

HNU-操作系统OS-作业1(4-9章)
4.1用以下标志运行程序:./process-run.py -l 5:100,5:100。CPU 利用率(CPU 使用时间的百分比)应该是多少?为什么你知道这一点?利用 -c 标记查看你的答案是否正确。4.2现在用这些标志运行: ./process-run.py -l 4:100,1:0 这些标志指定了一个包含 4 条指令的进程(都要使用 CPU),并且只是简单地发出 IO 并等待它完成。完成这两
这份文件是OS_homework_1 by计科2102 wolf 202108010XXX
文档设置了目录,可以通过目录快速跳转至答案部分。
第四章
4.1用以下标志运行程序:./process-run.py -l 5:100,5:100。CPU 利用率(CPU 使用时间的百分比)应该是多少?为什么你知道这一点?利用 -c 标记查看你的答案是否正确。
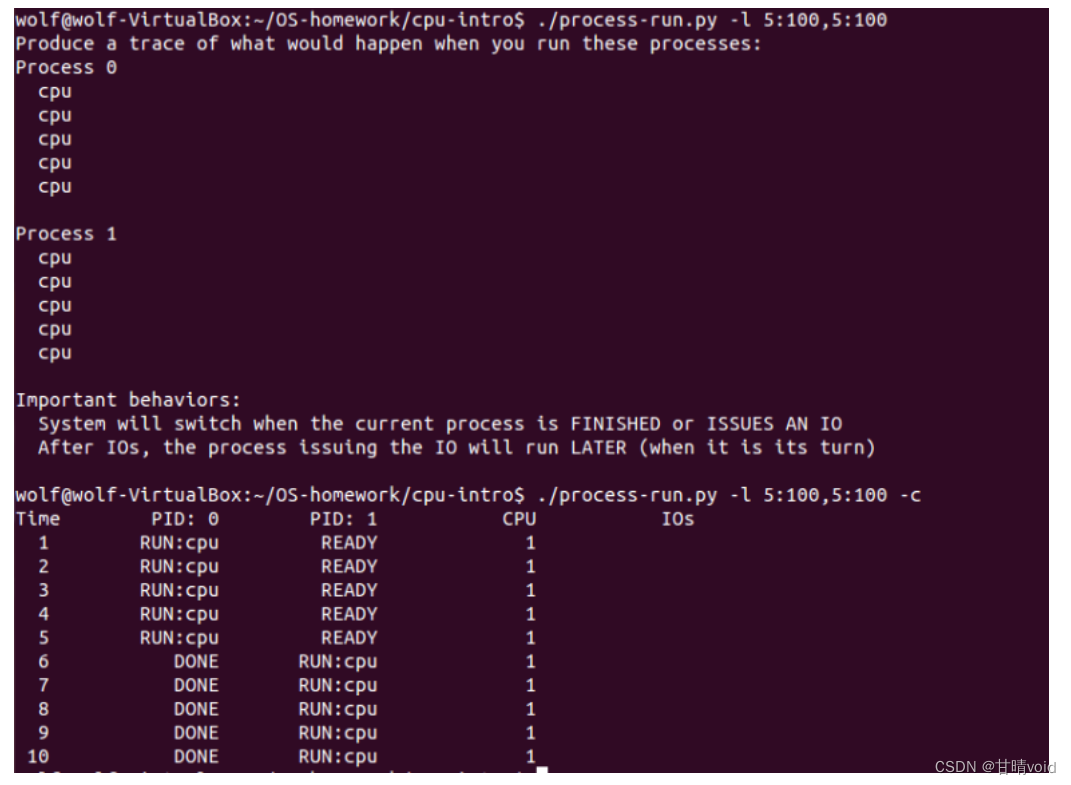
两进程都只使用cpu。每一时刻都使用到cpu,故cpu利用率为100%。
使用-c查看发现符合预期
4.2现在用这些标志运行: ./process-run.py -l 4:100,1:0 这些标志指定了一个包含 4 条指令的进程(都要使用 CPU),并且只是简单地发出 IO 并等待它完成。完成这两个进程需要多长时间?利用 c 检查你的答案是否正确。
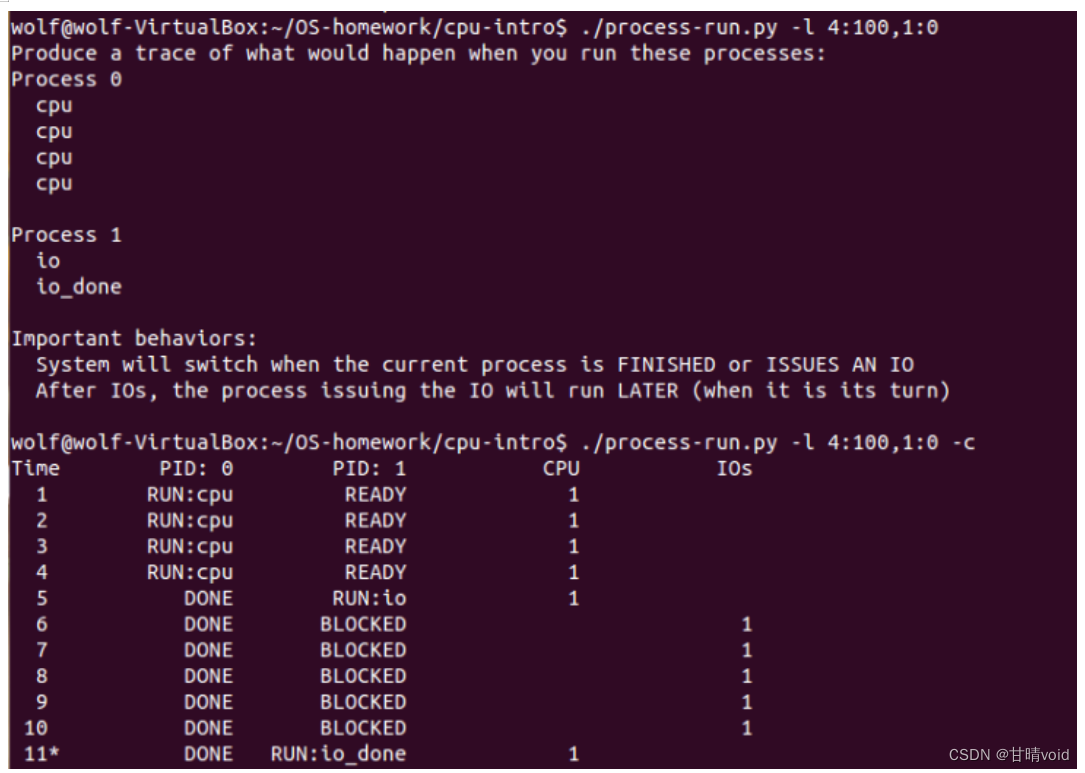
进程完成需要的时间与I/O等待完成需要的时间有关。若设这个时间为t0,则两个进程需要的时间t=4+t0+2。(表中假设t0为5个单位时间,两进程所需时间为11)
