Kubernetes 节点 NotReady 状态详解与诊断指南
目录标题
- NotReady
- Case记录
-
- Case @1 use of closed network connection' (may retry after sleeping)
- Case @2 etcdserver: request timed out
- Case @ 3 container runtime status check may not have completed yet.
- Case @4 invalid capacity 0 on image filesystem
- Case @5 时间不一致
- Case @6 Error updating node status, will retry
- Case @7 dockerd 报错too many open files
- Case@8 failed to update lease
- Case@9 System OOM encountered, victim process: prometheus
- Case@10 PLEG is not healthy: pleg was last seen active 3m7.377520804s ago; threshold is 3m0s
- Case@11 NodeStatusUnknown
- Case@12:cgroup driver "cgroupfs" is different from docker
- Kubernetes 节点 `NotReady` 状态详解与诊断指南 V2.0
- 说明 V1.0
NotReady
可能的原因
如果 Kubernetes 节点状态为 NotReady,这意味着节点无法执行其预定功能,并且不可用于调度新的工作负载。节点可能变为 NotReady 的原因有多种,包括:
- 网络问题:如果节点失去网络连接,它可能变为 NotReady。 ip -4 a
- 资源耗尽:如果节点耗尽了 CPU 或内存等资源,它可能变为 NotReady。 free -h top df -h
- 节点故障:如果节点崩溃或经历硬件故障,它可能变为 NotReady。
- Kubernetes 组件故障:如果节点上的关键 Kubernetes 组件(如 kubelet 或 kube-proxy)发生故障,节点可能变为 NotReady。
- 节点是否发生重启 uptime ,对比集群节点时间 date
排查步骤
要排查 NotReady 节点,您可以:
-
使用 kubectl 命令检查节点状态:
kubectl get nodes -
使用 kubectl 命令检查节点日志:
kubectl describe <node-name>,并将输出重定向到文件:kubectl describe node > node.log -
使用使用 kubectl 命令检查节点日志:
kubectl get <node-name> -oyaml,并将输出重定向到文件:kubectl describe node > nodexxx.log -
在节点上检查 kubelet 日志:
journalctl -xeu kubelet,并将输出重定向到文件:journalctl -xu kubelet > kubelet.log;使用 systemctl 查看 kubelet 状态:systemctl status kubelet -
检查节点上的系统日志:
/var/log/messages -
使用 kubectl 命令检查 Kubernetes 事件日志:
kubectl get events -
检查 docker/containerd 状态:
systemctl status docker && systemctl status containerd,使用管道查看更多信息:| more -
在节点上检查 docker 日志:
journalctl -xeu docker,并将输出重定向到文件:journalctl -xu docker > docker.log -
在节点上检查 containerd日志:
journalctl -xeu containerd,并将输出重定向到文件:journalctl -xu v > containerd.log -
检查磁盘空间:
df -h | head -
检查核心服务:
1.18docker ps | grep -E 'api|etcd'1.24
crictl ps | grep -E 'api|etcd' -
检查prom 监控:
kube_node_status_condition{condition="Ready",node="qfusion01",status="true"} -
容器是否卡住:
for c in $(docker ps -qa); do echo inspect $c; docker inspect $c > /dev/null; done;crictl ps -q |while read line; do echo $line; crictl inspect $line > /dev/null ; sleep 1;done
一旦确定了节点 NotReady 的根本原因,您可以采取适当的措施来解决问题。例如,如果节点由于资源耗尽而变为 NotReady,您可以为节点添加更多资源或调整运行在节点上的工作负载的资源限制。如果节点由于网络问题而变为 NotReady,您可以排查网络连接并修复任何问题。
/var/log/pods
/var/log/containers
crictl ps + crictl logs
docker ps + docker logs (in case when Docker is used)
kubelet logs: /var/log/syslog or journalctl

