
Reds来看看,会有一定的收获!!!
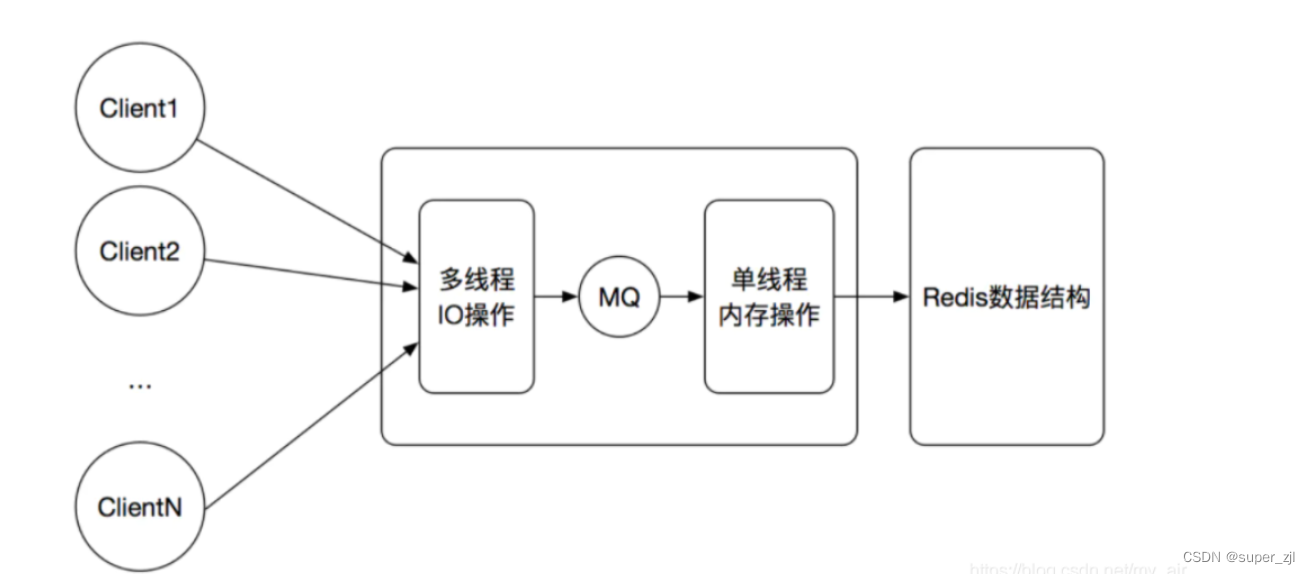
1.NoSQL数据库(Not Only SQL)的一种,即非关系型数据库2.Redis是一个开源的key-value存储系统。3.数据缓存在内存中4.单线程+I/O多路复用单线程: 来一个请求,走一套流程(效率低)单线程+ I/O多路复用(这里“多路”指的是多个网络连接(redis是以socket通信),“复用”指的是复用同一个线程。redis会建立多个scoket连接(Socket socket
1.Redis概述
1.NoSQL数据库(Not Only SQL)的一种,即非关系型数据库
2.Redis是一个开源的key-value存储系统。
3.数据缓存在内存中
4.单线程+I/O多路复用
单线程: 来一个请求,走一套流程(效率低)
单线程+ I/O多路复用(这里“多路”指的是多个网络连接(redis是以socket通信),“复用”指的是复用同一个线程。)
redis会建立多个scoket连接(Socket socket = serverSocket.accept();),基于这些建立的连接去探测哪个连接已经接收完了客户端的请求数据(注意:不是探测哪个连接建立好了,而是探测哪个接收完了请求数据),而且这里的探测动作就是单线程的开始,一旦探测到则基于接收到的数据开始数据处理阶段,然后返回数据,再继续探测下一个已经接收完请求数据的网络连接。注意,从探测到数据处理再到数据返回,全程单线程。这应该就是所谓的redis单线程。
如何理解?
老师出了一道题目,下面有10个同学解答,老师在讲台上等,谁做完谁举手,这时A,B举手,表示他们解答问题完毕,你下去依次检查A、B的答案,然后继续回到讲台上等。此时C、D又举手,然后去处理C和D...
多路IO复用只用来处理网络数据的读写和协议解析,命令的执行仍旧是单线程。
5.乐观锁

