

LiteFlow规则引擎的入门
LiteFlow是一个非常强大的现代化的规则引擎框架,融合了编排特性和规则引擎的所有特性。利用LiteFlow,你可以将瀑布流式的代码,转变成以组件为核心概念的代码结构,这种结构的好处是可以任意编排,组件与组件之间是解耦的,组件可以用脚本来定义,组件之间的流转全靠规则来驱动。LiteFlow拥有开源规则引擎最为简单的DSL语法。十分钟就可上手。详细可见官网:https://liteflow.yom
文章目录
1、LiteFlow简介
LiteFlow是一个非常强大的现代化的规则引擎框架,融合了编排特性和规则引擎的所有特性。
利用LiteFlow,你可以将瀑布流式的代码,转变成以组件为核心概念的代码结构,这种结构的好处是可以任意编排,组件与组件之间是解耦的,组件可以用脚本来定义,组件之间的流转全靠规则来驱动。LiteFlow拥有开源规则引擎最为简单的DSL语法。十分钟就可上手。
详细可见官网:https://liteflow.yomahub.com/
2、解决的痛点
-
复杂的业务逻辑、多变的条件的系统,维护困难、测试困难,导致不愿意有人维护项目。以至于不得不修改业务逻辑的时候,都是通过打补丁的方式,导致系统更加臃肿、一出问题难以排查。业务的多变导致小版本的不断迭代,其他开发人员接手项目时,感觉压力山大,心中一万只羊驼奔腾而过…
-
业务多变的条件,可以随时修改,而不改变代码本身。比如根据价格的不同的区间段,返回不同的折扣。
这样的系统彻底重构的话,就可以用到LiteFlow去优化。通过将复杂的逻辑和业务代码拆分成一个个独立的子单元,每一个子单元就是一个Bean,然后通过规则引擎根据需求编排每一个子单元。就像搭积木一样,最终组装成一个完整的产品,子单元还可以公用。
多变的条件,可用通过热部署的方式,随时修改分支的走向。
3、快速开始
3.1 引入依赖
以Springboot项目搭建为例
<dependency>
<groupId>com.yomahub</groupId>
<artifactId>liteflow-spring-boot-starter</artifactId>
<version>{latest.version}</version>
</dependency>
3.2 配置规则文件的位置
规则文件支持3中方式:
-
xml
-
json
-
yml
以下通过xml的形式说明,笔者以为xml文件使用更方便。
主要是为了配置规则引擎的路径(xml文件的位置)。旧版本里面必须是xxx.el.xml结尾,新版本中已经取消了限制只要是.xml结尾即可
这里只配置必须的参数,其他都是默认。详细配置请参考官网
liteflow:
#规则文件路径
rule-source: config/flow.el.xml
3.3 定义组件
组件其实就是一个Bean,继承LiteFLow提供的不同NodeComponent。

这里以最简单的NodeComponent为例。
@LiteflowComponent 注解中的value属性就是规则文件中的名称,name是名称的别名
@LiteflowComponent(value = "a", name = "Liteflow")
public class Anode extends NodeComponent {
@Override
public void process() throws Exception {
System.out.println(">>>>>>>Anode 被调用了。。。。。" + this.getRequestData() +">>>>" +this.getContextBean(Book.class));
}
}
@LiteflowComponent("b")
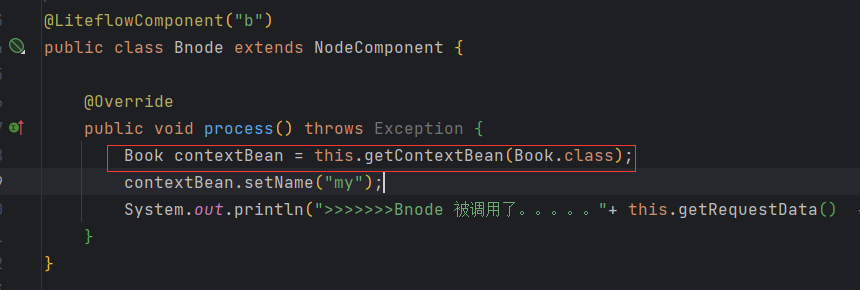
public class Bnode extends NodeComponent {
@Override
public void process() throws Exception {
Book contextBean = this.getContextBean(Book.class);
contextBean.setName("my");
System.out.println(">>>>>>>Bnode 被调用了。。。。。"+ this.getRequestData() +"oooooooooooooooooooooooo" + contextBean);
}
}
@LiteflowComponent("c")
public class Cnode extends NodeComponent {
@Override
public void process() throws Exception {
