
HTTP协议详解之HTTP/1.1
1、写在前面:学习的时候一定要对照官方文档、结合分析工具,才能深入理解。
目录
一、协议概述
1、写在前面:学习的时候一定要对照官方文档、结合分析工具,才能深入理解。
(1)HTTP1.1官方文档:RFC 2616 - Hypertext Transfer Protocol -- HTTP/1.1
(2)参考书籍:《图解http》
(3)学习的过程中可以借助 curl命令、postman 来模拟HTTP请求,通过 wireshark 抓包分析HTTP请求和响应的格式和内容。
2、HTTP从诞生到如今共经历了多个版本的迭代如HTTP/1.0、HTTP/1.1、HTTP/2.0。HTTP/2.0是HTTP协议的最新版本于2015年被批准,但是HTTP/1.1仍然被广泛使用,而且HTTP/1.1会一直存在,这是由于网络基础设施更新缓慢所决定的,所以网络协议新版本并不会马上取代旧版本。本文基于HTTP/1.1版本进行介绍。
3、HTTP协议是 HyperText Transfer Protocol(超文本传输协议)是一种应用非常广泛的基于TCP协议的应用层协议,它不涉及数据包(packet)传输,主要规定了客户端和服务器之间的通信格式,默认是80端口。HTTP是万维网的数据通信的基础。
4、HTTP遵循请求(Request)/响应(Response)模型。请求从客户端发出,最后服务器端响应该请求并返回。换句话说,肯定是先从客户端开始建立通信的,服务器端在没有接收到请求之前不会发送响应。当客户端向服务器发送个HTTP请求时,请求报文包含请求的方法、URL、协议版本、请求头部和请求数据。HTTP服务器则在端口(默认是80端口)监听客户端的请求。收到请求后,服务器会返回一个状态行及响应的内容,包括协议的版本、成功或者错误代码、服务器信息、响应头部和响应数据。
5、由于不同的HTTP请求的目的也不同,即有的请求想要获取资源,有的请求想要删除资源,根据不同的请求诉求,HTTP协议规定了不同的请求方法,即规定了客户与服务器联系的类型。比如获取数据的GET方法,删除数据的DELETE的方法等。
6、HTTP是一个无状态的面向连接的协议。无状态是指HTTP协议本身对于事务处理没有记忆功能,服务器不知道浏览器的状态。即使你登陆了一个网站,去访问一个网站内的不同的网页,服务器都不知道你是谁,因为HTTP协议本身没有记录用户信息,如果需要记录用户的登录信息、用户操作、用户行为等数据就需要使用cookie或session来存储。
二、HTTP请求与响应
1、HTTP遵循请求(request)/响应(response)模型,请求从客户端发出,最后服务器端响应该请求并返回。换句话说,肯定是先从客户端开始建立通信的,服务器端在没有接收到请求之前不会发送响应。
2、HTTP 是一种不保存状态,即无状态(stateless)协议。HTTP 协议自 身不对请求和响应之间的通信状态进行保存。也就是说在 HTTP 这个级别,协议对于发送过的请求或响应都不做持久化处理。 每当有新的请求发送时,就会有对应的新响应产生。协议本身并不保留之前一切的请求或响应报文的信息。这是为了更快地处理大量事务,确保协议的可伸缩性,而特意把 HTTP 协议设 计成如此简单的。 但是随着 Web 的不断发展,因无状态而导致业务处理变得棘手的情况增多了。比如,用户登录到一家购物网站,即使他跳转到该站的其它页面后,也需要能继续保持登录状态。针对这个实例,网站为了能够掌握是谁送出的请求,需要保存用户的状态。 HTTP/1.1 虽然是无状态协议,但为了实现期望的保持状态功能,于是引入了 Cookie 技术。有了 Cookie 再用 HTTP 协议通信,就可以管理状态了。有关 Cookie 的详细内容稍后讲解。
3、HTTP协议1.1之前版本的连接都是非持久连接,就是是一个请求一个响应之后,直接就断开了,但是现在的HTTP协议1.1版本不是直接就断开了,而是等一段时间,这段时间是等什么呢,等着用户有后续的操作,如果用户在这段时间之内有新的请求,那么还是通过之前的连接通道来收发消息,如果这段时间用户没有发送新的请求,那么就会断开连接,这样可以提高效率,减少短时间内建立连接的次数,因为建立连接也是耗时的,这个时间是可以通过后端的代码来调整,网站可以根据用户的行为来分析统计出一个最优的等待时间。(看了这篇http协议,你还敢说之前会吗?_马跃的随笔的技术博客_51CTO博客)
2.1 请求/响应过程
1、主要流程和数据打包过程如下图所示:

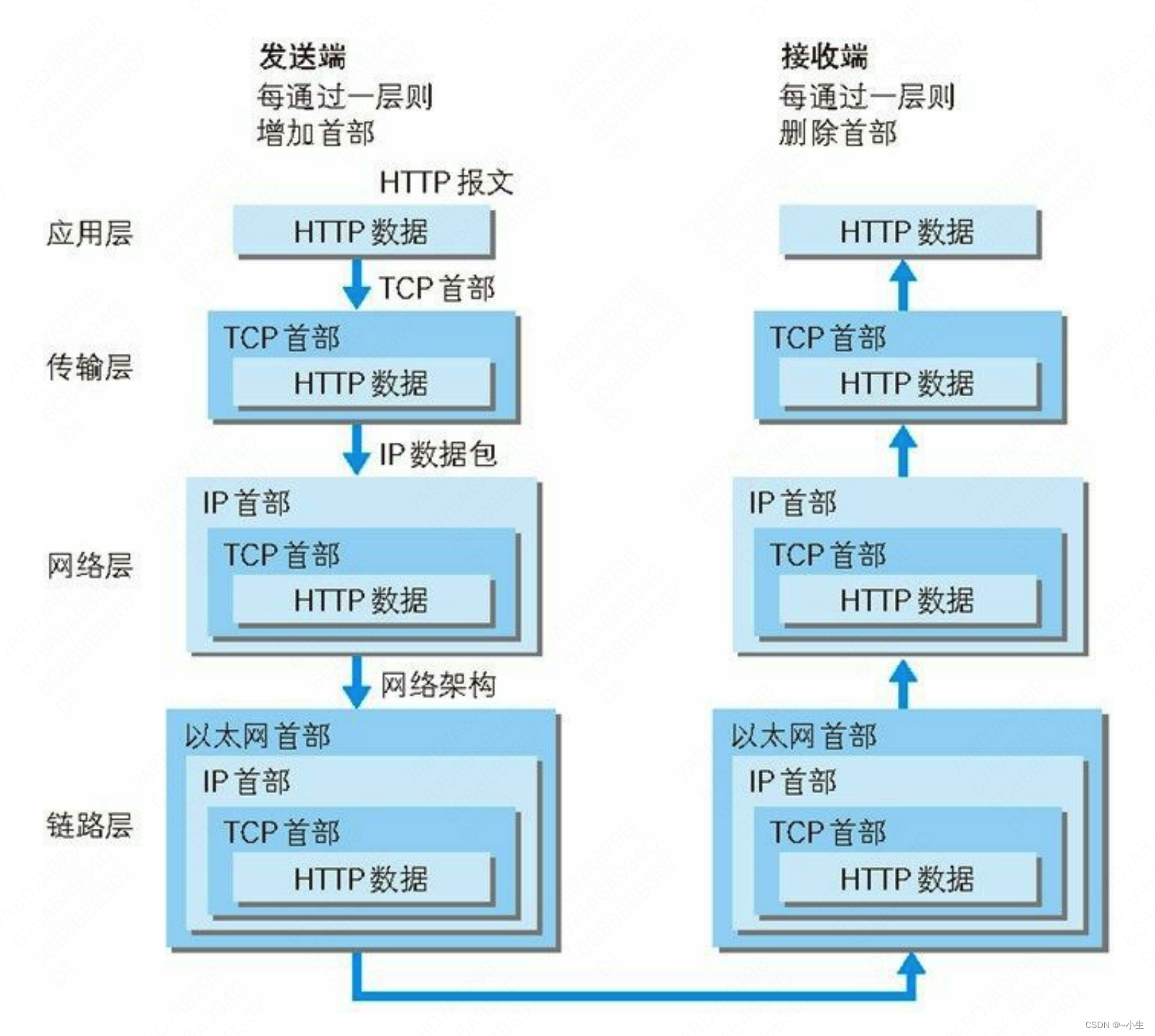
请求
(1)请求DNS服务器,找到URL中域名对应的服务器IP,找到服务器后就可以进行HTTP请求。
(2)客户端生成HTTP请求报文:包括起始行,首部,主体。
(3)建立tcp连接:由于HTTP是基于tcp的应用层协议,所以要此时进行tcp连接:客户端与服务端进行tcp三次握手,建立连接。
(4)发送HTTP请求报文:tcp握手成功后,通过tcp/ip通信协议将客户端生成的HTTP报文,发送至服务器。
响应
(5)服务器生成HTTP响应报文:服务器收到请求后会根据请求内容准备客户端需要的数据,并生成对应的HTTP报文。
(6)发送HTTP响应报文:通过tcp/ip通信协议将服务器生成的HTTP报文,发送至客户端。
(7)tcp断开连接:客户端与服务端进行tcp四次挥手,断开连接,请求/响应结束。
2、在浏览器地址栏键入URL,访问网页本质上也是HTTP请求和响应的过程,此时客户端是浏览器,在整个流程中会有浏览器本身的处理逻辑。在浏览器地址栏键入URL,按下回车之后会经历以下流程:其中步骤(1)(8)就是浏览器自己的处理逻辑。
(1)浏览器查找缓存:如果查找到缓存中有我们URL对应的网页信息,并且没有过期,如果有则会直接读取缓存内容,此时不会发送HTTP请求,如果没有则发送HTTP请求
(2)请求DNS服务器,找到URL中域名对应的服务器IP,找到服务器后就可以进行HTTP请求。
(3)浏览器生成HTTP请求报文:包括起始行,首部,主体。
(4)建立tcp连接:由于HTTP是基于tcp的应用层协议,所以要此时进行tcp连接:浏览器与服务端进行tcp三次握手,建立连接。
(5)发送HTTP请求报文:tcp握手成功后,通过tcp/ip通信协议将浏览器生成的HTTP报文,发送至服务器。
(6)服务器生成HTTP响应报文:服务器收到请求后会根据请求内容准备浏览器需要的数据,并生成对应的HTTP报文。
(7)发送HTTP响应报文:通过tcp/ip通信协议将服务器生成的HTTP报文,发送至浏览器。
(8)浏览器处理响应内容:浏览器根据返回的结果进行渲染展示,同时判断是否需要将网页信息存入缓存。
(9)tcp断开连接:浏览器与服务端进行tcp四次挥手,断开连接,请求/响应结束。
2.2 请求/响应报文
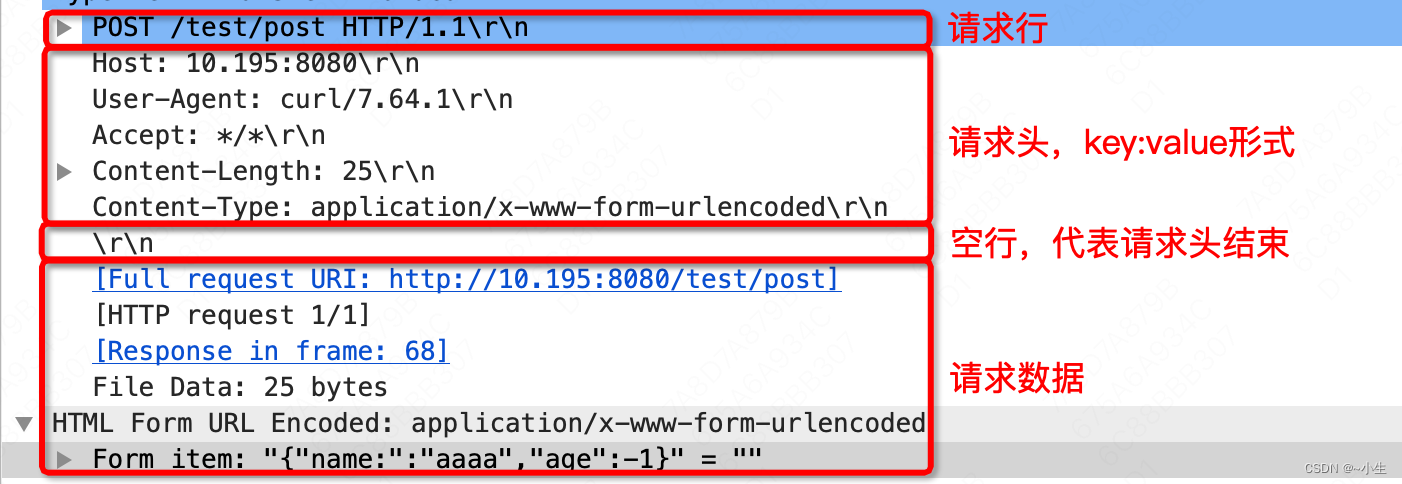
1、用于 HTTP 协议交互的信息被称为 HTTP 报文。请求端(客户端)的 HTTP 报文叫做请求报文,响应端(服务器端)的叫做响应报文。 HTTP 报文本身是由多行(用 CR+LF 作换行符)数据构成的字符串文本。 HTTP 报文大致可分为报文首部和报文主体两块,两者由最初出现的空行(CR+LF)来划分。报文首部和空行是一定要有的,但是并不一定要有报文实体。
2、HTTP协议的请求报文和响应报文的结构相同,如下图所示。