4.3现在交换进程的顺序: ./process-run.py -l 1:0,4:100 现在发生了什么?交换顺序是否重要?为什么?同样,用 -c 看看你的答案是否正确。
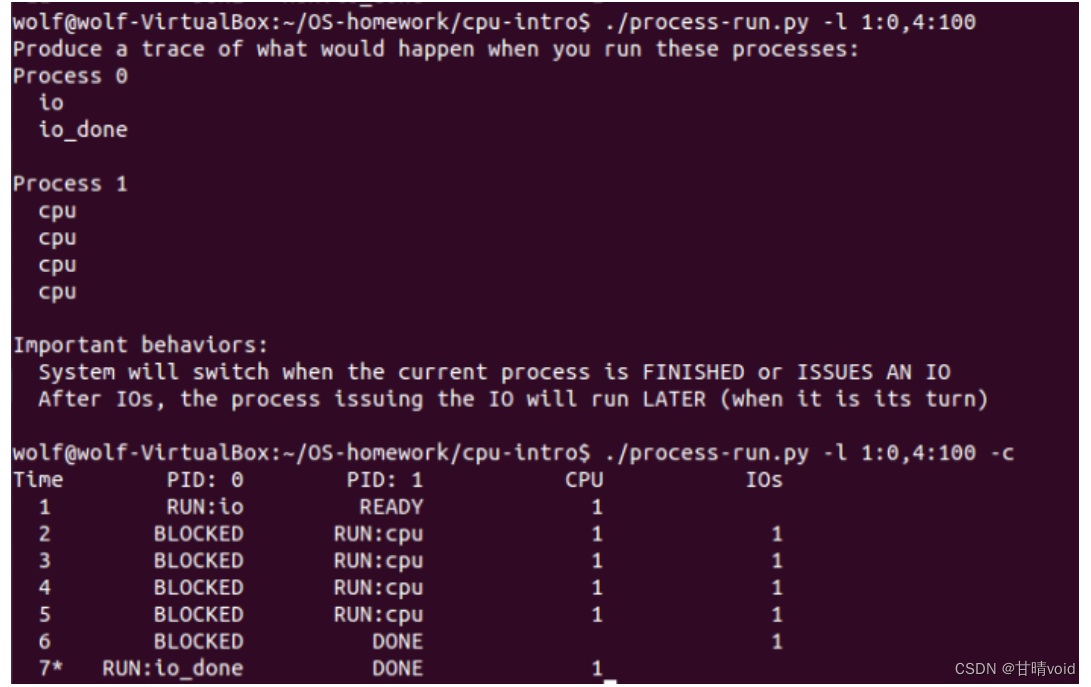
两个进程与第二题一致,只是把顺序交换了一下。但是可以看到,由于进程1的I/O使其进入阻塞状态,进程2补齐了这个空闲的时间,而导致总体的时间缩短了。
由此可见,合理地交换顺序十分重要,这样可以大大提高cpu利用率和效率。
使用-c可以发现答案正确。
4.4现在探索另一些标志。一个重要的标志是 -S,它决定了当进程发出 IO 时系统如何反应。将标志设置为 SWITCH_ON_END,在进程进行 I/O 操作时,系统将不会切换到另一个进程,而是等待进程完成。当你运行以下两个进程时,会发生什么情况?一个执行 I/O,另一个执行 CPU 工作。(-l 1:0,4:100 -c -S SWITCH_ON_END)
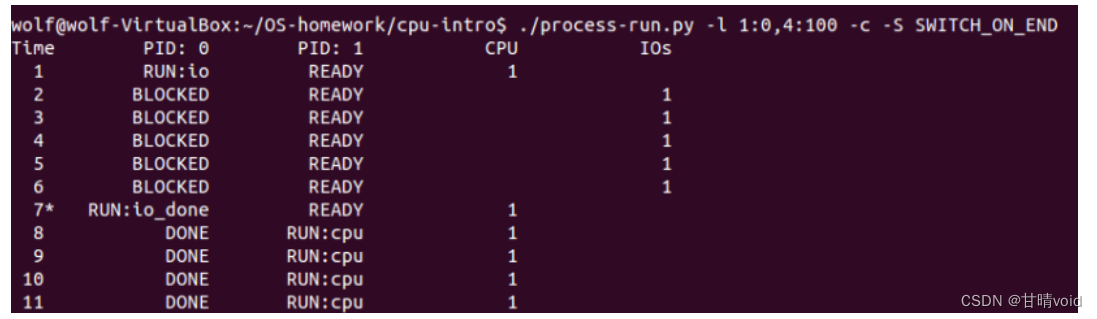
使用标记阻止切换。这种情况下系统将停止并等待I/O操作结束,再进行下一个进程。这种方式的时间与第二题的时间相同,cpu利用率很低。
4.5现在,运行相同的进程,但切换行为设置,在等待 IO 时切换到另一个进程(-l 1:0,4:100 c-S- SWITCH_ON_IO)现在会发生什么?利用 -c 来确认你的答案是否正确。

使用标记允许进行I/O操作时切换。这种情况下系统在进入I/O操作时将切换执行别的进程,以最大限度利用cpu。这种方式与第三题的时间相同,cpu利用率较高。
第五章
5.1编写一个调用 fork()的程序。在调用之前,让主进程访问一个变量(例如 x)并将其值设置为某个值(例如 100)。子进程中的变量有什么值?当子进程和父进程都改变 x 的值时,变量会发生什么?