Case记录
Case @1 use of closed network connection’ (may retry after sleeping)
查看操作系统/var/log/message日志,节点长期抛出use of closed network connection异常,并且在接下来的时间不断抛出该异常,无法自愈。
Sep 01 14:55:11 xxxx kubelet[1357]: E0901 14:55:11.356640 1357 event.go:269] Unable to write event: 'Post https://k8smaster.qfusion.irds:60443/api/v1/namespaces/qfusion/events: write tcp 127.0.0.1:37742->127.0.0.1:60443: use of closed network connection' (may retry after sleeping)

查看发现类似bug的PR信息
https://github.com/kubernetes/kubernetes/issues/87615
官方已经确认该bug并且下如下链接中说明修复内容
https://github.com/kubernetes/kubernetes/pull/104444
这个问题的根本原因可能与HTTP/2的特性和Kubernetes对其的处理方式有关。
HTTP/2允许在同一TCP连接上进行双向通信,即它支持半关闭(half-closed)连接,这就意味着一方可以停止发送数据,但仍然接收数据。在这种情况下,连接的一半被关闭,而另一半保持打开。
当Kubernetes的API server检测到一个半关闭的连接时,如果它还在发送数据,就可能会出现你遇到的那个错误信息。
在操作系统层面,TCP连接的半关闭状态通常是通过发送一个带有FIN标志的TCP段来实现的。接收到这个段的一方就知道发送方不再发送数据,但仍然可以继续接收数据。
在这种情况下,如果API server试图继续发送数据,就可能会产生"用于关闭网络连接"的错误。这是因为从操作系统的角度看,这个连接已经关闭,不应再发送数据。
该bug同时修复client-go的TCP库https://github.com/kubernetes/client-go/issues/374
以及K8s的API Server的KAS Egress组件https://github.com/kubernetes/kubernetes/pull/95981
处理方案:
systemctl restart kubelet
Case @2 etcdserver: request timed out
controller.go:178] failed to update node lease, error: etcdserver: request timed out
Case @ 3 container runtime status check may not have completed yet.

https://github.com/kubernetes/kubernetes/issues/101056
原因:
容器把docker搞崩了,然后节点就异常了!
处理方案:
for p in $(docker ps -q); do echo inspecting $p; docker inspect $p; echo complete; done;
ps -ef | grep 最后的id
kill 掉该进程
Case @4 invalid capacity 0 on image filesystem
Warning InvalidDiskCapacity 101s kubelet invalid capacity 0 on image filesystem
解决方案:systemctl restart containerd
Case @5 时间不一致

