

下载bert的预训练模型并加载训练教程
下载bert的预训练模型
一键AI生成摘要,助你高效阅读
问答
·
下载bert的预训练模型并加载训练
step1: 进入网址 https://huggingface.co 搜索自己需要的模型名(下面以bert-base-uncased 为例)
step2: 在如下的界面中,找到Files and versions,下载如下三个红框中的内容即可。(这里以下载pytorch版的模型为例)
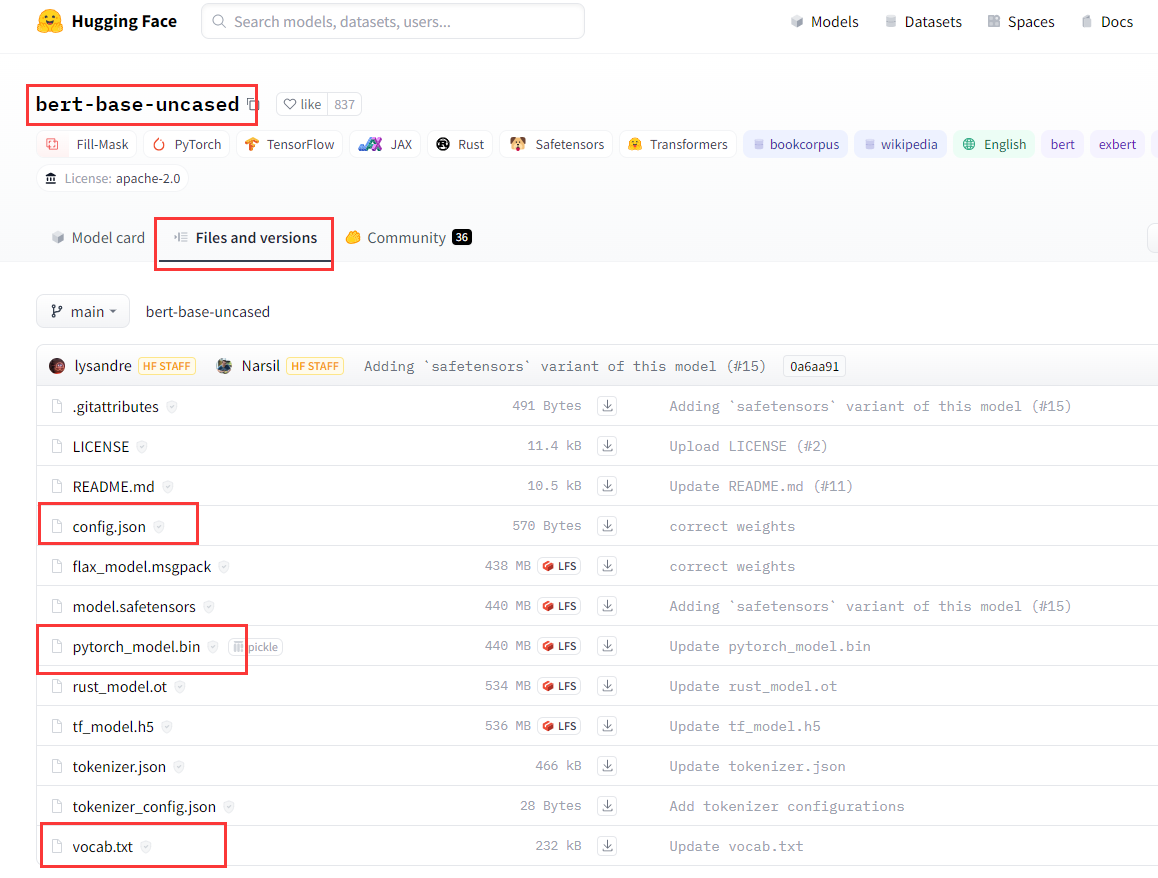
step3: 将上述下载好的内容放到/bert-base-uncased文件夹下。那么就可以在程序中这么用:
from transformers import BertModel, BertTokenizer
# 加载预训练的BERT模型和对应的分词器
model_name = 'bert-base-uncased'
tokenizer = BertTokenizer.from_pretrained(model_name)
model = BertModel.from_pretrained(model_name)
# 使用模型和分词器进行文本处理和编码
text = "Hello, how are you?"
tokens = tokenizer.tokenize(text)
input_ids = tokenizer.convert_tokens_to_ids(tokens)
print(tokens)
print(input_ids)
输出:
['hello', ',', 'how', 'are', 'you', '?']
[7592, 1010, 2129, 2024, 2017, 1029]
在这个示例中,我们首先使用 BertTokenizer.from_pretrained() 加载了预训练的BERT模型的分词器,并将其赋值给变量 tokenizer。然后,使用 BertModel.from_pretrained() 加载预训练的BERT模型本身,并将其赋值给变量 model。
接下来,我们使用 tokenizer.tokenize() 将文本进行分词处理,得到一个标记化的单词列表。然后,使用 tokenizer.convert_tokens_to_ids() 将标记化的单词转换为对应的词汇表索引。
请注意,上述示例中的代码假设您已经安装了Hugging Face Transformers库,并已正确导入相关的包和模块。
通过这些步骤,您可以加载预训练的BERT模型,并使用它进行文本处理和编码。根据具体的任务和需求,您可以进一步调整和使用BERT模型的输出。

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)