由三大部分组成:
(1)起始行(start line):描述请求或响应的基本信息
(2)头部字段集合(header):使用key-value的形式更详细的说明报文
(3)消息正文(entity):实际传输的数据,它不一定是纯文本,也可以是图片、视频等二进制数据。
这其中前两部分起始行和头部字段经常又合称为“请求头”或“响应头”,消息正文又称为“实体”,但是与“header”对应,很多时候就直接成为“body”。
HTTP协议规定报文必须有起始行(start line)和头部字段集合(header),但是可以没有消息正文(entity/body),而且在header之后必须要有一个“空行”,也就是CR+LF,所以一个完整的HTTP报文就像是下图的这样,注意在header和body之间有一个“空行”。
2.2.1 请求报文
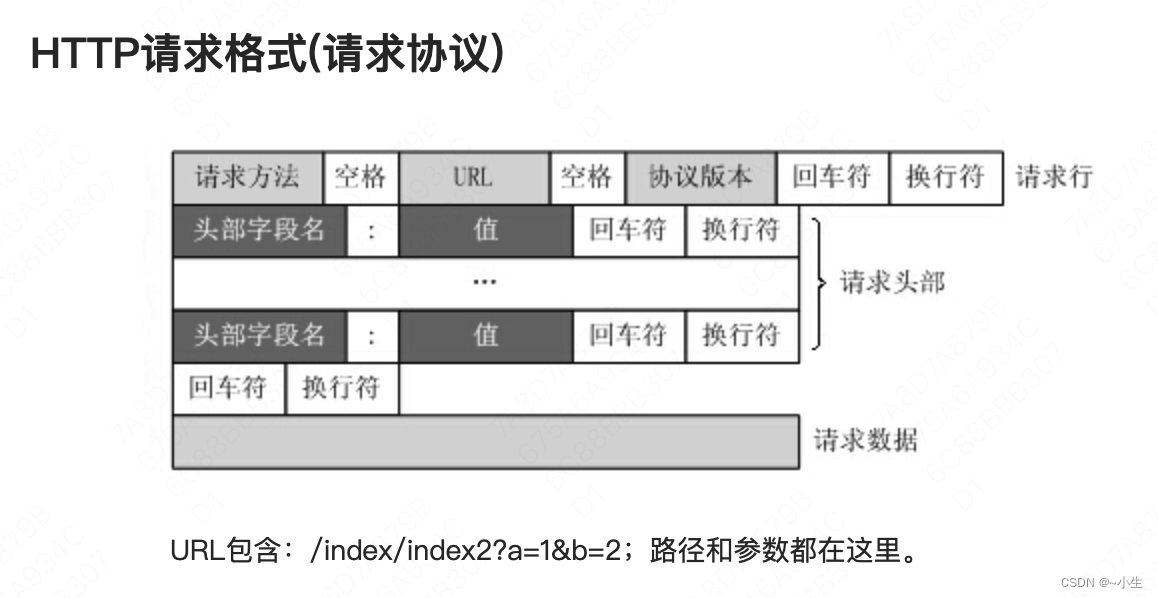
1、请求报文的详细格式如下图所示:
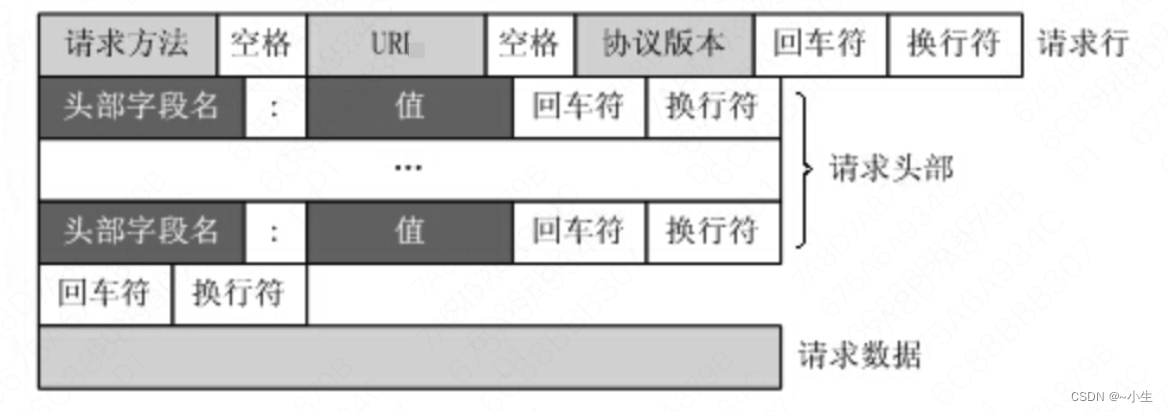
(1)请求行:它简要地描述了客户端想要如何操作服务器的资源
请求方法:表示对资源的操作方法
URI:标齐了请求方法要操作的资源,详见“3.1.3 url和uri”
协议版本:表示报文使用的HTTP协议版本
(2)请求头部
头部字段是key:value的形式,key和value之间用“:”分割,最用CRLF换行表示字段结束。比如“Host:127.0.0.1”这一行里key就是“Host”,value就是“127.0.0.1”;HTTP头部字段非常灵活,不仅可以使用官方文档里定义的Host、Connection等已有头部字段名,也可以任意添加自定义字头部字段名,这就给HTTP协议带来的非常好的扩展性。
不过使用头部字段需要注意一下几点:
- 头部字段名不区分大小写,例如“Host”也可以写成“host”,但首字母大写的可读性更好。
- 头部字段名里不允许出现空格,可以使用连字符“-”,但不能使用下划线“_”。例如,“test-name”是合法的头部字段名,而“test name”、“test_name”是不合法的头部字段名。
- 头部字段名后面必须紧接着“:”,不能有空格,而“:”后的字段值前可以有多个空格。
- 头部字段名的顺序是没有意义的,可以任意排列不影响语义。
- 头部字段名原则上不能重复,除非这字段本身的语义允许,例如Set-Cookie。
(3)请求数据:实际传输的数据,它不一定是纯文本,也可以是图片、视频等二进制数据。
2.2.2 响应报文
1、请求报文的详细格式如下图所示:
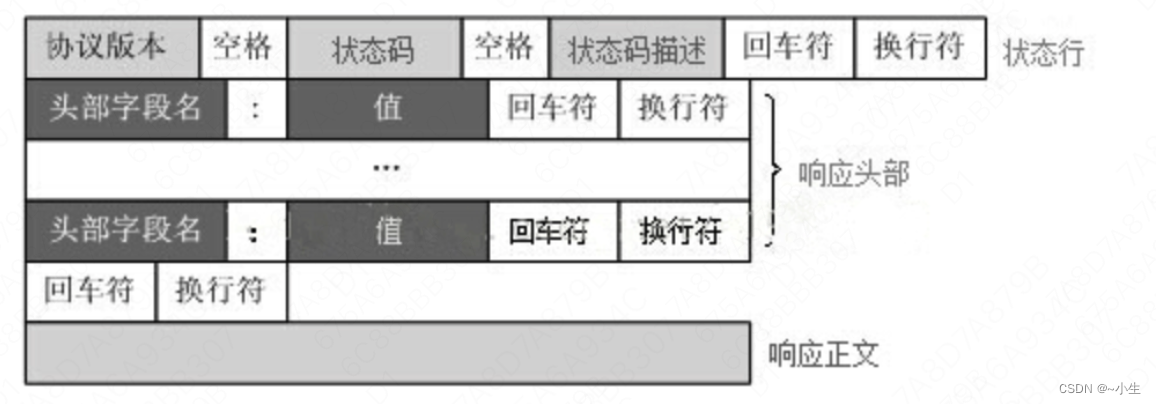
(1)状态行:服务器响应的状态
协议版本:表示报文使用的HTTP协议版本
状态码:一个三位数,用代码的形式表示处理的结果,比如200是成功,500是服务器错误,详见“五、状态码”
状态码描述:作为数字状态码补充,是更详细的解释文字,帮助人理解原因
(2)响应头部:和“请求头部”相同,详见“3.1.1 请求报文->(2)请求头部”
(3)响应正文:实际传输的数据,它不一定是纯文本,也可以是图片、视频等二进制数据。
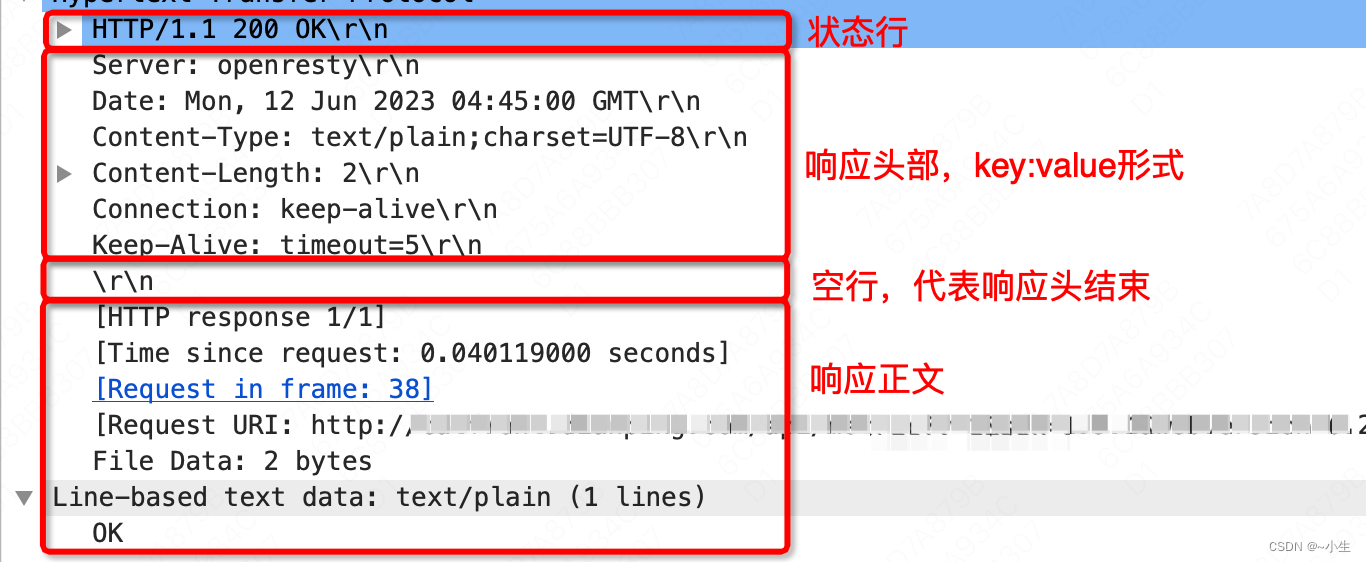
2.2.3 URI和URL
1、URI(Uniform Resource Identifier):统一资源标识符,是一个用于标识某一互联网资源名称的字符串。
URL(Uniform Resource Locator):统一资源定位符,是一个用于标识和定位某一互联网资源名称的字符串。
2、可能大家就比较困惑了,这俩好像是一样的啊?那我们就类比一下我们现实生活中的情况:
(1)我们要找一个人——张三,我们可以通过他的唯一的标识来找,比如说身份证,那么这个身份证就唯一的标识了一个人,这个身份证就是一个 URI;
(2)而要找到张三,我们不一定要用身份证去找,我们还可以根据地址去找,如在清华大学18号宿舍楼的404房间第一个床铺的张三,我们也可以唯一确定一个张三,住址协议://地球/中国/北京市/清华大学/18号宿舍楼/404号寝/张三.人。而这个地址就是我们用于标识和定位的 URL。
(3)我们从上面可以很明显的看出,URI 通过任何方法标识一个人即可,而 URL 虽然也可以标识一个人,但是它主要是通过定位地址的方法标识一个人,所以 URL 其实是 URI 的一个子集,即 URL 是靠标识定位地址的一个 URI。
3、URL一般有以下部分组成
scheme:[subscheme]://[username:password@]host:port/path?query#fragment
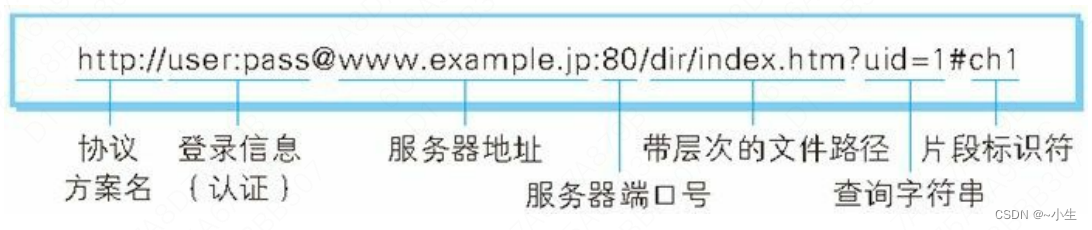
| 组成部分 | 说明 |
|---|---|
| scheme | 协议方案名,一般使用 http: 或 https: 等协议方案名获取访问资源时要指定协议类型。不 区分字母大小写,最后附一个冒号(:)。 也可使用 data: 或 javascript: 这类指定数据或脚本程序的方案名。 |
| subscheme | 可选,子协议,常用于区分不同数据库驱动协议。 |