System.out.println(">>>>>>>Cnode 被调用了。。。。。"+ this.getRequestData() +">>>>" +this.getContextBean(Book.class));
}
}
3.4 指定规则
也就是编写规则文件
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE flow PUBLIC "liteflow" "liteflow.dtd">
<flow>
<chain name="chain1">
THEN(a, b, c);
</chain>
</flow>
THEN 是规则文件中的关键字,表示串行执行。执行顺序:a->b-c
3.5 编写客户端
客户端中指定了一个Book的参数,是为了验证上下文的,可以忽略。
@SpringBootTest
class SimonkingLiteflowApplicationTests {
@Resource
private FlowExecutor flowExecutor;
@Test
void contextLoads() {
Book book = new Book();
book.setName("wsss:" + Thread.currentThread().getName());
LiteflowResponse response = flowExecutor.execute2Resp("chain1", "arg****************", book);
System.out.println("response:" + JSON.toJSONString(response));
}
}
3.6 运行以及说明
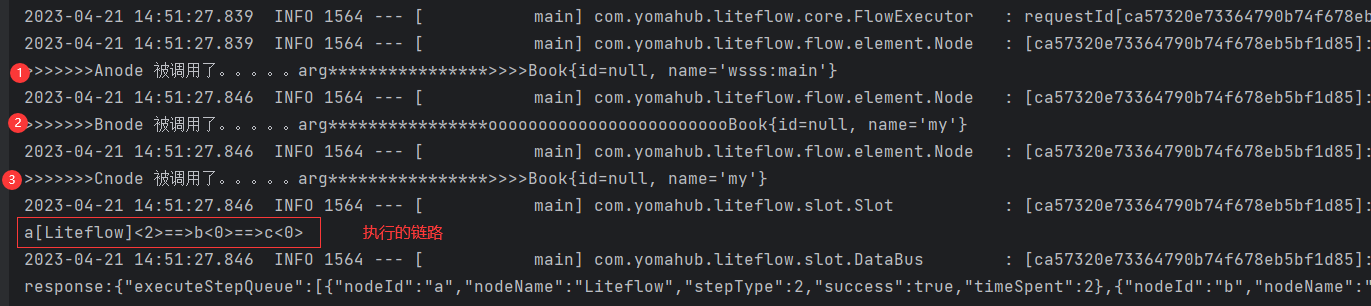
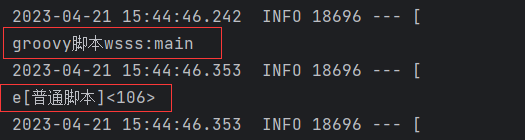
可以看出按照指定的规则运行了,还打印出了执行的链路。其中[]代表别名,<>代表耗时ms。至此我们就已经入门了。哈哈哈…
3.7 其他的组件
上面的例子我们只是用了普通组件,除了普通组件之外还有一下几种。

-
选择组件:关键字SWITCH,继承NodeSwitchComponent,实现processSwitch方法,表达式如下:<chain name="chain1"> SWITCH(a).to(b, c); </chain> -
条件组件:关键字IF...ELIF...ELSE,继承NodeIfComponent,实现processIf方法,表达式如下:<chain name="chain1"> IF(x, a, b); </chain> -
次数循环组件:关键字FOR...DO...,继承NodeForComponent,实现processFor方法,表达式如下:<chain name="chain1"> FOR(f).DO(THEN(a, b)); </chain> -
条件循环组件:关键字WHILE...DO...,继承NodeWhileComponent,实现processWhile方法,表达式如下:<chain name="chain1"> WHILE(w).DO(THEN(a, b)); </chai -
迭代循环组件:关键字ITERATOR...DO...,继承NodeIteratorComponent,实现processIterator方法,表达式如下:<chain name="chain1"> ITERATOR(x).DO(THEN(a, b)); </chain> -
退出循环组件:关键字BREAK,继承NodeBreakComponent,实现processBreak方法,主要用于以下组合:FOR...DO...BREAK,WHILE...DO...BREAK,ITERATOR...DO...BREAK表达式如下:
<chain name="chain1"> FOR(f).DO(THEN(a, b)).BREAK(c); </chain> <chain name="chain1"> WHILE(w).DO(THEN(a, b)).BREAK(c); </chain>
4、对于快速开始的思考
规则引擎的使用,我们算是已经入门了,可以使用这个框架了。但是如果应用到我们的实际业务场景中,有没有什么疑问呢?
Q: 如果有参数,参数如何传递下一个组件?
A: LiteFlow的设计理念是将所有的业务数据存放在上下文中,类似于Spring中的ApplicationContext,组件于组件之间不传递参数。这样一来,就从数据层面一定程度的解耦了。从而达到可编排的目的。
Q: 既然有上下文,上下文是怎么定义的?
