型,而是能够支持非 YOLO 模型以及分类分割姿态估计等各类任务。
2, YOLOv8与其他检测模型性能比较
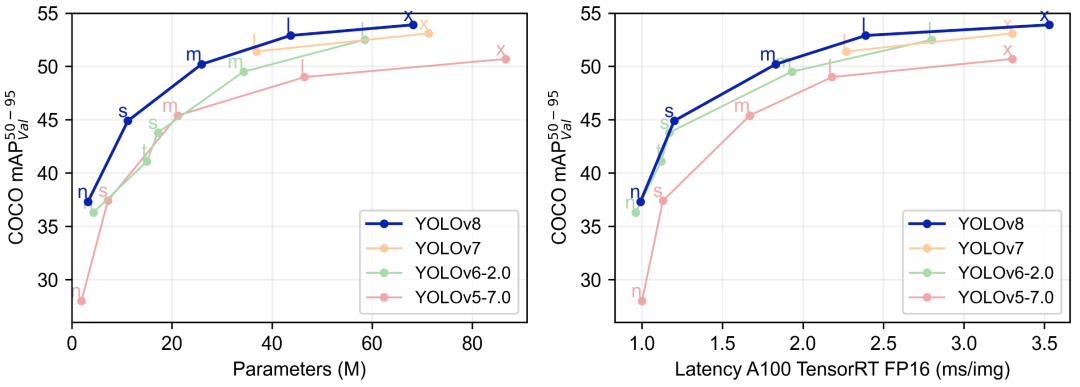
YOLOv8 与其他 YOLO 模型的对比
上图显示,与以640图像分辨率训练的其他 YOLO 模型相比,所有 YOLOv8 模型在参数数量相似的情况下都具有更好的吞吐量。
下表为官方在 COCO Val 2017 数据集上测试的 mAP、参数量和 FLOPs 结果。可以看出 YOLOv8 相比 YOLOv5 精度提升非常多,但是 N/S/M 模型相应的参数量和 FLOPs 都增加了不少,从上图也可以看出相比 YOLOV5 大部分模型推理速度变慢了。(FLOPs:floating point operations 指的是浮点运算次数,理解为计算量,可以用来衡量算法/模型的复杂度。FLOPS(全部大写)指的是每秒运算的浮点数,理解为计算速度,衡量一个硬件的标准。我们要的是衡量模型的复杂度的指标,所以选择FLOPs。)
| 模型 | YOLOv5 | params(M) |
FLOPs@640 (B) |
YOLOv8 | params(M) |
FLOPs @640 (B) |
| n | 28.0(300e) | 1.9 | 4.5 | 37.3 (500e) | 3.2 | 8.7 |
| s | 37.4 (300e) | 7.2 | 16.5 | 44.9 (500e) | 11.2 | 28.6 |
| m | 45.4 (300e) | 21.2 | 49.0 | 50.2 (500e) | 25.9 | 78.9 |
| l | 49.0 (300e) | 46.5 | 109.1 | 52.9 (500e) | 43.7 | 165.2 |