| username:password | 登录信息(认证),用户名:密码。指定用户名和密码作为从服务器端获取资源时必要的登录信息(身份 认证)。此项是可选项。 |
| host | 服务器地址,服务器的域名主机名或ip地址,地址可以是类似 hackr.jp 这种 DNS 可解析的名称,或是 192.168.1.1 这类 IPv4 地址 名,还可以是 [0:0:0:0:0:0:0:1] 这样用方括号括起来的 IPv6 地址名。 |
| port | 服务器端口号,此项为可选项,默认为80。若用户省略则自动 使用默认端口号。 |
| path | 带层次的文件路径,由“/”隔开的字符串,表示的是主机上的目录或文件地址。 |
| query | 查询字符串,此项为可选项,可以给动态网页传递参数,用“&”隔开,每个参数的名和值用“=”隔开。 |
| fragment | 判断标识符,使用片段标识符通常可标记出已获取资源中的子资源(文档内的某个位置)。 |
2.2.4 常用头部字段
1、HTTP协议规定了非常多的头部字段,实现各种各样的功能,但基本上可以分为四大类:
(1)通用字段(general-header):在请求头和响应头里都可以出现。
(2)请求字段(request-header):仅能出现在请求头里,进一步说明请求信息或者额外的附加条件。
(3)响应字段(response-header):仅能出现在响应头里,补充说明响应报文的信息。
(4)实体字段(entity-header):它实际上属于通用字段,但专门描述body的额外信息(只是描述body信息,字段本身存在于请求头或响应头中)。
对HTTP报文的解析和处理实际上主要就是对头字段的处理,理解了头字段也就理解了HTTP报文。
2、通用字段(general-header)
| 字段名称 | 说明 |
|---|---|
| Date | 通常出现在响应头里,表示HTTP报文创建的时间。客户端可以使用这个时间再搭配其它字段决定缓存策略。 |
| Connection | 管理持久连接。比如
|
3、请求字段(request-header)
| 字段名称 | 说明 |
|---|---|
| User-Agent | 声明客户端的操作系统和浏览器版本信息,服务器可以根据它来返回最适合客户端的现实内容。 |
| Accept | 代表客户端希望接收的数据类型,比如Accept: text/xml (application/json) 代表客户端希望接收的数据类型是xml(json)。比如Accept: */* 则说明客户端接收所有类型的数据。 |
| Host | 指定Internet主机和端口。它是唯一一个HTTP/1.1规范里要求必须出现的字段,也就是说,如果请求头里没有Host,那就是一个错误的报文。 |
| Range | 告知服务器资源的指定范围。比如Range:bytes=5001-10000表示请求获取从5001字节到10000字节的资源,比如Range:bytes=0- 表示请求所有的数据。接收到附带Range首部字段的服务器,会在处理请求之后状态码为206 Partial Content 的响应。无法处理该范围请求时,则会返回状态码200 OK 的响应及全部资源。 |
4、响应字段(response-header)
| 字段名称 | 说明 |
|---|---|
| Server | 它告诉客户端当前正在提供Web服务的软件名称和版本号,Server字段也不是必须要出现的,因为这会把服务器的一部分信息暴露给外界,如果这个版本恰好存在bug,那么黑客就有可能利用bug攻陷服务器。所以,有的网站响应头里要么没有这个字段,要么就给出一个完全无关的描述信息。 |
5、实体字段(entity-header)
| 字段名称 | 说明 |
|---|---|
| Content-Type | 表示发送端(客户端/服务器)的实体数据的数据类型。 Content-Type = text/html,数据是HTML格式 Content-Type = text/css,数据是CSS格式 Content-Type = application/javascript,数据是JavaScript格式 Content-Type = application/json,数据是JSON格式 |
| Content-Length | 表示报文里body的长度,也就是请求头或响应头空行后面数据的长度。服务器看到这个字段,就知道后续有多少数据,可以直接接收,接收到这个长度的数据后,如果在默认的保持连接的时长内没有新数据发送,就会断开连接。 如果没有这个字段,那么body就是不定长的,需要使用chunked方式分段传输,此时也会保持持久连接,详情可见“3.5 持久连接与分块传输”。 |
2.3 请求方法
HTTP/1.1协议中共定义了八种方法(有时也叫“动作”),来表明请求指定的资源不同的操作方式。
HTTP1.0定义了三种请求方法: GET,POST 和HEAD方法。
HTTP1.1新增了五种请求方法:OPTIONS,PUT,DELETE,TRACE和CONNECT方法。
2.3.1 OPTIONS方法
1、用来描述了目标资源的通信选项,返回服务器针对特定资源所支持的HTTP请求方法。
2、请求:没有请求体