A:
-
LiteFlow提供了一个默认的数据上下文的实现:
DefaultContext。这个默认的实现其实里面主要存储数据的容器就是一个Map。官方建议我们自己去实现自己数据上下文。 -
上下文的定义起其实就是我们定义的一个类,只要传进去,整个链路共享这个类型,如案例中的Book。
flowExecutor.execute2Resp("chain1", "arg****************", book); -
LiteFlow支持多个上下文,可以传递多个上下文对象
Q: 有了上下文之后,其他组件怎么获取?可以修改么?
A:
-
定义组件的时候我们继承的Nodexxx中已经封装了方法,直接通过this调用即可
-
多个上文的时候我们只要指定对用的class即可获取到
-
直接对上下文对象的操作,会直接修改上下文对象。后续节点会拿到最新的上下文数
Q: 既然上下文参数可以修改,开发的时候我们应该注意什么?
A: 上下文共享且可修改,那我们要注意一下几点
-
串行执行的时候,参数封装、校验、获取、操作的顺序,防止业务异常
-
并行执行的时候(多线程),主要只对共享变量读操作,尽量不要写操作。防止数据错乱
-
条件执行的时候,注意不同的跳转,对上下文的操作
Q: 在传递上下文的时候,还有一个参数是流程初始参数(官方文档有描述),它是怎么用的?  A: 这个参数是用来传递初始化参数的,全组件共享,可以不使用,我们直接将所有参数放在上下文中即可。使用的话,也有专门的获取。
A: 这个参数是用来传递初始化参数的,全组件共享,可以不使用,我们直接将所有参数放在上下文中即可。使用的话,也有专门的获取。
this.getRequestData()
5、LiteFlow的脚本组件
LiteFlow框架目前一共支持6种脚本语言:Groovy,Javascript,QLExpress,Python,Lua,Aviator
LiteFlow采用SPI机制进行选择脚本框架来动态编译你的脚本。
官方推荐使用Groovy,因为和java语法是最接近的。以下使用Groovy 为例。
5.1 脚本的定义
脚本组件也是定义在规则文件中的,以xml为例
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE flow PUBLIC "liteflow" "liteflow.dtd">
<flow>
<nodes>
<node id="e" name="普通脚本" type="script" language="groovy">
<![CDATA[
println("groovy脚本wsss:main")
]]>
</node>
</nodes>
</flow>
这里定义了一个e节点,name为别名, type是节点的类型,language代表使用的语言。
Type 的分类:
script:普通脚本节点,脚本里无需返回。
switch_script:选择脚本节点,脚本里需要返回选择的节点Id。
if_script:条件脚本节点,脚本里需要返回true/false。
for_script:数量循环节点,脚本里需要返回数值,表示循环次数。
while_script:条件循环节点,脚本里需要返回true/false,表示什么条件才继续循环。
break_script:退出循环节点,脚本里需要返回true/false,表示什么时候退出循环。
5.2 脚本的使用
脚本的使用就是和Java创建Bean一样,直接通过节点Id就可以,如:
<chain name="chain2">
THEN(e);
</chain>
修改启动类,指定执行的Chain即可
flowExecutor.execute2Resp("chain2", null, null);
5.3 关于脚本使用的思考
Q: 如果脚本定义的节点和Java定义的节点Id一致会怎样?
A: 首先,不会报错,这是令人神奇的地方。经过测试脚本的优先级高于JavaBean。也就是相同时,会调用脚本的节点忽略JavaBean的节点
Q: 脚本的作用是啥?脚本只能单纯的定义节点么?
