

TDEngine的常用命令及功能总结
TDEngine的常用功能及命令总结
TDEngine的常用命令总结
最近公司在启用TDengine作为实时数据的存储数据库,目前这个数据库的使用方式,我还不是很熟悉,特此记录和总结一些使用技巧。

官网链接:TDengine文档
一、相关配置文件
TD官方链接:参考手册-文件目录结构
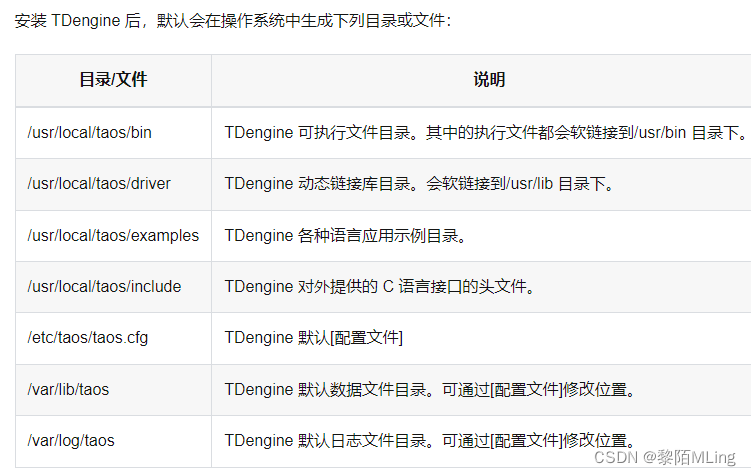
1.1 server端配置
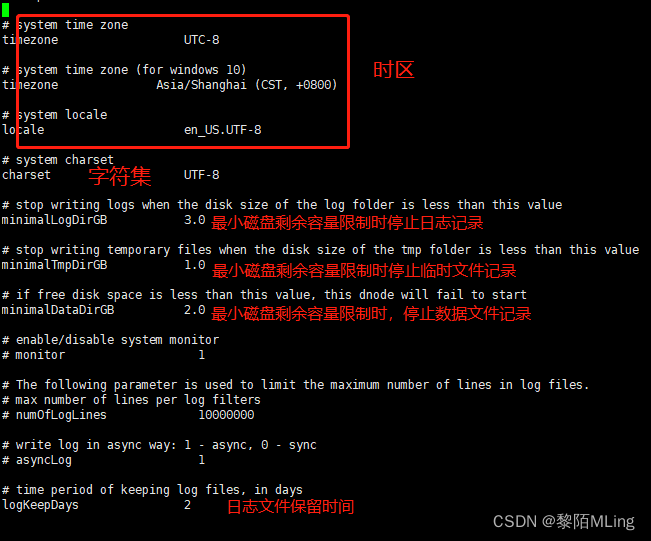
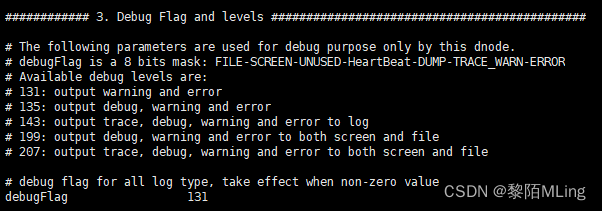
vi /etc/taos/taos.cfg
- 日志文件路径:logDir 数据文件路径:dataDir

