
pointNet训练预测自己的数据集Charles版本(一)
博主有逐步debug过,对其里面的机制还是了解的,感兴趣的童鞋可以自行去分析下,值得去做这样的事情。这里有个小插曲,即博主在cmd终端train时候,训练的很快,在pycharm中训练的很慢,发现是因为pycharm环境变量中并没有修正最新的cuda的路径,而导致跑在gpu上异常,模型训练实际是跑在cpu上的,所以这里需要结合自己的路径重新配置下。当前博主用的虚拟环境下的tensorflow版本是
这里跑下作者在github提供的pointNet源码,也会训练和预测下自己的数据集。实际动手看下效果。
https://github.com/charlesq34/pointnet![]() https://github.com/charlesq34/pointnet
https://github.com/charlesq34/pointnet
这边思路还是一样的,什么东西在被自己所用之前,先理解下原作者的代码,多debug下,然后才能更好地吸收。所以此篇先介绍如何跑通源码(分类,语义分割,部件分割都会跑一遍)。
一. 点云分类和预测
1.训练分类网络
所用的环境还是python下的一个虚拟环境,和之前博客中pointNet(Keras实现)那部分实验环境保持一致。工程下载完毕后,用pycharm community版打开, 如下是根目录下的train.py文件,做点云分类训练用。
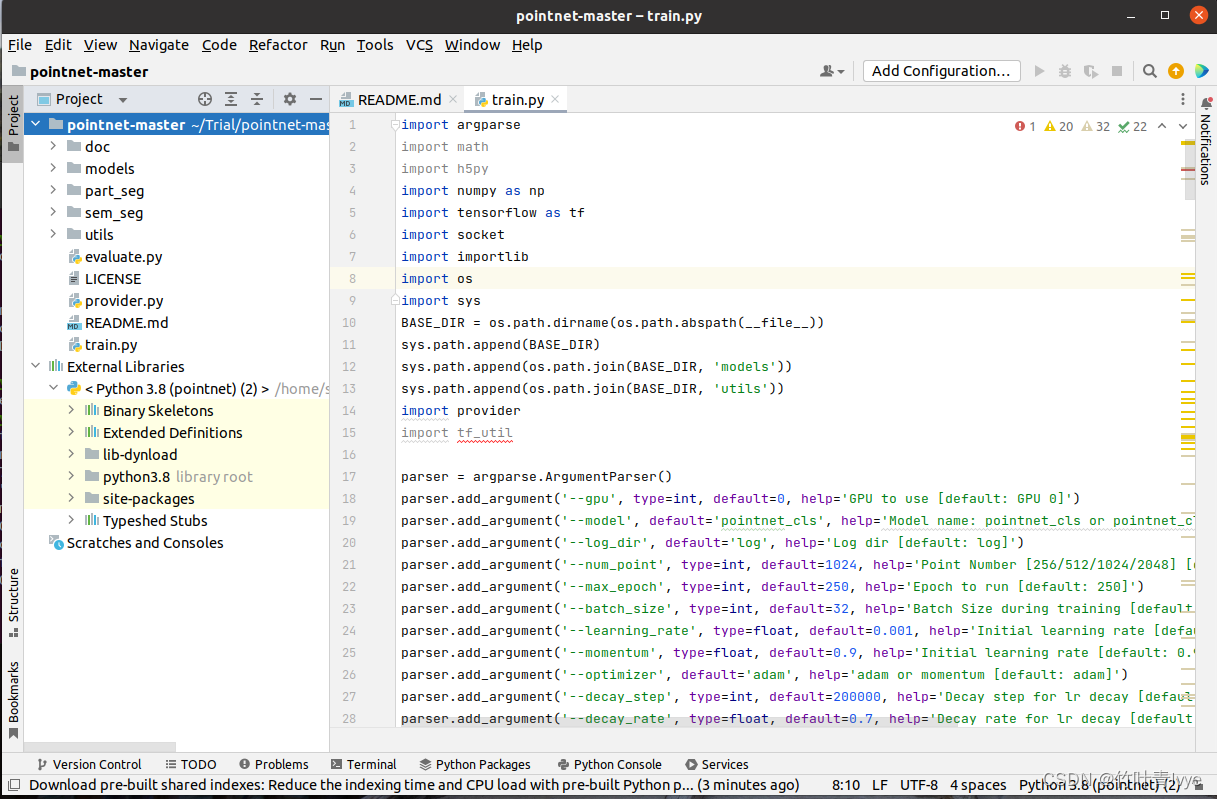
作者说了,当时是在 Tensorlfow1.x版本下实现的

当前博主用的虚拟环境下的tensorflow版本是2.4.0, 所以要对源代码进行一些修改,才能跑起来,可以参考博主之前的博客进行修改。
tensorflow1.x代码转换到tensorflow2.x_竹叶青lvye的博客-CSDN博客
重点说几点:
1). 将import tensorflow as tf语句修改为如下:
import tensorflow.compat.v1 as tf tf.compat.v1.disable_eager_execution()
2). 若碰到如下报错
AttributeError: 'int' object has no attribute 'value'
那解决办法是将value属性去掉即可,这里也贴上自己工程的链接。
链接: https://pan.baidu.com/s/1JvFgbW9aAI0akwvZ6w4JlQ 提取码: 4cvb
3).initializer =tf.contrib.layers.xavier_initializer()的报错问题,可参考如下论坛回复
python - change tf.contrib.layers.xavier_initializer() to 2.0.0 - Stack Overflow
训练之前要先下载modelnet40_ply_hdf5_2048数据集,github上有该数据集的下载地址,可手动下载。文末有该数据集的介绍,下载完毕后,博主放在如下工程目录下:
完毕后执行train.py,程序就能进入训练阶段
import tensorflow.compat.v1 as tf
tf.compat.v1.disable_eager_execution()
import argparse
import math
import h5py
import numpy as np
import socket
import importlib
import os
import sys
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
sys.path.append(BASE_DIR)
sys.path.append(os.path.join(BASE_DIR, 'models'))
sys.path.append(os.path.join(BASE_DIR, 'utils'))
import provider
import tf_util
parser = argparse.ArgumentParser()
parser.add_argument('--gpu', type=int, default=0, help='GPU to use [default: GPU 0]')
parser.add_argument('--model', default='pointnet_cls', help='Model name: pointnet_cls or pointnet_cls_basic [default: pointnet_cls]')
parser.add_argument('--log_dir', default='log', help='Log dir [default: log]')
parser.add_argument('--num_point', type=int, default=1024, help='Point Number [256/512/1024/2048] [default: 1024]')
parser.add_argument('--max_epoch', type=int, default=250, help='Epoch to run [default: 250]')
parser.add_argument('--batch_size', type=int, default=32, help='Batch Size during training [default: 32]')
parser.add_argument('--learning_rate', type=float, default=0.001, help='Initial learning rate [default: 0.001]')
parser.add_argument('--momentum', type=float, default=0.9, help='Initial learning rate [default: 0.9]')
parser.add_argument('--optimizer', default='adam', help='adam or momentum [default: adam]')
parser.add_argument('--decay_step', type=int, default=200000, help='Decay step for lr decay [default: 200000]')
parser.add_argument('--decay_rate', type=float, default=0.7, help='Decay rate for lr decay [default: 0.8]')
FLAGS = parser.parse_args()
BATCH_SIZE = FLAGS.batch_size
NUM_POINT = FLAGS.num_point
MAX_EPOCH = FLAGS.max_epoch
BASE_LEARNING_RATE = FLAGS.learning_rate
GPU_INDEX = FLAGS.gpu
MOMENTUM = FLAGS.momentum
OPTIMIZER = FLAGS.optimizer
DECAY_STEP = FLAGS.decay_step
DECAY_RATE = FLAGS.decay_rate
MODEL = importlib.import_module(FLAGS.model) # import network module
MODEL_FILE = os.path.join(BASE_DIR, 'models', FLAGS.model+'.py')
LOG_DIR = FLAGS.log_dir
if not os.path.exists(LOG_DIR): os.mkdir(LOG_DIR)
os.system('cp %s %s' % (MODEL_FILE, LOG_DIR)) # bkp of model def
os.system('cp train.py %s' % (LOG_DIR)) # bkp of train procedure
LOG_FOUT = open(os.path.join(LOG_DIR, 'log_train.txt'), 'w')
LOG_FOUT.write(str(FLAGS)+'\n')
MAX_NUM_POINT = 2048
NUM_CLASSES = 40
BN_INIT_DECAY = 0.5
BN_DECAY_DECAY_RATE = 0.5
BN_DECAY_DECAY_STEP = float(DECAY_STEP)
BN_DECAY_CLIP = 0.99
HOSTNAME = socket.gethostname()
# ModelNet40 official train/test split
TRAIN_FILES = provider.getDataFiles( \
os.path.join(BASE_DIR, 'data/modelnet40_ply_hdf5_2048/train_files.txt'))
TEST_FILES = provider.getDataFiles(\
os.path.join(BASE_DIR, 'data/modelnet40_ply_hdf5_2048/test_files.txt'))
def log_string(out_str):
LOG_FOUT.write(out_str+'\n')
LOG_FOUT.flush()
print(out_str)
def get_learning_rate(batch):
learning_rate = tf.train.exponential_decay(
BASE_LEARNING_RATE, # Base learning rate.
batch * BATCH_SIZE, # Current index into the dataset.
DECAY_STEP, # Decay step.
DECAY_RATE, # Decay rate.
staircase=True)
learning_rate = tf.maximum(learning_rate, 0.00001) # CLIP THE LEARNING RATE!
return learning_rate
def get_bn_decay(batch):
bn_momentum = tf.train.exponential_decay(
BN_INIT_DECAY,
batch*BATCH_SIZE,
BN_DECAY_DECAY_STEP,
BN_DECAY_DECAY_RATE,
staircase=True)
bn_decay = tf.minimum(BN_DECAY_CLIP, 1 - bn_momentum)
return bn_decay
def train():
with tf.Graph().as_default():
with tf.device('/gpu:'+str(GPU_INDEX)):
pointclouds_pl, labels_pl = MODEL.placeholder_inputs(BATCH_SIZE, NUM_POINT)
is_training_pl = tf.placeholder(tf.bool, shape=())
print(is_training_pl)
# Note the global_step=batch parameter to minimize.
# That tells the optimizer to helpfully increment the 'batch' parameter for you every time it trains.
batch = tf.Variable(0)
bn_decay = get_bn_decay(batch)
tf.summary.scalar('bn_decay', bn_decay)
# Get model and loss
pred, end_points = MODEL.get_model(pointclouds_pl, is_training_pl, bn_decay=bn_decay)
loss = MODEL.get_loss(pred, labels_pl, end_points)
tf.summary.scalar('loss', loss)
correct = tf.equal(tf.argmax(pred, 1), tf.to_int64(labels_pl))
accuracy = tf.reduce_sum(tf.cast(correct, tf.float32)) / float(BATCH_SIZE)
tf.summary.scalar('accuracy', accuracy)
# Get training operator
learning_rate = get_learning_rate(batch)
tf.summary.scalar('learning_rate', learning_rate)
if OPTIMIZER == 'momentum':
optimizer = tf.train.MomentumOptimizer(learning_rate, momentum=MOMENTUM)
elif OPTIMIZER == 'adam':
optimizer = tf.train.AdamOptimizer(learning_rate)
train_op = optimizer.minimize(loss, global_step=batch)
# Add ops to save and restore all the variables.
saver = tf.train.Saver()
# Create a session
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
config.allow_soft_placement = True
config.log_device_placement = False
sess = tf.Session(config=config)
# Add summary writers
#merged = tf.merge_all_summaries()
merged = tf.summary.merge_all()
train_writer = tf.summary.FileWriter(os.path.join(LOG_DIR, 'train'),
sess.graph)
test_writer = tf.summary.FileWriter(os.path.join(LOG_DIR, 'test'))
# Init variables
init = tf.global_variables_initializer()
# To fix the bug introduced in TF 0.12.1 as in
# http://stackoverflow.com/questions/41543774/invalidargumenterror-for-tensor-bool-tensorflow-0-12-1
#sess.run(init)
sess.run(init, {is_training_pl: True})
ops = {'pointclouds_pl': pointclouds_pl,
'labels_pl': labels_pl,
'is_training_pl': is_training_pl,
'pred': pred,
'loss': loss,
'train_op': train_op,
'merged': merged,
'step': batch}
for epoch in range(MAX_EPOCH):
log_string('**** EPOCH %03d ****' % (epoch))
sys.stdout.flush()
train_one_epoch(sess, ops, train_writer)
eval_one_epoch(sess, ops, test_writer)
# Save the variables to disk.
if epoch % 10 == 0:
save_path = saver.save(sess, os.path.join(LOG_DIR, "model.ckpt"))
log_string("Model saved in file: %s" % save_path)
def train_one_epoch(sess, ops, train_writer):
""" ops: dict mapping from string to tf ops """
is_training = True
# Shuffle train files
train_file_idxs = np.arange(0, len(TRAIN_FILES))
np.random.shuffle(train_file_idxs)
for fn in range(len(TRAIN_FILES)):
log_string('----' + str(fn) + '-----')
current_data, current_label = provider.loadDataFile(TRAIN_FILES[train_file_idxs[fn]])
current_data = current_data[:,0:NUM_POINT,:]
current_data, current_label, _ = provider.shuffle_data(current_data, np.squeeze(current_label))
current_label = np.squeeze(current_label)
file_size = current_data.shape[0]
num_batches = file_size // BATCH_SIZE
total_correct = 0
total_seen = 0
loss_sum = 0
for batch_idx in range(num_batches):
start_idx = batch_idx * BATCH_SIZE
end_idx = (batch_idx+1) * BATCH_SIZE
# Augment batched point clouds by rotation and jittering
rotated_data = provider.rotate_point_cloud(current_data[start_idx:end_idx, :, :])
jittered_data = provider.jitter_point_cloud(rotated_data)
feed_dict = {ops['pointclouds_pl']: jittered_data,
ops['labels_pl']: current_label[start_idx:end_idx],
ops['is_training_pl']: is_training,}
summary, step, _, loss_val, pred_val = sess.run([ops['merged'], ops['step'],
ops['train_op'], ops['loss'], ops['pred']], feed_dict=feed_dict)
train_writer.add_summary(summary, step)
pred_val = np.argmax(pred_val, 1)
correct = np.sum(pred_val == current_label[start_idx:end_idx])
total_correct += correct
total_seen += BATCH_SIZE
loss_sum += loss_val
log_string('mean loss: %f' % (loss_sum / float(num_batches)))
log_string('accuracy: %f' % (total_correct / float(total_seen)))
def eval_one_epoch(sess, ops, test_writer):
""" ops: dict mapping from string to tf ops """
is_training = False
total_correct = 0
total_seen = 0
loss_sum = 0
total_seen_class = [0 for _ in range(NUM_CLASSES)]
total_correct_class = [0 for _ in range(NUM_CLASSES)]
for fn in range(len(TEST_FILES)):
log_string('----' + str(fn) + '-----')
current_data, current_label = provider.loadDataFile(TEST_FILES[fn])
current_data = current_data[:,0:NUM_POINT,:]
current_label = np.squeeze(current_label)
file_size = current_data.shape[0]
num_batches = file_size // BATCH_SIZE
for batch_idx in range(num_batches):
start_idx = batch_idx * BATCH_SIZE
end_idx = (batch_idx+1) * BATCH_SIZE
feed_dict = {ops['pointclouds_pl']: current_data[start_idx:end_idx, :, :],
ops['labels_pl']: current_label[start_idx:end_idx],
ops['is_training_pl']: is_training}
summary, step, loss_val, pred_val = sess.run([ops['merged'], ops['step'],
ops['loss'], ops['pred']], feed_dict=feed_dict)
pred_val = np.argmax(pred_val, 1)
correct = np.sum(pred_val == current_label[start_idx:end_idx])
total_correct += correct
total_seen += BATCH_SIZE
loss_sum += (loss_val*BATCH_SIZE)
for i in range(start_idx, end_idx):
l = current_label[i]
total_seen_class[l] += 1
total_correct_class[l] += (pred_val[i-start_idx] == l)
log_string('eval mean loss: %f' % (loss_sum / float(total_seen)))
log_string('eval accuracy: %f'% (total_correct / float(total_seen)))
log_string('eval avg class acc: %f' % (np.mean(np.array(total_correct_class)/np.array(total_seen_class,dtype=np.float))))
if __name__ == "__main__":
train()
LOG_FOUT.close()

