
springboot中过滤器@WebFilter的使用以及简单介绍限流算法
本文针对springboot中过滤器@WebFilter的使用进行简单介绍,包括一些名词概念、使用方法和使用场景等等,同时引出一些限流算法的简单介绍
文章目录
一、名词解释
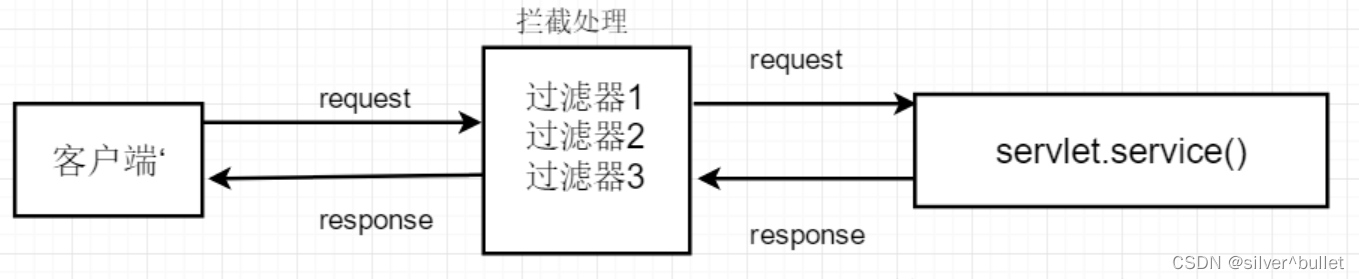
过滤器(Filter)实际上就是对web资源进行拦截,做一些处理后再交给下一个过滤器或servlet处理,通常都是用来拦截request进行处理的,也可以对返回的response进行拦截处理,大致流程如下图
二、使用方式
package filter;
import javax.servlet.*;
import javax.servlet.annotation.WebFilter;
import javax.servlet.annotation.WebInitParam;
import java.io.IOException;
@WebFilter(filterName = "MyFilter",
urlPatterns = "/*",/*通配符(*)表示对所有的web资源进行拦截*/
initParams = {
@WebInitParam(name = "test", value = "1")/*这里可以放一些初始化的参数*/
})
public class MyFilter implements Filter {
private String filterName;
private String test;
public void destroy() {
/*销毁时调用*/
System.out.println(filterName + "销毁");
}
public void doFilter(ServletRequest req, ServletResponse resp, FilterChain chain)
throws ServletException, IOException {
/*过滤方法 主要是对request和response进行一些处理,然后交给下一个过滤器或Servlet处理*/
System.out.println(filterName + "doFilter()");
chain.doFilter(req, resp);
}
public void init(FilterConfig config) throws ServletException {
/*初始化方法 接收一个FilterConfig类型的参数 该参数是对Filter的一些配置*/
filterName = config.getFilterName();
test= config.getInitParameter("test");
System.out.println("过滤器名称:" + filterName);
System.out.println("测试值:" + test);
}
}
三、使用场景
1. 字符集统一设置
public void doFilter(ServletRequest req, ServletResponse resp, FilterChain chain)
throws ServletException, IOException {
req.setCharacterEncoding("utf-8");
resp.setCharacterEncoding("utf-8");
chain.doFilter(req, resp);
}
2. 敏感参数加密
一般情况下,我们针对一些敏感的参数,例如密码、身份证号等,给它加密,防止报文明文传输,加密可以分为大体的两类,对称加密和非对称加密,下面,简单介绍下这两种方式。
- 对称加密
加密使用的密钥和解密使用的密钥是同一个,例如sm4加密,这样的加密方式简单,只需要加解密双方都有密钥即可,但是这样很不安全,一旦密钥泄漏,数据就会被解密。 - 非对称加密
非对称加密就是加密使用一个密钥(一般称为公钥),解密使用另一个密钥(一般称为私钥),常见的算法有RSA算法、sm2算法,这种情况下,私钥一般由解密方独立保存,极大提高了数据的安全性。如果要对所有请求参数加密,推荐使用https请求,因为https请求原理上也是非对称加密实现的,这里不做过多赘述。
3. 加签验签
我们对参数进行了加密,那么数据是否安全了呢?答案是否定的,因为我们只是保证了传入参数不被别人知道,但是我们的请求或响应是可以被篡改拦截的,那么,就需要引入新的方案,加签验签。
- 加签
用Hash函数把原始报文生成报文摘要,然后对这个摘要进行加密,就得到这个报文对应的数字签名。一般情况下,客户端会将签名和原始报文一起发给服务端。
//accessKey理解为一个盐值,signPriKey是加密私钥,map是请求参数
public static String sign(String accessKey, String signPriKey, Map<String, String> map) {
//sort方法主要用于参数排序及过滤,过滤掉key为sign的参数
String paramStr = sort(map);
//生成的摘要
String abstractText = SM3Digest.sm3Encry(paramStr + accessKey);
//非对称加密生成签名
return SMHelper.sm2Sign(signPriKey, abstractText);
}
public static String sort(String jsonString){
JSONObject jsonObject = JSON.parseObject(jsonString);
String aa = jsonObject.toJSONString();