3、响应:响应头部中的“Allow”就是特定资源支持的HTTP请求方法

2.3.2 GET方法
1、GET方法只是用来获取数据,不对服务器的数据做任何的修改,新增,删除等操作。生成的数据应作为响应中的实体(entry/body)。
2、GET请求会把请求的参数附加在URL后面,所以没有请求体,这样是不安全的,在处理敏感数据时最好对参数做加密处理,或者使用其它请求方法处理敏感数据。并且URL后面只能携带字符串,不能携带图片、视频或其它类型的数据。
3、HTTP协议并没有限制GET方法对URL大小,但是不同的浏览器对其有不同的大小长度限制。
4、请求的过程
(1)浏览器请求TCP连接(第一次握手)
(2)服务器答应进行TCP连接(第二次握手)
(3)浏览器确认,并发送GET请求头和数据(第三次握手,这个报文比较小,所以HTTP会在此时进行第一次数据发送)
(4)服务器返回200 OK响应
5、请求:没有请求体
 6、响应
6、响应
2.3.3 HEAD方法
1、HEAD方法与GET方法相同,只是HEAD的响应中没有响应正文,只有起始行和响应头,而且同样的请求内容使用HEAD方法和GET方法请求,响应的起始行和响应头是完全相同的。这种方法是通常用于测试超文本连接的有效性、可访问性,以及最近的修改。
2、请求:没有请求体

3、响应:没有响应正文

2.3.4 POST方法
1、向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在请求体中。POST请求可能会导致新的资源的建立和/或已有资源的修改。
2、请求过程
(1)浏览器请求TCP连接(第一次握手)
(2)服务器答应进行TCP连接(第二次握手)
(3)浏览器确认,并发送POST请求头(第三次握手,这个报文比较小,所以http会在此时进行第一次数据发送)同时可以确定源服务器是否愿意接受该请求(基于请求头)
(4)服务器返回100 Continue响应
(5)浏览器发送请求体数据
(6)服务器返回200 OK响应
3、请求
4、响应
2.3.5 PUT方法
1、数据发送到服务器以创建或更新资源,侧重于创建数据。
2、请求

3、响应
2.3.6 DELETE方法
1、DELETE方法请求源服务器删除由URI标识的资源。
2、请求

3、响应
2.3.7 TRACE方法
1、TRACE方法用于沿着目标资源的路径执行消息环回,回显服务器收到的请求,以便客户可以看到中间服务器进行了哪些(假设任何)进度或增量。主要用于测试或诊断。
2、请求
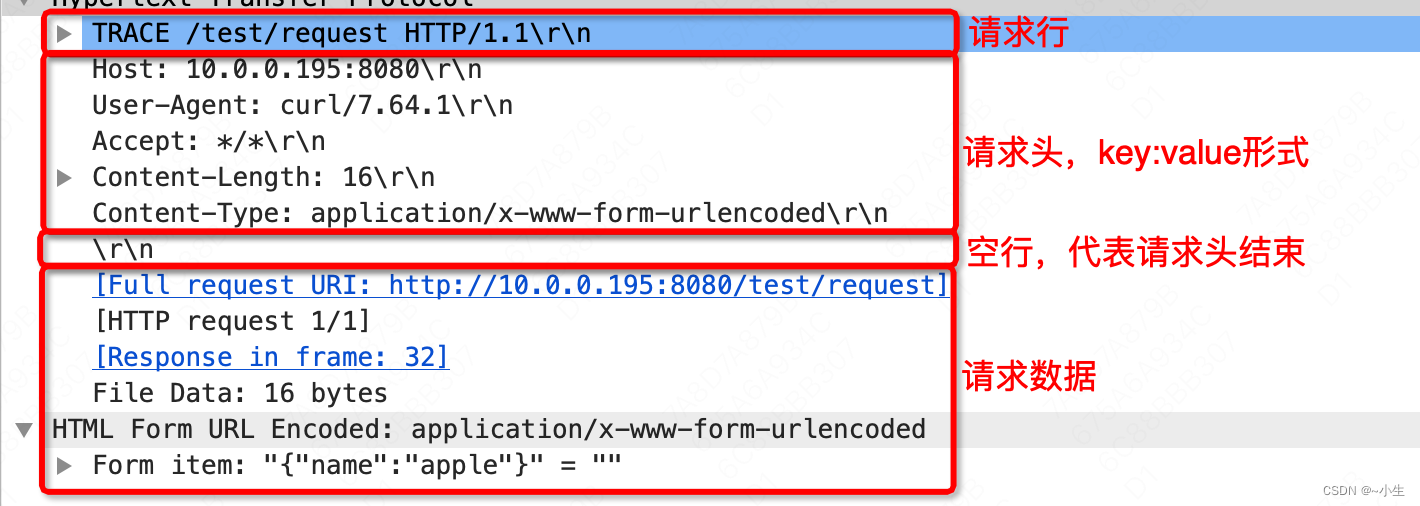
3、响应:响应正文里就是服务器收到的请求

2.3.8 CONNECT方法
1、HTTP/1.1协议中预留给能够将连接改为管道方式的代理服务器。(例如SSL编码的通信)
2.3.9 GET方法和POST方法的区别
1、参数传递的方式不同,GET请求的参数是直接拼接在地址栏URL的后面,而POST请求的参数是放到请求体里面的。
2、作用不同和使用场景不同,POST用于修改和写入数据,GET一般用于搜索排序和筛选之类的操作(淘宝,支付宝的搜索查询都是get提交),目的是资源的获取,读取数据。
3、POST的安全性更好,因为GET请求的数据都是明文显示在URL上面的,所以安全和私密性不如POST。
4、POST能发送更多的数据类型而GET只能发送字符,因为POST的请求数据是放在请求体里的数据可以是字符、图片甚至是音视频数据,而GET的请求数据是放在URL后面,所以请求数据只能是字符类型。
5、POST的请求速度比GET慢,因为GET产生一个数据包,POST产生两个数据包。对于GET请求,浏览器会把http header 和 请求数据 一并发出去,服务器响应返回数据。而对于POST,浏览器先发送header,服务器响应100 continue,浏览器再发送请求数据,服务器响应返回数据。所以POST发送了两次数据,而GET只发送一次数据。(GET方法的请求过程见“2.3.2 GET->请求过程”,POST方法的请求过程见“2.3.4 POST->请求过程”)
6、浏览器会将GET会将数据缓存起来,而POST不会。
2.4 状态码
1、状态码存在于响应报文的状态行中,状态代码旨在给机器使用,而状态码对应的含义是为人而设计。
2、状态代码是一个三位数,其中第一位数字定义了响应的类别,共有5类:
| 状态码分类 | 说明 |
|---|---|
| 1xx | 响应中:临时状态码,表示请求已经接受,告诉客户端应该继续请求或者如果它已经完成则忽略它 |
| 2xx | 成功:表示请求已经被成功接收,处理已完成 |
| 3xx | 重定向:重定向到其它地方:它让客户端再发起一个请求以完成整个处理。 |
| 4xx | 客户端错误:处理发生错误,责任在客户端,如:客户端的请求一个不存在的资源,客户端未被授权,禁止访问等 |
| 5xx | 服务器端错误:处理发生错误,责任在服务端,如:服务端抛出异常,路由出错,HTTP版本不支持等 |
3、常见的状态码描述如下(HTTP请求数据、响应数据格式、状态码_斯文~的博客-CSDN博客):( 本文只给出了常见的状态码描述,想了解全部状态码还需要查看官方文档:Status-Line)
| 状态码 | 英文描述 | 解释 |
|---|---|---|
| 200 | OK | 客户端请求成功,即处理成功,这是我们最想看到的状态码 |
| 302 | Found | 指示所请求的资源已移动到由Location响应头给定的 URL,浏览器会自动重新访问到这个页面 |
| 304 | Not Modified | 告诉客户端,你请求的资源至上次取得后,服务端并未更改,你直接用你本地缓存吧。隐式重定向 |
| 400 | Bad Request | 客户端请求有语法错误,不能被服务器所理解 |
| 403 | Forbidden | 服务器收到请求,但是拒绝提供服务,比如:没有权限访问相关资源 |
| 404 | Not Found | 请求资源不存在,一般是URL输入有误,或者网站资源被删除了 |
| 405 | Method Not Allowed | 请求方式有误,比如应该用GET请求方式的资源,用了POST |
| 428 | Precondition Required | 服务器要求有条件的请求,告诉客户端要想访问该资源,必须携带特定的请求头 |
| 429 | Too Many Requests | 太多请求,可以限制客户端请求某个资源的数量,配合 Retry-After(多长时间后可以请求)响应头一起使用 |
| 431 | Request Header Fields Too Large | 请求头太大,服务器不愿意处理请求,因为它的头部字段太大。请求可以在减少请求头域的大小后重新提交。 |
| 500 | Internal Server Error | 服务器发生不可预期的错误。服务器出异常了,赶紧看日志去吧 |
| 503 | Service Unavailable | 服务器尚未准备好处理请求,服务器刚刚启动,还未初始化好 |
| 511 | Network Authentication Required | 客户端需要进行身份验证才能获得网络访问权限 |
三、HTTP常用技术
3.1 数据统计与防盗链
1、HTTP请求头里,有一个referer字段,内容是上一页的地址,即可以告知服务端当前的请求的来源。比如一篇CSND的文章(连接为A)中引用了一个知乎的连接(连接为B),点击这个链接后,就会在浏览器在请求头里会将referer设置为CSDN文章的链接A,当知乎收到请求后就知道这次的流量是从CSDN过来的。这也就是为什么服务器知道我们请求是在哪发起的。但是如果直接从浏览器里直接输入地址,回车进去,此时没有referer信息。
2、针对此特点衍生出两个作用:
(1)数据统计:这对于数据分析来说,是非常重要的,比如,你在许多网站上投放了广告,你需要知道每个网站上的点击量,用户点击后来到你的网站,你就可以通过referer这个首部来统计各个网站的点击情况了,进而优化广告投放方法。
(2)防盗链:如果A网站引用了B网站的图片,从A网站访问该图片时,referer头信息就是A网站的链接,此时B网站收到信息后就可以知道本次请求是从A网站过来的,如果此图片仅允许在B网站内访问,不允许从其它网站访问则B网站可以不返回图片信息,此时A网站就无法引用该图片。A网站可能出现如下所图所示的情况。这就是利用referer做的防盗链。