这里有个小插曲,即博主在cmd终端train时候,训练的很快,在pycharm中训练的很慢,发现是因为pycharm环境变量中并没有修正最新的cuda的路径,而导致跑在gpu上异常,模型训练实际是跑在cpu上的,所以这里需要结合自己的路径重新配置下。
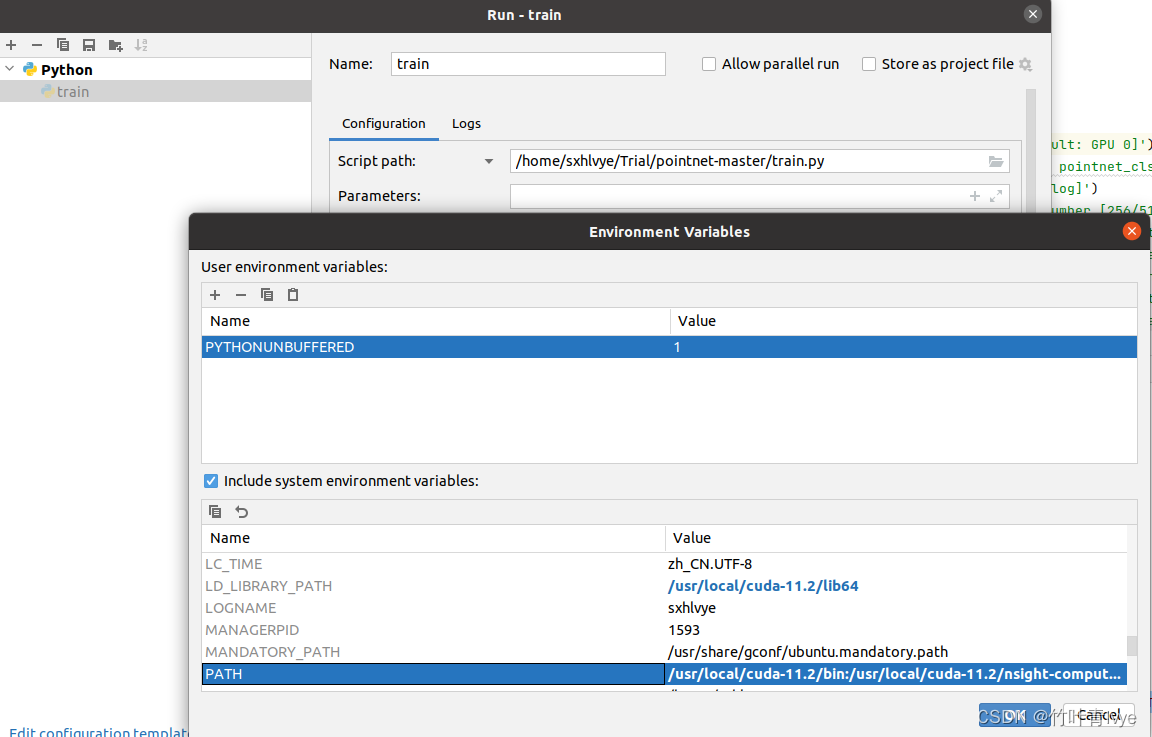
是否跑在gpu上可用如下语句来验证
import tensorflow as tf
print(tf.test.is_gpu_available())时间有限,博主这边只迭代训练了80次。如下语句可以通过tensorboard去查看训练的日志
tensorboard --logdir=/home/sxhlvye/Trial/pointnet-master/log/train --host=127.0.0.1
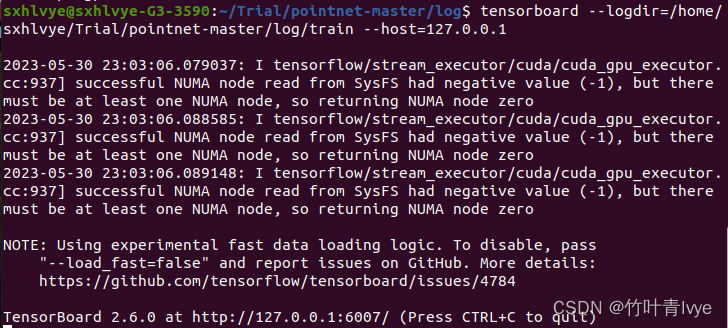
然后可以通过网页来查看详情
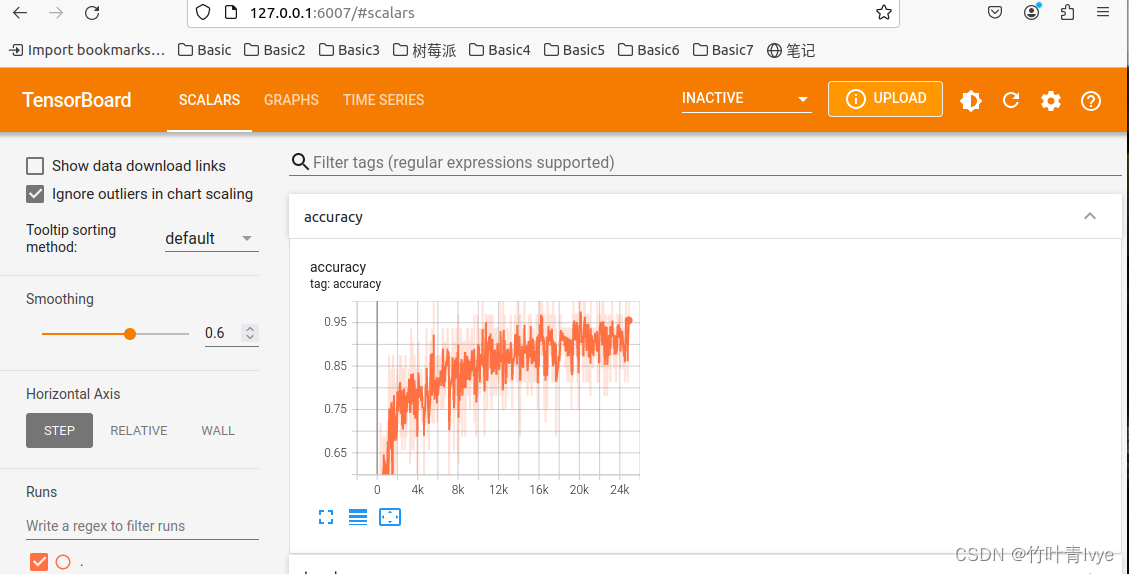
Tensorboard使用详情可参考如下博客
Keras相关知识点整理(tensorflow2.4)_with writer.as_default()_竹叶青lvye的博客-CSDN博客
可看到每份点云数据个数和对应每份点云数据的类别,这里共有2048份点云数据,所以label的维度是2048*1。
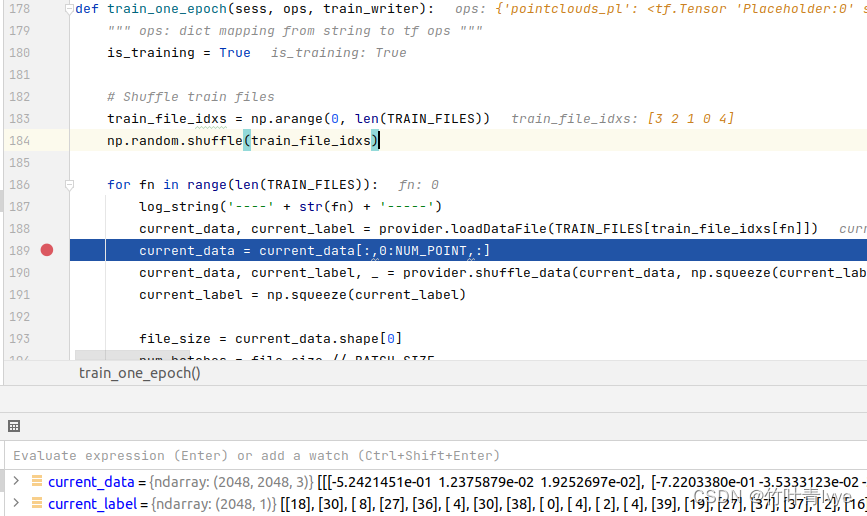
可看到modelnet40_ply_hdf5中的点云数据是3维的,只含有x,y,z信息

博主这边改写了下,这样可以在训练之前先加载下预训练的模型,在此基础上做增强学习,代码如下:
import tensorflow.compat.v1 as tf
tf.compat.v1.disable_eager_execution()
import argparse
import math
import h5py
import numpy as np
import socket
import importlib
import os
import sys
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
sys.path.append(BASE_DIR)
sys.path.append(os.path.join(BASE_DIR, 'models'))
sys.path.append(os.path.join(BASE_DIR, 'utils'))
import provider
import tf_util
parser = argparse.ArgumentParser()
parser.add_argument('--gpu', type=int, default=0, help='GPU to use [default: GPU 0]')
parser.add_argument('--model', default='pointnet_cls', help='Model name: pointnet_cls or pointnet_cls_basic [default: pointnet_cls]')
parser.add_argument('--log_dir', default='log', help='Log dir [default: log]')
parser.add_argument('--num_point', type=int, default=1024, help='Point Number [256/512/1024/2048] [default: 1024]')
parser.add_argument('--max_epoch', type=int, default=250, help='Epoch to run [default: 250]')
parser.add_argument('--batch_size', type=int, default=32, help='Batch Size during training [default: 32]')
parser.add_argument('--learning_rate', type=float, default=0.001, help='Initial learning rate [default: 0.001]')
parser.add_argument('--momentum', type=float, default=0.9, help='Initial learning rate [default: 0.9]')
parser.add_argument('--optimizer', default='adam', help='adam or momentum [default: adam]')
parser.add_argument('--decay_step', type=int, default=200000, help='Decay step for lr decay [default: 200000]')
parser.add_argument('--decay_rate', type=float, default=0.7, help='Decay rate for lr decay [default: 0.8]')
parser.add_argument('--model_path', default='log/model.ckpt', help='model checkpoint file path [default: log/model.ckpt]')
FLAGS = parser.parse_args()
BATCH_SIZE = FLAGS.batch_size
NUM_POINT = FLAGS.num_point
MAX_EPOCH = FLAGS.max_epoch
BASE_LEARNING_RATE = FLAGS.learning_rate
GPU_INDEX = FLAGS.gpu
MOMENTUM = FLAGS.momentum
OPTIMIZER = FLAGS.optimizer
DECAY_STEP = FLAGS.decay_step
DECAY_RATE = FLAGS.decay_rate
MODEL = importlib.import_module(FLAGS.model) # import network module
MODEL_FILE = os.path.join(BASE_DIR, 'models', FLAGS.model+'.py')
LOG_DIR = FLAGS.log_dir
if not os.path.exists(LOG_DIR): os.mkdir(LOG_DIR)
os.system('cp %s %s' % (MODEL_FILE, LOG_DIR)) # bkp of model def
os.system('cp train.py %s' % (LOG_DIR)) # bkp of train procedure
LOG_FOUT = open(os.path.join(LOG_DIR, 'log_train.txt'), 'w')
LOG_FOUT.write(str(FLAGS)+'\n')
MAX_NUM_POINT = 2048
NUM_CLASSES = 40
BN_INIT_DECAY = 0.5
BN_DECAY_DECAY_RATE = 0.5
BN_DECAY_DECAY_STEP = float(DECAY_STEP)
BN_DECAY_CLIP = 0.99
HOSTNAME = socket.gethostname()
# ModelNet40 official train/test split
TRAIN_FILES = provider.getDataFiles( \
os.path.join(BASE_DIR, 'data/modelnet40_ply_hdf5_2048/train_files.txt'))
TEST_FILES = provider.getDataFiles(\
os.path.join(BASE_DIR, 'data/modelnet40_ply_hdf5_2048/test_files.txt'))
def log_string(out_str):
LOG_FOUT.write(out_str+'\n')
LOG_FOUT.flush()
print(out_str)
def get_learning_rate(batch):
learning_rate = tf.train.exponential_decay(
BASE_LEARNING_RATE, # Base learning rate.
batch * BATCH_SIZE, # Current index into the dataset.
DECAY_STEP, # Decay step.
DECAY_RATE, # Decay rate.
staircase=True)
learning_rate = tf.maximum(learning_rate, 0.00001) # CLIP THE LEARNING RATE!
return learning_rate
def get_bn_decay(batch):
bn_momentum = tf.train.exponential_decay(
BN_INIT_DECAY,
batch*BATCH_SIZE,
BN_DECAY_DECAY_STEP,
BN_DECAY_DECAY_RATE,
staircase=True)
bn_decay = tf.minimum(BN_DECAY_CLIP, 1 - bn_momentum)
return bn_decay
def train():
with tf.Graph().as_default():
with tf.device('/gpu:'+str(GPU_INDEX)):
pointclouds_pl, labels_pl = MODEL.placeholder_inputs(BATCH_SIZE, NUM_POINT)
is_training_pl = tf.placeholder(tf.bool, shape=())
print(is_training_pl)
# Note the global_step=batch parameter to minimize.
# That tells the optimizer to helpfully increment the 'batch' parameter for you every time it trains.
batch = tf.Variable(0)
bn_decay = get_bn_decay(batch)
tf.summary.scalar('bn_decay', bn_decay)
# Get model and loss
pred, end_points = MODEL.get_model(pointclouds_pl, is_training_pl, bn_decay=bn_decay)
loss = MODEL.get_loss(pred, labels_pl, end_points)
tf.summary.scalar('loss', loss)
correct = tf.equal(tf.argmax(pred, 1), tf.to_int64(labels_pl))
accuracy = tf.reduce_sum(tf.cast(correct, tf.float32)) / float(BATCH_SIZE)
tf.summary.scalar('accuracy', accuracy)
# Get training operator
learning_rate = get_learning_rate(batch)
tf.summary.scalar('learning_rate', learning_rate)
if OPTIMIZER == 'momentum':
optimizer = tf.train.MomentumOptimizer(learning_rate, momentum=MOMENTUM)
elif OPTIMIZER == 'adam':
optimizer = tf.train.AdamOptimizer(learning_rate)
train_op = optimizer.minimize(loss, global_step=batch)
# Add ops to save and restore all the variables.
saver = tf.train.Saver()
# Create a session
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
config.allow_soft_placement = True
config.log_device_placement = True
sess = tf.Session(config=config)
# Add summary writers
#merged = tf.merge_all_summaries()
merged = tf.summary.merge_all()
train_writer = tf.summary.FileWriter(os.path.join(LOG_DIR, 'train'),
sess.graph)
test_writer = tf.summary.FileWriter(os.path.join(LOG_DIR, 'test'))
# Init variables
init = tf.global_variables_initializer()
# To fix the bug introduced in TF 0.12.1 as in
# http://stackoverflow.com/questions/41543774/invalidargumenterror-for-tensor-bool-tensorflow-0-12-1
#sess.run(init)
sess.run(init, {is_training_pl: True})
saver.restore(sess, FLAGS.model_path)
log_string("Model restored.")
config.log_device_placement = False
ops = {'pointclouds_pl': pointclouds_pl,
'labels_pl': labels_pl,
'is_training_pl': is_training_pl,
'pred': pred,
'loss': loss,
'train_op': train_op,
'merged': merged,
'step': batch}
for epoch in range(MAX_EPOCH):
log_string('**** EPOCH %03d ****' % (epoch))
sys.stdout.flush()
train_one_epoch(sess, ops, train_writer)
eval_one_epoch(sess, ops, test_writer)
# Save the variables to disk.
if epoch % 10 == 0:
save_path = saver.save(sess, os.path.join(LOG_DIR, "model.ckpt"))
log_string("Model saved in file: %s" % save_path)
def train_one_epoch(sess, ops, train_writer):
""" ops: dict mapping from string to tf ops """
is_training = True
# Shuffle train files
train_file_idxs = np.arange(0, len(TRAIN_FILES))
np.random.shuffle(train_file_idxs)
for fn in range(len(TRAIN_FILES)):
log_string('----' + str(fn) + '-----')
current_data, current_label = provider.loadDataFile(TRAIN_FILES[train_file_idxs[fn]])
current_data = current_data[:,0:NUM_POINT,:]
current_data, current_label, _ = provider.shuffle_data(current_data, np.squeeze(current_label))
current_label = np.squeeze(current_label)
file_size = current_data.shape[0]
num_batches = file_size // BATCH_SIZE
total_correct = 0
total_seen = 0
loss_sum = 0
for batch_idx in range(num_batches):
start_idx = batch_idx * BATCH_SIZE
end_idx = (batch_idx+1) * BATCH_SIZE
# Augment batched point clouds by rotation and jittering
rotated_data = provider.rotate_point_cloud(current_data[start_idx:end_idx, :, :])
jittered_data = provider.jitter_point_cloud(rotated_data)
feed_dict = {ops['pointclouds_pl']: jittered_data,
ops['labels_pl']: current_label[start_idx:end_idx],
ops['is_training_pl']: is_training,}
summary, step, _, loss_val, pred_val = sess.run([ops['merged'], ops['step'],
ops['train_op'], ops['loss'], ops['pred']], feed_dict=feed_dict)
train_writer.add_summary(summary, step)
pred_val = np.argmax(pred_val, 1)
correct = np.sum(pred_val == current_label[start_idx:end_idx])
total_correct += correct
total_seen += BATCH_SIZE
loss_sum += loss_val
log_string('total_correct: %d' % total_correct)
log_string('total_seen: %d' % total_seen)
log_string('file size: %d' % file_size)
log_string('mean loss: %f' % (loss_sum / float(num_batches)))
log_string('accuracy: %f' % (total_correct / float(total_seen)))
def eval_one_epoch(sess, ops, test_writer):
""" ops: dict mapping from string to tf ops """
is_training = False
total_correct = 0
total_seen = 0
loss_sum = 0
total_seen_class = [0 for _ in range(NUM_CLASSES)]
total_correct_class = [0 for _ in range(NUM_CLASSES)]
for fn in range(len(TEST_FILES)):
log_string('----' + str(fn) + '-----')
current_data, current_label = provider.loadDataFile(TEST_FILES[fn])
current_data = current_data[:,0:NUM_POINT,:]
current_label = np.squeeze(current_label)
file_size = current_data.shape[0]
num_batches = file_size // BATCH_SIZE
for batch_idx in range(num_batches):
start_idx = batch_idx * BATCH_SIZE
end_idx = (batch_idx+1) * BATCH_SIZE
feed_dict = {ops['pointclouds_pl']: current_data[start_idx:end_idx, :, :],
ops['labels_pl']: current_label[start_idx:end_idx],
ops['is_training_pl']: is_training}
summary, step, loss_val, pred_val = sess.run([ops['merged'], ops['step'],
ops['loss'], ops['pred']], feed_dict=feed_dict)
pred_val = np.argmax(pred_val, 1)
correct = np.sum(pred_val == current_label[start_idx:end_idx])
total_correct += correct
total_seen += BATCH_SIZE
loss_sum += (loss_val*BATCH_SIZE)
for i in range(start_idx, end_idx):
l = current_label[i]
total_seen_class[l] += 1
total_correct_class[l] += (pred_val[i-start_idx] == l)
log_string('eval mean loss: %f' % (loss_sum / float(total_seen)))
log_string('eval accuracy: %f'% (total_correct / float(total_seen)))
log_string('eval avg class acc: %f' % (np.mean(np.array(total_correct_class)/np.array(total_seen_class,dtype=np.float))))
if __name__ == "__main__":
train()
LOG_FOUT.close()
可看到,训练第一步的第一次批次精度就能到达0.93多了。

