MLC-LLM大语言模型部署实战(基于CUDA)
MLC-LLM 大语言模型部署 CUDA
1. 简介
MLC-LLM为5月初开源的一款基于Apache TVM Unity、专门用于在不同硬件设备上部署大语言模型的框架;
github仓库:https://github.com/mlc-ai/mlc-llm
MLC-LLM是一种在各类硬件上原生部署任意大语言模型的解决方案。按照所介绍的硬件平台支持类型如下:

按照docs中的教程,直接实操:
2.环境搭建
(1)首先确定你是要在什么平台使用mlc-llm做大模型部署;我这里使用的是Nvidia GPU,所以首先需要安装CUDA,这是必要的后端支持环境,成功安装好CUDA就可以进行下一步;
(2)安装TVM Unity:
有关于TVM Unity的技术策略介绍可以参考天奇大佬的介绍:https://discuss.tvm.apache.org/t/establish-tvm-unity-connection-a-technical-strategy/13344
TVM Unity是mlc-llm执行的必要依赖条件;所以需要事先安装它。
教程中提供了两种安装方案:
一种是通过预构建的包来安装:
预构建程序包地址:https://mlc.ai/package/
界面长这样,和目前主流的框架安装方式十分接近,选好你的设备平台、系统等,直接命令安装,非常方便;
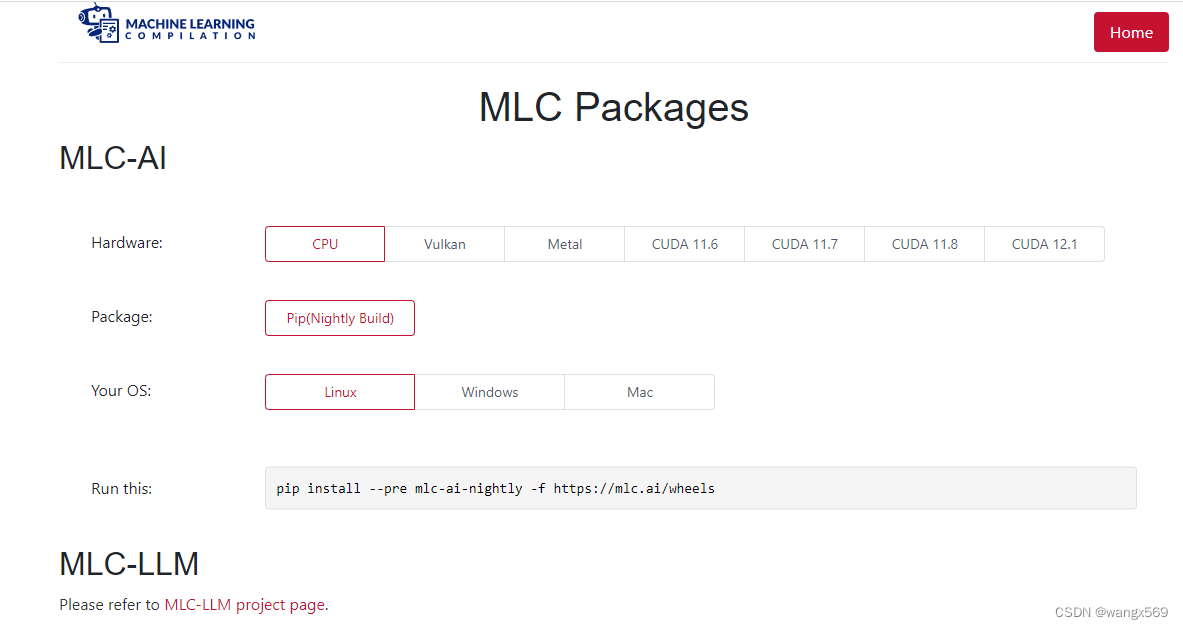
安装完上面的包以后,执行:
python -c "import tvm; print(tvm.__file__)"
输出:/usr/local/lib/python3.11/site-packages/tvm/__init__.py
继续输入:
export TVM_HOME=/usr/local/lib/python3.11/site-packages/tvm/
如果安装正确,会在上述目录下包含libtvm.so的动态库。
另一种是从源码安装(推荐这种方法安装):
首先系统中部分工具版本需要满足以下条件:
- CMake >= 3.18
- LLVM >= 15
- Git
- CUDA >= 11.8
然后从github下载TVM unity:
git clone https://github.com/mlc-ai/relax.git tvm-unity
cd tvm-unity
rm -rf build
mkdir build
cd build
cp ../cmake/config.cmake .