在主进程中访问变量x并设为100,子进程中变量x保持不变为100。
(这里对父进程sleep是为了防止命令行提示符混杂在结果中)
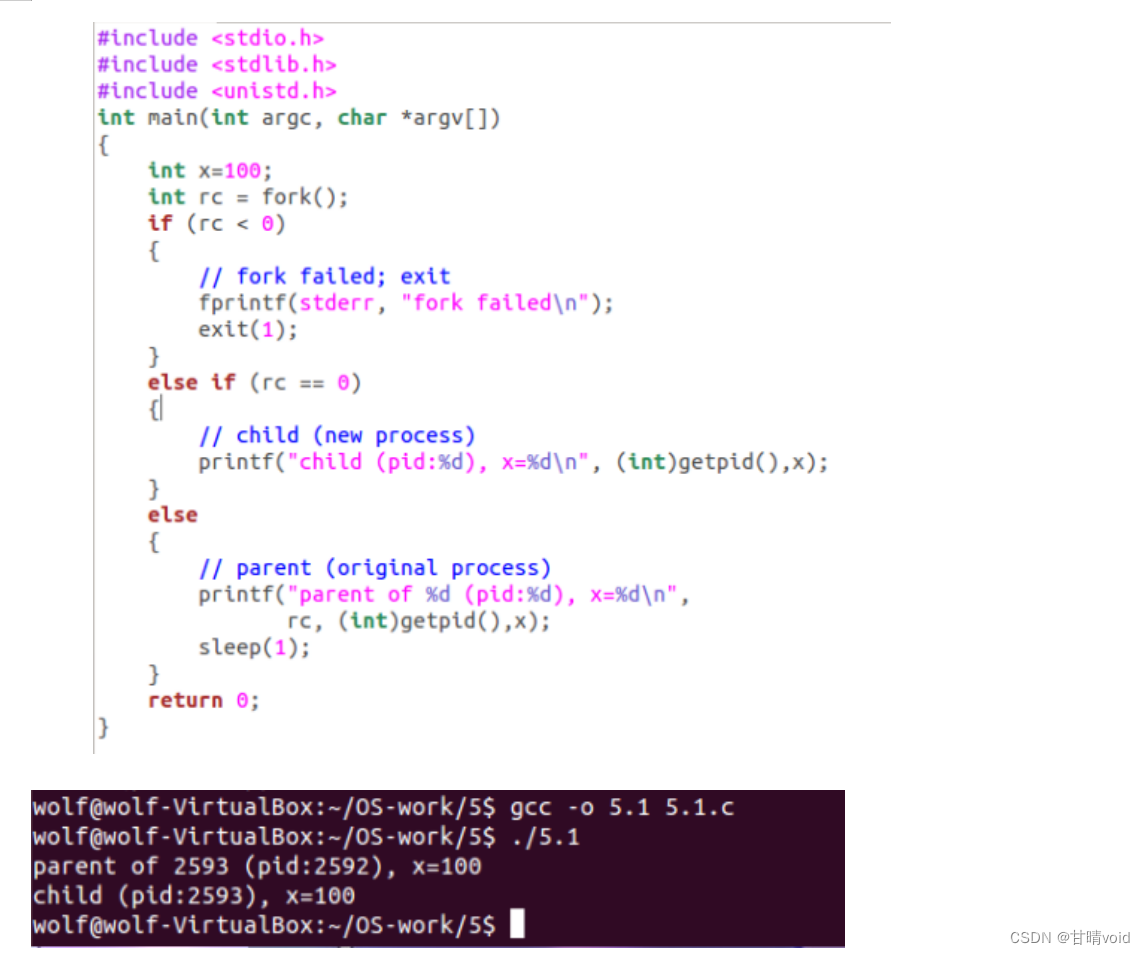
当子进程和父进程都改变x的值时,变量互不影响,各自改变。
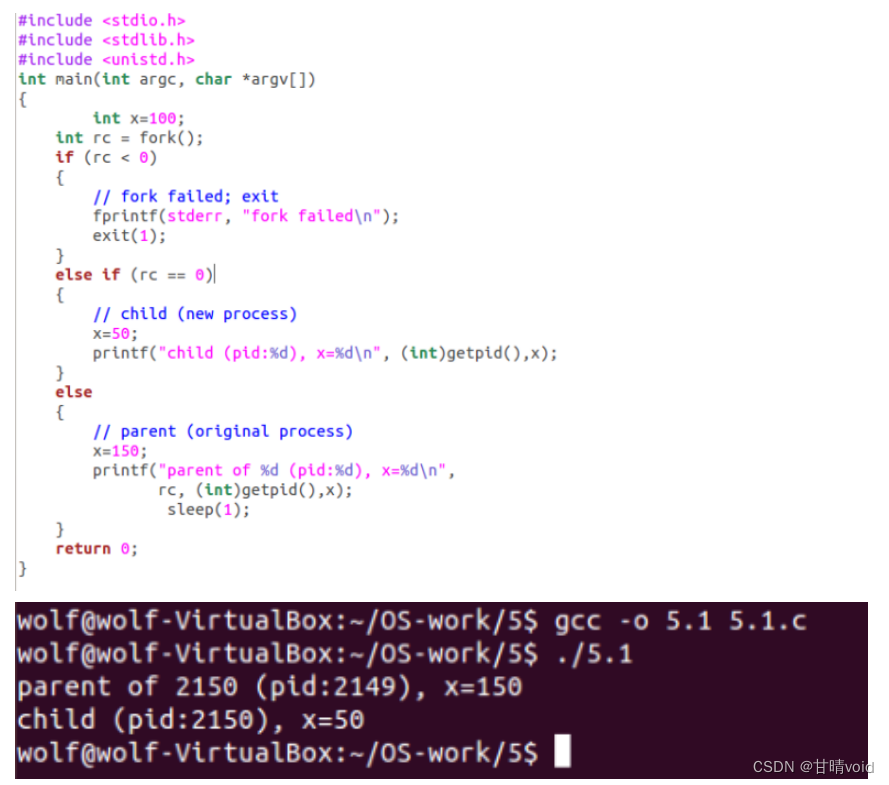
5.2编写一个打开文件的程序(使用 open 系统调用),然后调用 fork 创建一个新进程。子进程和父进程都可以访问 open()返回的文件描述符吗?当它们并发(即同时)写入文件时,会发生什么?