3.2 状态管理
1、HTTP协议虽然是一个无状态协议,但是有了Cookie技术就可以管理状态了。Cookie技术通过在请求和响应报文中写入Cookie信息来控制客户端的状态。(HTTP 知识点_http请求成功一定会有响应吗_万象新生_的博客-CSDN博客)
2、Cookie就是一个本文信息,它可以用来做用户认证,服务器校验等通过文本数据可以处理的问题。
3、Cookie是服务器生成的,通过HTTP响应发送给客户端,由客户端保存起来:Cookie会根据从服务器端发送的响应报文内的一个叫做Set-Cookie的首部字段信息,通知客户端保存Cookie,将Cookie保存在用户浏览器端的。当下次客户端再往该服务器发送请求时,客户端会自动在请求报文中加入Cookie值后发送出去。服务器端发现客户端发送过来的Cookie后,会去检查究竟是从哪一个客户端发来的连接请求,然后对比服务器上的记录,最后得到之前的状态信息。
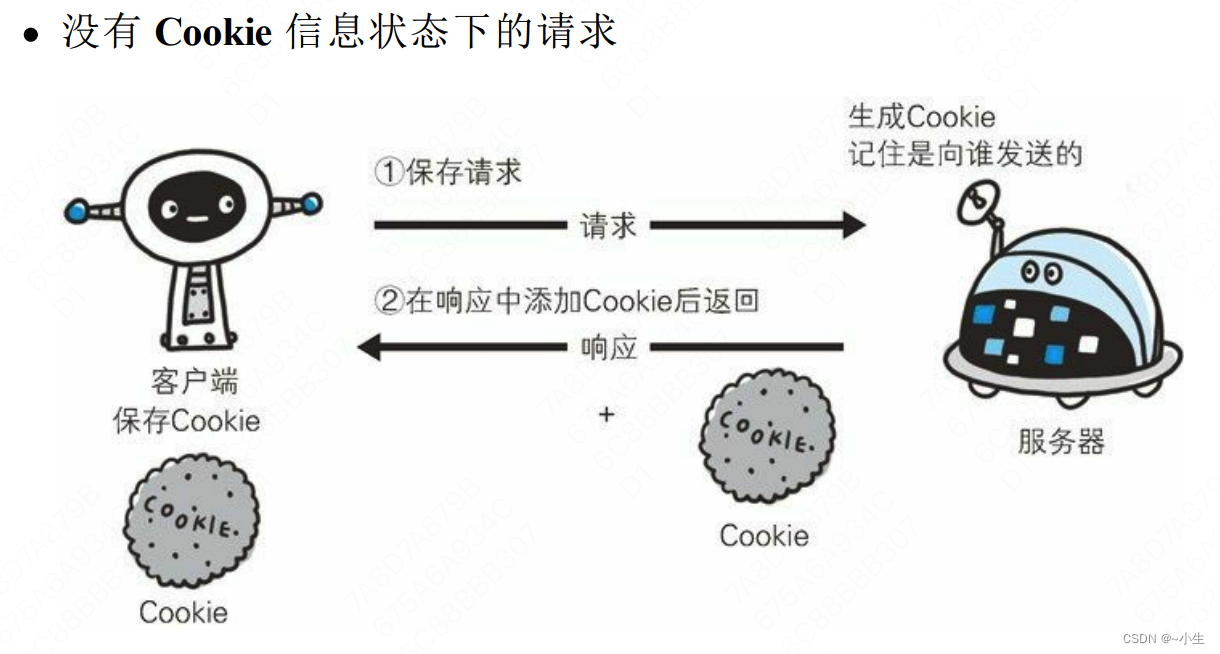
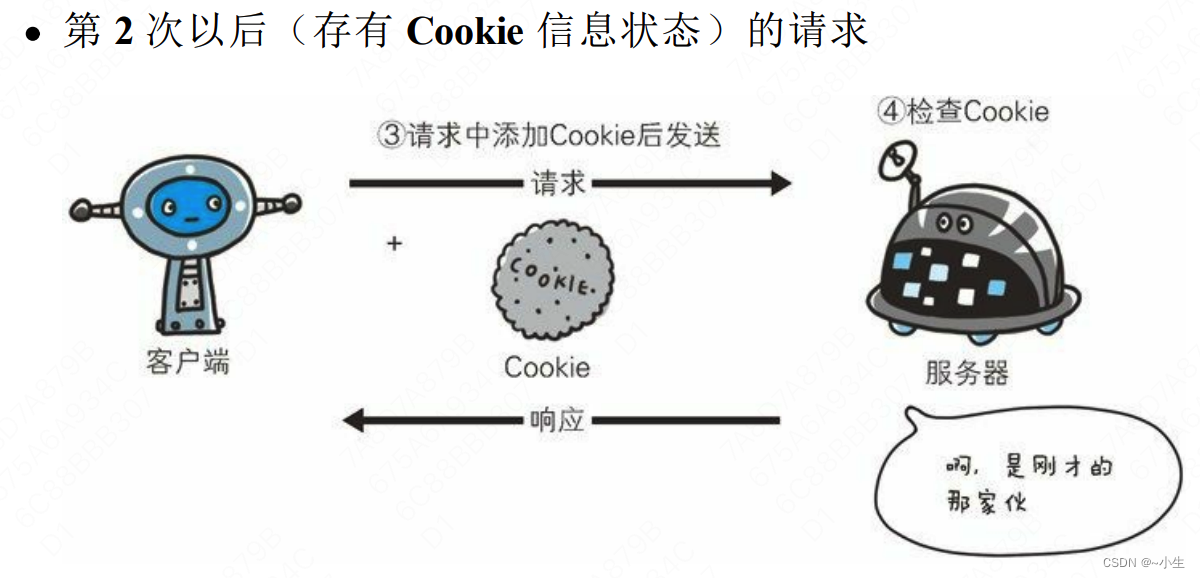
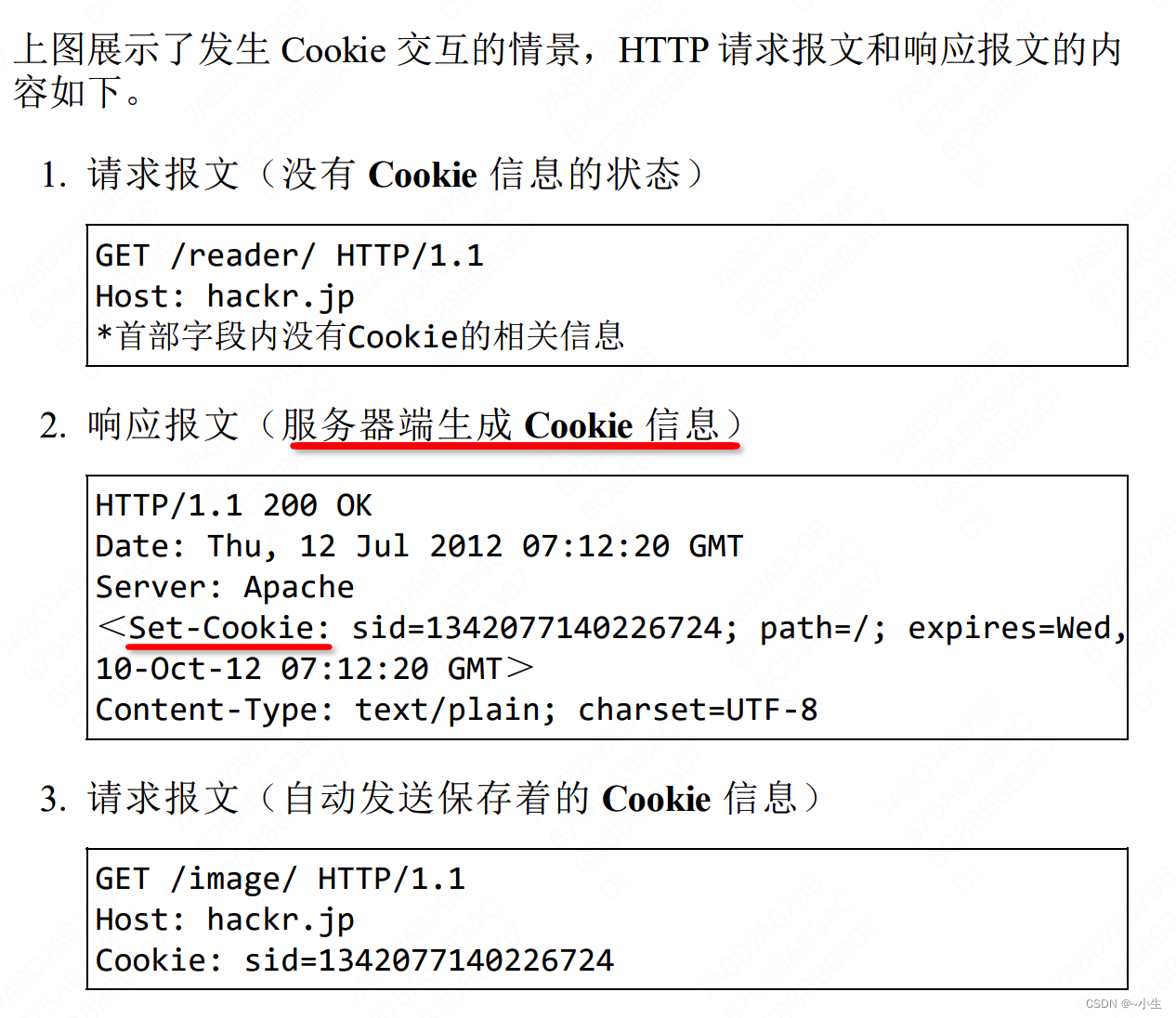
4、没有Cookie时,每次访问都像第一次访问一样,无法判断用户是否访问过,每次访问都需要重新填写用户信息。有Cookie后,仅第一次访问需要填写用户信息,后续访问可以发送Cookie,不用填写用户信息即可登录。
3.3 HTTP缓存
1、浏览器缓存是一种在本地保存资源副本,以供下次请求时直接使用的技术。
2、当浏览器在真正发起网络请求之前,浏览器会先在浏览器缓存中查询是否有要请求的文件。如果浏览器发现请求资源已经存在浏览器缓存中存有副本,则会拦截请求并返回该资源副本结束请求。如果查找缓存失败,则会进入网络请求。这样可以减轻的服务器负担,同时也节省了通信流量和通信时间。
3、即便浏览器内有缓存,也不能保证每次都会返回对同资源的请求。因为这关系到被缓存资源的有效性问题。 当遇上服务器上的资源更新时,如果还是使用不变的缓存,那就会 演变成返回更新前的“旧”资源了。 即使存在缓存,也会因为客户端的要求、缓存的有效期等因素,向服务器确认资源的有效性。若判断缓存失效,缓存服务器将会再次从服务器上获取“新”资源。
4、浏览器是通过响应头中的Cache-Control字段来设置是否缓存该资源。通常,我们还需要为这个资源设置一个缓存过期时长,而这个时长是通过Cache-Control中的Max-age参数来设置的。因此在该缓存资源还未过期的情况下, 如果再次请求该资源,会直接返回缓存中的资源给浏览器。如果缓存过期了,浏览器则会继续发起网络请求,并且在HTTP请求头中带上If-None-Match、If-Modified-Since,服务器收到请求头后,会根据If-Modified-Since、If-None-Match以及Etag的值来判断请求的资源是否有更新。如果没有更新,就返回304 Not Modified,相当于服务器告诉浏览器,这个缓存可以继续使用。如果资源有更新,服务器就直接返回最新资源给浏览器。(HTTP请求流程_http请求过程_GoodLinGL的博客-CSDN博客)(Cache-Control、If-Modified-Since、If-None-Match以及Etag的内容和作用可在本节中的“6、请求过程”中查看)
5、整体的流程可以参考下图,先查找缓存然后再根据情况看是否发起DNS解析进而发送HTTP请求。
(图片来源:HTTP请求流程_http请求过程_GoodLinGL的博客-CSDN博客)

