
使用Kettle做数据迁移
Kettle是一个颇受认可的开源ETL(Extract-Transform-Load 的缩写,即数据抽取、转换、装载的过程)工具
1.Kettle简介
Kettle是一个颇受认可的开源ETL(Extract-Transform-Load 的缩写,即数据抽取、转换、装载的过程)工具,2006年被Pentaho收购,2015年又被Hitachi Vantara收购,正式命名为PDI。 PDI EE(企业商用版)改进了PDI CE(开源社区版)在作业调度监控、系统安全机制、高可用性架构、对接SAP、对接Hadoop、对接AI/ML、 自助式DI/BI等方面之不足,尤其是凭借着原厂兜底的专业技术支持服务保障,获得企业客户广泛青睐。
Kettle使用纯Java编写,可以在Window、Linux、Unix上运行,无需安装。Kettle 中文名称叫水壶,该项目的主程序员MATT 希望把各种数据放到一个壶里,然后以一种指定的格式流出。Kettle这个ETL工具集,它允许用户管理来自不同存储方式的数据,通过提供一个图形化的管理工具来设计转换过程。Kettle中有两种脚本文件,transformation(转换)和job(作业),transformation完成针对数据的基础转换,job则完成整个工作流的控制。
源码地址:GitHub - pentaho/pentaho-kettle: Pentaho Data Integration ( ETL ) a.k.a Kettle
2.Kettle的核心组件
2.1.主要工具介绍
- Spoon:启动GUI的编辑工具,用来设计转换和作业。
- Pan:命令行工具,用于执行转换。
- Kitchen:用于执行作业的命令行工具。Pan的参数与Kitchen基本一致。
- Carte:启用一个轻量级的Web容器,用于建立专用、远程的ETL Server。
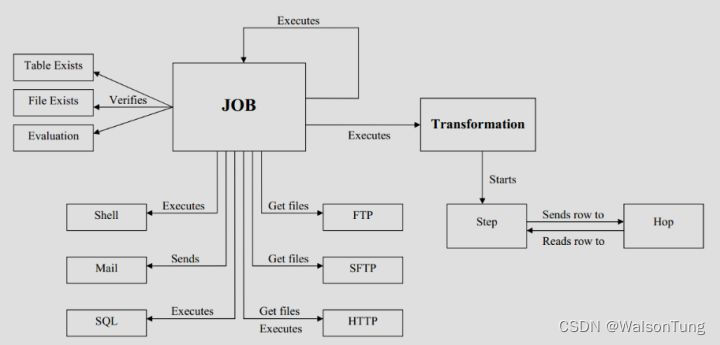
2.2.概念模型
Kettle 的执行分为两个层次:Job(作业,.kjb 后缀)和 Transformation(转换,.ktr 后缀)。转换是执行任务的最小单位,包括各种数据结构及存储方式的转换,可以通过Pan命令单独执行。若一个转换中包含多个数据转换,则并发执行这些数据转换,所以转换是数据流,关注数据来源和转换结果及目的地。作业完成转换之外的其他工作,可以集成多个转换和作业,一般以Start节点开始,以Success结束。作业专注的是操作流程,是按指定顺序支持的。
3.部署
从官网下载官方程序包pdi-ce-9.4.0.0-343.zip,此包为压缩包,非安装包,所以解压即可使用。配置jdk环境变量和数据库连接库。
3.1. 配置jdk环境变量
查看官方文档或压缩包内的README.txt文件,确定jdk版本,最新版要求至少jdk11。我使用的版本是9.1版,仅支持jdk8。