| x | 50.7 (300e) | 86.7 | 205.7 | 53.9 (500e) | 68.2 | 257.8 |
整体比较

YOLOv8 模型与 YOLOv5 模型整体对比
物体检测比较
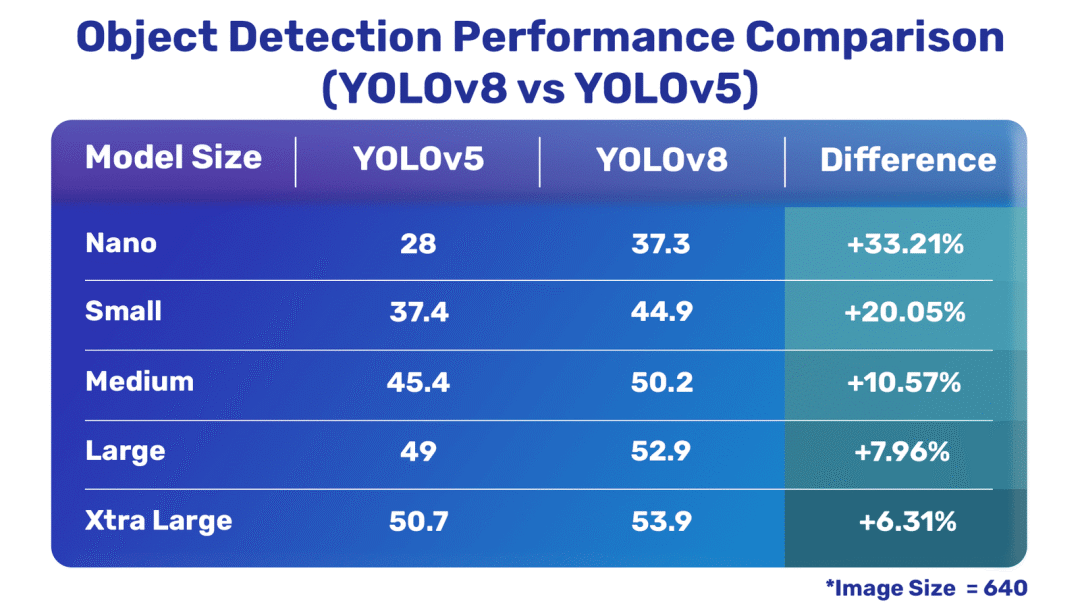
YOLOv8 与 YOLOv5 对象检测模型
实例分割比较
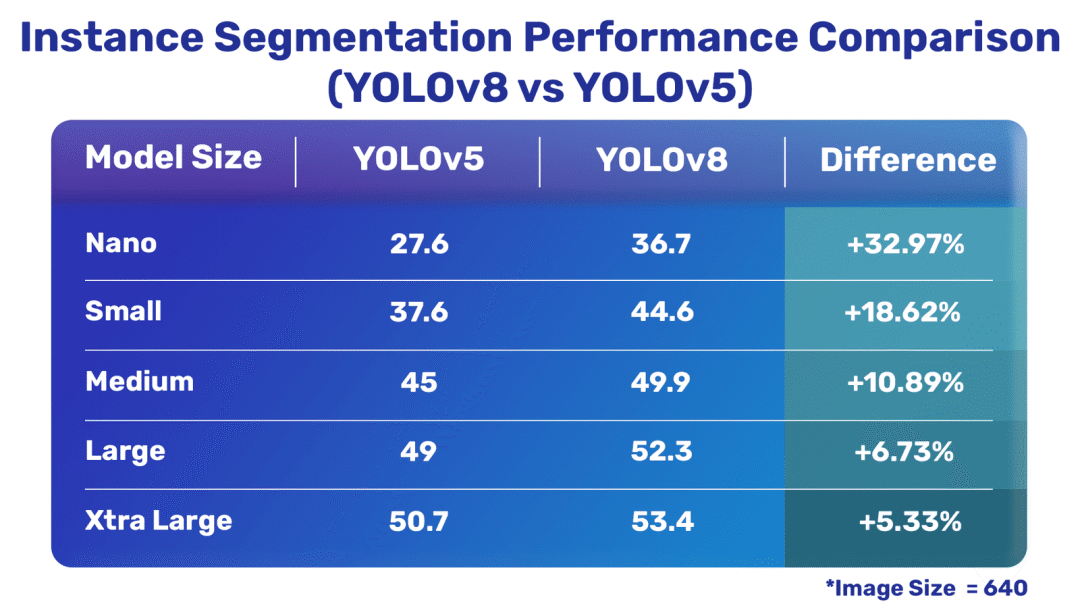
YOLOv8 与 YOLOv5 实例分割模型
图像分类比较
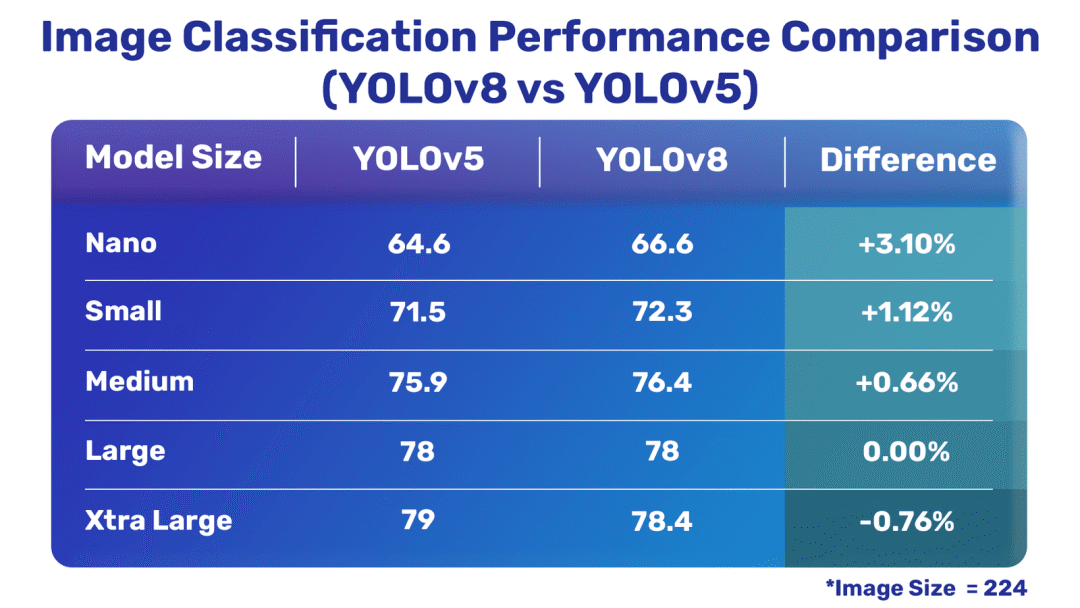
YOLOv8 与 YOLOv5 图像分类模型
通过上述数据,可以很明显的得出结论:除了其中一个分类模型外,最新的 YOLOv8 模型与 YOLOv5 相比要好得多。
3,创新点
yolov8具体改进如下:
-
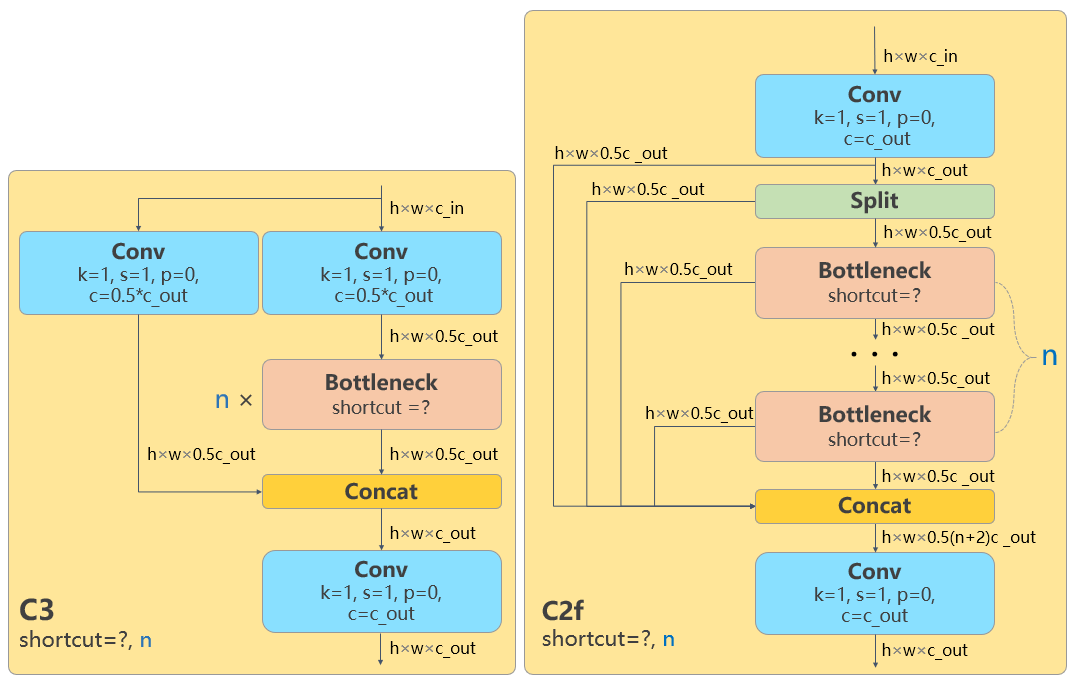
Backbone:使用的依旧是CSP的思想,不过YOLOv5中的C3模块被替换成了C2f模块,实现了进一步的轻量化,同时YOLOv8依旧使用了YOLOv5等架构中使用的SPPF模块;
-
PAN-FPN:YOLOv8依旧使用了PAN的思想,不过通过对比YOLOv5与YOLOv8的结构图可以看到,YOLOv8将YOLOv5中PAN-FPN上采样阶段中的CBS 1*1的卷积结构删除了,同时也将C3模块替换为了C2f模块;
-
Decoupled-Head:YOLOv8使用了Decoupled-Head;即通过两个头分别输出cls与reg的输出;
-
Anchor-Free:YOLOv8抛弃了以往的Anchor-Base,使用了Anchor-Free的思想;
-
Loss:YOLOv8使用VFL Loss作为分类损失(实际训练中并未使用),使用DFL Loss+CIOU Loss作为分类损失;