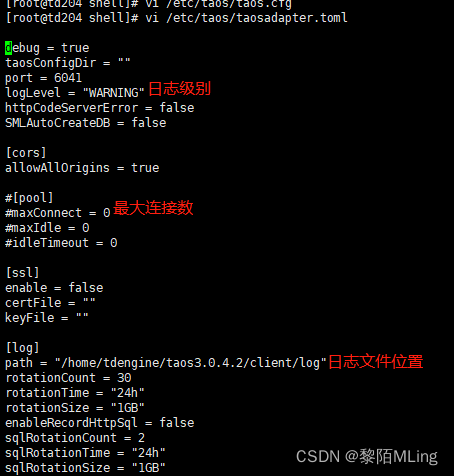
1.2 client taosadapter配置
vi /etc/taos/taosadapter.toml
二、服务启动\停止
- 启动服务:
systemctl start taosd - 查看服务状态:
systemctl status taosd - 停止服务:
systemctl stop taosd - 重启服务:
systemctl restart taosd
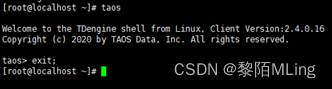
三、进入\退出taos shell命令
四、节点管理
TD官方链接:SQL手册-集群管理
- 查看数据库参数:
show variables; - 查看数据节点:
show dnodes; - 查看管理节点 :
show mondes; - 添加数据节点 :
create dnode “xxxx.com:6030” ; - 删除数据节点 :
drop dnode “xxxx.com:6030”;
要添加新节点,需要节点间以下参数相同:(1.查看数据库参数—>中查出来的参数值)
1. numOfMnodes:系统中管理节点个数。默认值:3。
2. balance:是否启动负载均衡。0:否,1:是。默认值:1。
3. mnodeEqualVnodeNum: 一个mnode等同于vnode消耗的个数。默认值:4。
4. offlineThreshold:>dnode离线阈值,超过该时间将导致该dnode从集群中删除。单位为秒,默认值:86400*10(即10天)。
5. statusInterval: dnode向mnode报告状态时长。单位为秒,默认值:1。
6. maxTablesPerVnode:>每个vnode中能够创建的最大表个数。默认值:1000000。
7. maxVgroupsPerDb:>每个数据库中能够使用的最大vgroup个数。
8. arbitrator: 系统中裁决器的end point,缺省为空。
9. timezone、locale、charset 的配置见客户端配置。
五、用户管理
taos 数据库
root用户的默认密码为:taosdata
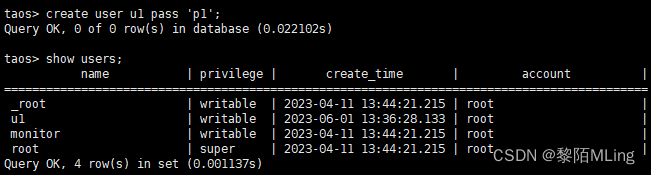
- 添加用户 :
create user 用户名 pass ‘密码’;
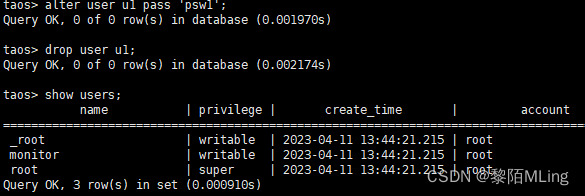
注:创建用户,并指定用户名和密码,密码需要用单引号引起来,单引号为英文半角 - 删除用户 :drop user 用户名;
- 查看用户: show users;
- 修改用户密码 : alter user 用户名 pass ‘新密码’;
- 修改用户权限 :alter user 用户名 privilege read;
注:系统内共有 super/write/read 三种权限级别,但不允许把 super 权限赋予用户。
回到目录 回到末尾
六、数据库登录
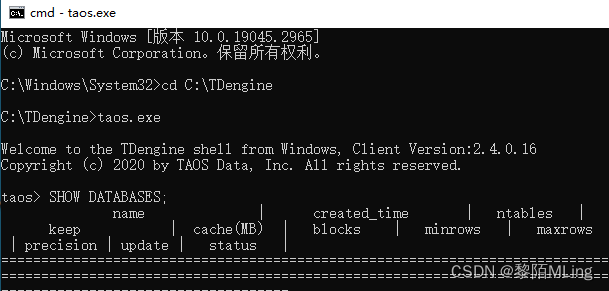
- 登录数据库:
taos -uroot -p密码
如:
taos -uroot -p123456 ;
七、数据库管理
- 创建库(如果不存在):
#keep 字段是指文件在表存储的时间,默认是天
create database if not exists 库名 keep n days m blocks k;
如:
create database if not exists mydb keep 365 days 10 blocks 4;
TDEngine3.x版本建库语句有变化,详见:TDengine3.0与2.0版本的差异总结
- 使用库:
use 库名;
- 删除库(如果存在):
#(如果存在)
drop database [if exists] 库名;
- 显示所有数据库:
show databases;
TDEngine3.x版本建库语句有变化,详见:TDengine3.0与2.0版本的差异总结
- 修改数据库属性:
TDEngine3.x版本建库语句有变化,详见:TDengine3.0与2.0版本的差异总结
(1)修改数据库文件压缩标志位:
alter database 库名 comp 位数;
如:
lter database mydb quorum 2;
(2)修改数据库副本数:
alter database 库名 replica 数量;
如:
alter database mydb replica 2;
(3)修改数据文件保存的天数:
alter database 库名 keep 天数;
如:
alter database mydb keep 35;
(4)修改数据写入成功所需要的确认数:
alter database 库名 quorum 数目;
如:
alter database mydb quorum 2;
(5) 修改每个VNODE (TSDB) 中有多少cache大小的内存块:
alter database 库名 blocks 大小;
如:
alter database mydb blocks 100;
- 查看数据库创建语句:
SHOW CREATE DATABASE db_name \G;
八、表管理
8.1 超级表操作
- 创建超级表
创建STable, 与创建表的SQL语法相似,但需指定TAGS字段的名称和类型。说明:
1) TAGS 列的数据类型不能是timestamp类型;
2) TAGS 列名不能与其他列名相同;
3) TAGS 列名不能为预留关键字;
4) TAGS 最多允许128个,可以0个,总长度不超过16k个字符
CREATE STABLE [IF NOT EXISTS] stb_name (create_definition [, create_definition] ...) TAGS (create_definition [, create_definition] ...) [table_options]
如:
creates stable if not exists st(time timestamp, column_name int) tags (t1 nchar(50), t2 nchar(100));
- 查看超级表
(1)显示当前数据库下的所有超级表信息
#查看数据库内全部 STable,及其相关信息,包括 STable 的名称、创建时间、列数量、标签(TAG)数量、通过该 STable 建表的数量。
SHOW STABLES [LIKE tb_name_wildcard];
#如:显示当前数据库下的所有超级表信息
show stables like "%super%";
TDEngine3.x版本建库语句有变化,详见:TDengine3.0与2.0版本的差异总结
(2)显示一个超级表的创建语句
#对一个已经存在的超级表,返回其创建语句;在另一个集群中执行该语句,就能得到一个结构完全相同的超级表。常用于数据库迁移。
SHOW CREATE STABLE stb_name \G;
(3)获取超级表的结构信息
# 返回结果集的第一列为子表名,后续列为标签列。
DESCRIBE [db_name.]stb_name;
如:describe super_table ;
(4)获取超级表中所有子表的标签信息
SHOW TABLE TAGS FROM stbname;
如:SHOW TABLE TAGS FROM st;
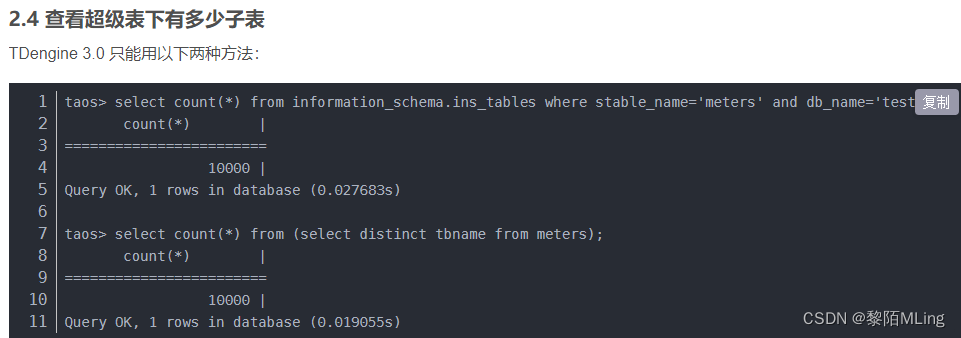
(5)超级表下的子表查询
TDEngine 2.x版本查询:
select tbname,tagname from 超级表名称 【where子句】
如:
select tbname,t1,t2 from alarms where tbname like '%BX0103%';
TDEngine 3.x版本查询:
select * from information_schema.ins_tables where 子句;
#示例
select table_name,db_name,stable_name from information_schema.ins_tables where stable_name = 'datan';