使用如下c代码打开文件并执行操作。
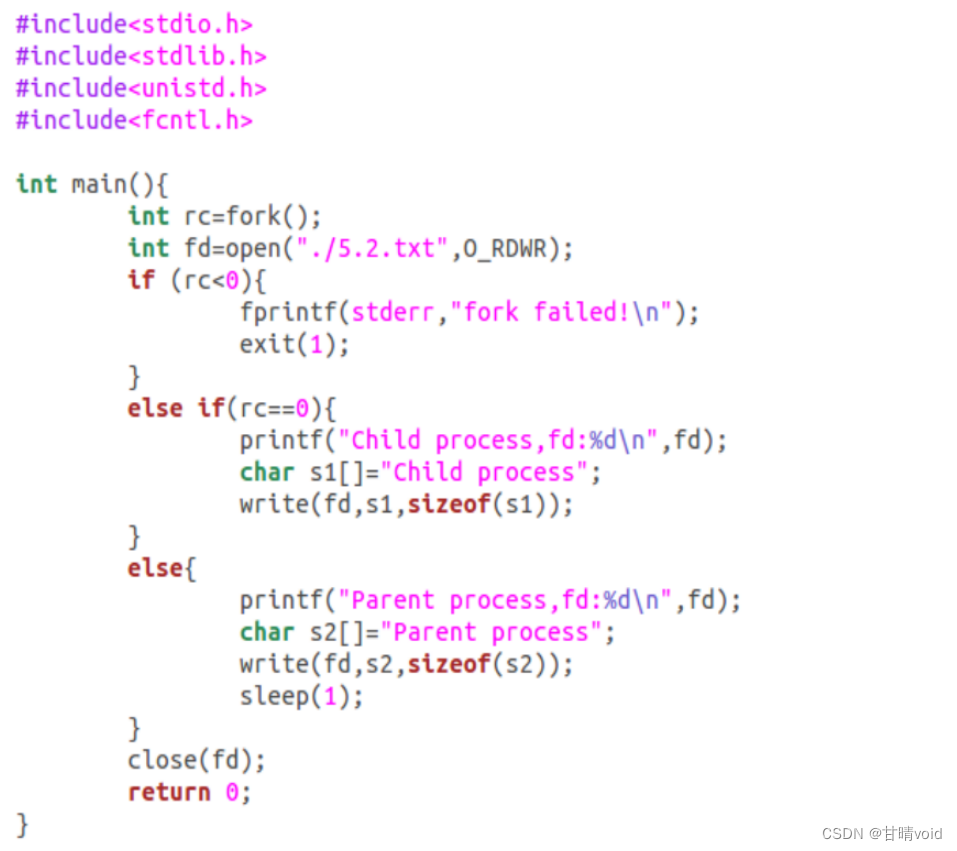
调用fork()创建新进程并使子进程与父进程访问open()返回的文件描述符。可见子进程与父进程都可以访问open()返回的文件描述符。

5.4编写一个调用 fork()的程序,然后调用某种形式的 exec()来运行程序"/bin/ls"看看是否可以尝试 exec 的所有变体,包括 execl()、 execle()、 execlp()、 execv()、 execvp()和 execve(),为什么同样的基本调用会有这么多变种?
首先使用man exec指令查看exec族函数的函数原型
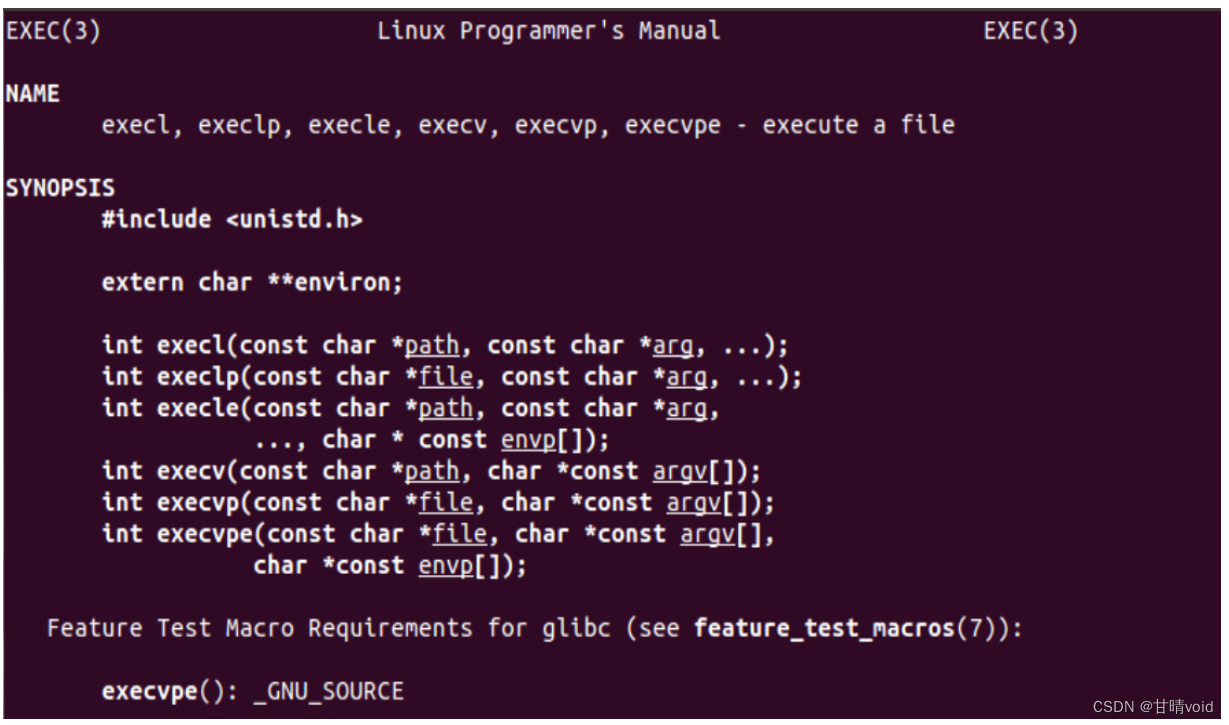
参数可以单独传入,也可以按数组的方式传入,并可以传入环境变量,路径,可执行文件名。
总结:
- 带 l 的exec函数:execl、execlp、execle,表示后边的参数以可变参数的形式给出且都以一个空指针结束。
- 带 p 的 exec 函数:execlp、execvp,表示第一个参数 path 不用输入完整路径,只要给出命令名即可,它会在环境变量 PATH 当中查找命令.