List<String> list = new ArrayList();
for(Entry<String, Object> entry : jsonObject.entrySet()){
String key = entry.getKey();
//主要关注这里,排除了sign参数,因为sign签也是要作为参数传递给服务端的,但是客户端加签时还没有sign签
if ("sign".equals(key)){
continue;
}
String value = null;
if (entry.getValue() instanceof JSONObject || entry.getValue() instanceof JSONArray){
value = JSON.toJSONString(entry.getValue());
} else {
value = (String)entry.getValue();
}
String str = key+value;
list.add(str);
}
Collections.sort(list, new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
try {
String s1 = new String(o1.toString().getBytes("UTF-8"), "ISO-8859-1");
String s2 = new String(o2.toString().getBytes("UTF-8"), "ISO-8859-1");
return s1.compareTo(s2);
} catch (Exception e) {
e.printStackTrace();
}
return 0;
}
});
StringBuffer paramStr = new StringBuffer();
for(String param : list){
paramStr.append(param);
}
return paramStr.toString();
}
- 验签
接收方拿到原始报文和sign签名后,用同一个Hash函数从报文中生成服务端摘要。然后用对方提供的公钥对数字签名进行解密,得到客户端摘要,对比两个摘要是否相同,就可以得知报文有没有被篡改过。
/ca是证书,存储了验签公钥等信息,sign是客户端的签名
private boolean sign(AuthSecCa ca, String sign, Map<String, String> param) {
//相同的排序hash方法
String paramStr = Sort.sort(param);
//生成服务端摘要
String design = SM3Digest.SM3Encry(paramStr + ca.getAccessKey());
// 验签
boolean b = SMHelper.sm2Verify(ca.getSignPubKey(), design, sign);
return b;
}
4. 时间戳验证
大体思路就是请求参数加上一个请求时间戳dataStamp,服务端获取到这个时间戳后,获取一个当前的时间戳serverStamp,然后这两个时间戳的差值少于多长时间才算有效请求。
private boolean verifyDataStamp(String time) {
boolean flag = false;
long nowTime = System.currentTimeMillis();
if (StringUtils.isNotEmpty(time)) {
long t = Long.parseLong(time);
//时间间隔超过1分钟
int stampInt = stamp;
if (Math.abs(nowTime - t) > stampInt * 1000) {
flag = true;
}
}
return flag;
}
5. 请求随机数验证
我们需要给请求加上一个唯一的随机数nonce,每次请求过来把nonce拿到,判断是否已经又过了,来考虑是否放行请求,但是如果存储大量的nonce对我们的系统来说也是巨大的压力,因此配合时间戳一起使用,例如,时间戳是一分钟,我们可以设置nonce的有效期为两分钟(大于一分钟即可,避免极端情况)
private boolean verifyNonce(String nonce) {
if (StringUtils.isEmpty(nonce)) {
return true;
}
if (缓存.isExist(nonce)) {
return false;
}
缓存.setWithExpire(nonce, 120);
return true;
}
6. 黑、白名单
我们可以在本身的后台管理系统中添加黑名单及白名单的相关配置,对于黑名单发起的请求,直接返回错误码;对于一些特别敏感的操作,例如涉及到转账等,只有在白名单中的请求才可以操作。
private boolean verifyBlack(String serviceId, String uri) {
boolean flag = 缓存.get(serviceId, uri);
log.info("api黑名单是否存在,serviceId:"+serviceId+",uri:"+uri+" -> 结果:"+flag);
return flag;
}
7. 服务限流
介绍一个常见的限流算法,令牌桶限流。它的思路为:
对于每个要限流的对象(比如一个user,或者一个接入证书),分配一个bucket;
bucket里的tokens以一个固定的速率在增加,bucket有个最大容量,到了最大容量就不再增加了;