vim config.cmake
修改config.cmake,选择你需要依赖的平台,打开它,比如这里我是基于CUDA运行,所以我选择将USE_CUDA的OFF改为ON
此外set(USE_LLVM ON)必须为ON,其他选项可以自由选择。
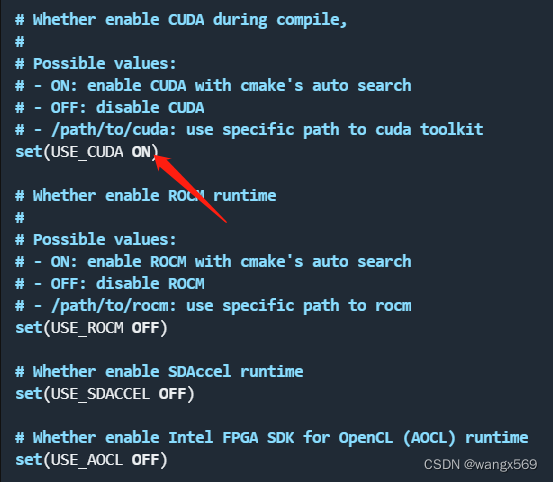
修改好以后执行:
cmake ..
make -j4
编译完成,没有任何错误,会在build目录下生成libtvm.so和libtvm_runtime.so库文件,切记不要把这两个库移动出去了;
然后添加环境变量:
vim ~/.bashrc
在文件尾添加:
export TVM_HOME=/home/wangxu/tvm-unity
export PYTHONPATH=$TVM_HOME/python:$PYTHONPATH
保存退出;
source ~/.bashrc
最后验证一下,直接参考官方文档,上述步骤没发生错误一般不会出现问题:
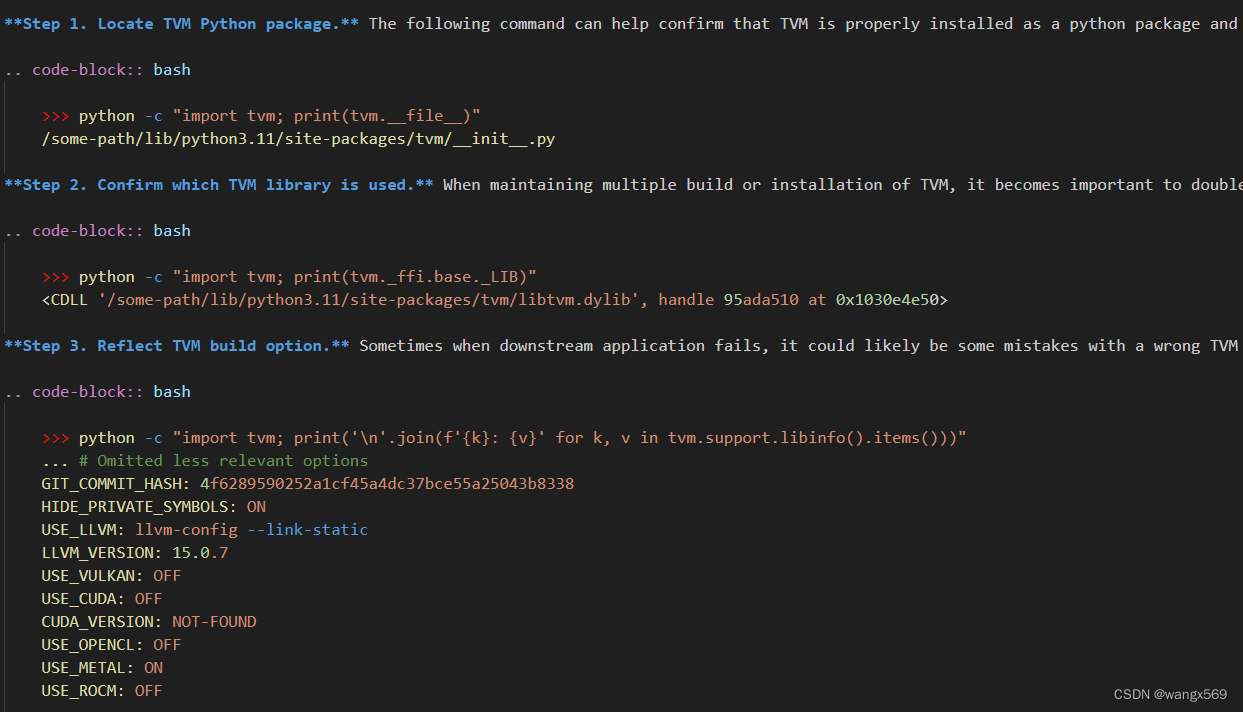
(3)安装MLC-LLM CLI
依旧有两种方式:
一种是通过conda环境安装,当然也给了提醒,这种类型不支持CUDA !,对于我们使用CUDA来执行mlc-llm来说肯定不能选用此种方法,同样给出方法,很简单:
conda create -n mlc-chat
conda activate mlc-chat
conda install -c mlc-ai -c conda-forge mlc-chat-nightly --force-reinstall
安装完成验证:
mlc_chat_cli --help
输出正常提示信息即可:

另一种方法通过源码安装:
首先从github拉取mlc-llm源码:
git clone https://github.com/mlc-ai/mlc-llm.git
切换成root权限,直接依次执行:
cd mlc-llm
mkdir -p build
bash scripts/prep_deps.sh
source "$HOME/.cargo/env"
python3 cmake/gen_cmake_config.py
cp config.cmake build
cd build
cmake ..