悲观锁

6.会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件。
2.Redis持久化方案
1.RDB(*Redis DataBase*)
在指定的时间间隔内将内存中的数据集快照写入磁盘,它恢复时是将快照文件直接读到内存里。
Redis会单独创建(fork)一个子进程来进行持久化,会先将数据写入到 一个临时文件中,待持久化过程都结束了,再用这个临时 文件替换上次持久化好的文件。 如果需要进行大规模数据的恢复,且对于数据恢复的完整性不是非常敏感,那RDB方式要比AOF 方式更加的高效。
Fork的作用是复制一个与当前进程一样的进程,内存中的数据也被复制了一份。
bgsave和save的区别:bgsave是后台异步进行的。
缺点:
最后一次持久化后的数据可能丢失。
两倍的资源占用
流程图:

2.AOF(*Append Only File*)
以日志的形式来记录每个写操作(增量保存),将Redis执行过的所有写指令记录下来(读操作不记录), 只许追加文件但不可以 改写文件,redis启动之初会读取该文件重新构建数据,换言之,redis 重启的话就根据日志文件的内容将写指令从前到后执行,一 次以完成数据的恢复工作

rewrite是什么?
AOF采用文件追加方式,文件会越来越大,为避免出现此种情况,新增了重写机制, 当AOF文件的大小超过所设定的阈值时,Redis就会启动AOF文件的内容压缩, 只保留可以恢复数据的最小指令集。
缺点:
比起RDB占用更多的磁盘空间。
恢复备份速度慢。
AOF默认不开启 持久化文件默认叫appendonly.aof
思考:如果RDB和AOF都开启,Redis会听谁的?
系统默认取AOF的数据(数据不会存在丢失)
总结:
官方推荐两个都启用。
如果对数据不敏感,可以选单独用RDB。
不建议单独用 AOF,因为可能会出现Bug。
如果只是做纯内存缓存,可以都不用。
3.Redis常见问题
1.缓存穿透
出现的原因:
当key对应的数据在数据源并不存在,每次针对此key的请求从缓存获取不到,请求都会压到数据源,从而可能压垮数据源。比如用一个不存在的用户id获取用户信息,不论缓存还是数据库都没有,若黑客利用此漏洞进行攻击可能压垮数据库。
试想一下,如果有人恶意对你的系统进行攻击,拿一个不存在的id 去查询数据,会产生大量的请求到数据库去查询。可能会导致你的数据库由于压力过大而宕掉。
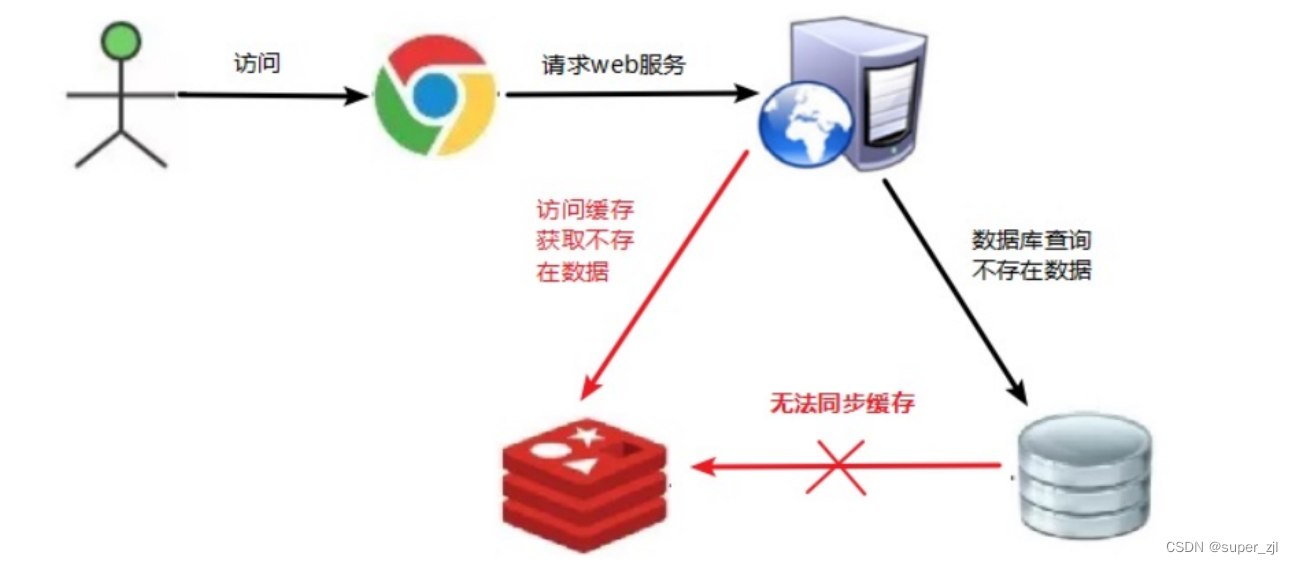
解决方案
1.缓存空值