- 不带 l 的 exec 函数:execv、execvp 表示命令所需的参数以 char *arg[] 形式给出且 arg 最后一个元素必须是 NULL 。
- 带 e 的 exec 函数:execle 表示,将环境变量传递给需要替换的进程。
我们这里以excl为例,尝试运行程序ls。

下面是结果。

当然也可以尝试其他的结果,我们这里分次尝试了以下代码的所有共6个语句。
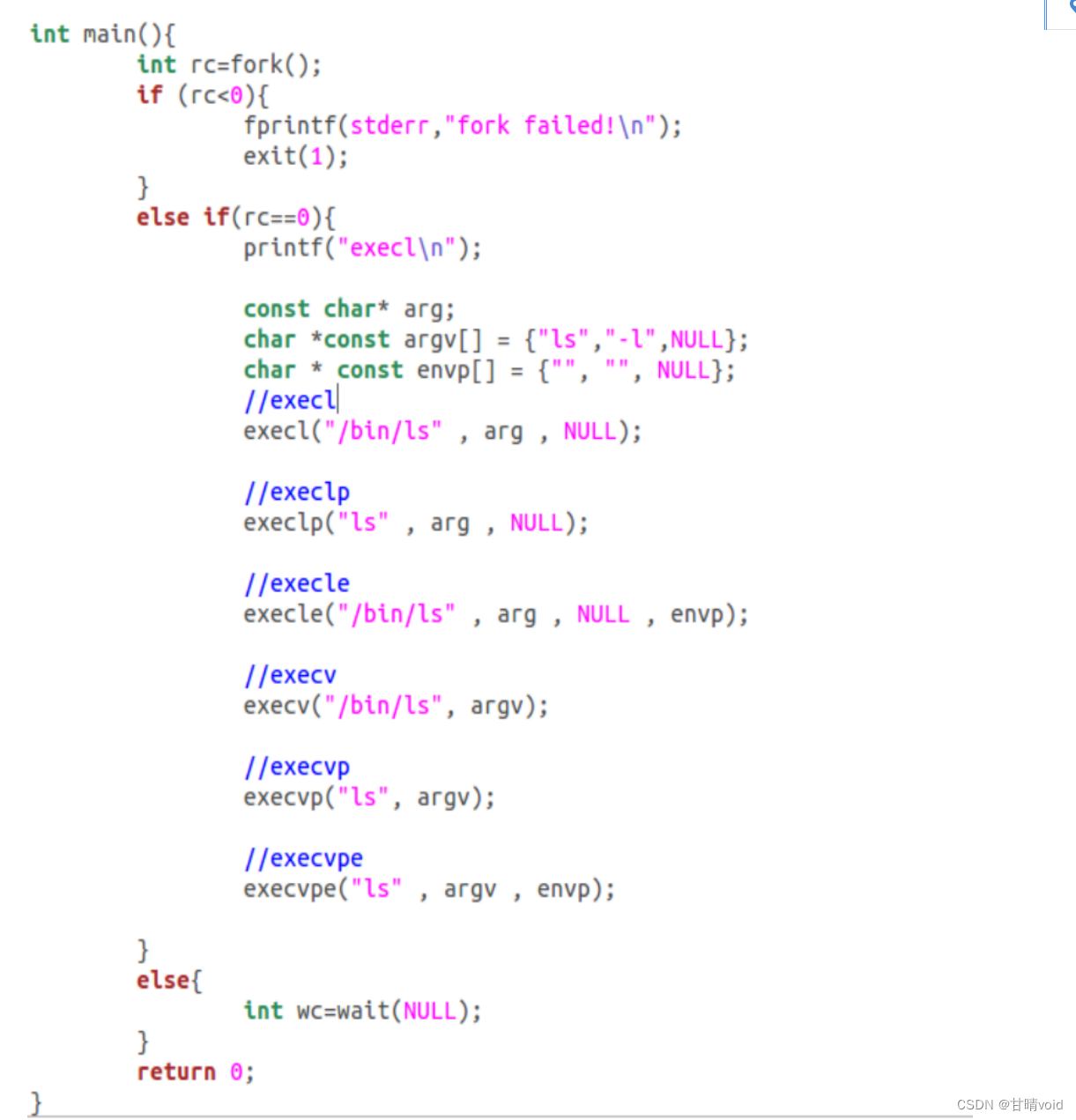
分别得到结果如下:

为什么同样的基本调用会有这么多变种?多种exec()调用的参数传递方式、传递参数不同,方便以不同的形式使用,实现更多功能。
第七章
7.1使用SJF和FIFO调度程序运行长度为200的3个作业时,计算响应时间和周转时间。
SJF与FIFO均采取如下方式运行三个进程
| SJF/FIFO | ||
| 200 | 200 | 200 |
| A | B | C |
可总结出如下表格
| SJF/FIFO | 响应时间 | 周转时间 |
| A | 0 | 200 |
| B | 200 | 400 |
| C | 400 | 600 |
| average | 200 | 400 |
可见,对于SJF与FIFO,其平均响应时间为200,平均周转时间为400。
7.2现在做同样的事情,但有不同长度的作业,即100、200和300。
SJF与FIFO均采取如下方式运行三个进程
| SJF/FIFO | ||
| 100 | 200 | 300 |
| A | B | C |
可总结出如下表格
| SJF/FIFO | 响应时间 | 周转时间 |
| A | 0 | 100 |
| B | 100 | 300 |
| C | 300 | 600 |
| average | 133.3 | 333.3 |
可见,对于SJF与FIFO,其平均响应时间为133.3,平均周转时间为333.3。
7.3现在做同样的事情,但采用RR调度程序,时间片为1。
采用RR调度,时间片为1。
| RR | 响应时间 | 周转时间 |
| A | 0 | 598 |
| B | 1 | 599 |
| C | 2 | 600 |
| average | 1 | 599 |
可见,对于RR,其平均响应时间为1,平均周转时间为599。
7.4对于什么类型的工作负载,SJF提供与FIFO相同的周转时间?
答:
- 作业到达时间不一致时。
- 作业到达时间一致时,列表中执行顺序按作业长度非严格递增。
- 部分作业到达时间一致时,到达时间一致的部分满足条件(2)
7.5对于什么类型的工作负载和量子长度,SJF与RR提供相同的响应时间?
答:每个工作的时长相同且等于量子长度(时间切片)。
7.6随着工作长度的增加,SJF的响应时间会怎样?你能使用模拟程序来展示趋势吗?
答:
- 若所有工作长度都增加,则除了最短任务的响应时间不变,其余任务的响应时间均增加。
- 若只有部分工作长度增加,则长度比该部分工作长的工作,其响应时间增加。
模拟程序略。
7.7随着量子长度的增加,RR 的响应时间会怎样?你能写出一个方程,计算给定 N 个工作时,最坏情况的响应时间吗?