6、请求过程
(1)第一次请求:返回200 OK

请求头:没有任何特殊
响应头: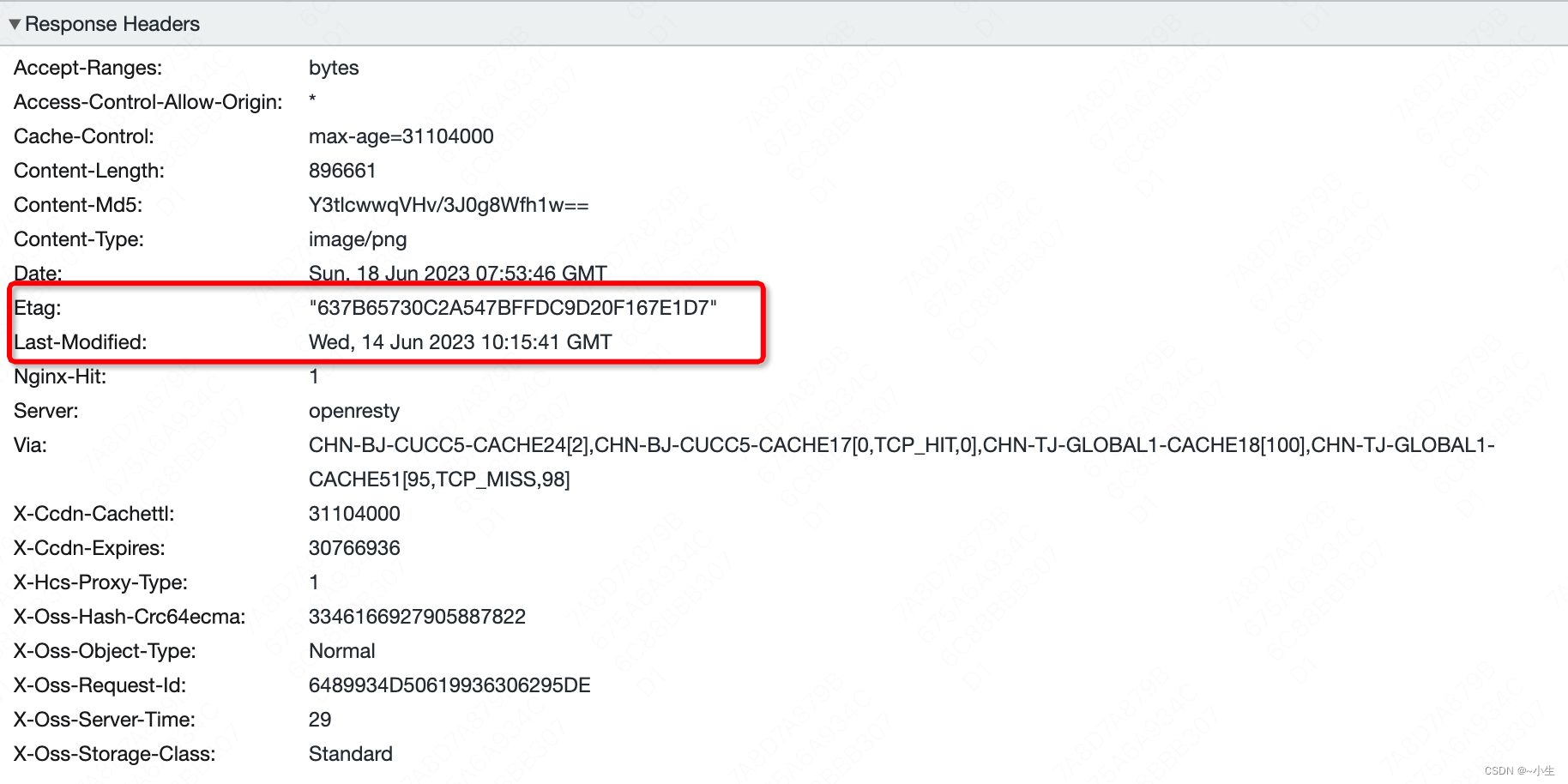
其中,Etag可以理解成文件的唯一标识,Last-Modified是文件的最后修改时间,浏览器会记录这两个信息,下次请求时会放在请求头中,服务器就可以根据请求头中的这两个信息来判断浏览器缓存的文件和服务器中的文件是否相同。如果相同则服务器会返回304 Not Modified表示文件没有修改,此时没有响应体,浏览器收到304后会从本地缓存中获取响应内容。如果不相同则服务器会返回200 OK,响应体中就是浏览器请求的文件内容。
(2)第二次请求:
返回304 Not Modified
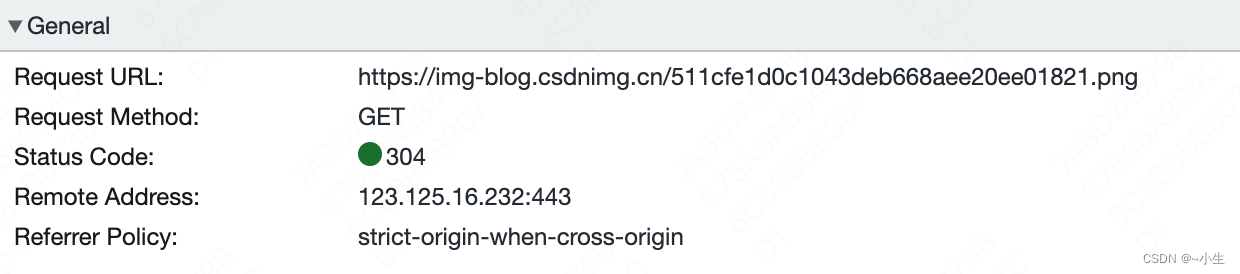
请求头:
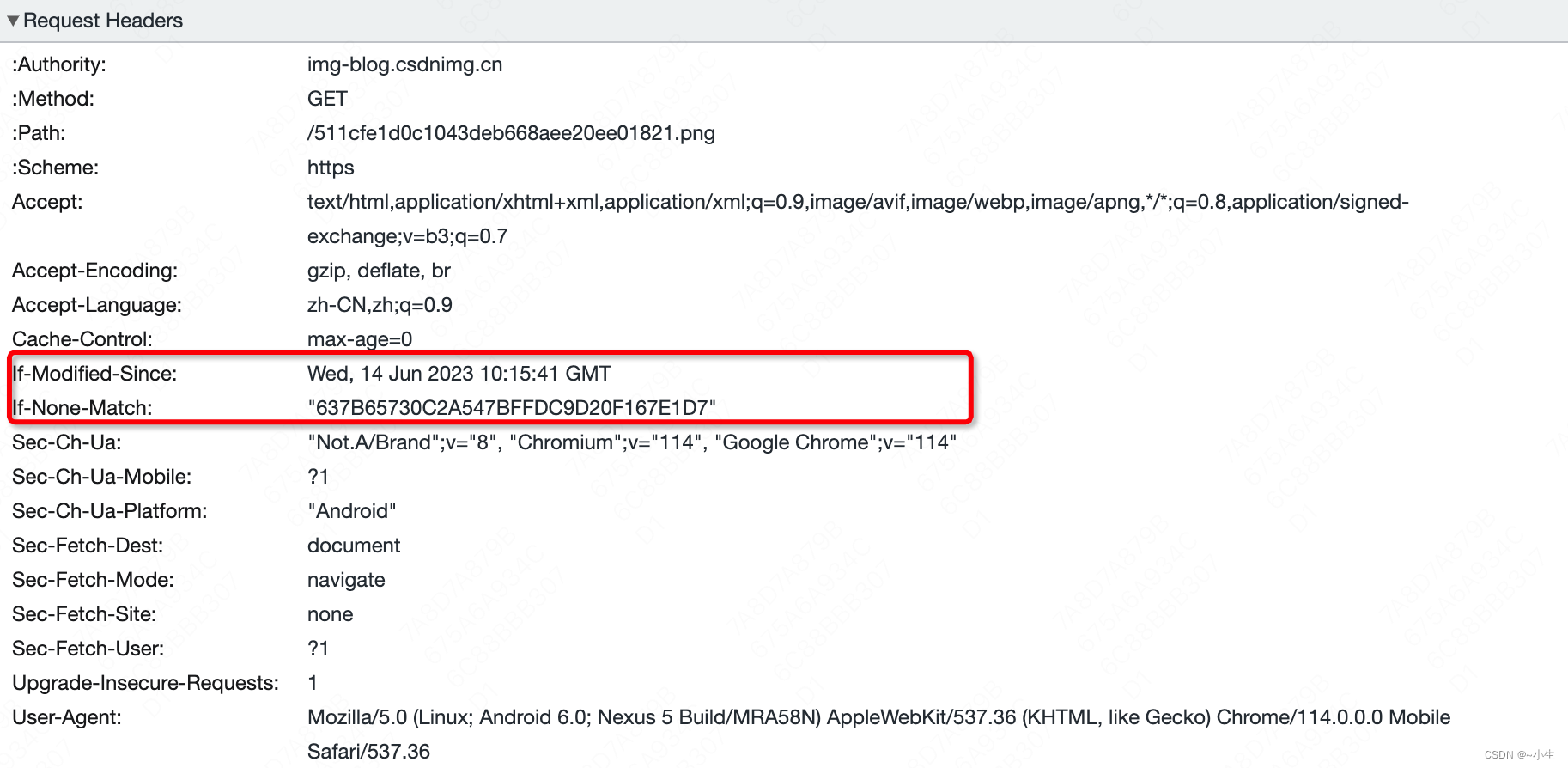
请求头中的Cache-Control浏览器设置成0,所以此时浏览器不会先查找本地缓存而是会直接发送HTTP请求至服务器。
两个条件满足一个服务器就会返回全部文件内容,(1)如果自If-Modified-Since这个时间点以后,请求的图片修改过,则不使用浏览器缓存,服务器要返回文件内容。(2)如果文件最新的Etag的值和If-None-Match的值不匹配,则不使用缓存,服务器要返回文件内容。
响应头:
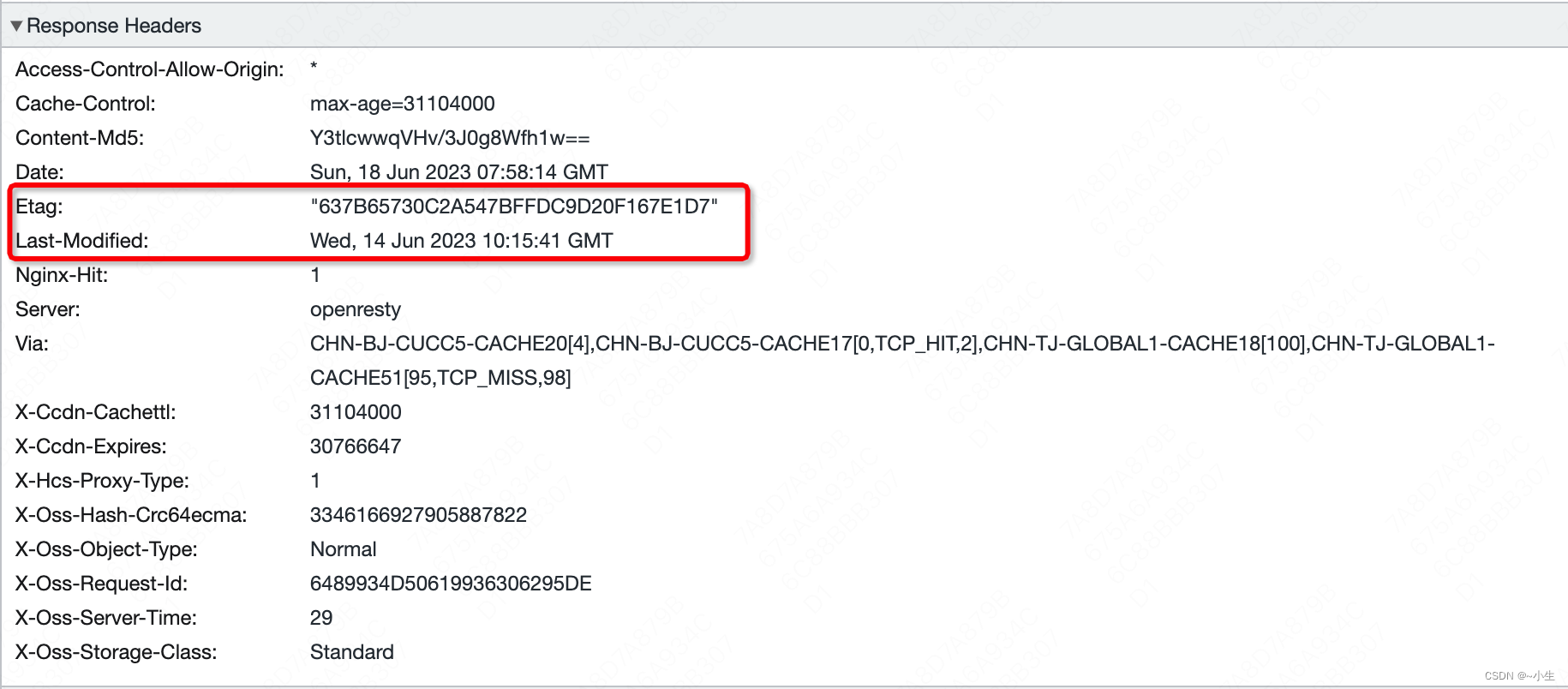
服务器获取到文件的最新的Etag,和文件的最后修改时间Last-Modified。
