
【论文阅读】CVPR2022 ||Towards Efficient Data Free Black-box Adversarial Attack
经典的黑盒对抗攻击可以利用类似替代模型生成的可转移对抗样本来成功欺骗目标模型。然而,这些替代模型需要通过目标模型的训练数据进行训练,由于隐私或传输原因,很难获得。认识到对抗性查询的真实数据的可用性有限,最近的工作提出在无数据黑盒场景中训练替代模型。然而,他们基于生成对抗网络(GAN)的框架存在收敛失败和模型崩溃的问题,导致效率低下。在本文中,通过重新思考生成器和替代模型之间的协作关系,我们设计了一

实现高效无数据黑盒对抗攻击
对抗场景:一个无法访问真实数据且查询目标模型的预算有限的黑盒模型。
这篇文章是针对迁移攻击的,它通过重新思考生成器和替代模型之间的协作关系,设计了一个新的黑盒攻击框架。
Abstract
经典的黑盒对抗攻击可以利用类似替代模型生成的可转移对抗样本来成功欺骗目标模型。然而,这些替代模型需要通过目标模型的训练数据进行训练,由于隐私或传输原因,很难获得。认识到对抗性查询的真实数据的可用性有限,最近的工作提出在无数据黑盒场景中训练替代模型。然而,他们基于生成对抗网络(GAN)的框架存在收敛失败和模型崩溃的问题,导致效率低下。在本文中,通过重新思考生成器和替代模型之间的协作关系,我们设计了一种新颖的黑盒攻击框架。所提出的方法可以通过少量的查询有效地模仿目标模型,并获得较高的攻击成功率。六个数据集的综合实验证明了我们的方法对最先进的攻击的有效性。特别是,我们对 Microsoft Azure 在线模型进行了仅标签攻击和仅概率攻击,并且在 SOTA 方法的查询预算仅为 0.46% 的情况下实现了 100% 的攻击成功率。
Motivation
在基于迁移的攻击中,很多方法需要先训练一个和目标模型相似的替代模型,然后利用替代模型生成对抗样本去攻击目标模型。
但替代模型需要通过目标模型的训练数据进行训练。 有一些工作提出在无数据黑盒场景中训练替代模型————基于生成对抗网络(GAN)的框架。
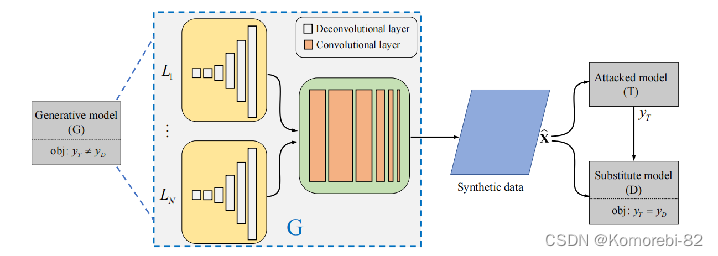
如图中这个方法DaST,让一个生成器负责合成一些输入图像,接着把合成数据输入到目标模型和替代模型中,利用输出结果让替代模型去模仿目标模型。 这个方法主要的训练过程就是一个生成器和替代模型之间的博弈,在这个博弈中,替代模型和生成器分别试图最小化和最大化S和T之间的匹配率。 但是在黑盒场景中精确量化它俩的不一致是很困难的,因此这种不稳定的训练会导致模型存在收敛失败和崩溃的问题。