答:
假设量子长度为t0,则平均响应时间为
[0*t0+1*t0+2*t0+……+(n-1)*t0]/n=(n-1)*t0/2
最坏情况的响应时间即是最后一个工作的响应时间,为(n-1)*t0
第八章
8.1只用两个工作和两个队列运行几个随机生成的问题。针对每个工作计算MLFQ的执行记录。限制每项作业的长度并关闭I/O,让你的生活更轻松。
根据题目意思,查阅Readme文件,使用以下指令
./mlfq.py -n 2 -j 2 -m 100 -M 0
其中-n为队列个数,-j为工作个数,-m为每项作业长度上限,-M为I/O频率,由于关闭I/O,其频率为0。
(1)尝试第一个问题
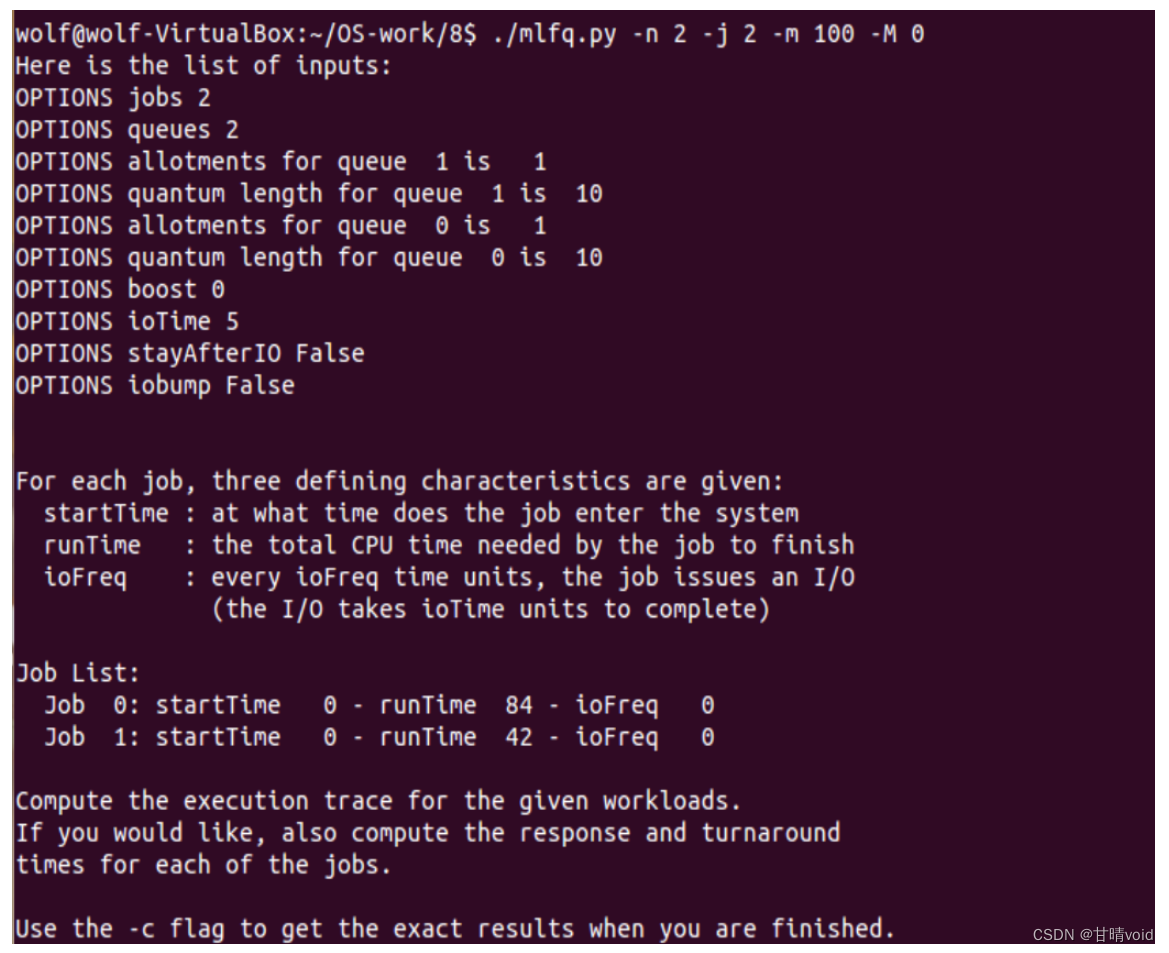
关于工作的参数记录如下:
工作0,时间84
工作1,时间42,
队列0,队列1:时间切片10
重新加入最高优先级队列的时间S(巫毒常量):0
(由于这里只有两个工作且无I/O,重新加入最高优先级队列的意义不大)
计算执行记录如下,
| 时间 | 队列0 | 队列1 | CPU |
| 0-10 | AB | A | |
| 10-20 | B | A | B |
| 20-30 | AB | A | |
| 30-40 | AB | B | |
| 40-50 | AB | A | |
| 50-60 | AB | B | |
| 60-70 | AB | A | |
| 70-80 | AB | B | |
| 80-90 | AB | A | |
| 90-92 | AB | B | |
| 92-126 | AB | A |
可见平均响应时间为5,平均周转时间为109
使用-c可以查看每个单位时间的运算情况,与上表一致。
使用-s指令可以更换种子,我这里用了-s 9,得到如下
(2)尝试第二个问题
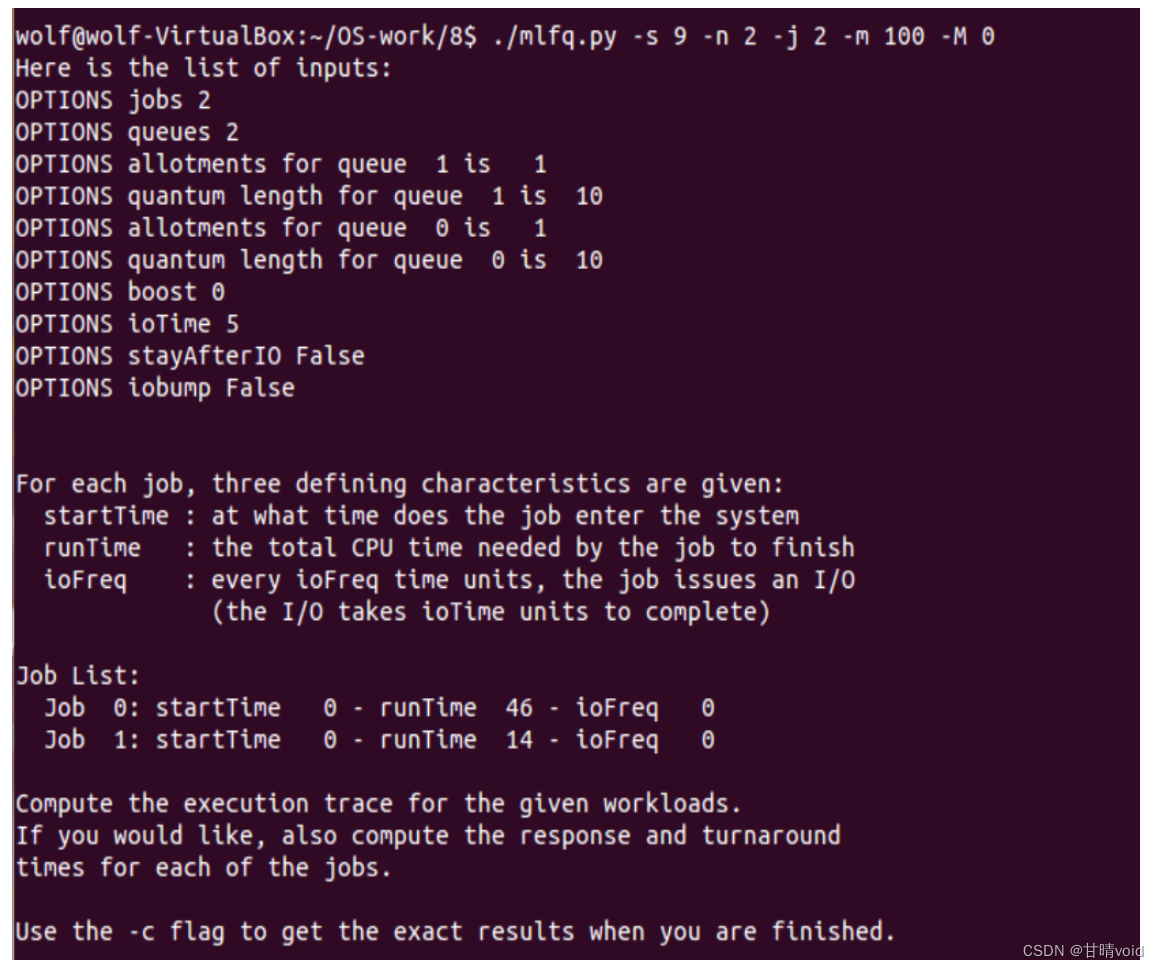
分析同第一个问题,略去不讲,只说计算执行记录如下表
| 时间 | 队列0 | 队列1 | CPU |
| 0-10 | AB | A | |
| 10-20 | B | A | B |
| 20-30 | AB | A | |
| 30-44 | AB | B | |
| 40-66 | AB | A |
可见平均响应时间为5,平均周转时间为55
使用-c可以查看每个单位时间的运算情况,与上表一致。
(3)尝试其他问题,可以通过指令运行,这里就不再赘述。
8.3将如何配置调度程序参数,像轮转调度程序那样工作?