综合请求头和响应头的信息来看,响应头的Last-Modified的值没有超过If-Modified-Since的值,并且响应头的Etag和请求头的If-None-Match相同,所以服务器判断客户端使用本地缓存即可,因为客户端的本地缓存的文件和服务器的保存的文件是相同的,此时返回304 Not Modified,此时服务器不会返回文件内容,也就是没有响应体,提高了响应速度。
3.4 HTTP内容压缩
1、为了提高网页在网络上的传输速度、节省流量,服务器会对响应体信息进行压缩,压缩方法如常见的gzip压缩、deflate压缩、compress压缩、sdch压缩等。能大大减少网络传输的数据量,提高了用户显示网页的速度。当然,同时会增加服务器的开销,因为压缩也是要消耗CPU资源的。
2、压缩的过程
(1)浏览器发送HTTP请求给服务器, 请求头中有Accept-Encoding表示浏览器支持什么样的压缩方式。
(2)服务器接到请求后,生成原始的响应体, 其中有原始的Content-Type和Content-Length。
(3)服务器对响应体进行压缩编码, 编码响应头中有压缩后的Content-Type和Content-Length(压缩后的大小), 并且增加了Content-Encoding表示压缩方法,然后把响应发送给浏览器。
(4)浏览器接到响应后,根据Content-Encoding表示的压缩方法来对响应体进行解码。 获取到原始响应体后, 再显示出网页。
3、请求过程
请求头:说明浏览器支持gzip、deflate、br三种压缩方式。
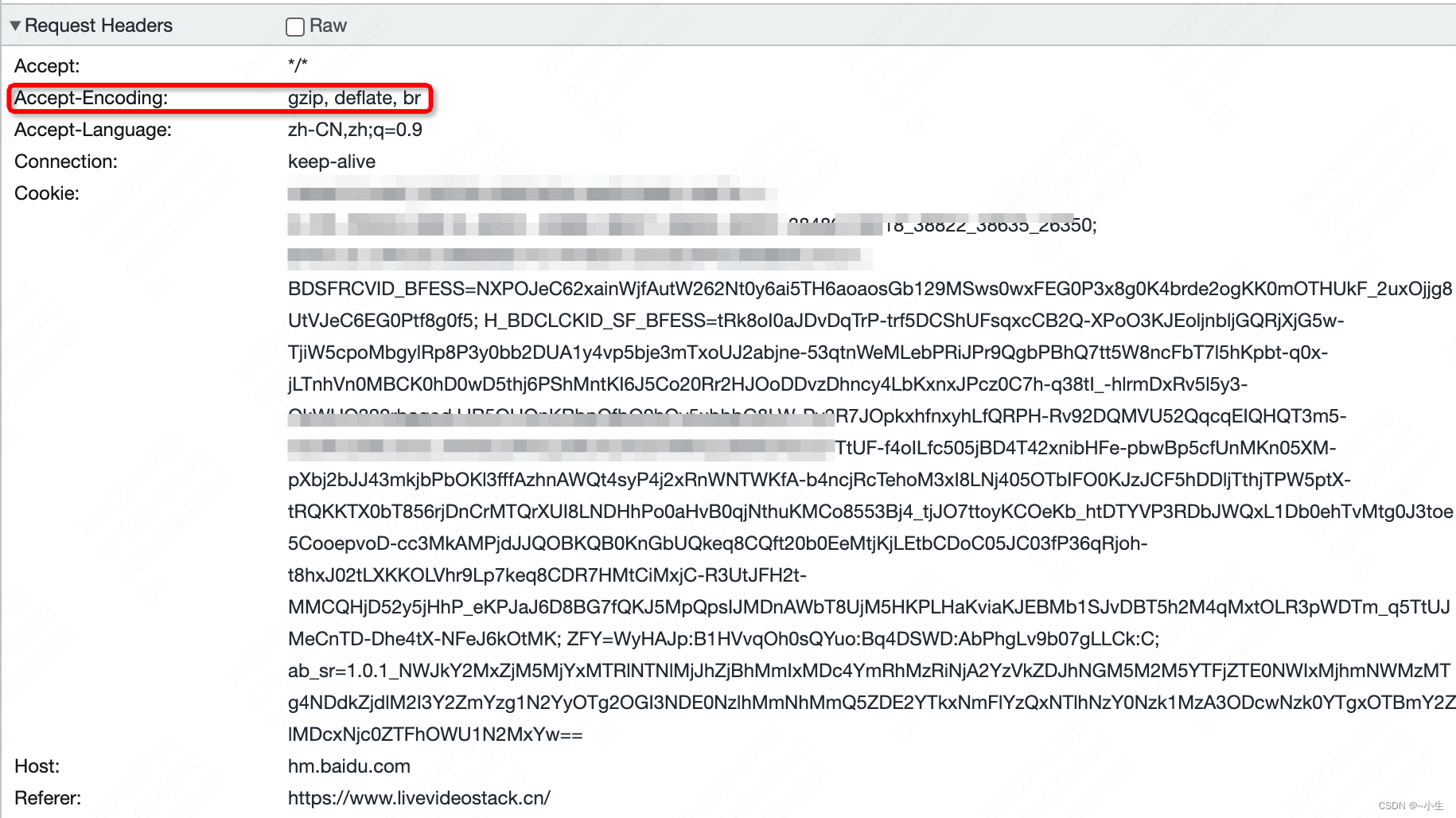
响应头:说明响应体是gzip压缩方式,浏览器浏览器会根据这种方式解压。