make -j4
sudo make install
ldconfig
构建成功情况下,添加环境变量:
vim ~/.bashrc
# 依旧在行尾添加:
export PATH=/usr/local/bin:$PATH
exportLD_LIBRARY_PATH=/usr/local/lib:$LD_LIBRARY_PATH
# 保存退出
ldconfig
验证:
mlc_chat_cli --help
和第一种方法输出信息一致即可。
mlc_chat_cli使用方法很简单,主要使用格式为:
mlc_chat_cli --local-id LOCAL_ID
这里的 local-id 其实就是模型名后面接上量化的格式,例如:
mlc_chat_cli --local-id RedPajama-INCITE-Chat-3B-v1-q4f16_0
mlc_chat_cli --local-id vicuna-v1-7b-q3f16_0
以上,环境搭建完成。
3.编译模型
(1)准备模型:
git lfs install
git clone https://huggingface.co/togethercomputer/RedPajama-INCITE-Chat-3B-v1 dist/models/RedPajama-INCITE-Chat-3B-v1
注意,这里将模型存放在/mlc-llm/dist/models路径下,后面拉取的每个模型都要放在此路径下,并且文件夹命名需要满足:
以(vicuna-, dolly-, stablelm-, redpajama-, moss-, open-llama-, rwkv-)命名开头;
(2)编译:
编译命令(需要在mlc-llm源码路径下执行下面命令):
python3 build.py --model MODEL_NAME_OR_PATH --target TARGET_NAME --quantization QUANTIZATION_NAME [--max-seq-len MAX_ALLOWED_SEQUENCE_LENGTH] [--debug-dump] [--use-cache=0]
--model 模型文件夹名称
--target 目标后端平台
--quantization 量化方式
例:
python3 build.py --model RedPajama-INCITE-Chat-3B-v1 --target cuda --quantization q4f32_0
编译过程比较消耗运存,建议使用较大运存的设备进行编译,比如vicuna-7b-delta-v0编译可能最高能达到30多G;
编译完成会在mlc-llm/dist目录下生成MODEL_NAME-quant_type的文件夹,比如上面的命令生成的文件夹名称就为:
RedPajama-INCITE-Chat-3B-v1-q4f32_0
4.部署模型
上述编译完成后,依旧在mlc-llm源码路径下执行命令:
mlc_chat_cli --local-id RedPajama-INCITE-Chat-3B-v1-q4f32_0
接下来,和它对话就可以啦:
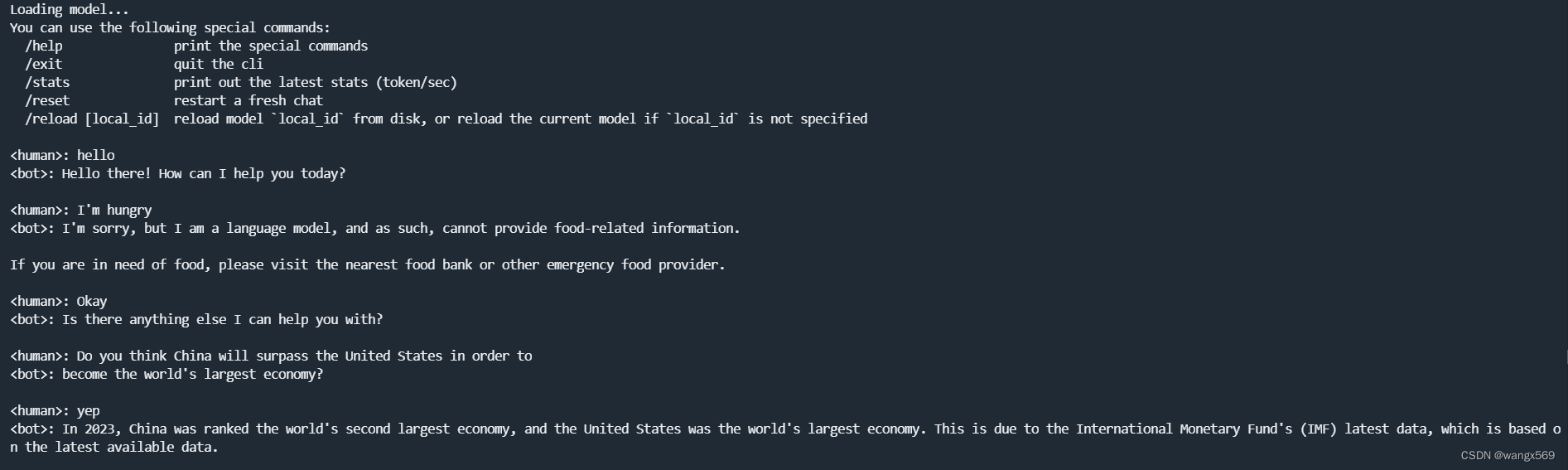

昇腾万里,让智能无所不及
更多推荐

 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)