每个请求会消耗一定的token数量,如果bucket内的token数量有剩余则请求通过;否则拒绝请求;
下面是通过引入guava的单机版限流RateLimiter做的一个限流demo
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>31.1-jre</version>
</dependency>
public class test {
//每秒钟生成4个token
private static final RateLimiter rateLimiter = RateLimiter.create(4);
public static void main(String[] args) throws InterruptedException {
for (int i = 0; i < 10; i++) {
new Thread(()->{
//每次请求消耗一个token
if(rateLimiter.tryAcquire()){
System.out.println("请求成功");
}else{
System.out.println("限流了");
}
}).start();
//每个请求相隔1/5秒
Thread.sleep(200);
}
}
}
四、额外知识补充
补充几种限流算法知识
1. 固定窗口限流
介绍:单位时间(固定时间窗口)内限制请求的数量,即将时间分为固定的窗口,限制每个窗口的请求数量;
缺点:存在临界问题,例如0-1和1-2是两个时间窗口,若在0.8-1s内有5个请求,在1-1.2s内有5个请求,虽然在各自的窗口上没有超限,但是在0.8-1.2s这个时间范围内超限了;
实现:假设单位时间是1s,限流阈值为5,在单位时间内,每来一次请求,计数器count +1,若count>5,后续请求全部拒绝,等到1s结束,count清零;
//计数器
public static AtomicInteger count = new AtomicInteger(0);
//时间窗口,单位s
public static final Long window = 1000L;
//窗口阈值
public static final int threshold = 5;
//上次请求时间
public static long lastAcquireTime = 0L;
public static synchronized boolean fixedWindowTryAcquire(){
//当前系统时间
long currentTime = System.currentTimeMillis();
//看看本次请求是否在窗口内
if(currentTime - lastAcquireTime > window){
//重置计数器和上次请求时间
count.set(0);
lastAcquireTime = currentTime;
}
//检查计数器是否超过阈值
if(count.incrementAndGet() <= threshold){
return true;
}
return false;
}
2. 滑动窗口限流
介绍:在固定窗口中,存在临界问题,那么,如果我们让这个小窗口动起来,不断去删除已经过去的时间,这样,动态的判断是否超限就可以了;
缺点:无法应对突发流量(短时间大量请求),许多请求会被直接拒绝;
实现:假设单位时间是100s(单位窗口),限流阈值为5,我们将单位窗口分为10个小窗口(每个小窗口为10s),然后不断的更新每个小窗口的请求和小窗口的起始时间,这样就模拟表现为动起来了
//时间窗口,单位s
public static final Long window = 100L;
//窗口阈值
public static final int threshold = 5;
//小窗口个数
public static final int windowCount = 10;
//存储每个小窗口开始时间及其流量
public static Map<Long, Integer>windowCounters = new HashMap<>();
public static synchronized boolean tryAcquire(){
//取当前时间,做了取整操作,保证在同一个小窗口内的时间落到同一个起点,将时间戳取秒计算,方便理解
long currentTime = System.currentTimeMillis()/1000 / windowCount * windowCount;
int currentCount = calculate(currentTime);
if(currentCount > threshold){
return false;
}
windowCounters.put(currentTime - windowCount* (window/windowCount-1),currentCount);
return true;
}
private static int calculate(long currentTime) {
//计算小窗口开始时间
//这里可以理解为 currentTime - entry.key > window/windowCount
long startTime = currentTime - windowCount* (window/windowCount-1);
System.out.println(startTime);
int count = 1;
//遍历计数器
Iterator<Map.Entry<Long,Integer>> iterator = windowCounters.entrySet().iterator();
while (iterator.hasNext()){