/var/log/messages systemd : time has been changed

原因:该节点时间和其他节点时间不一致导致。

Case @6 Error updating node status, will retry

解决方案:重启kubelet
kubelet 上报节点状态 源码分析:https://zhuanlan.zhihu.com/p/623840699

Case @7 dockerd 报错too many open files
https://blog.csdn.net/whatday/article/details/125481727
ls > /tmp/proc.log
cat /tmp/proc.log | wc -l
ll /proc/pid/fd/ 能看一些,详细的可以使用lsof 命令
Case@8 failed to update lease
E0522 00:38:34.444337 1421 controller.go:187] failed to update lease, error: Put “https://k8smaster.qfusion.irds:60443/apis/coordination.k8s.io/v1/namespaces/kube-node-lease/leases/?timeout=10s”: net/http: request canceled (Client.Timeout exceeded while awaiting headers)
查看组件状态
ks get pod | grep etcd
ks get pod | grep apiserver
收集组件日志
ks logs --since “72h” etcd-qfusion01
ks logs --since “72h” kube-apiserver-qfusion01
Case@9 System OOM encountered, victim process: prometheus
原因:内存耗尽
排查:free -h
解决方案1:释放内存(或者重启宿主机)
# 释放pagecache
echo 1 > /proc/sys/vm/drop_caches
# 释放dentries和inodes
echo 2 > /proc/sys/vm/drop_caches
# 释放pagecache、dentries和inodes
echo 3 > /proc/sys/vm/drop_caches
扩展:驱逐
驱逐信号 描述
memory.available memory.available := node.status.capacity[memory] - node.stats.memory.workingSet
memory.available 的值来自 cgroupfs,而不是像 free -m 这样的工具。 这很重要,因为 free -m 在容器中不起作用,如果用户使用 节点可分配资源 这一功能特性,资源不足的判定是基于 cgroup 层次结构中的用户 Pod 所处的局部及 cgroup 根节点作出的。 这个脚本或者 cgroupv2 脚本 重现了 kubelet 为计算 memory.available 而执行的相同步骤。 kubelet 在其计算中排除了 inactive_file(非活动 LRU 列表上基于文件来虚拟的内存的字节数), 因为它假定在压力下内存是可回收的。
例如,如果一个节点的总内存为 10GiB 并且你希望在可用内存低于 1GiB 时触发驱逐, 则可以将驱逐条件定义为 memory.available<10% 或 memory.available< 1G(你不能同时使用二者)。
- eviction-soft:一组驱逐条件,如 memory.available<1.5Gi, 如果驱逐条件持续时长超过指定的宽限期,可以触发 Pod 驱逐。
- eviction-soft-grace-period:一组驱逐宽限期, 如 memory.available=1m30s,定义软驱逐条件在触发 Pod 驱逐之前必须保持多长时间。
Case@10 PLEG is not healthy: pleg was last seen active 3m7.377520804s ago; threshold is 3m0s
https://github.com/kubernetes/kubernetes/issues/45419
PLEG(Pod Lifecycle Event Generator) :PLEG是kubelet的一个组件,负责生成Pod的生命周期事件。如果PLEG的时间过长,可能会导致节点被标记为NotReady
Case@11 NodeStatusUnknown
重启docker和kubelet后正常。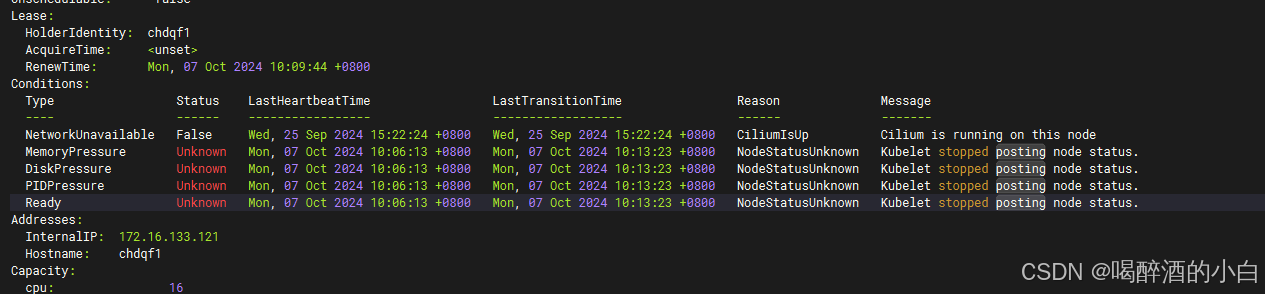
Case@12:cgroup driver “cgroupfs” is different from docker