因此本文设计了一种新的黑盒攻击框架。它改变了生成器和替代模型之间的博弈,将生成器的目标重置为合成分布接近目标训练数据集的代理数据集,替代模型的目标是用生成的训练样本有效的模拟目标模型。生成器和替代模型具有相对独立的优化过程。
Method
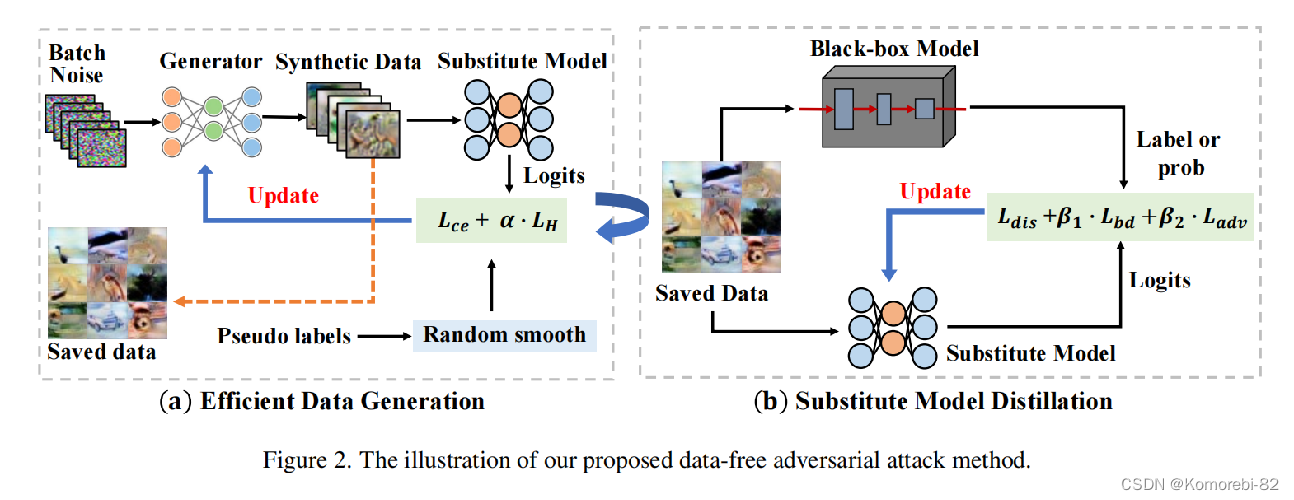
该方法包括两个阶段:1)高效数据生成和2)替代模型蒸馏。这两个阶段具有相对独立的优化过程
在阶段 1 中,给定一批随机噪声Z和伪标签Y,利用生成器G生成所需数据X。 因为生成器G的目标为合成具有与目标训练数据具有相同的分布的数据X。 如果分布相同,那么它们的分类结果也应该相似。 所以用这个损失函数来优化生成器G:
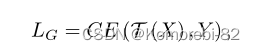
但是这种损失的反向传播需要T的梯度信息,这违反了黑盒的前提,所以用的是替代模型S:
![]()
为了使生成的样本能够覆盖所有类别,本文引入了信息熵来度量分类标签S(x)的混沌程度,当LH达到最大值时,类别越分散,类别分布均匀。(K:类别数)
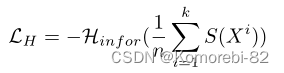
为了进一步提高数据的多样性,引入了随机平滑,来引导生成器合成每个类别中的不同数据。
最终最小化下面的损失函数来更新生成器:
![]()
α:调整正则化的超参数
在阶段 2 中,将上一阶段生成的数据分别输入到目标模型和替代模型中,得到输出结果,因为替代模型的目标是模拟黑盒目标模型,所以第一个损失就是这俩分类结果的距离:
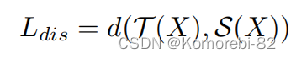
Ldis:对于只有标签的情况,这个测量可以是交叉熵损失,而对于只有概率的情况,d可以是L2范数。
此外作者认为有两种类型的数据需要给予额外的关注,又引入了两类损失。
边界支撑损失:
![]()
主要针对替代模型S和目标模型T在分类过程中出现分歧时的情况。这类数据主要存在于目标模型和替代模型的决策边界之间。 给予这些数据更多的权重有助于弥合两个决策边界之间的差距。
对抗样本支撑损失:
![]()
针对的是在替代模型上产生的对抗样本迁移到目标模型上,有一样的分类结果。 ~~~表明在这附近S和T的决策边界是比较接近的。对这类数据给予更多的关注可以确保S继续朝着接近T边界的正确方向移动。(PGD,会造成额外的查询)
最终损失:
![]()
其中β1和β2控制不同的损失函数值,默认为1。
Code