-
label assignmet:YOLOv8抛弃了以往的IOU匹配或者单边比例的分配方式,而是使用了Task-Aligned Assigner匹配方式。
4,模型结构设计

YOLOv8 官方代码所绘制的模型结构图
通过对比 YOLOv5 和 YOLOv8 的 yaml 配置文件可以发现,YOLOv8 的改动较小(不考虑 Head 情况下)。
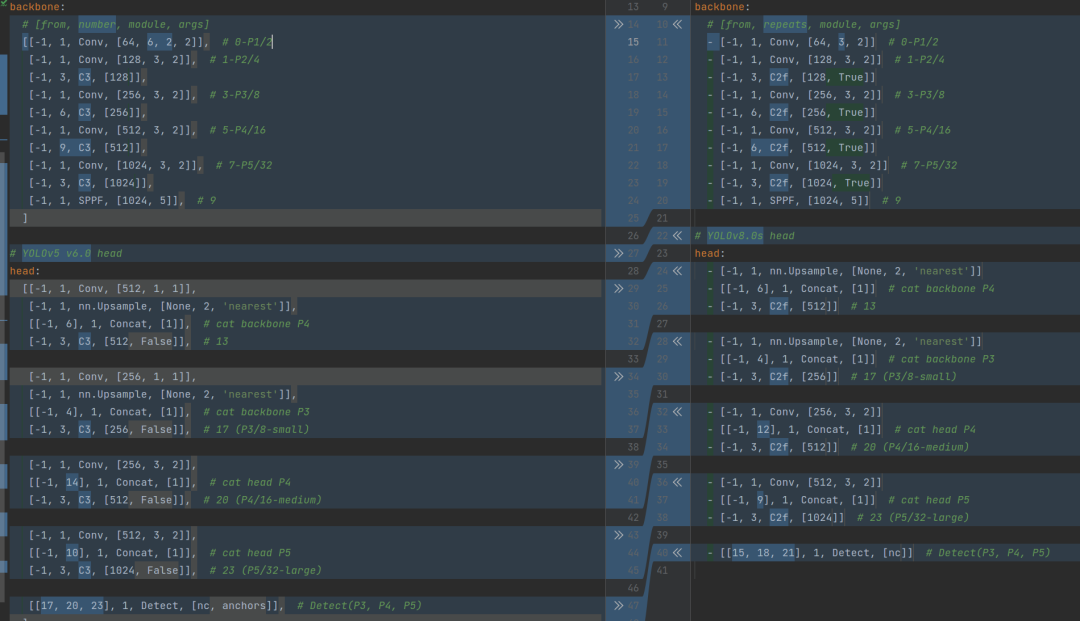
上图 分别为YOLOv5-s(左)与YOLOv8-s(右)
backbone和neck 的改动为:
-
将所有的 C3 模块换成了C2f(具体结构如下图所示,可以可以发现,新结构里多了更多的跳层连接以及额外的 Split 操作);
-
将第一层卷积的 kernel 改为 3x3,原来是6x6;
-
查看 N/S/M/L/X 等不同大小模型,可以发现 N/S 和 L/X 两组模型只是改了缩放系数,但是 S/M/L 等骨干网络的通道数设置不一样,没有遵循同一套缩放系数。如此设计的原因应该是同一套缩放系数下的通道设置不是最优设计,YOLOv7 网络设计时也没有遵循一套缩放系数作用于所有模型;
-
Backbone 中 C2f 的block 数从 3-6-9-3 改成了 3-6-6-3
-
去掉了 Neck 模块中的 2 个卷积连接层;
Head 部分的变化最大,原来是耦合头,现在变成了解耦头,YOLOv5是基于Anchor-Based的,YOLOV8变成了 Anchor-Free。YOLOV8的head结构如下图所示:
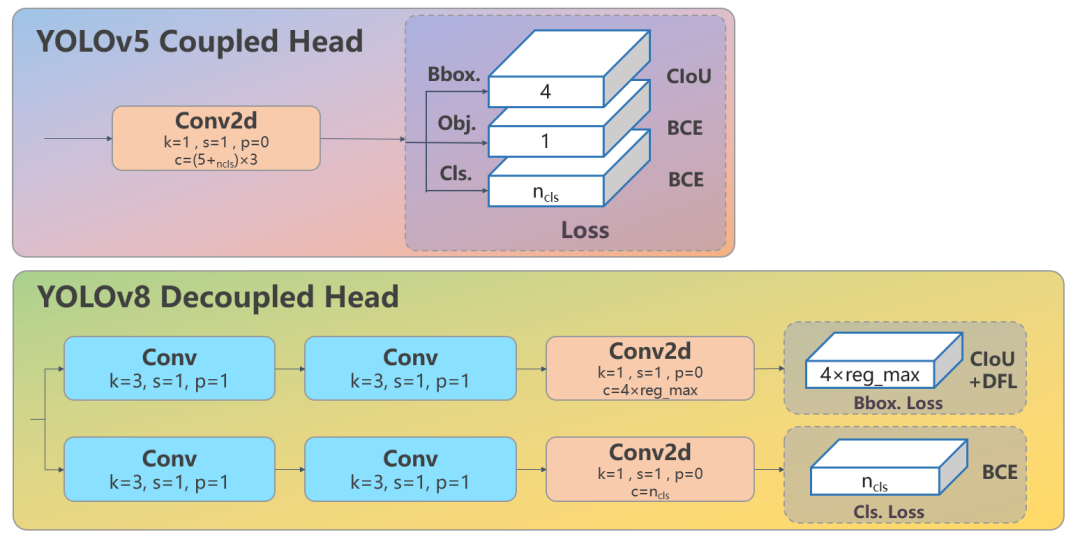