https://blog.csdn.net/qq_34556414/article/details/125321272
解决方案
vi /usr/lib/systemd/system/kubelet.service.d/10-kubeadm.conf
添加 --cgroup-driver=systemd
ExecStart=/usr/bin/kubelet $KUBELET_KUBECONFIG_ARGS $KUBELET_CONFIG_ARGS $KUBELET_KUBEADM_ARGS $KUBELET_EXTRA_ARGS --node-ip xxx –cgroup-driver=systemd
systemctl daemon-reload
systemctl restart kubelet
journalctl -u kubelet -f
Kubernetes 节点 NotReady 状态详解与诊断指南 V2.0
优化整理后的内容涵盖了 Kubernetes 中节点
NotReady状态的核心概念、常见原因、诊断手段与 Kubernetes 1.26 的健康检查改进,使结构更清晰、逻辑更完整:
在 Kubernetes 集群中,节点状态变为 NotReady 意味着该节点暂时无法调度 Pod,也可能失去对控制平面的响应。掌握这一状态的成因及排查手段,是集群稳定运行的关键。
一、关键术语解释
| 关键字 | 含义说明 |
|---|---|
NotReady |
节点无法接收新的 Pod 调度,Kubernetes 控制平面认为其不健康。 |
Unknown |
控制平面与节点通信失败,无法确定节点当前状态。 |
kubelet |
节点上关键组件,负责 Pod 生命周期管理,故障将直接影响节点状态。 |
PLEG |
Pod Lifecycle Event Generator,kubelet 的子模块,生成 Pod 生命周期事件,延迟或失败会使节点进入 NotReady。 |
kube-proxy |
负责配置节点的网络规则,异常可能导致网络不可用。 |
| 节点污点(Taints) | 标记节点为不可调度,或限制调度到指定 Pod 类型。 |
二、节点 NotReady 的常见原因
| 类别 | 原因说明 |
|---|---|
| 服务异常 | kubelet 启动失败、kube-proxy 异常、Docker 守护进程失效、CNI 插件未正常工作 |
| 资源瓶颈 | 节点磁盘空间不足、内存耗尽、CPU 负载高 |
| 网络问题 | 节点无法连接 apiserver,或集群网络插件失效 |
| 通信中断 | 控制平面与节点失联,节点状态为 Unknown |
| 配置错误 | kubelet 配置文件有误、证书失效、etcd 时间不同步 |
| PLEG 卡顿 | PLEG 周期性检查超时,导致 Pod 状态无法更新 |
| 节点事件 | Pod 驱逐、健康检查失败等系统事件 |
三、kubelet 启动失败导致节点 NotReady 的诊断步骤
-
检查 kubelet 服务状态
systemctl status kubelet -
查看 kubelet 启动日志
journalctl -u kubelet -xe -
验证配置文件
- 检查
/var/lib/kubelet/config.yaml或使用命令行传参的 kubelet 参数。 - 确认 TLS 证书、集群 DNS 和 API Server 地址设置正确。
- 检查
-
检查 CNI 插件
- 检查
/opt/cni/bin/是否存在插件文件; - 查看
/etc/cni/net.d/下的配置是否正确。
- 检查
-
检查容器运行时(如 Docker)状态
systemctl status docker -
磁盘资源检查
df -h -
使用 Node Problem Detector(NPD)
- NPD 可自动检测节点硬件/软件异常并上报 Kubernetes Events。
-
尝试重启 kubelet
systemctl restart kubelet
四、etcd 出现问题时的表现与解决方法
1. 数据库存储空间超限
-
表现:报错
etcdserver: mvcc: database space exceeded,集群变为只读状态。 -
解决方法:
etcdctl compact <revision> etcdctl defrag
2. etcd 节点不健康
-
表现:某个节点状态不健康或同步失败。
-
解决方法:
etcdctl endpoint health
3. 时间同步问题
- 表现:证书验证失败、客户端连接异常。
- 解决方法:启用 Chrony 或 NTP 服务,确保所有节点时间一致。
五、通过节点事件诊断 NotReady 状态
-
查看节点状态
kubectl get nodes -
查看具体节点描述