答:当工作在同一队列时,进行轮转调度工作,因此只需要将mlfq调度的队列数设置为1,这里考虑重新加入最高优先级队列的时间S(巫毒常量)意义不大,所以不需考虑。
综上答案为./mlfq.py -n 1
8.5给定一个系统,其最高队列中的时间片长度为10ms,你需要如何频繁地将工作推回到最高优先级级别(带有-B标志),以保证一个长时间运行(并可能饥饿)的工作得到至少5%的CPU。
答:10ms/5%=200ms,故boost的频率至少为200ms才能使该工作至少得到5%的CPU。
第九章
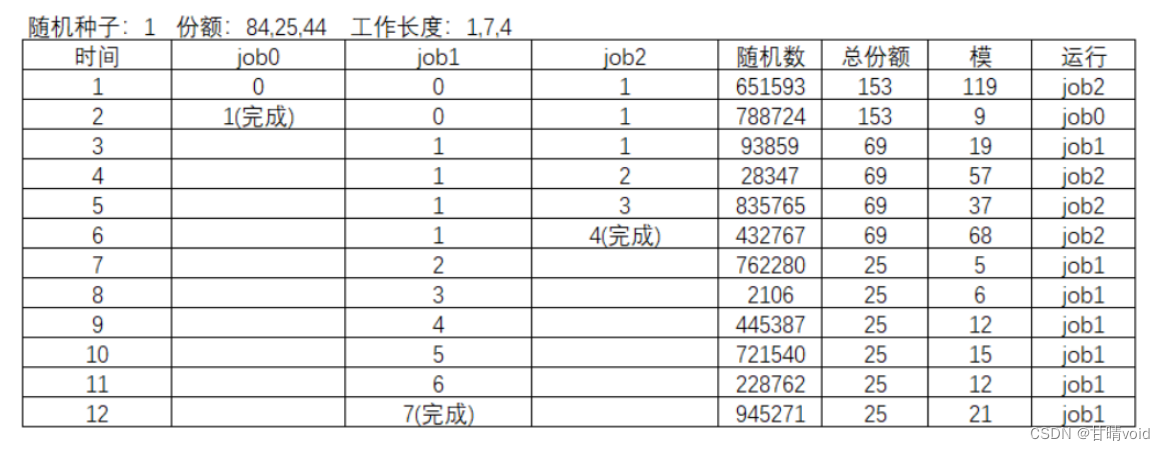
9.1计算3个工作在随机种子为1、2和3时的模拟解。
1.随机种子seed=1

计算模拟解过程如下
2.随机种子seed=2
计算模拟解过程如下:
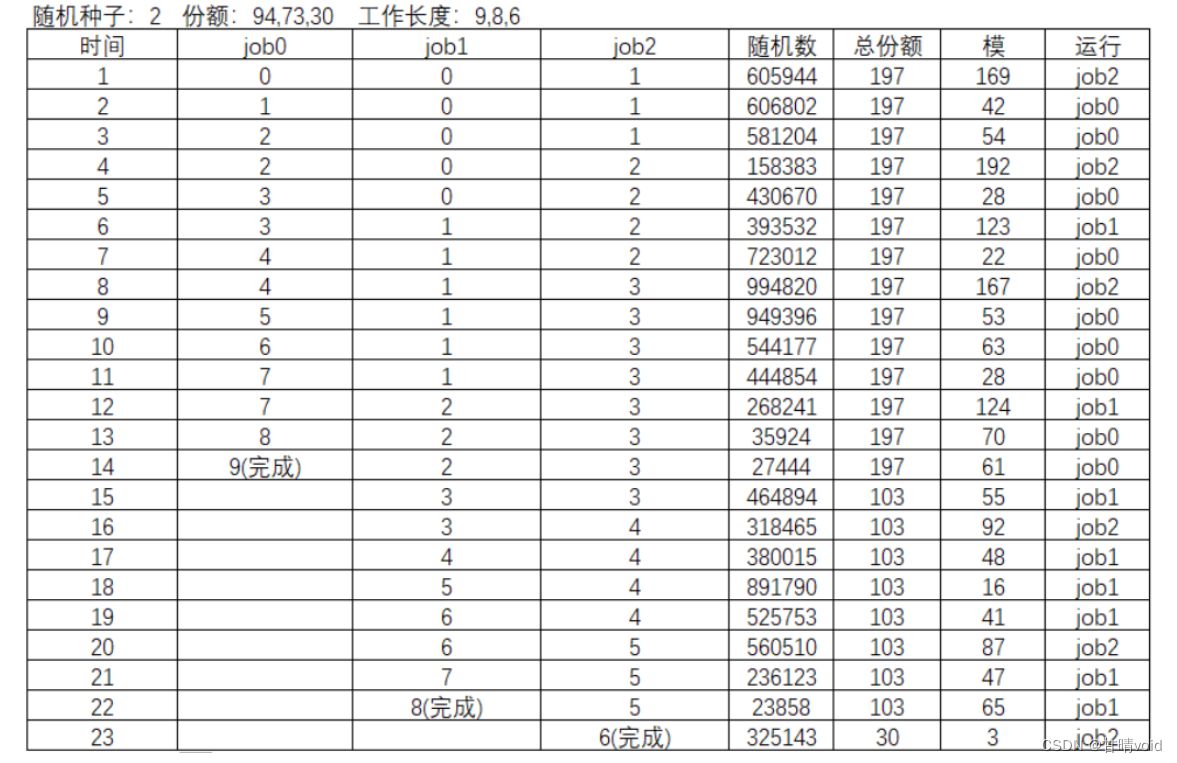
3.随机种子seed=3
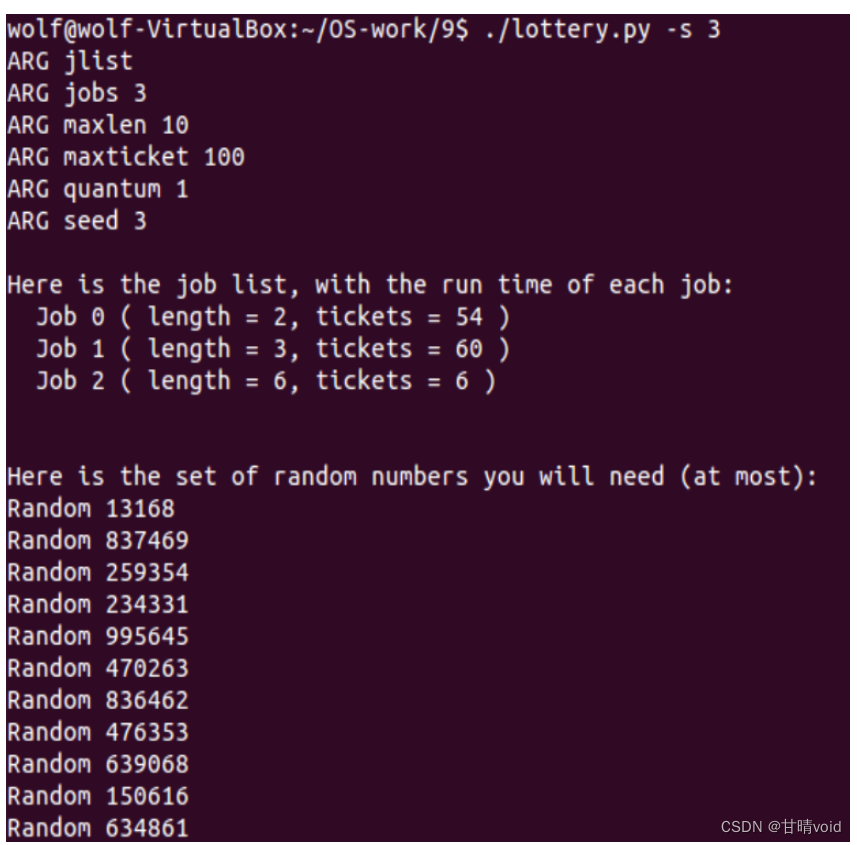
计算模拟解过程如下:
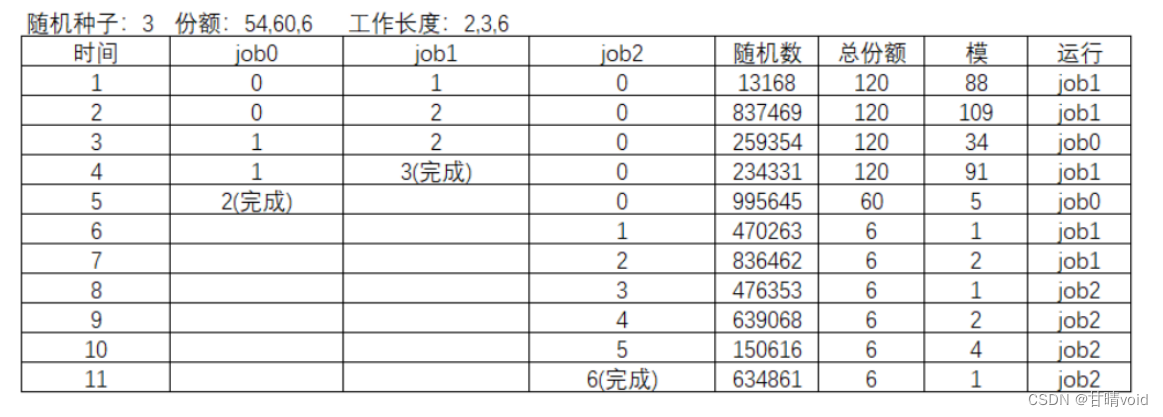
9.2现在运行两个具体的工作:每个长度为10,但是一个(工作0)只有一张彩票,另一个(工作1)有100张(-l 10:1,10:100)。
彩票数量如此不平衡时会发生什么?在工作1完成之前,工作0是否会运行?多久?一般来说,这种彩票不平衡对彩票调度的行为有什么影响?
使用 ./lottery.py -l 10:1,10:100进行模拟。

计算模拟解过程如下:
这里工作0与工作1的彩票数量差距过大了,导致在工作1完成之前工作0占用CPU几乎是不可能的。从模拟结果上看,在工作1完成之前,工作0没有运行。
