
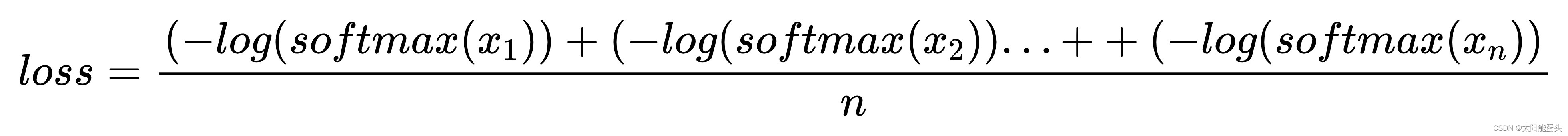
深度学习关于NLLLoss损失的数学向个人详解
就得减小,根据其图像可知,随着其减小,softmax(x)的值必然增大。由于网络在这个过程中输出的其实就是加了softmax激活函数的softmax(x),就能理解为,训练网络降低NLLLoss的过程中,网络计算出的样本属于其类的概率值越趋近于1。"" 然后就是对softmax的结果取对数,做log运算,再接着就是假设标签是[0, 1, 2],第一行取第0个元素,第二行取第1个,第三行取第2个,去
一、起因与目的
写这篇文章的起因,就是网络上查了很多NLLLoss(Negative Log-Likelihood Loss,负对数似然损失)相关的详解,但是要么没有讲透,要么就是只讲了如何应用。而我看了之后关于其底层是如何计算损失,并使预测值y趋近于target的原理还是不太清楚。自己从二维数学图像的角度小推了一遍,通俗一点,现在记录一下,以供查阅。
二、计算过程概览

首先根据上图,这里假定了网络输出的结果是一个3*3的tensor矩阵,作为本次推导的input。接着先使用softmax输出函数(softmax输出函数将结果映射为总和为1的概率值,详情请自行查阅)对其进行计算,得到一个3*3的矩阵。其代表的含义是对三个样本分别进行样本属于三类中的某一类的概率预测,那么结果自然就是3*3=9个。根据softmax函数的性质,我们可以很容易得出,一个样本分别属于三个样本的概率,且相加值为1.
图2为图解,格式问题数据有位置偏移,理解就行:

"" 然后就是对softmax的结果取对数,做log运算,再接着就是假设标签是[0, 1, 2],第一行取第0个元素,第二行取第1个,第三行取第2个,去掉负号,即[0.3168, 3.3093, 0.4701], 求平均值,就可以得到损失值。"" 如此便是整个计算过程。
这里我们再根据上图来理解,0、1、2分别是样本1、样本2、样本3 的标签,代表他们分别属于类1、类2、类3。那么根据标签取出来的数就代表,经过网络计算后,样本1属于其类1的概率、样本2属于其类2的概率、样本3属于其类3的概率。当然在实际计算中,这步的数据严格来说已经经过了softmax和log函数处理,不算概率,我们知道其对应关系就行。
验证如下图:

过程就是这样,接下来就从数学角度来理解一下。
二、计算过程理解
我们假定网络输出的是x,接下来首先得到的结果就是softmax(x)且由于其结果为概率值,其值域为(0~1)。
然后我们知道,NLLLloss函数就是先对softmax(x)的结果取对数,那么结果就是log(softmax(x)),根据log函数和函数图像和softmax(x)的值域,很容易得出其值域为(-∞,0)。
再对以上结果取负数,结果为 - log(softmax(x)),容易得知其值域为(0,+∞),接下来再根据其计算过程可以得出其公式:
我们知道网络学习的目的就是降低损失loss,根据等式,loss减小,那么每个 - log(softmax(x))就得减小,根据其图像可知,随着其减小,softmax(x)的值必然增大。由于网络在这个过程中输出的其实就是加了softmax激活函数的softmax(x),就能理解为,训练网络降低NLLLoss的过程中,网络计算出的样本属于其类的概率值越趋近于1。以上,就是我通过降低NLLLoss来训练网络分类任务的理解。
图解如下:
三、细节与思考
1.NLLLoss本身是不带输出函数的,所以在网络中通常需要添加softmax输出函数,通常是softmax,理论上别的输出函数也可以,但别的输出函数与NLLLoss的结合应用我暂时还没见过。
2.理解了NLLLoss之后对于理解CrossEntropyLoss有帮助,其官方文档的说明解释为:softmax(x)+log(x)+nn.NLLLoss====>nn.CrossEntropyLoss
3.观察推导出的损失公式,思考是否可以对每个样本的- log(softmax(x))加上权重,使其效果更好,如何添加合理,应该会是一个有趣的损失函数优化问题。

更多推荐


 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)