kubectl describe node <node-name>Conditions部分将列出Ready条目及其状态和原因;Events区域列出异常事件(如网络失败、PLEG 卡顿、CNI 加载失败等)。
-
检查资源状态
top # 或使用 sar、htop、iostat 等工具 -
排查驱逐情况
kubectl get events --field-selector involvedObject.kind=Node
六、Kubernetes 1.26 对 NotReady 节点健康检查的改进
Kubernetes 1.26 引入了节点健康检查机制的增强,目的是提高诊断精度并减少误报:
1. 健康检查指标增强
-
增加 Prometheus 格式的健康指标
kubernetes_healthcheck; -
包含两类指标:
gauge:当前健康状态;counter:各状态出现次数。
2. 外部通信不中断
- 新增机制允许节点在
NotReady状态下仍维持对外(如云商负载均衡器)的连接,以提高修复期间的容忍度。
七、总结与建议
| 建议类型 | 内容 |
|---|---|
| 监控预警 | 使用 Prometheus 监控 node_status_condition{condition="Ready"}、kube_node_status_condition{status="false"} 等指标,提前发现异常 |
| 定期巡检 | 节点时间、磁盘、网络、服务状态巡检不可缺 |
| 配置审计 | kubelet 参数与 CNI 配置应统一规范管理 |
| 日志归档 | 启用节点日志持久化,便于问题回溯 |
如需进一步故障定位工具或脚本(如自动诊断 NotReady 原因、事件归类分析等),可继续提供场景需求。
说明 V1.0
在Kubernetes集群中,当节点状态变为NotReady时,通常意味着该节点无法正常工作,导致Pod无法调度。以下是一些关键字和常见原因:
-
NotReady:这是节点状态变为
NotReady时的关键字,表示节点无法接受新的Pod调度。 -
Unknown:当Kubernetes主节点与节点失去通信时,节点状态可能会变为
Unknown,表示节点的状态无法确定。 -
kubelet:kubelet是Kubernetes集群中每个节点上的关键组件,负责管理Pod的生命周期。如果kubelet出现问题,节点可能会进入
NotReady状态。 -
PLEG(Pod Lifecycle Event Generator) :PLEG是kubelet的一个组件,负责生成Pod的生命周期事件。如果PLEG的时间过长,可能会导致节点被标记为
NotReady。 -
网络问题:网络不通或kubelet无法访问API Server可能导致节点状态变为
NotReady。 -
kube-proxy:kube-proxy负责维护节点的网络规则,如果kube-proxy出现问题,也可能导致节点状态变为
NotReady。 -
Pod驱逐:如果节点上的Pod因为资源压力等原因被驱逐,也可能导致节点状态变为
NotReady。 -
节点不可达:如果节点不可达,Kubernetes主节点会认为节点处于
Unreachable状态,进而导致节点状态变为NotReady。 -
kubelet服务启动失败:如果kubelet服务启动失败,可能会导致节点状态变为
NotReady。 -
节点污点:如果节点被标记为不可调度或不可执行,也可能导致节点状态变为
NotReady。 -
etcd:etcd是Kubernetes的分布式键值存储系统,如果etcd出现问题,可能会影响节点的状态。
-
apiserver:apiserver是Kubernetes的API入口,如果apiserver出现问题,可能会影响节点的状态。
-
节点event状态:通过
kubectl describe node <节点名称>命令查看节点的event状态,可以帮助诊断节点NotReady的原因。 -
kubelet运行状态:通过
systemctl status kubelet命令查看kubelet的运行状态,可以帮助诊断节点NotReady的原因。 -
节点健康检查:Kubernetes 1.26版本引入了对
NotReady状态节点的健康检查改进,允许节点在未从公共负载均衡器中分离的情况下保持出站互联网连接。
通过以上关键字和常见原因,可以更有效地诊断和解决Kubernetes节点NotReady的问题。
如何诊断和解决kubelet服务启动失败导致的节点NotReady状态?
当Kubernetes节点出现NotReady状态时,通常意味着该节点无法正常运行Pod或无法正确响应Kubernetes控制平面。诊断和解决这一问题需要按照以下步骤进行:
-
检查Kubelet日志:首先,查看kubelet服务的日志以了解具体的错误信息。可以通过命令
journalctl -u kubelet来查看日志。根据日志中的错误信息,可以定位问题的原因。 -