博主有逐步debug过,对其里面的机制还是了解的,感兴趣的童鞋可以自行去分析下,值得去做这样的事情。
2.分类网络预测
博主简化了下evaluate.py文件中的代码(之前的代码里是批量对测试图片进行预测,并统计分析结果),只预测一张图片,并显示预测的图片及结果,代码如下:
import tensorflow.compat.v1 as tf
tf.compat.v1.disable_eager_execution()
import numpy as np
import argparse
import socket
import importlib
import time
import os
import scipy.misc
import sys
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
sys.path.append(BASE_DIR)
sys.path.append(os.path.join(BASE_DIR, 'models'))
sys.path.append(os.path.join(BASE_DIR, 'utils'))
import provider
import pc_util
from matplotlib import pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
parser = argparse.ArgumentParser()
parser.add_argument('--gpu', type=int, default=0, help='GPU to use [default: GPU 0]')
parser.add_argument('--model', default='pointnet_cls', help='Model name: pointnet_cls or pointnet_cls_basic [default: pointnet_cls]')
parser.add_argument('--batch_size', type=int, default=1, help='Batch Size during training [default: 1]')
parser.add_argument('--num_point', type=int, default=1024, help='Point Number [256/512/1024/2048] [default: 1024]')
parser.add_argument('--model_path', default='log/model.ckpt', help='model checkpoint file path [default: log/model.ckpt]')
parser.add_argument('--dump_dir', default='dump', help='dump folder path [dump]')
parser.add_argument('--visu', action='store_true', help='Whether to dump image for error case [default: False]')
FLAGS = parser.parse_args()
BATCH_SIZE = FLAGS.batch_size
NUM_POINT = FLAGS.num_point
MODEL_PATH = FLAGS.model_path
GPU_INDEX = FLAGS.gpu
MODEL = importlib.import_module(FLAGS.model) # import network module
DUMP_DIR = FLAGS.dump_dir
if not os.path.exists(DUMP_DIR): os.mkdir(DUMP_DIR)
LOG_FOUT = open(os.path.join(DUMP_DIR, 'log_evaluate.txt'), 'w')
LOG_FOUT.write(str(FLAGS)+'\n')
NUM_CLASSES = 40
SHAPE_NAMES = [line.rstrip() for line in \
open(os.path.join(BASE_DIR, 'data/modelnet40_ply_hdf5_2048/shape_names.txt'))]
HOSTNAME = socket.gethostname()
# ModelNet40 official train/test split
TRAIN_FILES = provider.getDataFiles( \
os.path.join(BASE_DIR, 'data/modelnet40_ply_hdf5_2048/train_files.txt'))
TEST_FILES = provider.getDataFiles(\
os.path.join(BASE_DIR, 'data/modelnet40_ply_hdf5_2048/test_files.txt'))
def log_string(out_str):
LOG_FOUT.write(out_str+'\n')
LOG_FOUT.flush()
print(out_str)
def evaluate(num_votes):
is_training = False
with tf.device('/gpu:'+str(GPU_INDEX)):
pointclouds_pl, labels_pl = MODEL.placeholder_inputs(BATCH_SIZE, NUM_POINT)
is_training_pl = tf.placeholder(tf.bool, shape=())
# simple model
pred, end_points = MODEL.get_model(pointclouds_pl, is_training_pl)
loss = MODEL.get_loss(pred, labels_pl, end_points)
# Add ops to save and restore all the variables.
saver = tf.train.Saver()
# Create a session
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
config.allow_soft_placement = True
config.log_device_placement = True
sess = tf.Session(config=config)
# Restore variables from disk.
saver.restore(sess, MODEL_PATH)
log_string("Model restored.")
ops = {'pointclouds_pl': pointclouds_pl,
'labels_pl': labels_pl,
'is_training_pl': is_training_pl,
'pred': pred,
'loss': loss}
eval_one_epoch(sess, ops, num_votes)
def eval_one_epoch(sess, ops, num_votes=1, topk=1):
error_cnt = 0
is_training = False
total_correct = 0
total_seen = 0
loss_sum = 0
total_seen_class = [0 for _ in range(NUM_CLASSES)]
total_correct_class = [0 for _ in range(NUM_CLASSES)]
fout = open(os.path.join(DUMP_DIR, 'pred_label.txt'), 'w')
current_data, current_label = provider.loadDataFile(TEST_FILES[0])
current_label = np.squeeze(current_label)
# predict a pointcloud
object_index = 1111
current_data = current_data[object_index:object_index+1, 0:NUM_POINT, :]
feed_dict = {ops['pointclouds_pl']: current_data,
ops['labels_pl']: current_label[object_index:object_index+1],
ops['is_training_pl']: is_training}
loss_val, pred_val = sess.run([ops['loss'], ops['pred']], feed_dict=feed_dict)
pred_val = np.argmax(pred_val, 1)
fig = plt.figure(figsize=(15, 10))
ax = fig.add_subplot(1, 1, 1, projection="3d")
ax.scatter(current_data[:,:,0], current_data[:, :, 1], current_data[:, :, 2])
ax.set_title("label: {:}, pred: {:}".format(SHAPE_NAMES[current_label[object_index]], SHAPE_NAMES[pred_val[0]]))
ax.set_axis_off()
plt.show()
if __name__=='__main__':
with tf.Graph().as_default():
evaluate(num_votes=1)
LOG_FOUT.close()
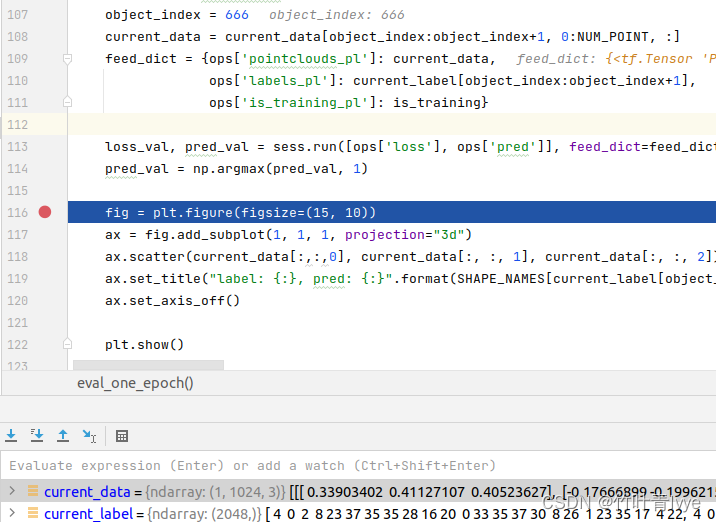
运行结果如下:

若object_index设直888,则预测结果如下:

可看到这两份点云都分类预测正确。
附:也可以用Open3D来显示点云,Open3D的使用可参考博主之前的博客:
pycharm配置PyQt5、Open3D、Python-pcl_pyqt5 open3d_竹叶青lvye的博客-CSDN博客
这里博主使用的是open3d_python-0.3.0.0-py2.py3-none-any.whl安装包,python环境是3.6,如下代码来可视化上面ply_data_test0.h5中的数据
import os
import sys
import numpy as np
import h5py
import open3d as o3d
def load_h5(h5_filename):
f = h5py.File(h5_filename)
data = f['data'][:]
label = f['label'][:]
return (data, label)
if __name__ == '__main__':
current_data, current_label = load_h5("ply_data_test0.h5")
pcd = o3d.PointCloud()
object_index = 1111
pcd.points = o3d.Vector3dVector(current_data[object_index:object_index+1,:,:].reshape(-1,3))
o3d.draw_geometries([pcd])

工程目录结构
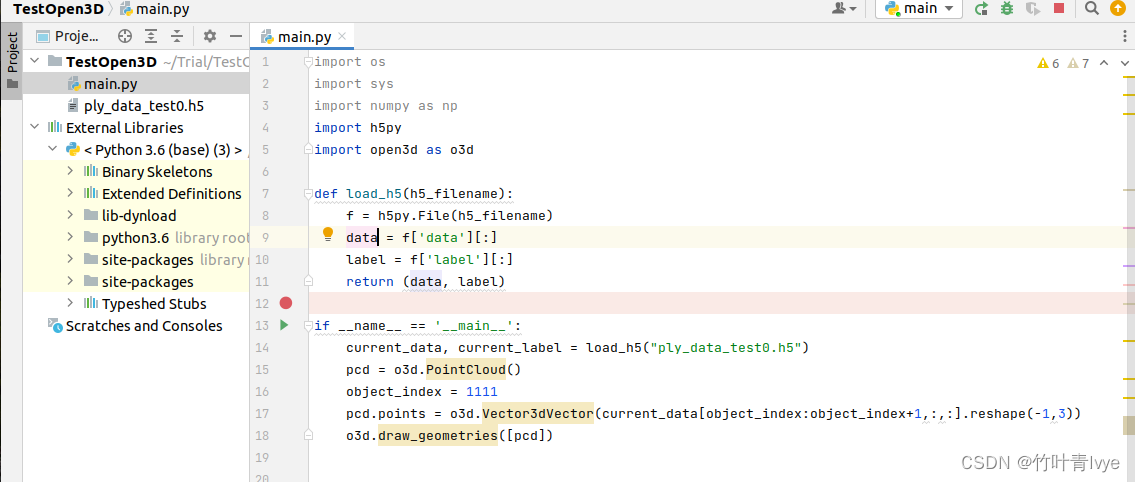
运行结果如下:

如下代码是带指定颜色的(对各点)来显示点云
import os
import sys
import numpy as np
import h5py
import open3d as o3d
def load_h5(h5_filename):
f = h5py.File(h5_filename)
data = f['data'][:]
label = f['label'][:]
return (data, label)
if __name__ == '__main__':
current_data, current_label = load_h5("ply_data_test0.h5")
pcd = o3d.PointCloud()
object_index = 1111
pcd.points = o3d.Vector3dVector(current_data[object_index:object_index+1,:,:].reshape(-1,3))
colors = []
for i in range(2048):
colors.append([0,0,255])
pcd.colors = o3d.Vector3dVector(colors)
o3d.draw_geometries([pcd])
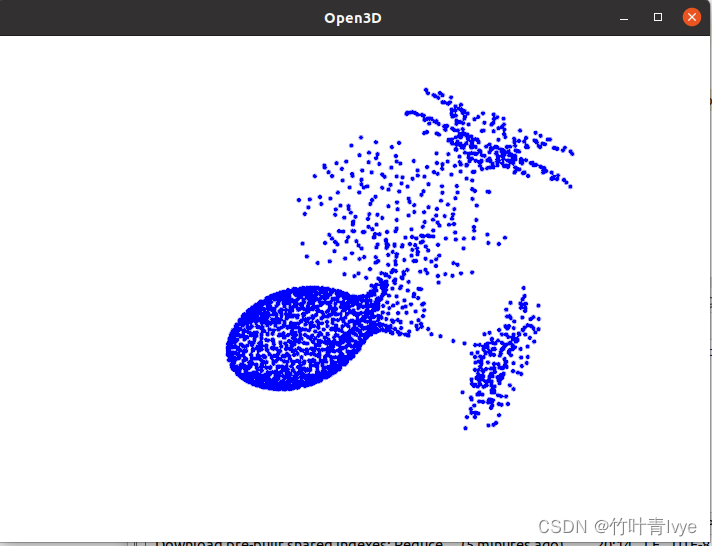
二. 点云分割和预测
1.训练语义分割网络
首先下载训练集,路径可以从sem_seg目录下的download_data.sh中找到,也可以手动到如下网页上下载
https://shapenet.cs.stanford.edu/media/indoor3d_sem_seg_hdf5_data.zip
下载完毕后博主放在工程的如下目录下
博主修改了sem_seg目录下的train.py(因为显存原因,博主这边对每份点云随机抽取了1024个点云来训练网络),代码如下:
import tensorflow.compat.v1 as tf
tf.compat.v1.disable_eager_execution()
import argparse
import math
import h5py
import numpy as np
import socket
import os
import sys
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
ROOT_DIR = os.path.dirname(BASE_DIR)
sys.path.append(BASE_DIR)
sys.path.append(ROOT_DIR)
sys.path.append(os.path.join(ROOT_DIR, 'utils'))
import provider
import tf_util
from model import *
parser = argparse.ArgumentParser()
parser.add_argument('--gpu', type=int, default=0, help='GPU to use [default: GPU 0]')
parser.add_argument('--log_dir', default='log', help='Log dir [default: log]')
parser.add_argument('--num_point', type=int, default=1024, help='Point number [default: 4096]')
parser.add_argument('--max_epoch', type=int, default=50, help='Epoch to run [default: 50]')
parser.add_argument('--batch_size', type=int, default=2, help='Batch Size during training [default: 24]')
parser.add_argument('--learning_rate', type=float, default=0.001, help='Initial learning rate [default: 0.001]')
parser.add_argument('--momentum', type=float, default=0.9, help='Initial learning rate [default: 0.9]')
parser.add_argument('--optimizer', default='adam', help='adam or momentum [default: adam]')
parser.add_argument('--decay_step', type=int, default=300000, help='Decay step for lr decay [default: 300000]')
parser.add_argument('--decay_rate', type=float, default=0.5, help='Decay rate for lr decay [default: 0.5]')
parser.add_argument('--test_area', type=int, default=6, help='Which area to use for test, option: 1-6 [default: 6]')
FLAGS = parser.parse_args()
BATCH_SIZE = FLAGS.batch_size
NUM_POINT = FLAGS.num_point
MAX_EPOCH = FLAGS.max_epoch
NUM_POINT = FLAGS.num_point
BASE_LEARNING_RATE = FLAGS.learning_rate
GPU_INDEX = FLAGS.gpu
MOMENTUM = FLAGS.momentum
OPTIMIZER = FLAGS.optimizer
DECAY_STEP = FLAGS.decay_step
DECAY_RATE = FLAGS.decay_rate
LOG_DIR = FLAGS.log_dir
if not os.path.exists(LOG_DIR): os.mkdir(LOG_DIR)
os.system('cp model.py %s' % (LOG_DIR)) # bkp of model def
os.system('cp train.py %s' % (LOG_DIR)) # bkp of train procedure
LOG_FOUT = open(os.path.join(LOG_DIR, 'log_train.txt'), 'w')
LOG_FOUT.write(str(FLAGS)+'\n')
MAX_NUM_POINT = 4096
NUM_CLASSES = 13
BN_INIT_DECAY = 0.5
BN_DECAY_DECAY_RATE = 0.5
#BN_DECAY_DECAY_STEP = float(DECAY_STEP * 2)
BN_DECAY_DECAY_STEP = float(DECAY_STEP)
BN_DECAY_CLIP = 0.99
HOSTNAME = socket.gethostname()
ALL_FILES = provider.getDataFiles('indoor3d_sem_seg_hdf5_data/all_files.txt')
room_filelist = [line.rstrip() for line in open('indoor3d_sem_seg_hdf5_data/room_filelist.txt')]
# Load ALL data
data_batch_list = []
label_batch_list = []
for h5_filename in ALL_FILES:
data_batch, label_batch = provider.loadDataFile(h5_filename)
data_batch_list.append(data_batch)
label_batch_list.append(label_batch)
data_batches = np.concatenate(data_batch_list, 0)
label_batches = np.concatenate(label_batch_list, 0)
print(data_batches.shape)
print(label_batches.shape)
test_area = 'Area_'+str(FLAGS.test_area)
train_idxs = []
test_idxs = []
for i,room_name in enumerate(room_filelist):
if test_area in room_name:
test_idxs.append(i)
else:
train_idxs.append(i)
train_data = data_batches[train_idxs,...]
train_label = label_batches[train_idxs]
test_data = data_batches[test_idxs,...]
test_label = label_batches[test_idxs]
print(train_data.shape, train_label.shape)
print(test_data.shape, test_label.shape)
def log_string(out_str):
LOG_FOUT.write(out_str+'\n')
LOG_FOUT.flush()
print(out_str)
def get_learning_rate(batch):
learning_rate = tf.train.exponential_decay(
BASE_LEARNING_RATE, # Base learning rate.
batch * BATCH_SIZE, # Current index into the dataset.
DECAY_STEP, # Decay step.
DECAY_RATE, # Decay rate.
staircase=True)
learning_rate = tf.maximum(learning_rate, 0.00001) # CLIP THE LEARNING RATE!!
return learning_rate
def get_bn_decay(batch):
bn_momentum = tf.train.exponential_decay(
BN_INIT_DECAY,
batch*BATCH_SIZE,
BN_DECAY_DECAY_STEP,
BN_DECAY_DECAY_RATE,
staircase=True)
bn_decay = tf.minimum(BN_DECAY_CLIP, 1 - bn_momentum)
return bn_decay
def train():
with tf.Graph().as_default():
with tf.device('/gpu:'+str(GPU_INDEX)):
pointclouds_pl, labels_pl = placeholder_inputs(BATCH_SIZE, NUM_POINT)
is_training_pl = tf.placeholder(tf.bool, shape=())
# Note the global_step=batch parameter to minimize.
# That tells the optimizer to helpfully increment the 'batch' parameter for you every time it trains.
batch = tf.Variable(0)
bn_decay = get_bn_decay(batch)
tf.summary.scalar('bn_decay', bn_decay)
# Get model and loss
pred = get_model(pointclouds_pl, is_training_pl, bn_decay=bn_decay)
loss = get_loss(pred, labels_pl)
tf.summary.scalar('loss', loss)
correct = tf.equal(tf.argmax(pred, 2), tf.to_int64(labels_pl))
accuracy = tf.reduce_sum(tf.cast(correct, tf.float32)) / float(BATCH_SIZE*NUM_POINT)
tf.summary.scalar('accuracy', accuracy)
# Get training operator
learning_rate = get_learning_rate(batch)
tf.summary.scalar('learning_rate', learning_rate)
if OPTIMIZER == 'momentum':
optimizer = tf.train.MomentumOptimizer(learning_rate, momentum=MOMENTUM)
elif OPTIMIZER == 'adam':
optimizer = tf.train.AdamOptimizer(learning_rate)
train_op = optimizer.minimize(loss, global_step=batch)
# Add ops to save and restore all the variables.
saver = tf.train.Saver()
# Create a session
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
config.allow_soft_placement = True
config.log_device_placement = True
sess = tf.Session(config=config)
# Add summary writers
merged = tf.summary.merge_all()
train_writer = tf.summary.FileWriter(os.path.join(LOG_DIR, 'train'),
sess.graph)
test_writer = tf.summary.FileWriter(os.path.join(LOG_DIR, 'test'))
# Init variables
init = tf.global_variables_initializer()
sess.run(init, {is_training_pl:True})
ops = {'pointclouds_pl': pointclouds_pl,
'labels_pl': labels_pl,
'is_training_pl': is_training_pl,
'pred': pred,
'loss': loss,
'train_op': train_op,
'merged': merged,
'step': batch}
for epoch in range(MAX_EPOCH):
log_string('**** EPOCH %03d ****' % (epoch))
sys.stdout.flush()
train_one_epoch(sess, ops, train_writer)
eval_one_epoch(sess, ops, test_writer)
# Save the variables to disk.
if epoch % 10 == 0:
save_path = saver.save(sess, os.path.join(LOG_DIR, "model.ckpt"))
log_string("Model saved in file: %s" % save_path)
def train_one_epoch(sess, ops, train_writer):
""" ops: dict mapping from string to tf ops """
is_training = True
log_string('----')
current_data, current_label, _ = provider.shuffle_data(train_data, train_label)
current_data = current_data[:,0:NUM_POINT,:]
current_label = current_label[:,0:NUM_POINT]
file_size = current_data.shape[0]
num_batches = file_size // BATCH_SIZE
total_correct = 0
total_seen = 0
loss_sum = 0
for batch_idx in range(num_batches):
if batch_idx % 100 == 0:
print('Current batch/total batch num: %d/%d'%(batch_idx,num_batches))
start_idx = batch_idx * BATCH_SIZE
end_idx = (batch_idx+1) * BATCH_SIZE
feed_dict = {ops['pointclouds_pl']: current_data[start_idx:end_idx, :, :],
ops['labels_pl']: current_label[start_idx:end_idx],
ops['is_training_pl']: is_training,}
summary, step, _, loss_val, pred_val = sess.run([ops['merged'], ops['step'], ops['train_op'], ops['loss'], ops['pred']],
feed_dict=feed_dict)
train_writer.add_summary(summary, step)
pred_val = np.argmax(pred_val, 2)
correct = np.sum(pred_val == current_label[start_idx:end_idx])
total_correct += correct
total_seen += (BATCH_SIZE*NUM_POINT)
loss_sum += loss_val
log_string('mean loss: %f' % (loss_sum / float(num_batches)))
log_string('accuracy: %f' % (total_correct / float(total_seen)))
def eval_one_epoch(sess, ops, test_writer):
""" ops: dict mapping from string to tf ops """
is_training = False
total_correct = 0
total_seen = 0
loss_sum = 0
total_seen_class = [0 for _ in range(NUM_CLASSES)]
total_correct_class = [0 for _ in range(NUM_CLASSES)]
log_string('----')
current_data, current_label, _ = provider.shuffle_data(test_data, test_label)
current_data = current_data[:, 0:NUM_POINT, :]
current_label = current_label[:, 0:NUM_POINT]
current_label = np.squeeze(current_label)
file_size = current_data.shape[0]
num_batches = file_size // BATCH_SIZE
for batch_idx in range(num_batches):
start_idx = batch_idx * BATCH_SIZE
end_idx = (batch_idx+1) * BATCH_SIZE
feed_dict = {ops['pointclouds_pl']: current_data[start_idx:end_idx, :, :],
ops['labels_pl']: current_label[start_idx:end_idx],
ops['is_training_pl']: is_training}
summary, step, loss_val, pred_val = sess.run([ops['merged'], ops['step'], ops['loss'], ops['pred']],
feed_dict=feed_dict)
test_writer.add_summary(summary, step)
pred_val = np.argmax(pred_val, 2)
correct = np.sum(pred_val == current_label[start_idx:end_idx])
total_correct += correct
total_seen += (BATCH_SIZE*NUM_POINT)
loss_sum += (loss_val*BATCH_SIZE)
for i in range(start_idx, end_idx):
for j in range(NUM_POINT):
l = current_label[i, j]
total_seen_class[l] += 1
total_correct_class[l] += (pred_val[i-start_idx, j] == l)
log_string('eval mean loss: %f' % (loss_sum / float(total_seen/NUM_POINT)))
log_string('eval accuracy: %f'% (total_correct / float(total_seen)))
log_string('eval avg class acc: %f' % (np.mean(np.array(total_correct_class)/np.array(total_seen_class,dtype=np.float))))
if __name__ == "__main__":
train()
LOG_FOUT.close()
运行train.py文件便进入训练阶段(博主训练了12小时左右)
前面点云分类,对应每份点云数据是一个类别信息。参考图像语义分割(像素级分割),这里的点云中的每个点都应该有个类别标签,我们debug看一下。可看到对应于data_batches的label_batches,其维度是23585*4096,因为有23585份点云数据,4096就对应一份点云中每个点的标签信息。同时也看到一份点云中每个点的label值是不一样的,所以训练的时候是拿的各场景下的实际点云数据来训练的(将房间的点云数据划分为1 m × 1 m 的块,从各块中随机抽取4096个点)

2. 点云分割网络预测
(1)npy数据准备
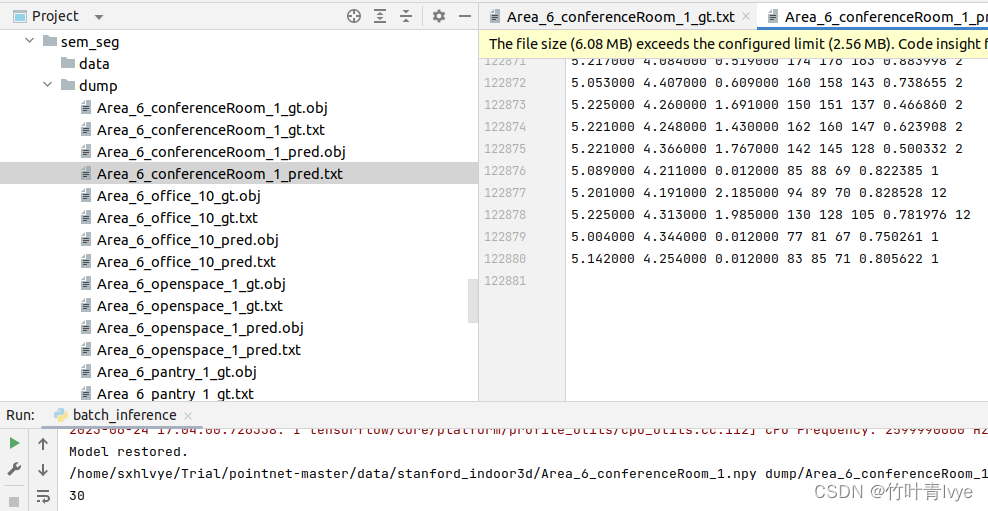
源代码并不是用的前面indoor3d_sem_seg_hdf5_data中的h5数据来做预测(虽然h5文件中包含了点云和label标签信息,以能去判断预测结果和ground true是不是一致),拿的是点云的npy格式数据来做预测的。那么我们就要生成一份npy数据出来。博主这里只对Stanford3dDataset_v1.2_Aligned_Version数据集(底部附注中有对该数据集做介绍)中的Area_6生成一份npy。可运行collect_indoor3d_data.py文件开完成。博主的数据集放置在工程中的如下位置
debug可看到,此份点云数据points有7090个点,每个点有6维来表示。labels则有7090维,对应每一个点的标签。合并后的points_list中的元素维度则变为了7090*7,相较于之前的原始数据,这里多了一个标签信息。
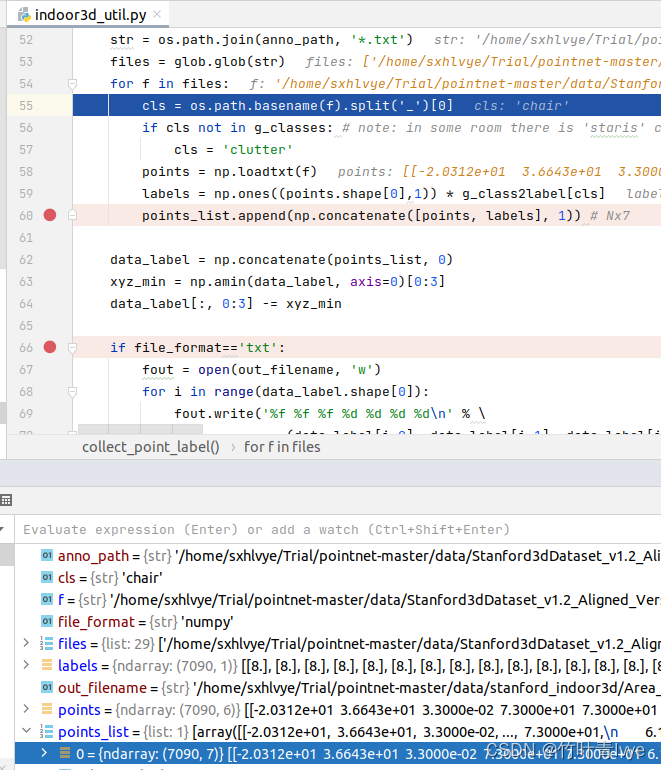
同时为了节省时间(这里的初衷只是为了跑通一下源码),所以只对Area_6中的四份Annotions中的数据做转换。所以all_data_label.txt中的文本修改为如下:
Area_6_conferenceRoom_1.npy
Area_6_office_10.npy
Area_6_openspace_1.npy
Area_6_pantry_1.npy
anno_paths.txt中的文本修改为如下:
Area_6/conferenceRoom_1/Annotations
Area_6/office_10/Annotations
Area_6/openspace_1/Annotations
Area_6/pantry_1/Annotations
area6_data_label.txt中的文本修改为如下:
data/stanford_indoor3d/Area_6_conferenceRoom_1.npy
data/stanford_indoor3d/Area_6_office_10.npy
data/stanford_indoor3d/Area_6_openspace_1.npy
data/stanford_indoor3d/Area_6_pantry_1.npy
运行collect_indoor3d_data.py文件,结果如下:

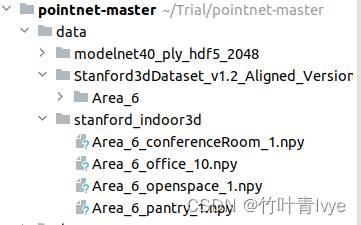
可看到生成的四份npy文件,每一份npy文件都是对应场景下Annotations中所有文件中点云拼接的数据(同时包含了label信息)。这么费劲做,而不是直接读那个和Annotations文件夹并列的完整点云数据(是原始数据,不含有标签信息),就是为了获得每个点的标签信息。
(2)预测
博主这边简单修改了下batch_inference.py文件中的代码,如下:
import tensorflow.compat.v1 as tf
tf.compat.v1.disable_eager_execution()
import argparse
import os
import sys
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
ROOT_DIR = os.path.dirname(BASE_DIR)
sys.path.append(BASE_DIR)
from model import *
import indoor3d_util
parser = argparse.ArgumentParser()
parser.add_argument('--gpu', type=int, default=0, help='GPU to use [default: GPU 0]')
parser.add_argument('--batch_size', type=int, default=1, help='Batch Size during training [default: 1]')
parser.add_argument('--num_point', type=int, default=4096, help='Point number [default: 4096]')
parser.add_argument('--model_path', default='log/model.ckpt', help='model checkpoint file path')
parser.add_argument('--dump_dir', default='dump', help='dump folder path')
parser.add_argument('--output_filelist', default='output.txt', help='TXT filename, filelist, each line is an output for a room')
parser.add_argument('--room_data_filelist', default='meta/area6_data_label.txt', help='TXT filename, filelist, each line is a test room data label file.')
parser.add_argument('--no_clutter', action='store_true', help='If true, donot count the clutter class')
parser.add_argument('--visu', default='true', help='Whether to output OBJ file for prediction visualization.')
FLAGS = parser.parse_args()
BATCH_SIZE = FLAGS.batch_size
NUM_POINT = FLAGS.num_point
MODEL_PATH = FLAGS.model_path
GPU_INDEX = FLAGS.gpu
DUMP_DIR = FLAGS.dump_dir
if not os.path.exists(DUMP_DIR): os.mkdir(DUMP_DIR)
LOG_FOUT = open(os.path.join(DUMP_DIR, 'log_evaluate.txt'), 'w')
LOG_FOUT.write(str(FLAGS)+'\n')
ROOM_PATH_LIST = [os.path.join(ROOT_DIR,line.rstrip()) for line in open(FLAGS.room_data_filelist)]
NUM_CLASSES = 13
def log_string(out_str):
LOG_FOUT.write(out_str+'\n')
LOG_FOUT.flush()
print(out_str)
def evaluate():
is_training = False
with tf.device('/gpu:'+str(GPU_INDEX)):
pointclouds_pl, labels_pl = placeholder_inputs(BATCH_SIZE, NUM_POINT)
is_training_pl = tf.placeholder(tf.bool, shape=())
# simple model
pred = get_model(pointclouds_pl, is_training_pl)
loss = get_loss(pred, labels_pl)
pred_softmax = tf.nn.softmax(pred)
# Add ops to save and restore all the variables.
saver = tf.train.Saver()
# Create a session
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
config.allow_soft_placement = True
config.log_device_placement = True
sess = tf.Session(config=config)
# Restore variables from disk.
saver.restore(sess, MODEL_PATH)
log_string("Model restored.")
ops = {'pointclouds_pl': pointclouds_pl,
'labels_pl': labels_pl,
'is_training_pl': is_training_pl,
'pred': pred,
'pred_softmax': pred_softmax,
'loss': loss}
total_correct = 0
total_seen = 0
fout_out_filelist = open(FLAGS.output_filelist, 'w')
for room_path in ROOM_PATH_LIST:
out_data_label_filename = os.path.basename(room_path)[:-4] + '_pred.txt'
out_data_label_filename = os.path.join(DUMP_DIR, out_data_label_filename)
out_gt_label_filename = os.path.basename(room_path)[:-4] + '_gt.txt'
out_gt_label_filename = os.path.join(DUMP_DIR, out_gt_label_filename)
print(room_path, out_data_label_filename)
a, b = eval_one_epoch(sess, ops, room_path, out_data_label_filename, out_gt_label_filename)
total_correct += a
total_seen += b
fout_out_filelist.write(out_data_label_filename+'\n')
fout_out_filelist.close()
log_string('all room eval accuracy: %f'% (total_correct / float(total_seen)))
def eval_one_epoch(sess, ops, room_path, out_data_label_filename, out_gt_label_filename):
error_cnt = 0
is_training = False
total_correct = 0
total_seen = 0
loss_sum = 0
total_seen_class = [0 for _ in range(NUM_CLASSES)]
total_correct_class = [0 for _ in range(NUM_CLASSES)]
if FLAGS.visu:
fout = open(os.path.join(DUMP_DIR, os.path.basename(room_path)[:-4]+'_pred.obj'), 'w')
fout_gt = open(os.path.join(DUMP_DIR, os.path.basename(room_path)[:-4]+'_gt.obj'), 'w')
fout_data_label = open(out_data_label_filename, 'w')
fout_gt_label = open(out_gt_label_filename, 'w')
current_data, current_label = indoor3d_util.room2blocks_wrapper_normalized(room_path, NUM_POINT)
current_data = current_data[:,0:NUM_POINT,:]
current_label = np.squeeze(current_label)
# Get room dimension..
data_label = np.load(room_path)
data = data_label[:,0:6]
max_room_x = max(data[:,0])
max_room_y = max(data[:,1])
max_room_z = max(data[:,2])
file_size = current_data.shape[0]
num_batches = file_size // BATCH_SIZE
print(file_size)
for batch_idx in range(num_batches):
start_idx = batch_idx * BATCH_SIZE
end_idx = (batch_idx+1) * BATCH_SIZE
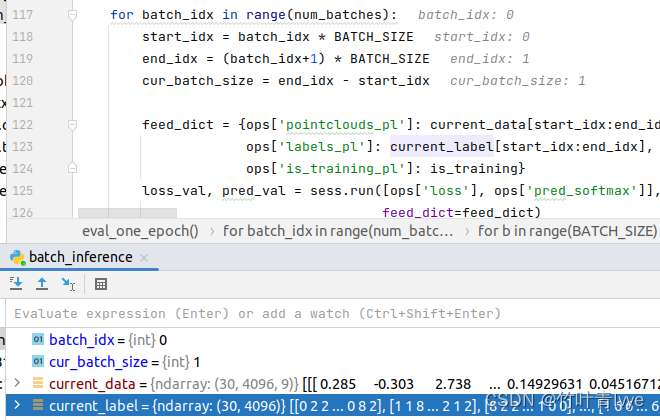
cur_batch_size = end_idx - start_idx
feed_dict = {ops['pointclouds_pl']: current_data[start_idx:end_idx, :, :],
ops['labels_pl']: current_label[start_idx:end_idx],
ops['is_training_pl']: is_training}
loss_val, pred_val = sess.run([ops['loss'], ops['pred_softmax']],
feed_dict=feed_dict)
if FLAGS.no_clutter:
pred_label = np.argmax(pred_val[:,:,0:12], 2) # BxN
else:
pred_label = np.argmax(pred_val, 2) # BxN
# Save prediction labels to OBJ file
for b in range(BATCH_SIZE):
pts = current_data[start_idx+b, :, :]
l = current_label[start_idx+b,:]
pts[:,6] *= max_room_x
pts[:,7] *= max_room_y
pts[:,8] *= max_room_z
pts[:,3:6] *= 255.0
pred = pred_label[b, :]
for i in range(NUM_POINT):
color = indoor3d_util.g_label2color[pred[i]]
color_gt = indoor3d_util.g_label2color[current_label[start_idx+b, i]]
if FLAGS.visu:
fout.write('v %f %f %f %d %d %d\n' % (pts[i,6], pts[i,7], pts[i,8], color[0], color[1], color[2]))
fout_gt.write('v %f %f %f %d %d %d\n' % (pts[i,6], pts[i,7], pts[i,8], color_gt[0], color_gt[1], color_gt[2]))
fout_data_label.write('%f %f %f %d %d %d %f %d\n' % (pts[i,6], pts[i,7], pts[i,8], pts[i,3], pts[i,4], pts[i,5], pred_val[b,i,pred[i]], pred[i]))
fout_gt_label.write('%d\n' % (l[i]))
correct = np.sum(pred_label == current_label[start_idx:end_idx,:])
total_correct += correct
total_seen += (cur_batch_size*NUM_POINT)
loss_sum += (loss_val*BATCH_SIZE)
for i in range(start_idx, end_idx):
for j in range(NUM_POINT):
l = current_label[i, j]
total_seen_class[l] += 1
total_correct_class[l] += (pred_label[i-start_idx, j] == l)
log_string('eval mean loss: %f' % (loss_sum / float(total_seen/NUM_POINT)))
log_string('eval accuracy: %f'% (total_correct / float(total_seen)))
fout_data_label.close()
fout_gt_label.close()
if FLAGS.visu:
fout.close()
fout_gt.close()
return total_correct, total_seen
if __name__=='__main__':
with tf.Graph().as_default():
evaluate()
LOG_FOUT.close()
来对上面生成的四份npy数据做预测,执行结果如下:

生成的结果数据在dump文件夹下

详情过程可以debug去看,大概过程就是先加载npy文件,然后做数据和标签的拆分,然后对数据部分(点表示为6维)进行1mm*1mm的分块并采样(一个分块中随机采样4096个点),同时点的表示由之前的(x,y,z,r,g,b)转换为(x,y,z,r,g,b,x',y',z'),后3个是x,y,z相对于整体空间归一化的空间坐标。然后对所有块中的数据做预测,并把所有块预测的结果(x',y',z', r',g',b')写到obj中(带pred关键字的obj), 其中x',y',z'就是前面归一化的空间坐标,r' , g' , b'是有对应各标签对应的颜色索引值。同时,也保存了ground truth的结果,这样视觉上课直观做比较。如下是debug的记录结果:

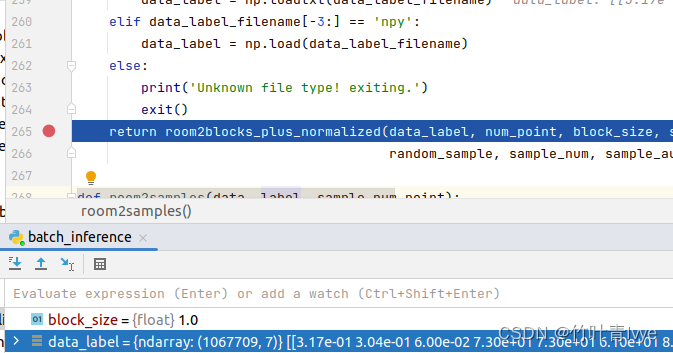

这边可以看到对点云随机取点采样的代码
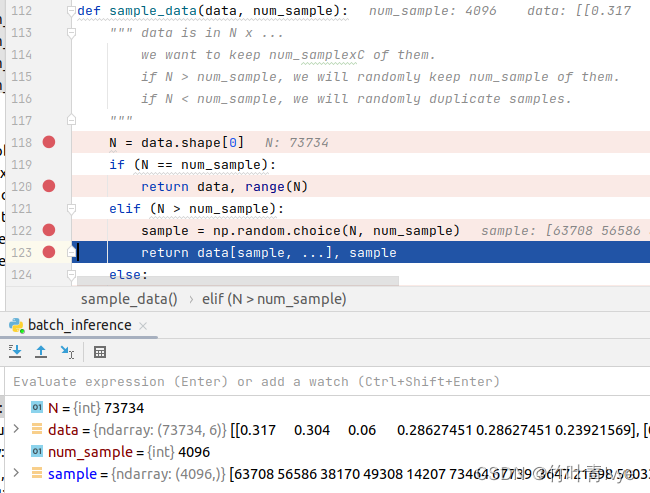
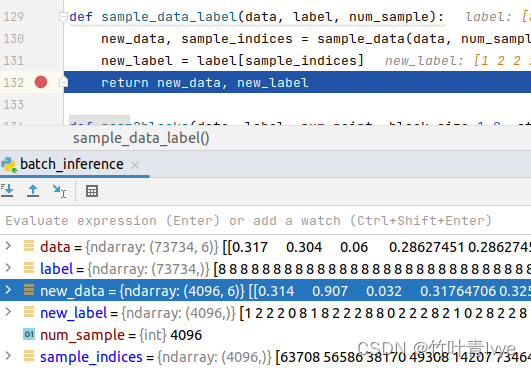
从保存的预测结果数据也可以看出每份点云是抽取了4096个点,所以30份点云文件共对应4096*30=122880个点。


上传下这份点云语义分割的工程,链接如下:
链接: https://pan.baidu.com/s/18xdS-VYHaFCK69hPLpujYw 提取码: cbqe
接下来,我们来可视化下obj文件,以来对比预测结果和ground truth
(3)可视化obj,对比预测结果和ground truth
->使用meshlab可视化
如下语句即可安装meshlab
sudo apt-get install meshlab显示Area_6_openspace_1_gt.obj

显示Area_6_openspace_1_pred.obj

->使用cloudcompare可视化
如下语句即可安装
sudo apt-get install cloudcompare
cloudcompare的使用可以参考博主之前的博客
CloudCompare配置介绍_cloudcompare二次开发_竹叶青lvye的博客-CSDN博客
CloudCompare中PLC插件开发介绍_cloudcompare 插件_竹叶青lvye的博客-CSDN博客
但是丢失了颜色标签信息。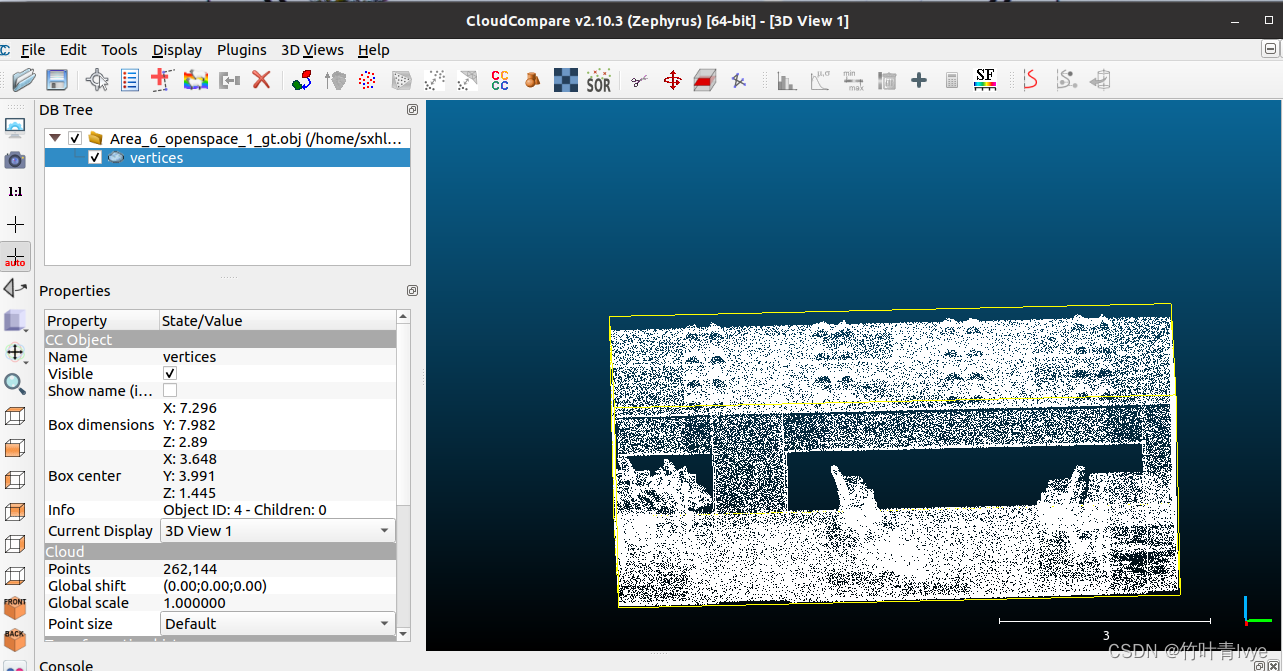
三. 部件分割和预测
1. 训练
首先下载训练集,路径可以从part_seg目录下的download_data.sh中找到,也可以手动到如下网页上下载
https://shapenet.cs.stanford.edu/media/shapenet_part_seg_hdf5_data.zip
https://shapenet.cs.stanford.edu/ericyi/shapenetcore_partanno_v0.zip
下载完毕后,博主放在如下目录结构