A: 笔者以为脚本组件为规则引擎提供了更多可能。为什么这么说呢,首先如果依靠脚本编写节点,我们是完全不用编写JavaBean就可以实现规则引擎的调用,当然这个例子有点夸张且不切实际。但是我们可以手动创建节点,并且通过节点控制流程的走向,是不是给我们提供了极大的灵活以及可能。单纯的项目可能想象不了这种灵活,因为不管怎么样我们都需要编写代码并发布。但是,如果搭配中间件(注册发现的组件),我们就可以通过修改脚本节点直接动态控制线上的业务流程的走向,且不用代码发布。这是不是很爽呢。
脚本当然不是单纯的定义节点,他可以实现与上下文的交互,通过不同的节点类型,修改规则链路的走向。
6、规则引擎的配置源
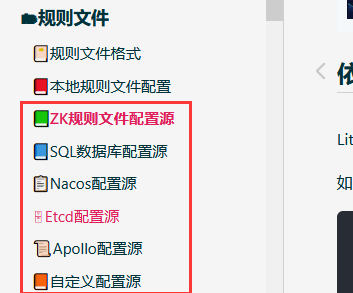
如果所有的规则引擎文件都只是配置在项目里,那么规则引擎的另一大亮点就会被埋没。想象一下如果规则文件可以动态修改,而不用发布代码,对于多变的业务流程场景岂不是很香。官方已经提供了多种配置源:
以Apollo配置源为例
6.1 引入依赖
<dependency>
<groupId>com.yomahub</groupId>
<artifactId>liteflow-rule-apollo</artifactId>
<version>{latest.version}</version>
</dependency>
6.2 配置参数
依赖插件包之后,无需再配置`liteflow.ruleSource`的路径。只允许要配置额外的参数即可:
liteflow:
rule-source-ext-data-map
# 执行链的namespace
chainNamespace: liteFlow
# 脚本组件的namespace
scriptNamespace: liteFlow-script
6.3 配置apollo环境
默认已经安装apollo服务。windows将apollo的连接放置在C:\opt\setting\server.properties
env=DEV
apollo.meta=http://127.0.0.1:8190
idc=local
项目使用apollo为配置中心的的朋友都应该知道,项目中需要指定/META-INF/app.properties中要指定app.id和Apollo中的AppId对应。我们这里需要配置么?
官方文档没有说明要配置,我们先不配置。
6.4 Apollo创建名称空间
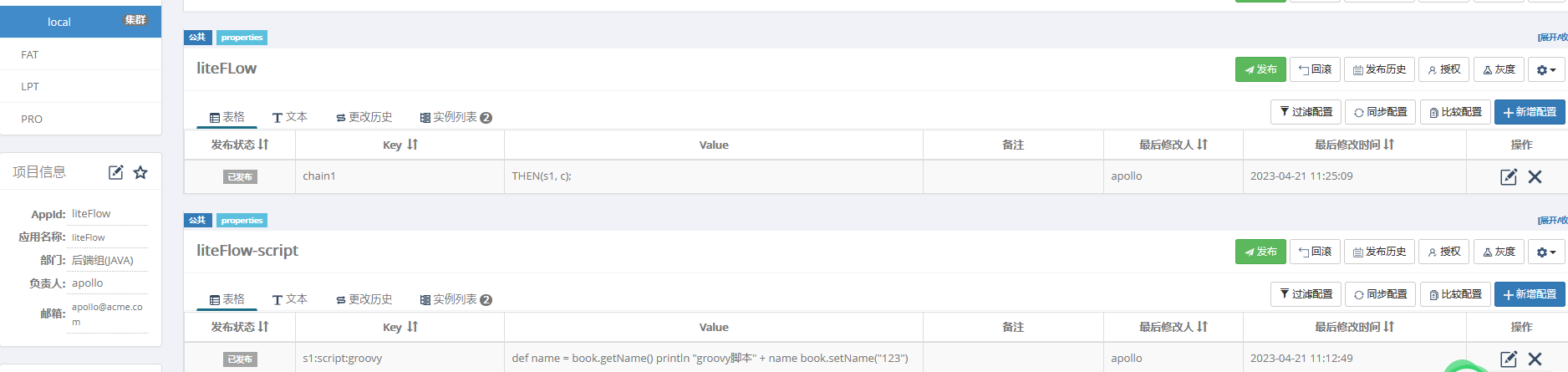
执行链的key为链的名称,value为具体的规则
脚本组件的key有固定格式:脚本组件ID:脚本类型:脚本名称,value为脚本数据
6.5 项目启动查看运行结果
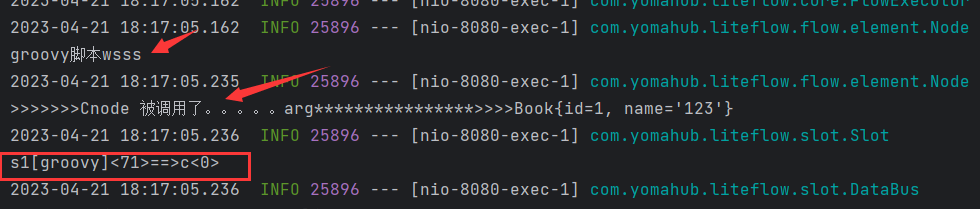
我们看到apollo中配置的已经执行了,和项目中的配置一模一样
6.6 测试app.id是否有效
测试中发现,故意指定一个app.id,项目不会报错并且不会影响正常的链路调用,也就是说namespace是整个集群(local:因为我server.properties中指定idc=local)共享的。app.id配置或者不配置、甚至配错都不会影响规则引擎的执行。
– END

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 4
4 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)