检查Kubelet运行状态:在notReady的主机上执行
systemctl status kubelet命令,查看kubelet的运行状态。如果kubelet状态为非active(running),则需要根据具体的日志提示信息排查修复。 -
检查配置文件:确认kubelet的配置文件是否正确,有时候配置错误也会导致服务启动失败。
-
检查网络插件:CNI(容器网络接口)插件未部署或配置错误也可能导致节点无法就绪。需要确保CNI插件已正确部署并配置。
-
检查Docker状态:如果Docker服务僵死或API不响应,也会导致节点无法就绪。可以尝试重启Docker服务。
-
磁盘空间检查:磁盘空间不足也可能导致节点无法就绪。清理磁盘空间,如删除不必要的镜像和临时文件。
-
使用Node Problem Detector (NPD) :NPD是一个监控工具,可以在节点上运行并检测各种异常情况,如内核死锁、Docker挂起、磁盘问题等。通过NPD可以更快地发现节点上的问题。
-
手动启动Kubelet:如果上述方法无效,可以尝试使用tjc命令手动启动kubelet进程。
-
提交工单:如果问题依然无法解决,建议收集异常Pod信息并提交工单联系技术支持。
Kubernetes中etcd出现问题时的具体表现和解决方法是什么?
在Kubernetes中,etcd出现问题时的具体表现和解决方法如下:
- etcd数据库空间超限:
- 表现:当etcd的数据库文件大小超过配额时,会出现错误信息“etcdserver: mvcc: database space exceeded”,导致整个集群进入只读状态,无法进行写操作。
- 解决方法:
- 使用etcd的compact机制来清理旧的数据,以释放空间。etcd默认不会自动执行compact操作,需要手动设置启动参数或通过命令进行。
- 升级etcd版本以支持更大的存储容量。例如,将etcd升级到v3.4.3版本可以支持高达100GB的存储空间。
- etcd节点不健康:
- 表现:etcd节点可能因为各种原因(如网络问题、配置错误等)变得不健康。etcd-operator会检测到这些不健康的节点,并报告相关错误信息。
- 解决方法:
- 使用
etcdctl endpoint health命令检查集群成员的健康状态,确认哪个节点不健康。 - 如果发现某个节点不健康,可以通过删除相关的MachineCustom资源来移除不健康的控制平面。
- 时间同步问题:
- 表现:如果生成证书的机器时间快于etcd服务器时间,会导致证书验证失败,进而影响etcd集群的正常运行。
- 解决方法:确保服务器和生成证书的机器时间同步更新。
在Kubernetes中,如何通过节点event状态准确诊断NotReady的原因?
在Kubernetes中,当节点处于NotReady状态时,可以通过以下步骤准确诊断其原因:
-
查看节点状态和事件:首先使用
kubectl get nodes命令查看所有节点的状态,确认哪些节点处于NotReady状态。然后,使用kubectl describe node <node-name>命令获取该节点的详细信息,包括事件和条件状态。 -
检查kubelet运行状态:如果可以登录到节点,可以通过
systemctl status kubelet命令查看kubelet的运行状态。如果kubelet未运行(非active状态),则需要根据日志提示信息进行排查和修复。 -
查看系统日志:如果节点无法登录,可以尝试通过控制台页面或远程访问工具查看kubelet的日志,例如使用
journalctl -u kubelet命令。这有助于了解节点未就绪的具体原因。 -
检查资源使用情况:高内存使用率、磁盘空间不足或CPU负载过高都可能导致节点进入
NotReady状态。可以使用df -h命令检查磁盘空间,使用sar命令监控CPU和内存使用情况。 -
检查网络和资源限制:网络问题或资源不足也可能导致节点无法正常工作。可以检查节点的网络配置和资源限制,确保没有因资源不足而导致的问题。
Kubernetes 1.26版本中对NotReady状态节点的健康检查改进具体是什么?
在Kubernetes 1.26版本中,对NotReady状态节点的健康检查进行了改进。具体来说,引入了一个新的指标kubernetes_healthcheck,该指标以标准的Prometheus格式返回数据,用于直观地查看Kubernetes集群组件是否健康。此外,还增加了一个gauge和一个计数器,分别代表健康检查的当前状态和记录每个健康检查状态观察到的累积计数。这些信息可以帮助用户检查Kubernetes内部的超时状态。

K8S/Kubernetes社区为您提供最前沿的新闻资讯和知识内容
更多推荐



 6
6 0
0- 0



 已为社区贡献30条内容
已为社区贡献30条内容

所有评论(0)