之所以会发生穿透,就是因为缓存中没有存储这些空数据的key。从而导致每次查询都到数据库去了。那么我们就可以为这些key对应的值设置为null 丢到缓存里面去。后面再出现查询这个key 的请求的时候,直接返回null 。这样,就不用在到数据库中去走一圈了,但是别忘了设置过期时间。
2.BloomFilter(布隆过滤器)
将所有可能存在的数据哈希到一个足够大的bitmap中,一个一定不存在的数据会被 这个bitmap拦截掉,从而避免了对底层存储系统的查询压力。在缓存之前在加一层 BloomFilter ,在查询的时候先去 BloomFilter 去查询 key 是否存在,如果不存在就直接返回,存在再走查缓存 -> 查 DB。
3.进行实时监控
当发现Redis的命中率开始急速降低,需要排查访问对象和访问的数据,和运维人员配合,可以设置黑名单限制服务。
bitmap是什么?
布隆过滤器原理?
2.缓存击穿
出现的原因:
key对应的数据存在,但在redis中过期,此时若有大量并发请求过来,这些请求发现缓存过期一般都会从后端DB加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把后端DB压垮。

解决方案
1.预先设置热门数据
在redis高峰访问之前,把一些热门数据提前存入到redis里面,加大这些热门数据key的时长。
2.实时调整
现场监控哪些数据热门,实时调整key的过期时长。
3.使用互斥锁(mutex key)
简单地来说,就是在缓存失效的时候(判断拿出来的值为空),不是立即去load db,而是先使用Redis的SETNX命令去set一个互斥key,当操作返回成功时,再进行load db的操作并回设缓存;否则,就让当前线程睡眠一段时间再次查询。SETNX,是「SET if Not eXists」的缩写,也就是只有键不存在的时候才设置,可以利用它来实现互斥的效果。
3.缓存雪崩
出现的原因:
与缓存击穿相似
注意区分:
缓存雪崩和缓存击穿的区别在于:前者针对多个key批量过期,后者只针对一个key。
解决方案
1.构建多级缓存架构
nginx缓存 + redis缓存 +其他缓存(ehcache等)
2.使用锁或队列
用加锁或者队列的方式保证来保证不会有大量的线程对数据库一次性进行读写,从而避免失效时大量的并发请求落到底层存储系统上。不适用高并发情况。
3.设置过期标志更新缓存
记录缓存数据是否过期(设置提前量),如果过期会触发通知另外的线程在后台去更新实际key的缓存。
4.将缓存失效时间分散开
比如我们可以在原有的失效时间基础上增加一个随机值,比如1-5分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件。

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)