用文本编辑器打开文件set-pentaho-env.bat文件,会发现主要设置三个关于jdk的环境变量,PENTAHO_JAVA_HOME和JAVA_HOME为jdk安装根目录,PENTAHO_JAVA为java.exe所在目录。
3.2. 数据库连接包
我需要前移的数据存储在mysql数据库中,所以需要从官网下载mysql 的数据库连接库mysql-connector-j-8.0.31.jar,并复制到目录data-integration\lib下。退回到目录data-integration下,双击Spoon.bat即可开始编辑数据转换流程。
4.Spoon
双击Spoon.bat即可开始编辑数据转换流程。
4.1.转换Transformation
点击菜单“文件”-“新建”-“转换”,新建转换文件。Spoon内容区会显示“转换”设计区,并提醒通过拖拽来设计数据转换。左边菜单栏是可选择对象,包含:主对象树、核心对象。如下图:
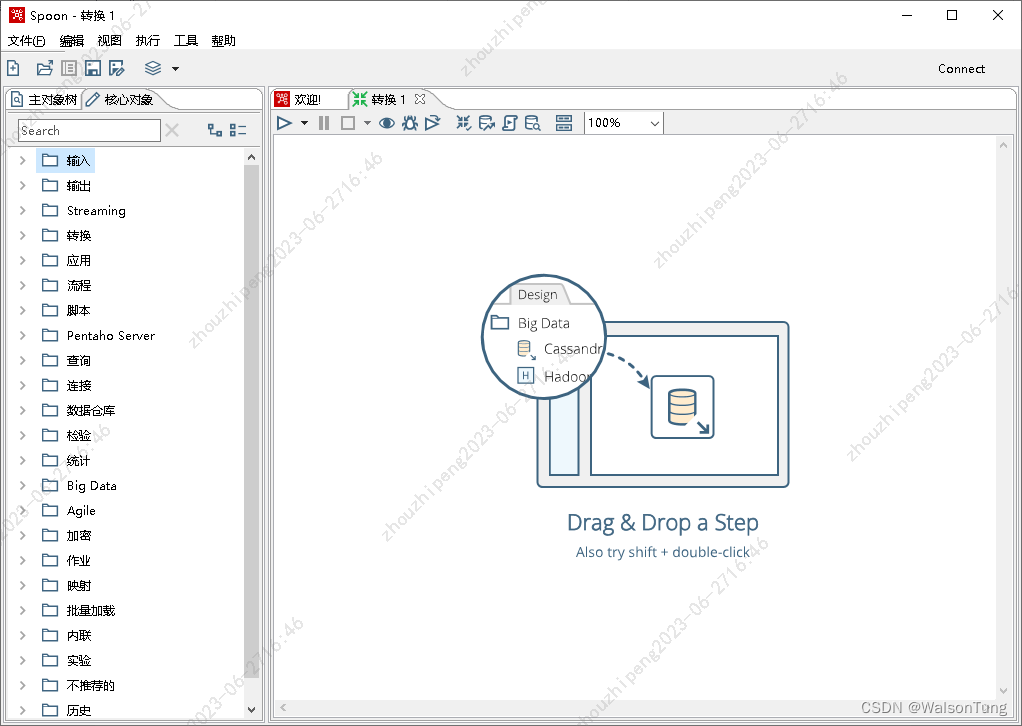
4.1.1.核心对象
核心对象就是可以拖拽到设计区的对象,其中输入表示数据来源,包括数据库、各种数据文件等;输出表示要数据最终要存入的目的地,类型与输入相似,只是在操作方式上不同。输入是指获取数据的方式及数据格式,而输出指输出的方式及存储格式。
作业代表执行作业类型的节点,包括获取数据和存储数据。
若需要在执行数据转换时设置参数,可以通过命令行传入参数,也可以从文件中读取参数值。若从文件中读取参数值,就需要通过输入中的文件输入获取数据,并把数据传入到来自作业对象中设置参数节点来设置参数。如图:
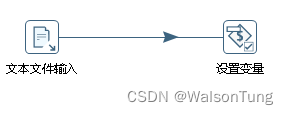
数据转换就是拖拽一个输入节点,再拖拽一个输出节点,然后点击输入节点,拉出一个箭头指向输出节点。并设置读取节点的设置和输出节点的设置。
在工作中经常遇到把数据从数据库中迁移到另一个数据库中,或者通过csv文件的进行中转跨网传输。
表输出就是从指定数据库中提取数据,需要选择数据库连接,并通过SQL来从数据表中获取数据。SQL中支持参数,以${param}的形式获取参数。注意:若SQL中包含参数变量,必须勾选“替换SQL语句里的变量”
csv文件输入需要选择文件,支持相对地址,设置解析文件方式:包括:字段分隔符、行分隔符、标题行以及字段名、字段类型、字段长度等。读取出来的应该是结构化的数据。
数据库输入包括五种:删除、插入/更新、同步、更新、表输入。用途根据名称可以判断。其中删除指仅根据指定字段的值删除数据;插入/更新是根据指定字段的值插入或更新数据,不存在则插入,存在则更新;同步时指根据指定字段的值删除、插入或更新数据,三种操作可以分别指定字段;更新仅根据指定字段值更新已有数据;表输入表示插入所有传递过来的值。
输入中没有单独的csv输入,可通过文本输入来实现。修改文件扩展名为csv,设置字段分隔符和行分隔符,以及头尾。另外,对于输出的字符串,强烈建议设置封装符号为双引号,这样不会使字符串中的符号与字段分隔符混淆。
4.1.2.主对象树
主对象树是对转换图的一种树状描述,包括节点、节点连接、数据库等。