3. 删除超级表
#删除 STable 会自动删除通过 STable 创建的子表以及子表中的所有数据。
DROP STABLE [IF EXISTS] [db_name.]stb_name
- 修改超级表
修改超级表的结构会对其下的所有子表生效。无法针对某个特定子表修改表结构。标签结构的修改需要对超级表下发,TDengine 会自动作用于此超级表的所有子表。
(1)超级表增加列
ALTER STABLE stb_name ADD COLUMN col_name column_type;
如:alter table super_table add column column_name int;
(2)超级表删除列
ALTER STABLE stb_name DROP COLUMN col_name;
如:alter table super_table drop column column_name;
(3)添加标签
ALTER STABLE stb_name ADD TAG tag_name tag_type;
如:alter table super_table add tag column nchar(60);
(4)删除标签
ALTER STABLE stb_name DROP TAG tag_name;
如:alter table super_table drop tag tag_name;
(5)修改标签名
ALTER STABLE stb_name change TAG old_tag_name new_tag_name;
如:alter table super_table change tag old_tag_name new_tag_name;
(6)修改子表标签值(TAG)
alter table item_table_name set tag column_key = “value”;
- 超级表查询
使用 SELECT 语句可以完成在超级表上的投影及聚合两类查询,在 WHERE 语句中可以对标签及列进行筛选及过滤。
如果在超级表查询语句中不加 ORDER BY, 返回顺序是先返回一个子表的所有数据,然后再返回下个子表的所有数据,所以返回的数据是无序的。如果增加了 ORDER BY 语句,会严格按 ORDER BY 语句指定的顺序返回的。
解释一下(超级表)super_table,(子表)sub_table,(标签)Tag之间的关系:
在物联网中,假设我们现在有一个小区的电表设备需要联网。那么电表就会存在张三家的电表,李四家的电表,张三家电表的电流和电压,李四家的电流和电压,以及王五等等家的设备信息。
那么,作为电表这个物联设备,就可以设计成超级表super_table,这样电表就有了张三的电表sub_table1,李四家的电表sub_table2,等等,电流和电压就是超级表中定义表字段属性,而电表所属的业主名称,小区地址可以存放在TAG。
这个场景中,我们就可以下如下创建语句:
(1)创建电表超级表:super_table
create database mydb;
use mydb;
create table super_dianbiao(ts timestamp,dianya float,dianliu float) tags (yezhu_name nchar(15),xiaoqu_location nchar(50),menpai_num nchar(10));
(2)创建子表dianbiao……
create table dianbiao1001 using super_dianbiao tags(‘张三’,‘东城小区’,‘1-1101’);
create table dianbiao1002 using super_dianbiao tags(‘李四’,‘东城小区’,‘1-1102’);
(3)往子表中插入数据
insert into dianbiao1001 values(now,1.7,3.2);
8.2 表操作
- 创建表
创建表时timestamp 字段必须为第一个字段类型为主键
CREATE TABLE [IF NOT EXISTS] [db_name.]tb_name (create_definition [, create_definition] ...) [table_options]
示例:
(1)创建普通表:
CREATE TABLE IF NOT EXISTS a(c timestamp,b int)
(2)根据超级表创建子表
#这样建表之后,子表会复制除去超级表里面的tags字段外的所有字段;
create table table_name using super_table tags (column_value,column_value……);
- 删除数据表
drop table if exists 表名;
- 显示当前数据库下的所有数据表信息
show tables;
- 显示当前数据库下的所有数据表信息
show tables like "%table_name%";
- 获取表的结构信息
describe 表名;
- 表增加列
alter table mytable add column addfield int;
- 表删除列
alter table mytable drop column addfield;
- 显示表的创建语句
#对一个已经存在的表,返回其创建语句;在另一个集群中执行该语句,就能得到一个结构完全相同的表。常用于数据库迁移。
SHOW CREATE TABLE stb_name \G;
九、数据导入、导出
为方便数据导出,TDengine 提供了两种导出方式,分别是按表导出和用 taosdump 导出。
9.1 taosdump批量导出
TD官方链接:参考手册-taosdump
实战链接:TDEngine - taosdump的安装与使用实战
9.2 按表导入、导出 – csv
9.2.1 子表数据的导出
如果用户需要导出一个表或一个 STable 中的数据,表 tb_name 中的数据就会按照 CSV 格式导出到文件 data.csv 中.
- 创建目录
- 创建对应的数据文件 :文件名.csv
- 在taos shell命令执行sql语句导出:
select * from子表名称 >> 文件目录/文件名称.csv ;
如:
select * from bx0101_tlt02s >> bx0101_tlt02s.csv ;
9.2.2 子表数据导入
TDengine 也支持在 shell 对已存在的表从 CSV 文件中进行数据导入。CSV 文件只属于一张表且 CSV 文件中的数据格式需与要导入表的结构相同,在导入的时候,其语法如下:
- 创建子表
- 文件预处理:从数据库导出的csv文件第一行是表结构描述信息,如下所示:
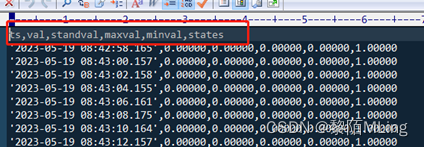
如果 CSV 文件首行存在描述信息,请手动删除后再导入。如某列为空,填 NULL,无引号。 - 在taos shell命令执行sql语句导入:
insert into 子表名称 file '文件名称';
如:insert into bx0102_tlt02s file 'bx0102_tlt02s.csv' ;

十、TDengine3.0与2.0版本的差异
十一、数据库升级及数据同步
十二、 更多

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐


 2
2 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)