从上图可以看出,YOLOV8里去掉了objectness 分支,同时也将分类和回归分支进行了解耦,其中的回归分支改用了Distribution Focal Loss 中提出的积分形式的表示法。
5,Loss 计算
Loss 计算过程包括 2 个部分: 正负样本分配策略和 Loss 计算。
现代目标检测器大部分都会在正负样本分配策略上面做文章,典型的如 YOLOX 中的simOTA、TOOD的TaskAlignedAssigner以及RTMDet的 DynamicSoftLabelAssigner,这类 Assigner 大都是动态分配策略,而 YOLOv5 采用的依然是静态分配策略。考虑到动态分配策略的优异性,YOLOv8 算法中则直接引用了 TOOD 的 TaskAlignedAssigner。
TaskAlignedAssigner 的匹配策略简单总结为:根据分类与回归的分数加权的分数选择正样本。
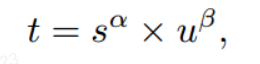
s 是标注类别对应的预测分值,u 是预测框和 gt 框的 iou,两者相乘就可以衡量对齐程度。
对于每一个 GT,对所有的预测框基于 GT 类别对应分类分数,预测框与 GT 的 IoU 的加权得到一个关联分类以及回归的对齐分数 alignment_metrics,对于每一个 GT,直接基于 alignment_metrics 对齐分数选取 topK 大的作为正样本。
Loss 计算包括 2 个分支:分类和回归分支,没有了之前的 objectness 分支,3 个 Loss 采用一定权重比例加权即可。
-
分类分支依然采用 BCE Loss;
-
回归分支需要和 Distribution Focal Loss 中提出的积分形式表示法绑定,因此使用了 Distribution Focal Loss, 同时还使用了 CIoU Loss;
6,训练数据增强