可以点击DB连接,弹出新建数据库的选项。点击新建打开新建数据库连接对话框。选择数据库类型、设置连接名称、主机名称、数据库名称、用户名、密码等创建连接,并通过点击测试按钮来测试是否可以连接成功。可以添加多个数据库连接,设置好后可以在对象节点使用。
右键点击转换名称,弹出菜单,点击设置菜单,弹出设置转换属性的对话框。页签“命名参数”是用来传递参数的。若需要通过命令行参数的形式传递参数,需要设置命名参数;若通过从文件中读取参数值,则不需要设置。
4.1.3.执行转换的命令
Pan命令文件负责执行转换操作。命令格式如下:
# Linux 命令
sh pan.sh -rep=initech_pdi_repo -user=pgibbons -pass=lumburghsux -trans=TPS_reports_2011
# Windows 命令,注意:Windows 传递参数需要用双引号包裹参数,多个参数需要使用多个"/param:name=value"来传递。
pan.bat /rep:initech_pdi_repo /user:pgibbons /pass:lumburghsux /trans:TPS_reports_2011 "/param:startTime=2023-07-01"Pan命令参数含义请参考官方文档。
4.2.作业Job
如果说转换是做具体数据转换工作的,那么作业就是组织者和协助者,以完成更复杂的工作。
4.2.1.作业设计页面
同转换一样,通过点击菜单:文件-新建-作业 创建作业设计页面,页面左边工具栏同样包括主对象树和核心对象。通过拖拽核心对象到作业设计区来设计作业的操作流程。核心对象包括通用、邮件、文件管理、条件、脚本、文件传输、文件加密等。主对象树与转换一样是以树形结构展现作业流程。
一个完整的作业一般开始节点和成功节点。作业中可以嵌套多个转换和作业。可以像设计流程图一样进行设计。
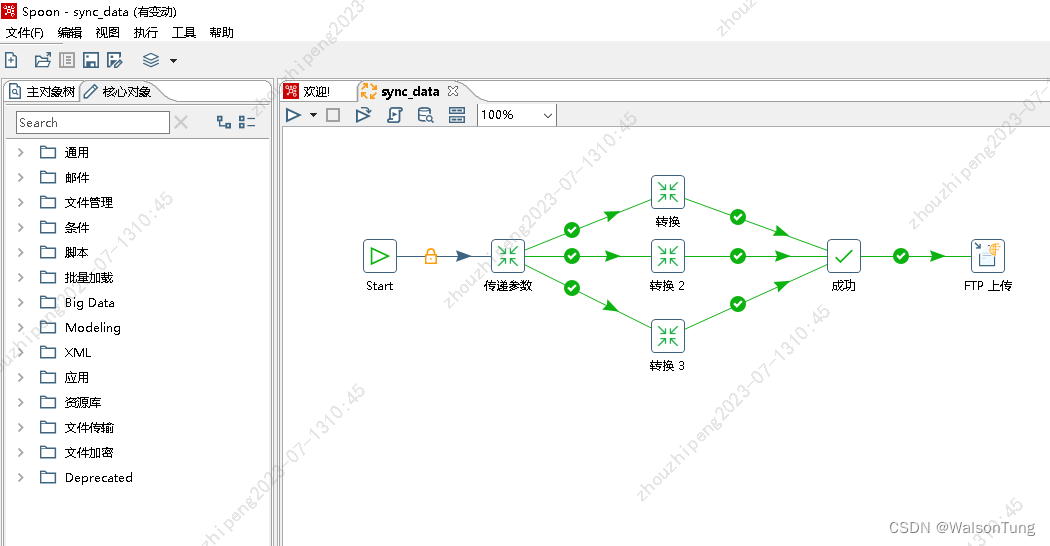
若出现流程分支,分支是并行执行的。且当每个分支执行完毕后,才走向归结点成功,如上图所示。转换成功后,依次上传文件到FTP服务器。
4.2.2.作业执行命令
作业命令工具为Kitchen,命令格式如下:
# Linux命令
sh kitchen.sh -rep=initech_pdi_repo -user=pgibbons -pass=lumburghsux -job=TPS_reports_2011
# Windows命令,同Pan命令一样,传递参数需要使用双引号包裹,多个参数需要分别传递。
kitchen.bat /rep:initech_pdi_repo /user:pgibbons /pass:lumburghsux /job:TPS_reports_2011Kitchen命令参数含义请参考官方文档。
5.参考:
更多推荐



 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)