3.5 持久连接与分块传输
1、有的时候,服务器无法确定HTTP回应的消息的大小,比如非常大的文件的下载,或者处理的逻辑比较复杂,需要一边处理一边实时生成消息,这个时候服务器一般都使用分块chunked编码。此时,服务器不会带上Content-Length这个响应头字段,带上了另外一个响应头字段:Transfer-encoding:chunked。如果报文中包含Transfer-encoding:chunked首部, 那么Content-Length将被忽略.
2、chunked编码使用若干个chunk组成,由一个标明长度为0的chunk结束,每个Chunk有两部分组成,每个部分用回车换行隔开。因此,接收数据的时候,需要首先获取每一个chunk数据的字节长度,然后,跳过2个字节(/r/n),取出数据,然后,再跳过2个字节(/r/n),获取下一个chunk的长度,直到最后一个chunk,最后一个chunk一定是0,并且字节的长度都是十六进制形式传输,需要进行相应的转化成十进制,如果是gzip格式的数据,那么,在最后完成所有数据组合之后,需要再解压。
比如传输内容:先读取123字节内容,然后再读区41字节内容,最后读到0H(也就是一个空包),读取结束,即最后一个块的大小为0,用于表示数据传输结束。
123H/r/n
....(123字节内容)
41H/r/n
...(41字节内容)
0H/r/n(结束)
3、分块传输优点(HTTP首部——分块传输和持久连接_CrazyDragon_King的博客-CSDN博客)
(1)动态内容,Content-length无法预知:HTTP分块传输编码允许服务器为动态生成的内容维持HTTP持久连接。通常,持久连接需要服务器在开始发送消息体前发送Content-Length消息头字段,但是对于动态生成的内容来说,在内容创建完之前是不可知的。
(2)gzip压缩,压缩与传输同时进行:HTTP服务器有时使用压缩 (gzip或deflate)以缩短传输花费的时间。分块传输编码可以用来分隔压缩对象的多个部分。在这种情况下,块不是分别压缩的,而是整个负载进行压缩,压缩的输出使用本文描述的方案进行分块传输。在压缩的情形中,分块编码有利于一边进行压缩一边发送数据,压缩过程中,压缩完成的内容可以分块传输,未压缩的部分可以继续压缩,而不是先完成所有压缩过程以得知压缩后数据的大小再分块传输。
(3)散列签名,需缓冲完成才能计算:分块传输编码允许服务器在最后发送消息头字段。对于那些头字段值在内容被生成之前无法知道的情形非常重要,例如消息的内容要使用散列进行签名,散列的结果通过HTTP消息头字段进行传输。没有分块传输编码时,服务器必须缓冲内容直到完成后计算头字段的值并在发送内容前发送这些头字段的值。
4、请求过程
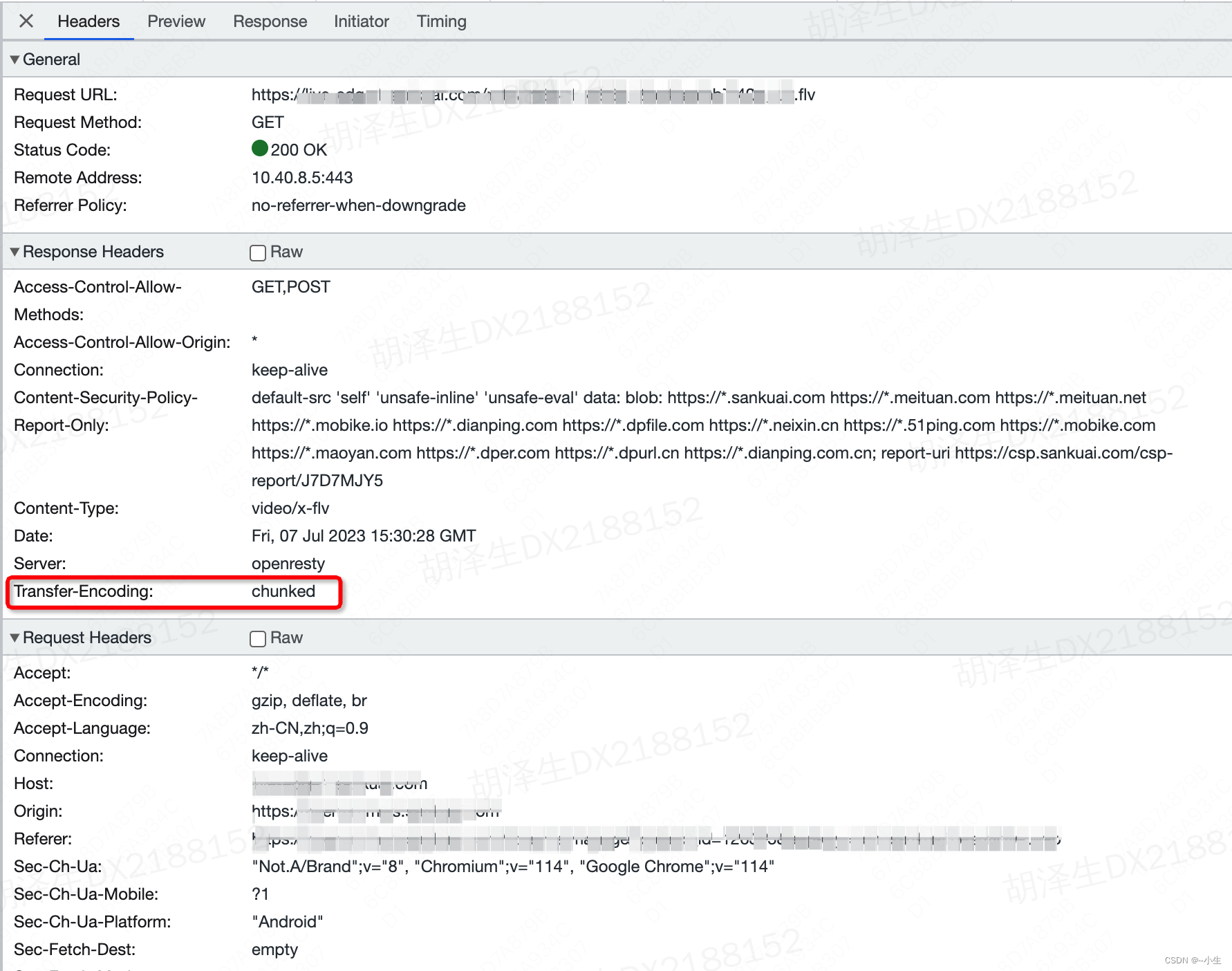
四、知识点汇总
1、在浏览器地址栏键入URL,按下回车之后会经历的流程:详见“2.1 请求/响应过程->2”
2、HTTP GET方法和POST方法的区别:详见“2.3.9 GET方法和POST方法的区别”
3、HTTP请求、响应报文格式:详见“2.2 请求/响应报文”
4、头部字段名不区分大小写,例如“Host”也可以写成“host”,但首字母大写的可读性更好。
五、HTTP使用场景及优缺点
1、使用场景
(1)Web应用,HTTP最广泛的应用就是Web应用程序。无论是桌面端的浏览器还是移动端的应用程序,HTTP都是应用层协议。
(2)API接口,在Web应用程序中,API接口是连接前端UI和后端数据的桥梁。HTTP协议的接口设计,可以使不同语言、不同框架的应用程序在接口层面得到统一,以方便数据的交互与共享。
2、优点:
(1)简单易用:HTTP 协议的语法和规范相对简单,容易学习和使用。
(2)可扩展性:HTTP 协议支持插件和扩展,可以根据需要添加新的功能和特性。
(3)传输超文本:HTTP 协议是传输超文本的标准协议,可以在网页中嵌入各种形式的媒体内容。
(4)分布式:HTTP 协议是基于客户端-服务器模式的,可以支持分布式计算和资源共享。
(5)跨平台性:HTTP 协议是跨平台的,可以在不同的操作系统、编程语言和硬件平台上使用,具有较好的兼容性。
(6)可读性强:HTTP 协议使用文本形式来表示请求和响应,具有较好的可读性,方便调试和排错。
(7)支持多种传输方式:HTTP 协议支持多种传输方式,如普通文本、JSON、XML 等,可以适应不同的应用场景。
(8)支持代理服务器:HTTP 协议支持代理服务器,可以在客户端和服务器之间建立代理,从而增强了协议的灵活性和可扩展性。
3、缺点:
(1)安全性差:HTTP 协议是明文传输的,数据容易被窃听和篡改,因此安全性较差,需要额外的安全机制来保护数据的安全。
(2)性能较低:HTTP 协议在传输大量数据和处理高并发请求时,性能较低,容易导致网络拥塞和延迟。
(3)不支持推送功能:HTTP 协议不支持服务器向客户端主动推送数据的功能,客户端需要定期向服务器发送请求才能获取最新的数据。
(4)没有优先级控制:HTTP 协议没有优先级控制的机制,所有的请求和响应都被视为同等重要,这可能会影响一些特定应用场景的性能表现。
(5)请求-响应模式:HTTP 协议采用请求-响应模式,即客户端必须等待服务器响应后才能进行下一步操作,这可能会影响用户体验和应用程序的响应速度。

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐


 5
5 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)