在这种情况下,持有份额小的工作响应时间与周转时间非常长,且基本上占用不了CPU。极有可能会“饿死”。
9.3如果运行两个长度为100的工作,都有100张彩票(-l 100:100,100:100),调度程序有多不公平?运行一些不同的随机种子来确定(概率上的)答案。不公平性取决于一项工作比另一项工作早完成多少。
使用./lottery.py -l 100:100,100:100来进行模拟。使用-s来设定种子。
| 种子编号 | 工作0完成时间 | 工作1完成时间 | 提前完成时间 |
| 0 | 192 | 200 | 8 |
| 1 | 200 | 196 | 4 |
| 2 | 200 | 190 | 10 |
| 3 | 196 | 200 | 4 |
| 4 | 200 | 199 | 1 |
| 5 | 200 | 181 | 19 |
| 6 | 200 | 193 | 7 |
| 7 | 200 | 185 | 15 |
| 8 | 200 | 191 | 9 |
| 9 | 200 | 192 | 8 |
| 10 | 197 | 200 | 3 |
| 11 | 196 | 200 | 4 |
| 12 | 200 | 189 | 11 |
| Average | 198.5 | 193.5 | 7.9 |
提前完成的工作所用时间平均比后完成的快了8左右,对比工作长度只能保证基本接近公平,假设以提前完成时间比工作长度为指标,不公平度约为7.9%。

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)