
k8s网络如何连接?
eBPF 是一种革命性的技术,起源于 Linux 内核,它可以在特权上下文(如操作系统内核)中运行沙箱程序。它用于安全有效地扩展内核的功能,而不需要更改内核源代码或加载内核模块。从历史上看,操作系统一直是实现可观察性、安全性和网络功能的理想场所,因为内核具有监视和控制整个系统的特权。同时,操作系统内核由于其核心作用和对稳定性和安全性的高要求而难以发展。因此,与在操作系统之外实现的功能相比,传统上操
在k8s中网络连接可以分为
-
容器与容器: 所有在pod中的容器表现为在同一个host,他们之间可以通过端口进行连接
-
pod与pod: 因为每个pod都有一个ip,因此pod可以通过ip进行直接连接
在不同主机上pod究竟是如何连接的呢?毕竟pod ip只是虚拟的,只能被本主机上pod访问的到,这将是本文的重点
-
service与service: service创建一个虚拟ip,客户端可以访问该虚拟ip,并被透明代理到service中的pod
-
外界与内网: 通常的实现方式是设置外部负载平衡器(例如GCE的ForwardingRules或AWS的ELB),它针对集群中的所有节点
k8s网络模型
为了使得应用程序更容易从虚拟机和主机迁移到由Kubernetes管理的pod,并让网络很容易理解,k8s网络模型定义了
- 每个 pod 都有自己的 IP 地址
- 每个 pod 中的容器共享 pod 的 IP 地址,并且可以自由地相互通信
- 使用 pod IP 地址(不含 NAT) ,Pods 可以与集群中的所有其他 pod 进行通信
- 使用网络策略定义隔离(限制每个 pod 可以与之通信的内容)
在下面介绍的多个网络插件都将基于该模型去实现
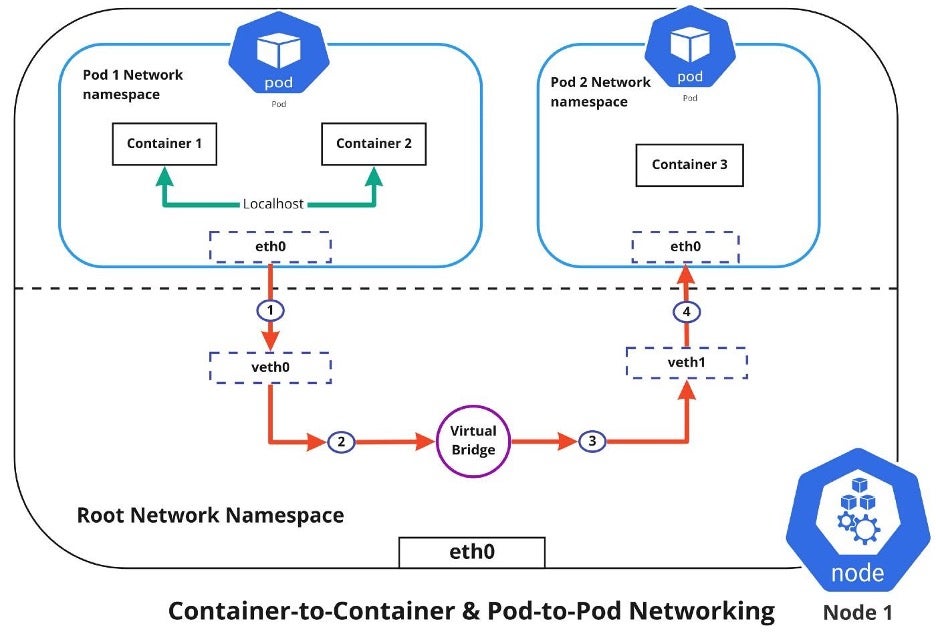
同主机内pod连接