数据增强方面和 YOLOv5 差距不是很大,只不过引入了 YOLOX 中提出的最后 10 个 epoch 关闭 Mosaic 的操作。假设训练 epoch 是 500,训练示意图如下图所示:
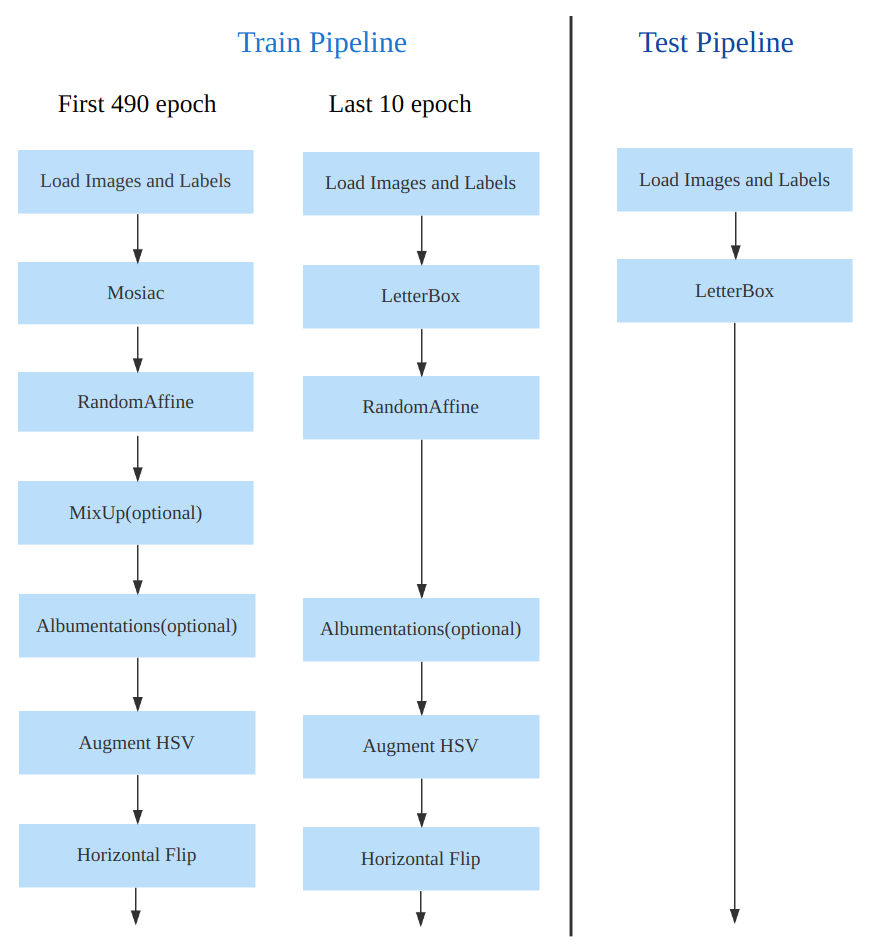
考虑到不同模型应该采用的数据增强强度不一样,因此对于不同大小模型,有部分超参会进行修改,典型的如大模型会开启 MixUp 和 CopyPaste。数据增强后典型效果如下所示:

7,训练策略
YOLOv8 的训练策略和 YOLOv5 没啥区别,最大区别就是模型的训练总 epoch 数从 300 提升到了 500,不过这也导致训练时间急剧增加。以 YOLOv8-S 为例,其训练策略汇总如下:
| 配置 | YOLOv8-s P5 参数 |
| optimizer | SGD |
| base learning rate | 0.01 |
| Base weight decay | 0.0005 |
| optimizer momentum | 0.937 |
| batch size | 128 |
| learning rate schedule | 128 |
| training epochs | 500 |
| warmup iterations | max(1000,3 * iters_per_epochs) |
| input size | 640x640 |
| EMA decay | 0.9999 |
8,模型推理过程
YOLOv8 的推理过程和 YOLOv5 几乎一样,唯一差别在于前面需要对 Distribution Focal Loss 中的积分表示 bbox 形式进行解码,变成常规的 4 维度 bbox,后续计算过程就和 YOLOv5 一样了。
其推理和后处理过程为:
-