对于每个epoch,我们运行t次迭代来合成数据x。
首先输入随机噪声Z用生成器生成数据,计算损失函数,进行梯度下降微调生成器的参数,保存合成的数据。
将合成的数据输入到替代模型和目标模型中,计算损失函数,进行梯度下降微调替代模型的参数。
进行攻击时在这个训练好的替代模型上使用一些已有的攻击方法生成攻击样本。
我们在每个epoch随机初始化G。在这种情况下,G只负责这一阶段生成的合成数据, G不直接参与模型蒸馏阶段,只用到替代模型,用不到目标模型。
Experiments

上表显示了在这两个数据集中,仅针对标签和仅针对概率的有目标和无目标攻击下的攻击成功率。 列:训练替代模型的方法 行:生成对抗样本的方法 我们的方法的攻击成功率远高于其他最先进的基线。
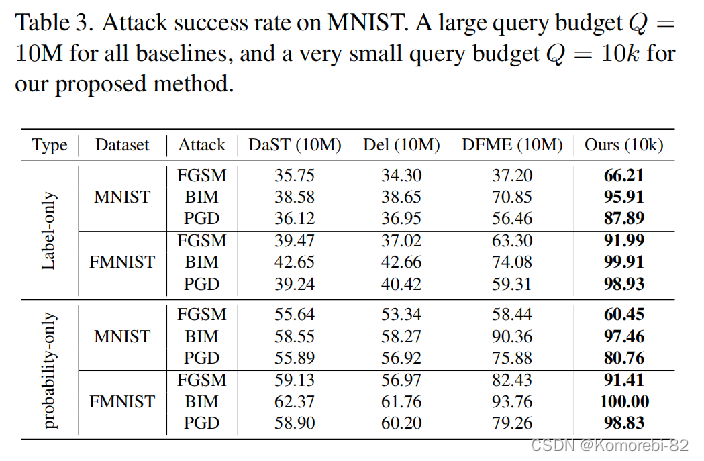
表三显示了在MNIST数据集的攻击成功率。对于所有其他无数据攻击方法给定查询预算Q = 10M,对于我们提出的方法,给定一个非常小的查询预算Q = 10k。可以看到,本文的方法仍然是优于其他方法 这就说明本文的方法比其他的训练替代模型的方法需要的查询次数更少,且攻击结果更好
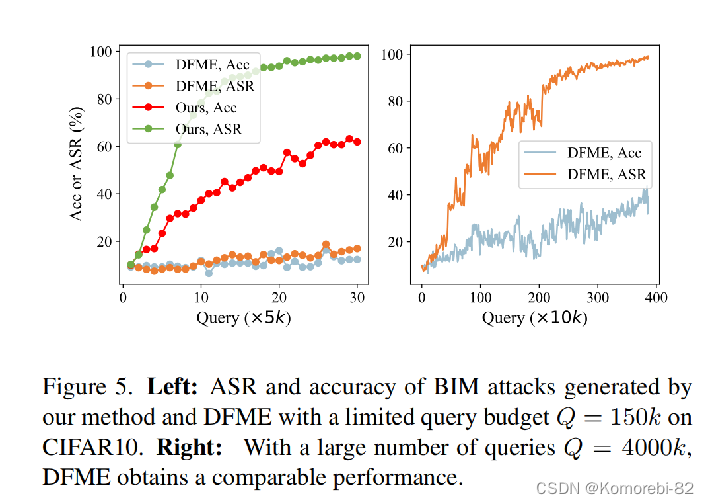
上图我们首先将本文的方法与CIFAR10数据集上的最佳方法DFME进行比较。 如图所示,较小的查询预算会导致DFME的性能比较差。当把查询预算设置为4000k时,DFME的攻击成功率上来了,但准确性还是比较低。(替代模型的准确率)

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐

 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)