在k8s中每个节点都有预先设置的ip范围分配给pods。这样能保证每个pod都拥有唯一ip,且集群中其他pod都能看到
在上图中可以看到,pod1到pod2数据流向是
- pod1流量通过eth0流到root网络命名空间中veth0
- 随后从veth0通过虚拟网桥到达veth1
- veth1最后流向pod2命名空间中的eth0
跨主机pod连接方案
由上我们可以知道通过veth pair和bridge是能实现同主机下的pod之间访问,那么跨主机之间的连接呢?
- underlay: 依赖于底层网络去实现。比如在同局域网内基于路由、或者属于不同局域网下采用BGP
- overlay: 底层物理网络称之为underlay,那么在这样的物理网络上再叠加一层就是overlay了。常见的overlay实现方案有VXLAN
BGP协议(边界网关协议)是一个标准化的外部网关协议,用以在互联网上的自主系统(AS)之间交换路由和可达性信息。BGP 被归类为路径向量路由协议,它根据路径、网络策略或网络管理员配置的规则集来做出路由决策。用于自治系统内部路由的内部边界网关协议网关协议称为内部网关协议,即内部网关协议(ibGP)。相比之下,该协议的互联网应用程序被称为外部边界网关协议,外部边界网关协议(ebGP)。
Virtual Extensible LAN (vxLAN)是一种网络虚拟化技术,旨在解决与大型云计算部署相关的可伸缩性问题。它使用类似 VLAN 的封装技术将 OSI 第2层以太网帧封装在第4层 UDP 数据报中,使用4789作为 IANA 指定的默认目标 UDP 端口号。
Overlay代表——Flannel

UDP模式
flannel在每个主机创建了daemon进程flanneld以及TUN设备flannel0,flanneld创建一些路由规则,将100.96.0.0/16下的流量导向flannel0设备
假设pod1(100.96.1.2)想要连接pod2(100.96.2.3)那么在UDP模式下
- pod1创建src: 100.96.1.2 -> dst: 100.96.2.3的包传递给了网桥
- 根据flanneld配置的路由规则,将包交给了flannel0设备
- flannel0设备将包交给了flanneld进程。由于flanneld进程储存了pod ip与实际主机ip的映射,因此会将目标ip为100.96.2.3包装为另一个主机实际ip 172.20.54.98,并且包装了源ip
- 在另一个主机收到之后,flanneld监听着udp端口,然后flanneld获取到该UDP包并拆包交给了flannel0
- flannel0收到之后交给了kernel匹配到源ip是要给网桥去处理,最后网桥交给实际pod,并返回回去
不过UDP模式的弊端在于从TUN设备flannel0到进程flanneld经历了用户态到内核态的转变,因此更加消耗性能

VXLAN模式
VXLAN(Virtual eXtensible Local Area Network)通过三层网络来搭建虚拟的二层网络
相比于UDP模式,VTEP承担了导流向实际网络主机的任务,但是还是要通过flanneld储存的pod ip和宿主机映射关系找到所对应的宿主机ip
VTEP(VXLAN Tunnel Endpoints): VXLAN边缘设备,用于VXLAN报文处理(封包和解包等)
BGP——calico
Calico使用 BGP 协议在其默认配置的节点之间传输网络数据包。使用 BGP,Calico 直接指导数据包,而不需要将它们包装在额外的封装层中。与 VXLAN 等更复杂的后端相比,这种方法提高了性能,简化了网络问题的故障排除。
calico有如下特性
- 多dataplanes: 可以选择Linux eBPF、标准Linux或者Windows HNS都能获得相同的体验
- 网络性能:使用 Linux eBPF 或 Linux 内核高度优化的标准网络管道来提供高性能的网络。Calico 的网络选项足够灵活,可以在大多数环境中不使用覆盖,避免了数据包 encap/decap 的开销。Calico 的控制平面和策略引擎已经在多年的生产使用中进行了微调,以最大限度地减少总体 CPU 使用和占用。
- 网络安全: Calico 丰富的网络政策模式使得锁定通信变得容易,因此唯一流动的流量就是想要流动的流量。
- 可拓展性
- 依赖低:直接基于路由实现,避免重复的封装解包工作,直接走原生协议栈
不足在于
- 租户隔离:若多租户使用同一个CIDR网络就面临地址冲突问题
- 路由规模:pod分散在host集群会产生较多路由项
- iptables规模:主机虚拟机或者容器过多会产生过多的iptables,进而会导致复杂、不可调试以及性能问题
- 跨子网时的网关路由问题:当对端网络不为二层可达时,需要通过三层路由机时,需要网关支持自定义路由配置,即 pod 的目的地址为本网段的网关地址,再由网关进行跨三层转发。
架构