bbox 积分形式转换为 4d bbox 格式,对 Head 输出的 bbox 分支进行转换,利用 Softmax 和 Conv 计算将积分形式转换为 4 维 bbox 格式;
-
维度变换,YOLOv8 输出特征图尺度为 80x80、40x40 和 20x20 的三个特征图。Head 部分输出分类和回归共 6 个尺度的特征图。将 3 个不同尺度的类别预测分支、bbox 预测分支进行拼接,并进行维度变换。为了后续方便处理,会将原先的通道维度置换到最后,类别预测分支 和 bbox 预测分支 shape 分别为 (b, 80x80+40x40+20x20, 80)=(b,8400,80),(b,8400,4)。
-
解码还原到原图尺度,分类预测分支进行 Sigmoid 计算,而 bbox 预测分支需要进行解码,还原为真实的原图解码后 xyxy 格式。
-
阈值过滤,遍历 batch 中的每张图,采用 score_thr 进行阈值过滤。在这过程中还需要考虑 multi_label 和 nms_pre,确保过滤后的检测框数目不会多于 nms_pre。
-
还原到原图尺度和 nms,基于前处理过程,将剩下的检测框还原到网络输出前的原图尺度,然后进行 nms 即可。最终输出的检测框不能多于 max_per_img。
9,特征图可视化
可视化 backbone 输出的 3 个特征图效果

从上图可以看出不同输出特征图层主要负责预测不同尺度的物体。
可视化 Neck 层的 3 个输出层特征图

从上图可以发现物体处的特征更加聚焦。
YOLOv8x 检测和实例分割模型的输出。

10,总结
简单来说 YOLOv8 是一个包括了图像分类、Anchor-Free 物体检测和实例分割的高效算法,检测部分设计参考了目前大量优异的最新的 YOLO 改进算法,实现了新的 SOTA。不仅如此还推出了一个全新的框架。不过这个框架还处于早期阶段,还需要不断完善。
二,相关地址:
论文地址:
代码地址:https://github.com/ultralytics/ultralytics
权重地址:https://github.com/ultralytics/assets/releases
文档地址:https://docs.ultralytics.com/
三,参考文章:
https://www.zhihu.com/search?type=content&q=YOLOv8
https://zhuanlan.zhihu.com/p/598656212
https://blog.csdn.net/qq_39967751/article/details/128665294
https://zhuanlan.zhihu.com/p/147691786
https://xiaobaibubai.blog.csdn.net/article/details/128875476?spm=1001.2101.3001.6650.1&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1-128875476-blog-129584303.235%5Ev36%5Epc_relevant_default_base&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1-128875476-blog-129584303.235%5Ev36%5Epc_relevant_default_base&utm_relevant_index=2
更多推荐


 18
18 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)