Map.Entry<Long,Integer>entry = iterator.next();
//删除无效过期的子窗口
if(entry.getKey() < startTime){
iterator.remove();
System.out.println("移除了");
}else{
//累加请求
count = entry.getValue()+1;
}
}
return count;
}
3. 漏桶算法
介绍:对于每个请求,检查漏桶是否有容量,没有直接拒绝;有的话放入漏桶,漏桶以一定速率处理桶内的请求,生产者-消费者模型,请求作为生产者,系统作为消费者;
缺点:需要缓存请求,面对突发流量,处理不能及时响应
实现:假设漏桶容量为5,速率为1个/s,那么我们还需要有一个当前的水量和当前时间分别用来判断是否可以存放请求和消耗请求
public class leakBucket {
//漏桶的容量
private long capacity;
//滴水(消耗请求)速率
private long rate;
//当前桶中的水(未消耗的请求)
private long water;
//上次滴水时间(用来计算现在要消耗多少个)
private long lastLeakTime;
public leakBucket(long capacity, long rate, long water, long lastLeakTime) {
this.capacity = capacity;
this.rate = rate;
this.water = water;
this.lastLeakTime = lastLeakTime;
}
}
public static synchronized boolean tryAcquire(){
leak();
//判断是否有空间,这里我设为每个请求都要判断,也可以直接传参多少个请求
if(leakBucket.getWater()+1 <leakBucket.getCapacity()){
leakBucket.setWater(leakBucket.getWater()+1);
return true;
}
return false;
}
private static void leak() {
//当前时间,以秒操作
long currentTime = System.currentTimeMillis() / 1000;
//最后一次漏水到现在应该漏多少
long leakWater = (currentTime - leakBucket.getLastLeakTime()) * leakBucket.getRate();
if(leakWater > 0){
leakBucket.setWater(Math.max(0,leakBucket.getWater() - leakWater));
leakBucket.setLastLeakTime(currentTime);
}
}
4. 令牌桶算法
介绍:令牌桶算法相当于漏桶算法的翻版,之前说过,漏桶算法生产者是客户端,令牌桶是服务端作为生产者,以一定速率生成令牌放入桶中,桶满丢弃令牌,每次来一个请求消耗一个令牌,没有令牌就丢弃请求;相对于漏桶算法变化:生产者–>服务端,更符合限流的定义;消费者–>客户端,不需要另外的存储请求;
缺点:令牌桶算法需要在固定的时间间隔内生成令牌,因此要求时间精度较高,如果系统时间不准确,可能会导致限流效果不理想
实现:
public class tokenBucket {
//令牌桶的容量
private long capacity;
//生成令牌的速率
private long rate;
//当前桶中的令牌数
private long tokenNum;
//上次生成令牌的时间
private long lastMakeTime;
public tokenBucket(long capacity, long rate, long tokenNum, long lastMakeTime) {
this.capacity = capacity;
this.rate = rate;
this.tokenNum = tokenNum;
this.lastMakeTime = lastMakeTime;
}
}
public static synchronized boolean tryAcquire(){
makeToken();
if(tokenBucket.getTokenNum() > 0){
tokenBucket.setTokenNum(tokenBucket.getTokenNum() - 1);
return true;
}
return false;
}
private static void makeToken() {
//当前时间,以秒计算
Long currentTime = System.currentTimeMillis() / 1000;
if(currentTime > tokenBucket.getLastMakeTime()){
//计算应该生成多少令牌
long makeNums = (currentTime - tokenBucket.getLastMakeTime()) * tokenBucket.getRate();
//放入令牌桶,多余容量的抛弃
tokenBucket.setTokenNum(Math.min(tokenBucket.getCapacity(),makeNums+tokenBucket.getTokenNum()));
//更新生成令牌时间
tokenBucket.setLastMakeTime(currentTime);
}
}

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)