机器学习手写体识别项目(KNN)
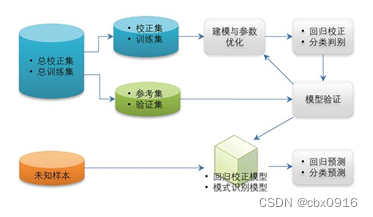
监督学习非监督学习手写体数字识别属于模式识别范畴,主要使用分类算法来对未知样本进行分类预测。其流程图如下:本项目前期需要进行数据采集,故整体项目可分为以下几个阶段:1、数据采集2、特征提取3、训练模型4、模型验证分析调优5、分类模型应用。
·
监督学习
- 分类:主要任务是将实例数据划分到合适的分类中
- 回归:预测数值型数据(数据拟合曲线:通过给定数据点最优拟合曲线)
说明:之所以称之为监督学习,是因为这类算法必须知道预测什么,即目标变量的分类信息;
非监督学习
- 聚类:将数据集合分成由类似的对象组成的多个类的过程称为聚类
- 密度估计:将寻找描述数据统计值的过程称之为密度估计
手写体数字识别属于模式识别范畴,主要使用分类算法来对未知样本进行分类预测。其流程图如下:
本项目前期需要进行数据采集,故整体项目可分为以下几个阶段:
1、 数据采集
2、 特征提取
3、 训练模型
4、 模型验证分析调优
5、 分类模型应用
数据采集
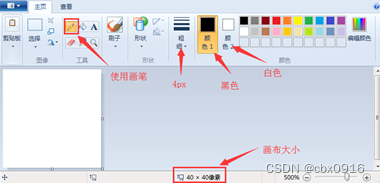
1、数据采集工具:使用画图软件来模拟手写输入设备。
2、采集过程描述:画布大小40*40,使用画笔、粗细:4px,颜色1为黑色,颜色2为白色。如下图:
3、图片命名规则:存储名称为”数字_序号.bmp”,最终采集图片和命名可参考下图:

4、采集数据量:10*30,即每个数字采集30副图片。
特征提取
由于当前数字图像比较简单,可直接使用图像的灰度图像素值作为该数字图像的特征值。由于原始图像大小为40 * 40像素,特征值为1600个,比较多。对于该项目中的数字图像来说,每种数字其书写轨迹有一定的范围限制,可将图像缩放为8*8,即每个样本拥有64个特征值。
模型训练
当前项目使用KNN算法(或其它分类算法)来进行分类。
| k-近邻 | 线性回归 |
| 朴素贝叶斯 | 局部加权线性回归 |
| 支持向量机 | Ridge回归 |
| 决策树 | Lasso最小回归系数估计 |
| K均值 | 最大期望算法(EM算法) |
| DBSCAN(基于密度的聚类算法) | Parzen窗设计 |
项目风险分析及识别调优策略
分类识别准确率如果比较低,可考虑从以下几个方面来进行相关调优操作:
1、 提取的特征值不合适:有可能是图像未进行预处理操作,可增加预处理过程;其它特征值提取算法暂不考虑。
2、 KNN算法中近邻值K取值不合适,可进行多次测试,从而找到合适的K值。
代码
"""
项目:手写体数字识别项目
作者:CBX
时间:2019.01.15
备注:初稿
"""
import os
import cv2
import numpy as np
from sklearn import neighbors
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
def my_load_data(file_name,test_size):
"""
加载自己的数据文件
:param file_name:
:param test_size:
:return:拆分之后的训练集和测试集
"""
X = np.loadtxt(file_name,usecols=tuple(range(64)))
Y = np.loadtxt(file_name,usecols=(64,))
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=test_size)
return X_train, X_test, Y_train, Y_test
def img_prepro(src_img):
"""
针对一张灰度图,进行预处理,对图像进行简单的剪裁
:param src_img: 原始图片
:return: 预处理之后的图片
"""
image = src_img
row, col = image.shape
top = row
bottom = 0
left = col
right = 0
for i in range(row):
for j in range(col):
if image[i, j] == 0:
if i < top:
top = i
if j < left:
left = j
if i > bottom:
bottom = i
if j > right:
right = j
# 剪裁图像
dst_img = image[int(top):int(bottom), int(left):int(right)]
# 统一预处理后的图像大小
dst_img = cv2.resize(dst_img, (8,8))
return dst_img
def prepro(dir_name , pre_dir):
"""
根据文件夹名,循环遍历所有图像,对每一张图像进行预处理。并保存预处理后的图像。
:param dir_name: 被遍历的文件夹名
:param pre_dir: 预处理后的图像保存路径
:return: 预处理过程无异常情况则返回True,否则False
"""
# 1.获得指定文件夹下所有的文件名
file_name_list = os.listdir(dir_name)
# 2.针对每一个图像进行预处理操作,循环遍历文件名列表
for file_name in file_name_list:
# 2.1 根据文件名,读取图像(灰度图)
img_path = dir_name + "/" + file_name
img = cv2.imread(img_path, cv2.IMREAD_GRAYSCALE) # 灰度图
# 2.2 对图像进行预处理操作
dst_img = img_prepro(img)
# 2.3 把预处理后的图像存储
preimg_path = pre_dir + "/" + file_name
cv2.imwrite(preimg_path, dst_img)
return True
def get_feature(src_img):
"""
提取单张图片的特征值
:param src_img:
:return:
"""
row, col = src_img.shape
feature = np.array(src_img).reshape((1, row*col))
return feature
def create_feature_file(dir_path, data_file_name):
"""
对dir_path下的所有图像,提取特征值,并生成数据文档
:param dir_path: 文件夹名
:param data_file_name: 数据文档名
:return: 无异常,则为True
"""
# 1.获得指定文件夹下所有的文件名
file_name_list = os.listdir(dir_path)
# 2.针对每一个图像进行预处理操作,循环遍历文件名列表
X = np.zeros((1, 64))
Y = np.zeros((1,1))
for file_name in file_name_list:
# 2.1 根据文件名,读取图像(灰度图)
img_path = dir_path + "/" + file_name
img = cv2.imread(img_path, cv2.IMREAD_GRAYSCALE) # 灰度图
# 2.2 获得当前样本的目标值
y = int(file_name[0])
# 2.3 提取特征值
feature = get_feature(img)
# 将单个样本的目标值和特征值进行拼接
X = np.append(X, feature, axis=0)
Y = np.append(Y, np.array(y).reshape((1,1)), axis=0)
# 根据数据文档的特点,需要拼接X、Y
my_set = np.append(X, Y, axis=1)
# 将数据直接保存
np.savetxt(data_file_name, my_set[1:,:])
return True
def my_train_model(X_train,Y_train):
"""
训练分类模型,这里使用KNN算法
:param X_train: 训练集
:param Y_train: 训练目标集
:return: 训练之后的模型
"""
# 使用KNN算法
# clf = neighbors.KNeighborsClassifier(n_neighbors=1)
# 使用SVM算法
clf = SVC(C=200, kernel='linear')
clf.fit(X_train,Y_train)
return clf
def my_test_model(clf, X_test, Y_test):
result = clf.score(X_test, Y_test)
print("测试成功率为:"+ str(result))
def my_app(img_name, clf):
"""
模型应用
:param img_name: 需要进行识别(分类)的实际样本
:param clf: 使用的训练好的模型
:return: 分类结果
"""
# 1.根据文件名,读取图片(灰度图)
img = cv2.imread(img_name,cv2.IMREAD_GRAYSCALE)
# 2.对实际样本进行预处理
dst_img = img_prepro(img)
# 3.提取实际样本的特征值
feature = get_feature(dst_img)
# 4.使用训练好的模型进行预测、识别
result = clf.predict(feature)
return result
# 程序入口
if __name__ == "__main__":
# 图像预处理,输入文件路径。可以将预处理之后的图像进行保存,以便验证预处理的结果。
# prepro("WeMNTS", "PreMNTS")
# 提取特征值,并将特征值存储到数据文档中
# create_feature_file("PreMNTs", "mnts_data.txt")
# 加载特征值
X_train, X_test, Y_train, Y_test = my_load_data("mnts_data.txt", 0.2)
# 训练模型
clf = my_train_model(X_train, Y_train)
# 测试模型
my_test_model(clf, X_test, Y_test)
# 模型应用
# result = my_app("9.bmp",clf)
# print(result)

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)