- Felix: 运行在每个主机的agent进程,负责网络接口管理和监听、路由、ARP 管理、ACL 管理和同步、状态上报等。比如为机器添加了ip,或者创建了容器,那么felix就会负责设置好网卡、IP、Mac,然后在内核路由表写入
- etcd: 分布式键值存储,主要负责网络元数据一致性,确保Calico网络状态的准确性,可以与kubernetes共用
- BGP Client(BIRD): 运行在每个主机的BGP Client(采用BIRD实现),实现了如BGP、OSRF、RIP等动态路由,主要是监听由felix注入的路由信息,然后通过BGP广播通知其他主机
- BGP Router Refletor: 解决BGP client俩俩互通问题,采用的BGP Router Refletor,使所有 BGP Client 仅与特定 RR 节点互联并做路由同步,从而大大减少连接数
BGP模式下的网络连接
主机A中pod1想要与另一个主机B中pod2连接
- pod1欲发送包到pod2 ip地址,因此发送arp请求来获取pod2 ip的mac地址
- 主机收到arp请求,通过代理arp技术将自己的mac地址返回给pod1
- pod1发送数据包到主机
- 主机判断ip不在本局域网内(就是主机网络内),因此通过查询路由转发给对端主机
- 主机B收到数据包后,匹配本地路由表,随后转发给pod2
代理 ARP 是给定网络上的代理服务器响应地址解析协议(ARP)对不在该网络上的 IP 地址的查询。代理知道流量目的地的位置,并提供自己的 MAC 地址作为(表面上是最终的)目的地。指向代理地址的流量通常由代理通过另一个接口或隧道路由到预定目的地。
eBPF——cilium

eBPF与XDP简介
eBPF 是一种革命性的技术,起源于 Linux 内核,它可以在特权上下文(如操作系统内核)中运行沙箱程序。它用于安全有效地扩展内核的功能,而不需要更改内核源代码或加载内核模块。从历史上看,操作系统一直是实现可观察性、安全性和网络功能的理想场所,因为内核具有监视和控制整个系统的特权。同时,操作系统内核由于其核心作用和对稳定性和安全性的高要求而难以发展。因此,与在操作系统之外实现的功能相比,传统上操作系统一级的创新率较低。
随着分布式任务、公有云的崛起,网络成为了很大的瓶颈,已有的Linux网络栈已经无法满足高性能网络处理的要求
XDP(eXpress DataPath),是一种基于 eBPF 的高性能数据路径,用于绕过大部分操作系统网络堆栈以高速率发送和接收网络数据包。自从4.8版本以来,它被合并到 Linux 内核中
XDP可以分为Native、Offloaded、Generic三种模式
- Native: XDP程序hook到网卡驱动。需要网卡驱动支持。
- Offloaded: XDP程序直接hook到可编程网卡设备。处理性能最强
- Generic: 由内核提供的XDP,性能最差
Native、Offloaded模式都在驱动poll之后

Generic模式则在receive_skv()之后

BGP模式下pod之间的连接
在主机A中pod1与另一台主机B中pod2沟通过程如下(以BGP模式为例)
-
pod1通过查询由cilium_host配置的pod内路由表可知pod2的ip匹配到host侧的veth pair lxc
-
包装源ip为a1 ip,源mac为a1 mac,目的ip为pod2 ip,目的mac为host侧的veth pair mac发送到主机侧的lxc
-
主机内核协议栈查询内核路由表,从而将包导向egress BPF bond0
如果包请求的是serviceIP,lxc上的tc ingress BPF,也就是from-container BPF会将serviceIP转换为pod ip
-
bond0将包的源mac转为bond0 mac,主机网关的mac设置为目的mac
-
随后包传递到主机网关,由于pod2的ip已经通过BGP协议声明了,因此转发到pod2所在的主机B,最后按照类似路径到达pod2

Ref
- https://github.com/kubernetes/design-proposals-archive/blob/main/network/networking.md
- https://www.tigera.io/learn/guides/kubernetes-networking/
- https://opensource.com/article/22/6/kubernetes-networking-fundamentals
- https://blog.laputa.io/kubernetes-flannel-networking-6a1cb1f8ec7c
- https://cloud.tencent.com/developer/article/2090641
- https://en.wikipedia.org/wiki/Border_Gateway_Protocol
- https://docs.tigera.io/calico/latest/about/
- https://en.wikipedia.org/wiki/Proxy_ARPs
- https://www.cnblogs.com/goldsunshine/p/10701242.html
- https://icloudnative.io/posts/poke-calicos-lies/
- https://ebpf.io/what-is-ebpf/
- https://kccncna19.sched.com/event/Uae7/understanding-and-troubleshooting-the-ebpf-datapath-in-cilium-nathan-sweet-digitalocean
- https://en.wikipedia.org/wiki/Express_Data_Path
- http://arthurchiao.art/blog/cilium-life-of-a-packet-pod-to-service/

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)