执行part_seg目录下的train.py文件,即开始训练
import argparse
import subprocess
import tensorflow.compat.v1 as tf
tf.compat.v1.disable_eager_execution()
import numpy as np
from datetime import datetime
import json
import os
import sys
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
sys.path.append(BASE_DIR)
sys.path.append(os.path.dirname(BASE_DIR))
import provider
import pointnet_part_seg as model
# DEFAULT SETTINGS
parser = argparse.ArgumentParser()
parser.add_argument('--gpu', type=int, default=1, help='GPU to use [default: GPU 0]')
parser.add_argument('--batch', type=int, default=4, help='Batch Size during training [default: 32]')
parser.add_argument('--epoch', type=int, default=200, help='Epoch to run [default: 50]')
parser.add_argument('--point_num', type=int, default=2048, help='Point Number [256/512/1024/2048]')
parser.add_argument('--output_dir', type=str, default='train_results', help='Directory that stores all training logs and trained models')
parser.add_argument('--wd', type=float, default=0, help='Weight Decay [Default: 0.0]')
FLAGS = parser.parse_args()
hdf5_data_dir = os.path.join(BASE_DIR, './hdf5_data')
# MAIN SCRIPT
point_num = FLAGS.point_num
batch_size = FLAGS.batch
output_dir = FLAGS.output_dir
if not os.path.exists(output_dir):
os.mkdir(output_dir)
color_map_file = os.path.join(hdf5_data_dir, 'part_color_mapping.json')
color_map = json.load(open(color_map_file, 'r'))
all_obj_cats_file = os.path.join(hdf5_data_dir, 'all_object_categories.txt')
fin = open(all_obj_cats_file, 'r')
lines = [line.rstrip() for line in fin.readlines()]
all_obj_cats = [(line.split()[0], line.split()[1]) for line in lines]
fin.close()
all_cats = json.load(open(os.path.join(hdf5_data_dir, 'overallid_to_catid_partid.json'), 'r'))
NUM_CATEGORIES = 16
NUM_PART_CATS = len(all_cats)
print('#### Batch Size: {0}'.format(batch_size))
print('#### Point Number: {0}'.format(point_num))
print('#### Training using GPU: {0}'.format(FLAGS.gpu))
DECAY_STEP = 16881 * 20
DECAY_RATE = 0.5
LEARNING_RATE_CLIP = 1e-5
BN_INIT_DECAY = 0.5
BN_DECAY_DECAY_RATE = 0.5
BN_DECAY_DECAY_STEP = float(DECAY_STEP * 2)
BN_DECAY_CLIP = 0.99
BASE_LEARNING_RATE = 0.001
MOMENTUM = 0.9
TRAINING_EPOCHES = FLAGS.epoch
print('### Training epoch: {0}'.format(TRAINING_EPOCHES))
TRAINING_FILE_LIST = os.path.join(hdf5_data_dir, 'train_hdf5_file_list.txt')
TESTING_FILE_LIST = os.path.join(hdf5_data_dir, 'val_hdf5_file_list.txt')
MODEL_STORAGE_PATH = os.path.join(output_dir, 'trained_models')
if not os.path.exists(MODEL_STORAGE_PATH):
os.mkdir(MODEL_STORAGE_PATH)
LOG_STORAGE_PATH = os.path.join(output_dir, 'logs')
if not os.path.exists(LOG_STORAGE_PATH):
os.mkdir(LOG_STORAGE_PATH)
SUMMARIES_FOLDER = os.path.join(output_dir, 'summaries')
if not os.path.exists(SUMMARIES_FOLDER):
os.mkdir(SUMMARIES_FOLDER)
def printout(flog, data):
print(data)
flog.write(data + '\n')
def placeholder_inputs():
pointclouds_ph = tf.placeholder(tf.float32, shape=(batch_size, point_num, 3))
input_label_ph = tf.placeholder(tf.float32, shape=(batch_size, NUM_CATEGORIES))
labels_ph = tf.placeholder(tf.int32, shape=(batch_size))
seg_ph = tf.placeholder(tf.int32, shape=(batch_size, point_num))
return pointclouds_ph, input_label_ph, labels_ph, seg_ph
def convert_label_to_one_hot(labels):
label_one_hot = np.zeros((labels.shape[0], NUM_CATEGORIES))
for idx in range(labels.shape[0]):
label_one_hot[idx, labels[idx]] = 1
return label_one_hot
def train():
with tf.Graph().as_default():
with tf.device('/gpu:'+str(FLAGS.gpu)):
pointclouds_ph, input_label_ph, labels_ph, seg_ph = placeholder_inputs()
is_training_ph = tf.placeholder(tf.bool, shape=())
batch = tf.Variable(0, trainable=False)
learning_rate = tf.train.exponential_decay(
BASE_LEARNING_RATE, # base learning rate
batch * batch_size, # global_var indicating the number of steps
DECAY_STEP, # step size
DECAY_RATE, # decay rate
staircase=True # Stair-case or continuous decreasing
)
learning_rate = tf.maximum(learning_rate, LEARNING_RATE_CLIP)
bn_momentum = tf.train.exponential_decay(
BN_INIT_DECAY,
batch*batch_size,
BN_DECAY_DECAY_STEP,
BN_DECAY_DECAY_RATE,
staircase=True)
bn_decay = tf.minimum(BN_DECAY_CLIP, 1 - bn_momentum)
lr_op = tf.summary.scalar('learning_rate', learning_rate)
batch_op = tf.summary.scalar('batch_number', batch)
bn_decay_op = tf.summary.scalar('bn_decay', bn_decay)
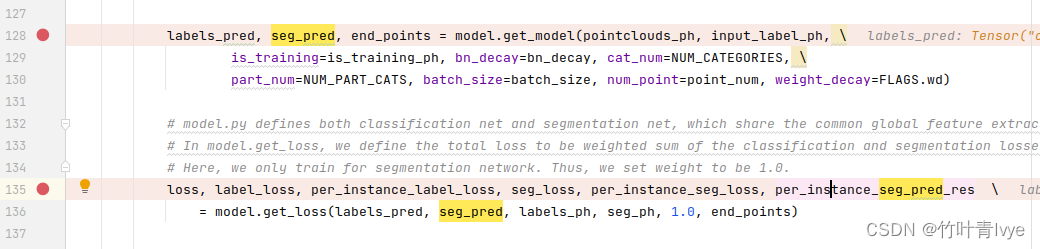
labels_pred, seg_pred, end_points = model.get_model(pointclouds_ph, input_label_ph, \
is_training=is_training_ph, bn_decay=bn_decay, cat_num=NUM_CATEGORIES, \
part_num=NUM_PART_CATS, batch_size=batch_size, num_point=point_num, weight_decay=FLAGS.wd)
# model.py defines both classification net and segmentation net, which share the common global feature extractor network.
# In model.get_loss, we define the total loss to be weighted sum of the classification and segmentation losses.
# Here, we only train for segmentation network. Thus, we set weight to be 1.0.
loss, label_loss, per_instance_label_loss, seg_loss, per_instance_seg_loss, per_instance_seg_pred_res \
= model.get_loss(labels_pred, seg_pred, labels_ph, seg_ph, 1.0, end_points)
total_training_loss_ph = tf.placeholder(tf.float32, shape=())
total_testing_loss_ph = tf.placeholder(tf.float32, shape=())
label_training_loss_ph = tf.placeholder(tf.float32, shape=())
label_testing_loss_ph = tf.placeholder(tf.float32, shape=())
seg_training_loss_ph = tf.placeholder(tf.float32, shape=())
seg_testing_loss_ph = tf.placeholder(tf.float32, shape=())
label_training_acc_ph = tf.placeholder(tf.float32, shape=())
label_testing_acc_ph = tf.placeholder(tf.float32, shape=())
label_testing_acc_avg_cat_ph = tf.placeholder(tf.float32, shape=())
seg_training_acc_ph = tf.placeholder(tf.float32, shape=())
seg_testing_acc_ph = tf.placeholder(tf.float32, shape=())
seg_testing_acc_avg_cat_ph = tf.placeholder(tf.float32, shape=())
total_train_loss_sum_op = tf.summary.scalar('total_training_loss', total_training_loss_ph)
total_test_loss_sum_op = tf.summary.scalar('total_testing_loss', total_testing_loss_ph)
label_train_loss_sum_op = tf.summary.scalar('label_training_loss', label_training_loss_ph)
label_test_loss_sum_op = tf.summary.scalar('label_testing_loss', label_testing_loss_ph)
seg_train_loss_sum_op = tf.summary.scalar('seg_training_loss', seg_training_loss_ph)
seg_test_loss_sum_op = tf.summary.scalar('seg_testing_loss', seg_testing_loss_ph)
label_train_acc_sum_op = tf.summary.scalar('label_training_acc', label_training_acc_ph)
label_test_acc_sum_op = tf.summary.scalar('label_testing_acc', label_testing_acc_ph)
label_test_acc_avg_cat_op = tf.summary.scalar('label_testing_acc_avg_cat', label_testing_acc_avg_cat_ph)
seg_train_acc_sum_op = tf.summary.scalar('seg_training_acc', seg_training_acc_ph)
seg_test_acc_sum_op = tf.summary.scalar('seg_testing_acc', seg_testing_acc_ph)
seg_test_acc_avg_cat_op = tf.summary.scalar('seg_testing_acc_avg_cat', seg_testing_acc_avg_cat_ph)
train_variables = tf.trainable_variables()
trainer = tf.train.AdamOptimizer(learning_rate)
train_op = trainer.minimize(loss, var_list=train_variables, global_step=batch)
saver = tf.train.Saver()
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
config.allow_soft_placement = True
sess = tf.Session(config=config)
init = tf.global_variables_initializer()
sess.run(init)
train_writer = tf.summary.FileWriter(SUMMARIES_FOLDER + '/train', sess.graph)
test_writer = tf.summary.FileWriter(SUMMARIES_FOLDER + '/test')
train_file_list = provider.getDataFiles(TRAINING_FILE_LIST)
num_train_file = len(train_file_list)
test_file_list = provider.getDataFiles(TESTING_FILE_LIST)
num_test_file = len(test_file_list)
fcmd = open(os.path.join(LOG_STORAGE_PATH, 'cmd.txt'), 'w')
fcmd.write(str(FLAGS))
fcmd.close()
# write logs to the disk
flog = open(os.path.join(LOG_STORAGE_PATH, 'log.txt'), 'w')
def train_one_epoch(train_file_idx, epoch_num):
is_training = True
for i in range(num_train_file):
cur_train_filename = os.path.join(hdf5_data_dir, train_file_list[train_file_idx[i]])
printout(flog, 'Loading train file ' + cur_train_filename)
cur_data, cur_labels, cur_seg = provider.loadDataFile_with_seg(cur_train_filename)
cur_data, cur_labels, order = provider.shuffle_data(cur_data, np.squeeze(cur_labels))
cur_seg = cur_seg[order, ...]
cur_labels_one_hot = convert_label_to_one_hot(cur_labels)
num_data = len(cur_labels)
num_batch = num_data // batch_size
total_loss = 0.0
total_label_loss = 0.0
total_seg_loss = 0.0
total_label_acc = 0.0
total_seg_acc = 0.0
for j in range(num_batch):
begidx = j * batch_size
endidx = (j + 1) * batch_size
feed_dict = {
pointclouds_ph: cur_data[begidx: endidx, ...],
labels_ph: cur_labels[begidx: endidx, ...],
input_label_ph: cur_labels_one_hot[begidx: endidx, ...],
seg_ph: cur_seg[begidx: endidx, ...],
is_training_ph: is_training,
}
_, loss_val, label_loss_val, seg_loss_val, per_instance_label_loss_val, \
per_instance_seg_loss_val, label_pred_val, seg_pred_val, pred_seg_res \
= sess.run([train_op, loss, label_loss, seg_loss, per_instance_label_loss, \
per_instance_seg_loss, labels_pred, seg_pred, per_instance_seg_pred_res], \
feed_dict=feed_dict)
per_instance_part_acc = np.mean(pred_seg_res == cur_seg[begidx: endidx, ...], axis=1)
average_part_acc = np.mean(per_instance_part_acc)
total_loss += loss_val
total_label_loss += label_loss_val
total_seg_loss += seg_loss_val
per_instance_label_pred = np.argmax(label_pred_val, axis=1)
total_label_acc += np.mean(np.float32(per_instance_label_pred == cur_labels[begidx: endidx, ...]))
total_seg_acc += average_part_acc
total_loss = total_loss * 1.0 / num_batch
total_label_loss = total_label_loss * 1.0 / num_batch
total_seg_loss = total_seg_loss * 1.0 / num_batch
total_label_acc = total_label_acc * 1.0 / num_batch
total_seg_acc = total_seg_acc * 1.0 / num_batch
lr_sum, bn_decay_sum, batch_sum, train_loss_sum, train_label_acc_sum, \
train_label_loss_sum, train_seg_loss_sum, train_seg_acc_sum = sess.run(\
[lr_op, bn_decay_op, batch_op, total_train_loss_sum_op, label_train_acc_sum_op, \
label_train_loss_sum_op, seg_train_loss_sum_op, seg_train_acc_sum_op], \
feed_dict={total_training_loss_ph: total_loss, label_training_loss_ph: total_label_loss, \
seg_training_loss_ph: total_seg_loss, label_training_acc_ph: total_label_acc, \
seg_training_acc_ph: total_seg_acc})
train_writer.add_summary(train_loss_sum, i + epoch_num * num_train_file)
train_writer.add_summary(train_label_loss_sum, i + epoch_num * num_train_file)
train_writer.add_summary(train_seg_loss_sum, i + epoch_num * num_train_file)
train_writer.add_summary(lr_sum, i + epoch_num * num_train_file)
train_writer.add_summary(bn_decay_sum, i + epoch_num * num_train_file)
train_writer.add_summary(train_label_acc_sum, i + epoch_num * num_train_file)
train_writer.add_summary(train_seg_acc_sum, i + epoch_num * num_train_file)
train_writer.add_summary(batch_sum, i + epoch_num * num_train_file)
printout(flog, '\tTraining Total Mean_loss: %f' % total_loss)
printout(flog, '\t\tTraining Label Mean_loss: %f' % total_label_loss)
printout(flog, '\t\tTraining Label Accuracy: %f' % total_label_acc)
printout(flog, '\t\tTraining Seg Mean_loss: %f' % total_seg_loss)
printout(flog, '\t\tTraining Seg Accuracy: %f' % total_seg_acc)
def eval_one_epoch(epoch_num):
is_training = False
total_loss = 0.0
total_label_loss = 0.0
total_seg_loss = 0.0
total_label_acc = 0.0
total_seg_acc = 0.0
total_seen = 0
total_label_acc_per_cat = np.zeros((NUM_CATEGORIES)).astype(np.float32)
total_seg_acc_per_cat = np.zeros((NUM_CATEGORIES)).astype(np.float32)
total_seen_per_cat = np.zeros((NUM_CATEGORIES)).astype(np.int32)
for i in range(num_test_file):
cur_test_filename = os.path.join(hdf5_data_dir, test_file_list[i])
printout(flog, 'Loading test file ' + cur_test_filename)
cur_data, cur_labels, cur_seg = provider.loadDataFile_with_seg(cur_test_filename)
cur_labels = np.squeeze(cur_labels)
cur_labels_one_hot = convert_label_to_one_hot(cur_labels)
num_data = len(cur_labels)
num_batch = num_data // batch_size
for j in range(num_batch):
begidx = j * batch_size
endidx = (j + 1) * batch_size
feed_dict = {
pointclouds_ph: cur_data[begidx: endidx, ...],
labels_ph: cur_labels[begidx: endidx, ...],
input_label_ph: cur_labels_one_hot[begidx: endidx, ...],
seg_ph: cur_seg[begidx: endidx, ...],
is_training_ph: is_training,
}
loss_val, label_loss_val, seg_loss_val, per_instance_label_loss_val, \
per_instance_seg_loss_val, label_pred_val, seg_pred_val, pred_seg_res \
= sess.run([loss, label_loss, seg_loss, per_instance_label_loss, \
per_instance_seg_loss, labels_pred, seg_pred, per_instance_seg_pred_res], \
feed_dict=feed_dict)
per_instance_part_acc = np.mean(pred_seg_res == cur_seg[begidx: endidx, ...], axis=1)
average_part_acc = np.mean(per_instance_part_acc)
total_seen += 1
total_loss += loss_val
total_label_loss += label_loss_val
total_seg_loss += seg_loss_val
per_instance_label_pred = np.argmax(label_pred_val, axis=1)
total_label_acc += np.mean(np.float32(per_instance_label_pred == cur_labels[begidx: endidx, ...]))
total_seg_acc += average_part_acc
for shape_idx in range(begidx, endidx):
total_seen_per_cat[cur_labels[shape_idx]] += 1
total_label_acc_per_cat[cur_labels[shape_idx]] += np.int32(per_instance_label_pred[shape_idx-begidx] == cur_labels[shape_idx])
total_seg_acc_per_cat[cur_labels[shape_idx]] += per_instance_part_acc[shape_idx - begidx]
total_loss = total_loss * 1.0 / total_seen
total_label_loss = total_label_loss * 1.0 / total_seen
total_seg_loss = total_seg_loss * 1.0 / total_seen
total_label_acc = total_label_acc * 1.0 / total_seen
total_seg_acc = total_seg_acc * 1.0 / total_seen
test_loss_sum, test_label_acc_sum, test_label_loss_sum, test_seg_loss_sum, test_seg_acc_sum = sess.run(\
[total_test_loss_sum_op, label_test_acc_sum_op, label_test_loss_sum_op, seg_test_loss_sum_op, seg_test_acc_sum_op], \
feed_dict={total_testing_loss_ph: total_loss, label_testing_loss_ph: total_label_loss, \
seg_testing_loss_ph: total_seg_loss, label_testing_acc_ph: total_label_acc, seg_testing_acc_ph: total_seg_acc})
test_writer.add_summary(test_loss_sum, (epoch_num+1) * num_train_file-1)
test_writer.add_summary(test_label_loss_sum, (epoch_num+1) * num_train_file-1)
test_writer.add_summary(test_seg_loss_sum, (epoch_num+1) * num_train_file-1)
test_writer.add_summary(test_label_acc_sum, (epoch_num+1) * num_train_file-1)
test_writer.add_summary(test_seg_acc_sum, (epoch_num+1) * num_train_file-1)
printout(flog, '\tTesting Total Mean_loss: %f' % total_loss)
printout(flog, '\t\tTesting Label Mean_loss: %f' % total_label_loss)
printout(flog, '\t\tTesting Label Accuracy: %f' % total_label_acc)
printout(flog, '\t\tTesting Seg Mean_loss: %f' % total_seg_loss)
printout(flog, '\t\tTesting Seg Accuracy: %f' % total_seg_acc)
for cat_idx in range(NUM_CATEGORIES):
if total_seen_per_cat[cat_idx] > 0:
printout(flog, '\n\t\tCategory %s Object Number: %d' % (all_obj_cats[cat_idx][0], total_seen_per_cat[cat_idx]))
printout(flog, '\t\tCategory %s Label Accuracy: %f' % (all_obj_cats[cat_idx][0], total_label_acc_per_cat[cat_idx]/total_seen_per_cat[cat_idx]))
printout(flog, '\t\tCategory %s Seg Accuracy: %f' % (all_obj_cats[cat_idx][0], total_seg_acc_per_cat[cat_idx]/total_seen_per_cat[cat_idx]))
if not os.path.exists(MODEL_STORAGE_PATH):
os.mkdir(MODEL_STORAGE_PATH)
for epoch in range(TRAINING_EPOCHES):
printout(flog, '\n<<< Testing on the test dataset ...')
eval_one_epoch(epoch)
printout(flog, '\n>>> Training for the epoch %d/%d ...' % (epoch, TRAINING_EPOCHES))
train_file_idx = np.arange(0, len(train_file_list))
np.random.shuffle(train_file_idx)
train_one_epoch(train_file_idx, epoch)
if (epoch+1) % 10 == 0:
cp_filename = saver.save(sess, os.path.join(MODEL_STORAGE_PATH, 'epoch_' + str(epoch+1)+'.ckpt'))
printout(flog, 'Successfully store the checkpoint model into ' + cp_filename)
flog.flush()
flog.close()
if __name__=='__main__':
train()
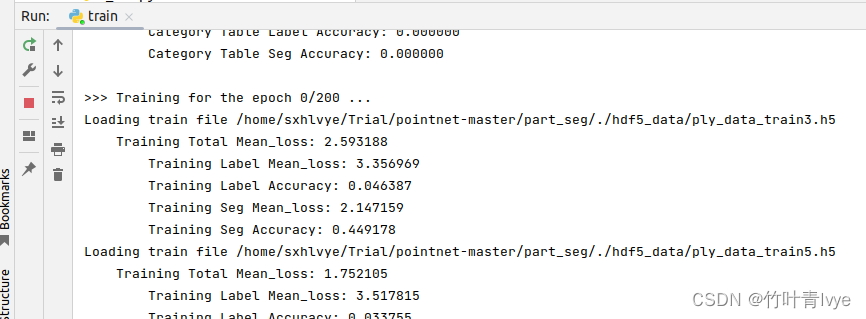
训练模型保存在工程如下位置(只训练了20次):
我们看下训练这个模型需要准备什么样的数据:
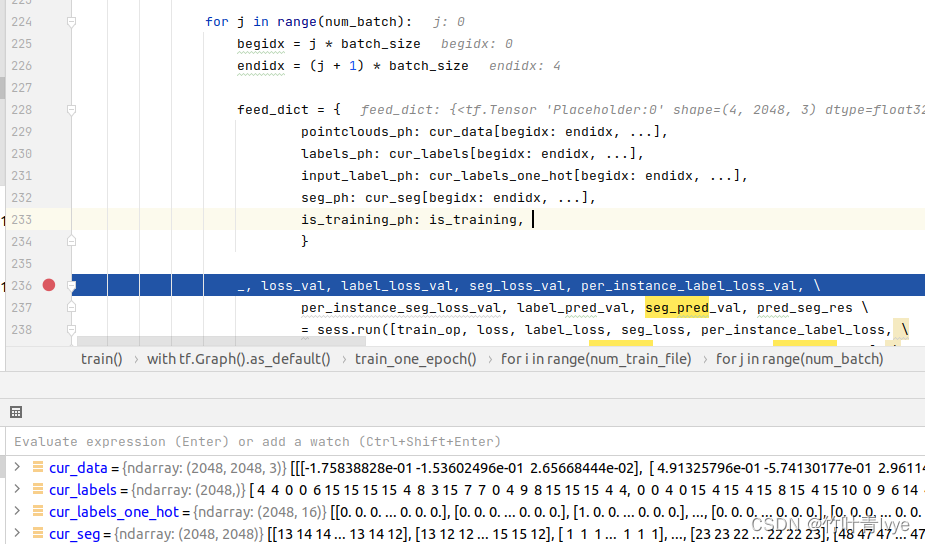
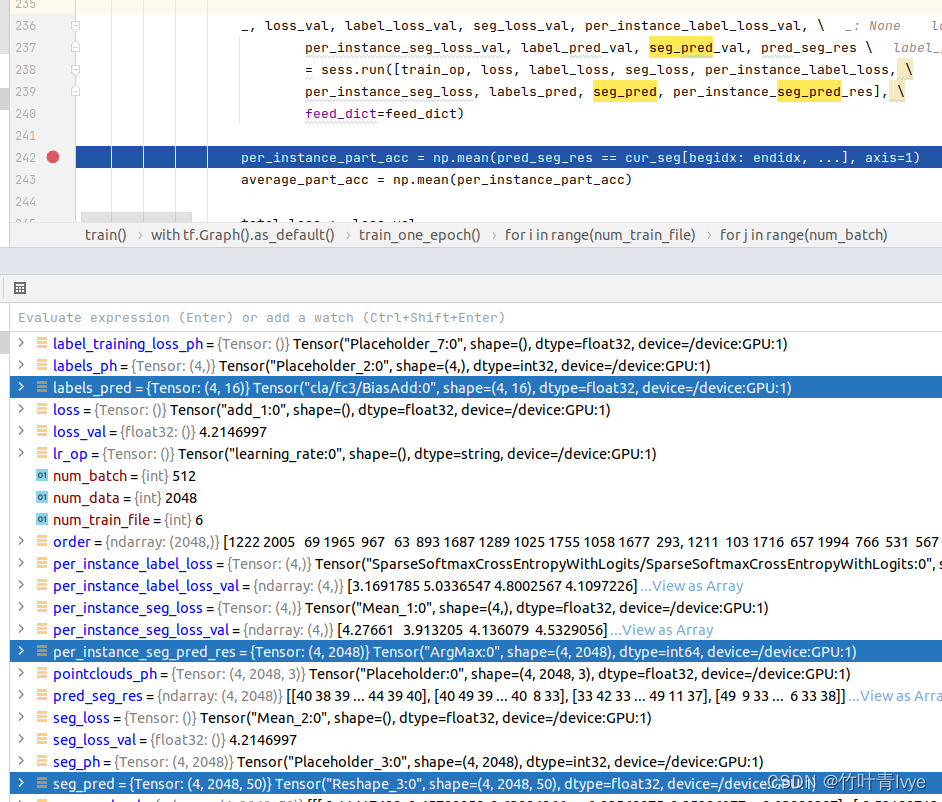
假设batchsize为1,即只一次训练只要一份点云(2048个点),可看到需要点云数据cur_data,大小为1*2048*3;点云的分类类别cur_labels,大小为(1,); 点云属于每个类别的概率cur_labels_one_hot,大小为(1,16);点云的语义分割标签,即点云中每个点属于具体哪个部件cur_seg,大小为(1,2048)。可看到物体总类别有16种

所有类别中总部件共有50种
假设batch size为1,此外还有这几个变量 seg_pred,大小为(1,2048,50),label_pred,大小为(1,16),per_instance_seg_pred_red,大小为(1,2048)。这些变量是在如下语句时候获取的。
接下来用训练获得的模型来对点云进行预测。
2. 预测阶段
将前面下载下来的shapenetcore_partanno_v0.zip解压放到如下工程目录结构下,然后跑下part_seg目录下的test.py
import argparse
import tensorflow.compat.v1 as tf
tf.compat.v1.disable_eager_execution()
import json
import numpy as np
import os
import sys
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
sys.path.append(BASE_DIR)
sys.path.append(os.path.dirname(BASE_DIR))
import provider
import pointnet_part_seg as model
parser = argparse.ArgumentParser()
parser.add_argument('--model_path', default='train_results/trained_models/epoch_20.ckpt', help='Model checkpoint path')
FLAGS = parser.parse_args()
# DEFAULT SETTINGS
pretrained_model_path = FLAGS.model_path # os.path.join(BASE_DIR, './pretrained_model/model.ckpt')
hdf5_data_dir = os.path.join(BASE_DIR, './hdf5_data')
ply_data_dir = os.path.join(BASE_DIR, './PartAnnotation')
gpu_to_use = 0
output_dir = os.path.join(BASE_DIR, './test_results')
output_verbose = True # If true, output all color-coded part segmentation obj files
# MAIN SCRIPT
point_num = 3000 # the max number of points in the all testing data shapes
batch_size = 1
test_file_list = os.path.join(BASE_DIR, 'testing_ply_file_list.txt')
oid2cpid = json.load(open(os.path.join(hdf5_data_dir, 'overallid_to_catid_partid.json'), 'r'))
object2setofoid = {}
for idx in range(len(oid2cpid)):
objid, pid = oid2cpid[idx]
if not objid in object2setofoid.keys():
object2setofoid[objid] = []
object2setofoid[objid].append(idx)
all_obj_cat_file = os.path.join(hdf5_data_dir, 'all_object_categories.txt')
fin = open(all_obj_cat_file, 'r')
lines = [line.rstrip() for line in fin.readlines()]
objcats = [line.split()[1] for line in lines]
objnames = [line.split()[0] for line in lines]
on2oid = {objcats[i]:i for i in range(len(objcats))}
fin.close()
color_map_file = os.path.join(hdf5_data_dir, 'part_color_mapping.json')
color_map = json.load(open(color_map_file, 'r'))
NUM_OBJ_CATS = 16
NUM_PART_CATS = 50
cpid2oid = json.load(open(os.path.join(hdf5_data_dir, 'catid_partid_to_overallid.json'), 'r'))
def printout(flog, data):
print(data)
flog.write(data + '\n')
def output_color_point_cloud(data, seg, out_file):
with open(out_file, 'w') as f:
l = len(seg)
for i in range(l):
color = color_map[seg[i]]
f.write('v %f %f %f %f %f %f\n' % (data[i][0], data[i][1], data[i][2], color[0], color[1], color[2]))
def output_color_point_cloud_red_blue(data, seg, out_file):
with open(out_file, 'w') as f:
l = len(seg)
for i in range(l):
if seg[i] == 1:
color = [0, 0, 1]
elif seg[i] == 0:
color = [1, 0, 0]
else:
color = [0, 0, 0]
f.write('v %f %f %f %f %f %f\n' % (data[i][0], data[i][1], data[i][2], color[0], color[1], color[2]))
def pc_normalize(pc):
l = pc.shape[0]
centroid = np.mean(pc, axis=0)
pc = pc - centroid
m = np.max(np.sqrt(np.sum(pc**2, axis=1)))
pc = pc / m
return pc
def placeholder_inputs():
pointclouds_ph = tf.placeholder(tf.float32, shape=(batch_size, point_num, 3))
input_label_ph = tf.placeholder(tf.float32, shape=(batch_size, NUM_OBJ_CATS))
return pointclouds_ph, input_label_ph
def output_color_point_cloud(data, seg, out_file):
with open(out_file, 'w') as f:
l = len(seg)
for i in range(l):
color = color_map[seg[i]]
f.write('v %f %f %f %f %f %f\n' % (data[i][0], data[i][1], data[i][2], color[0], color[1], color[2]))
def load_pts_seg_files(pts_file, seg_file, catid):
with open(pts_file, 'r') as f:
pts_str = [item.rstrip() for item in f.readlines()]
pts = np.array([np.float32(s.split()) for s in pts_str], dtype=np.float32)
with open(seg_file, 'r') as f:
part_ids = np.array([int(item.rstrip()) for item in f.readlines()], dtype=np.uint8)
seg = np.array([cpid2oid[catid+'_'+str(x)] for x in part_ids])
return pts, seg
def pc_augment_to_point_num(pts, pn):
assert(pts.shape[0] <= pn)
cur_len = pts.shape[0]
res = np.array(pts)
while cur_len < pn:
res = np.concatenate((res, pts))
cur_len += pts.shape[0]
return res[:pn, :]
def convert_label_to_one_hot(labels):
label_one_hot = np.zeros((labels.shape[0], NUM_OBJ_CATS))
for idx in range(labels.shape[0]):
label_one_hot[idx, labels[idx]] = 1
return label_one_hot
def predict():
is_training = False
with tf.device('/gpu:'+str(gpu_to_use)):
pointclouds_ph, input_label_ph = placeholder_inputs()
is_training_ph = tf.placeholder(tf.bool, shape=())
# simple model
pred, seg_pred, end_points = model.get_model(pointclouds_ph, input_label_ph, \
cat_num=NUM_OBJ_CATS, part_num=NUM_PART_CATS, is_training=is_training_ph, \
batch_size=batch_size, num_point=point_num, weight_decay=0.0, bn_decay=None)
# Add ops to save and restore all the variables.
saver = tf.train.Saver()
# Later, launch the model, use the saver to restore variables from disk, and
# do some work with the model.
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
config.allow_soft_placement = True
with tf.Session(config=config) as sess:
if not os.path.exists(output_dir):
os.mkdir(output_dir)
flog = open(os.path.join(output_dir, 'log.txt'), 'w')
# Restore variables from disk.
printout(flog, 'Loading model %s' % pretrained_model_path)
saver.restore(sess, pretrained_model_path)
printout(flog, 'Model restored.')
# Note: the evaluation for the model with BN has to have some statistics
# Using some test datas as the statistics
batch_data = np.zeros([batch_size, point_num, 3]).astype(np.float32)
total_acc = 0.0
total_seen = 0
total_acc_iou = 0.0
total_per_cat_acc = np.zeros((NUM_OBJ_CATS)).astype(np.float32)
total_per_cat_iou = np.zeros((NUM_OBJ_CATS)).astype(np.float32)
total_per_cat_seen = np.zeros((NUM_OBJ_CATS)).astype(np.int32)
ffiles = open(test_file_list, 'r')
lines = [line.rstrip() for line in ffiles.readlines()]
pts_files = [line.split()[0] for line in lines]
seg_files = [line.split()[1] for line in lines]
labels = [line.split()[2] for line in lines]
ffiles.close()
len_pts_files = len(pts_files)
for shape_idx in range(len_pts_files):
if shape_idx % 100 == 0:
printout(flog, '%d/%d ...' % (shape_idx, len_pts_files))
cur_gt_label = on2oid[labels[shape_idx]]
cur_label_one_hot = np.zeros((1, NUM_OBJ_CATS), dtype=np.float32)
cur_label_one_hot[0, cur_gt_label] = 1
pts_file_to_load = os.path.join(ply_data_dir, pts_files[shape_idx])
seg_file_to_load = os.path.join(ply_data_dir, seg_files[shape_idx])
pts, seg = load_pts_seg_files(pts_file_to_load, seg_file_to_load, objcats[cur_gt_label])
ori_point_num = len(seg)
batch_data[0, ...] = pc_augment_to_point_num(pc_normalize(pts), point_num)
label_pred_val, seg_pred_res = sess.run([pred, seg_pred], feed_dict={
pointclouds_ph: batch_data,
input_label_ph: cur_label_one_hot,
is_training_ph: is_training,
})
label_pred_val = np.argmax(label_pred_val[0, :])
seg_pred_res = seg_pred_res[0, ...]
iou_oids = object2setofoid[objcats[cur_gt_label]]
non_cat_labels = list(set(np.arange(NUM_PART_CATS)).difference(set(iou_oids)))
mini = np.min(seg_pred_res)
seg_pred_res[:, non_cat_labels] = mini - 1000
seg_pred_val = np.argmax(seg_pred_res, axis=1)[:ori_point_num]
seg_acc = np.mean(seg_pred_val == seg)
total_acc += seg_acc
total_seen += 1
total_per_cat_seen[cur_gt_label] += 1
total_per_cat_acc[cur_gt_label] += seg_acc
mask = np.int32(seg_pred_val == seg)
total_iou = 0.0
iou_log = ''
for oid in iou_oids:
n_pred = np.sum(seg_pred_val == oid)
n_gt = np.sum(seg == oid)
n_intersect = np.sum(np.int32(seg == oid) * mask)
n_union = n_pred + n_gt - n_intersect
iou_log += '_' + str(n_pred)+'_'+str(n_gt)+'_'+str(n_intersect)+'_'+str(n_union)+'_'
if n_union == 0:
total_iou += 1
iou_log += '_1\n'
else:
total_iou += n_intersect * 1.0 / n_union
iou_log += '_'+str(n_intersect * 1.0 / n_union)+'\n'
avg_iou = total_iou / len(iou_oids)
total_acc_iou += avg_iou
total_per_cat_iou[cur_gt_label] += avg_iou
if output_verbose:
output_color_point_cloud(pts, seg, os.path.join(output_dir, str(shape_idx)+'_gt.obj'))
output_color_point_cloud(pts, seg_pred_val, os.path.join(output_dir, str(shape_idx)+'_pred.obj'))
output_color_point_cloud_red_blue(pts, np.int32(seg == seg_pred_val),
os.path.join(output_dir, str(shape_idx)+'_diff.obj'))
with open(os.path.join(output_dir, str(shape_idx)+'.log'), 'w') as fout:
fout.write('Total Point: %d\n\n' % ori_point_num)
fout.write('Ground Truth: %s\n' % objnames[cur_gt_label])
fout.write('Predict: %s\n\n' % objnames[label_pred_val])
fout.write('Accuracy: %f\n' % seg_acc)
fout.write('IoU: %f\n\n' % avg_iou)
fout.write('IoU details: %s\n' % iou_log)
printout(flog, 'Accuracy: %f' % (total_acc / total_seen))
printout(flog, 'IoU: %f' % (total_acc_iou / total_seen))
for cat_idx in range(NUM_OBJ_CATS):
printout(flog, '\t ' + objcats[cat_idx] + ' Total Number: ' + str(total_per_cat_seen[cat_idx]))
if total_per_cat_seen[cat_idx] > 0:
printout(flog, '\t ' + objcats[cat_idx] + ' Accuracy: ' + \
str(total_per_cat_acc[cat_idx] / total_per_cat_seen[cat_idx]))
printout(flog, '\t ' + objcats[cat_idx] + ' IoU: '+ \
str(total_per_cat_iou[cat_idx] / total_per_cat_seen[cat_idx]))
with tf.Graph().as_default():
predict()
运行结果如下:
会对2874份点云逐一预测,测试结果保存在如下目录下:

我们用meshlab来看下第3个点云的结果,首先是2_gt.obj

其次是2_pred.obj

最后是2_diff.obj

seg_img下对应的2D图如下:
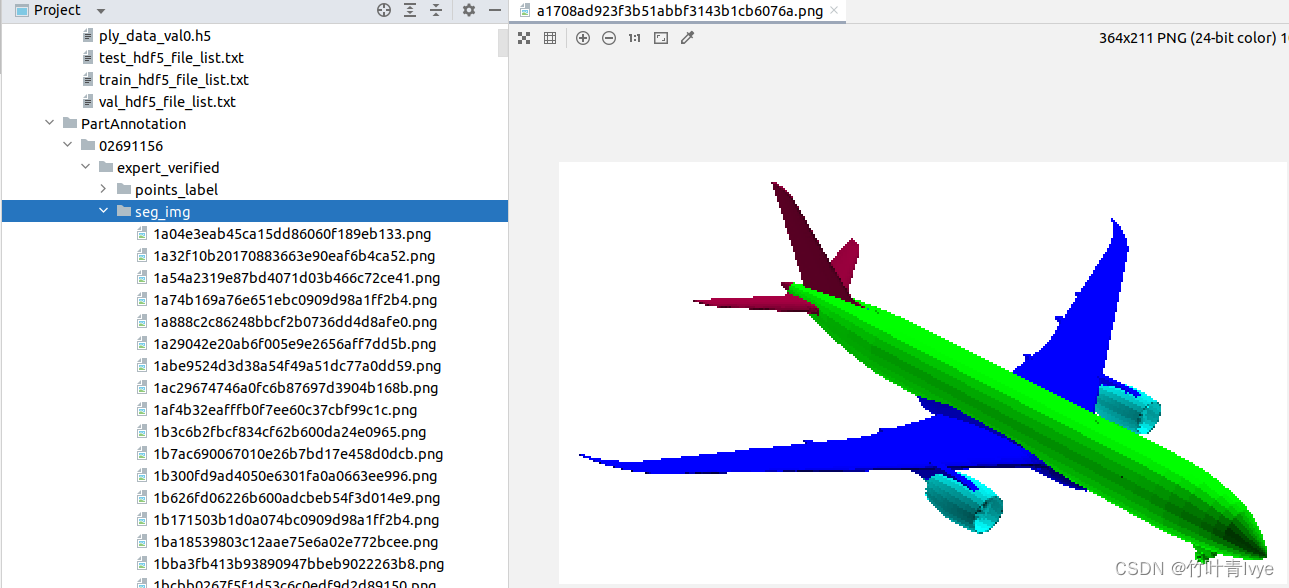
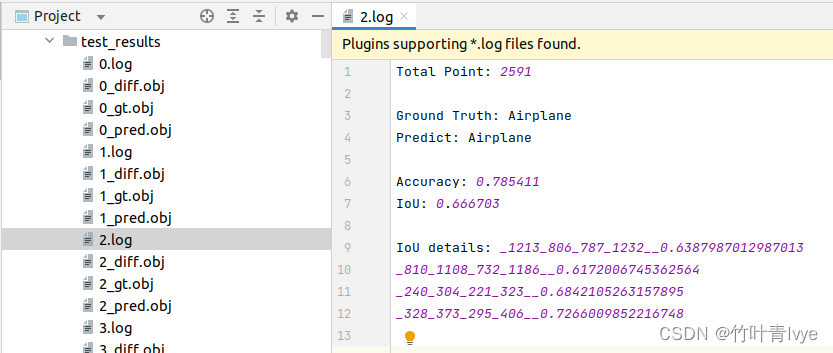
再看下2.log中的数据
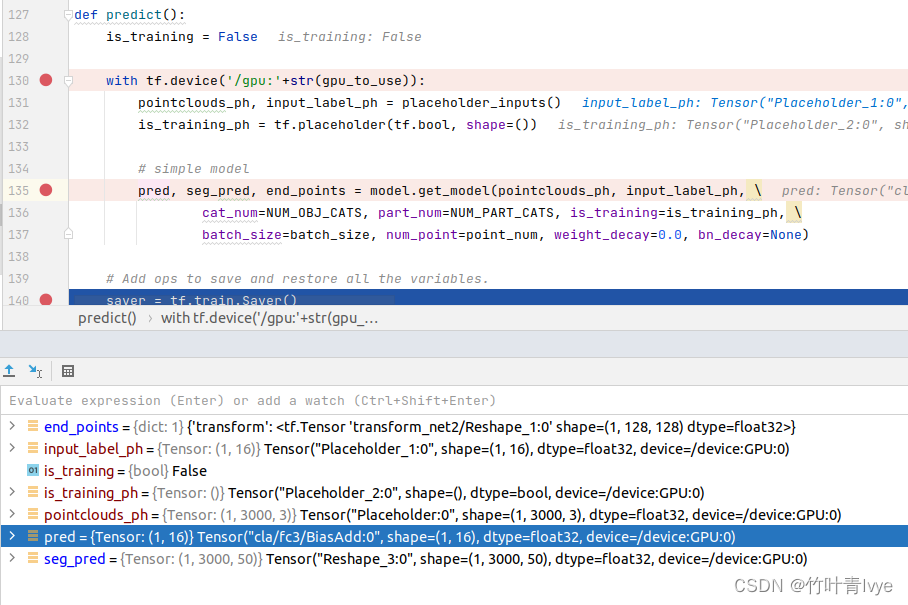
下面我们debug分析下程序,如下是一些占位符变量的维度
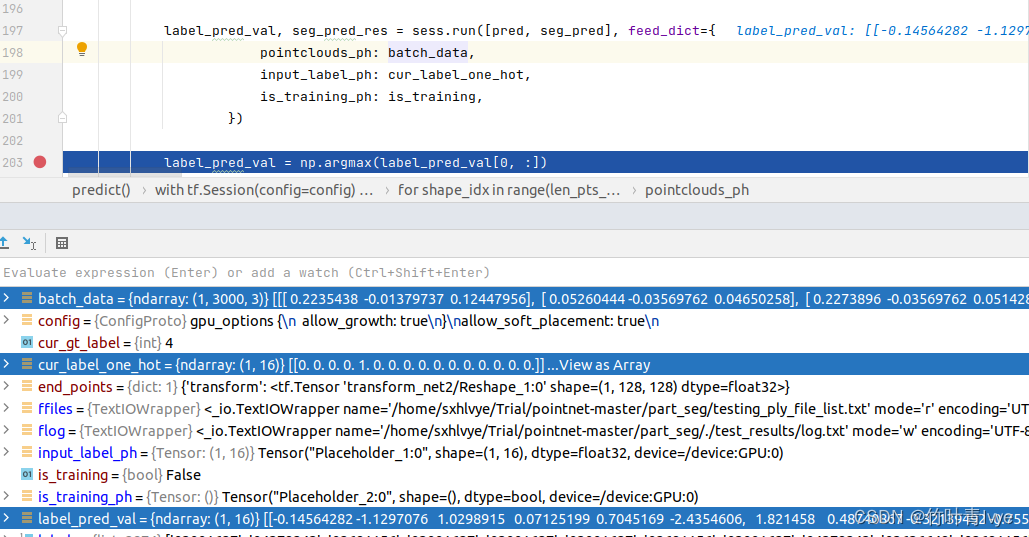
如下是预测一份点云要准备的数据以及预测返回的值。batch_data是一份点云数据,大小为(1,3000,3),cur_Label_one_hot是该点云的类别信息,大小为(1,16)。返回label_pred_val是点云的预测分类信息,大小为(1,16),属于某种类型的概率值都可以获得。seg_pred_res是点云中每个点的部件分割信息,大小为(1,3000,50)
![]()
如下变量可以获取到该测试点云中含有哪些部件类型

同时看到为了计算预测值和groundth的差异表征数据,所以还需要加载一些groundth值,如下:
pts是实际加载的数据,seg是每个点的标签的值(部件类型)
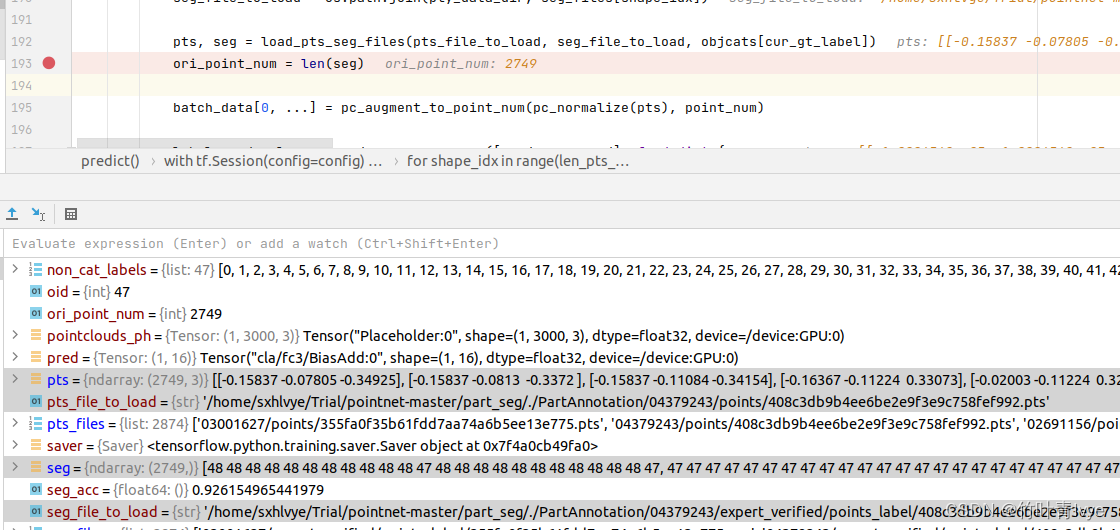
之所以如下操作,是保证该份点云数据中每个点的预测值都是在这个类所包含的部件类型内。接下来会获得如下表征值:(1)点云中各点的部件类别不一致的(预测值和groundth比较) (2)每个部件的单独正确率统计 (3)。程序最后又保存了带颜色信息的(根据部件类型去索引颜色值)的预测值,groundth值,两者之间的差异值

最后再看下PartAnnotation目录结构,主要涉及到的文件夹和文件上面已经提到
以上几个功能的完整测试工程链接如下:
链接: https://pan.baidu.com/s/1xf_LHu0-FxGXZA_ojUufjg 提取码: r4df
到此,此篇就结束啦!
附:常用3D数据集的介绍可参考如下博客
大场景室内点云标注数据集S3DIS介绍_stanford3ddataset_v1.2_aligned_version_lucky li的博客-CSDN博客
Stanford3dDataset_v1.2_Aligned_Version数据集的目录结构如下:



旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)