

SpringCloudAlibaba
微服务其实本质上还是分布式,只是拆分的粒度大与小的问题。微服务是一种架构风格,这个概念最早是 Martin Folwer 提出,它的每个服务都是一个可以独立运行的应用,每个服务运行在自己独立的进程中,服务间通常使用http请求来相互沟通,每个服务以一种去中心化的方式进行运行。
Spring Cloud Alibaba
一. 简介
微服务其实本质上还是分布式,只是拆分的粒度大与小的问题。微服务是一种架构风格,这个概念最早是 Martin Folwer 提出,它的每个服务都是一个可以独立运行的应用,每个服务运行在自己独立的进程中,服务间通常使用http请求来相互沟通,每个服务以一种去中心化的方式进行运行。
Spring Cloud是2017年开始流行,它是将 NetFlix 开源的框架集成到spring 中,出现了 spring cloud. Netflix 在2020年初的时候将自家的几个产品不再开源。但是很多企业内部虽然用spring cloud,但是其中夹杂着很多阿里的框架,然后阿里顺势就是在spring cloud的基础上研发 spring cloud alibaba,将spring cloud 内部使用的 Netflix的一些组件摒弃掉了。
微服务架构它并没有解决项目内部的编码问题,只是解决服务间的调用问题。
二. Spring Cloud Alibaba的搭建
只需要在父工程中引入如下的依赖:
<dependencyManagement>
<dependencies>
<!-- spring cloud alibaba的依赖 -->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-dependencies</artifactId>
<version>2.2.7.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<!-- spring cloud的依赖 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>Hoxton.SR12</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
三. Nacos
2.1 注册中心
每个应用都有一个自己的服务名(不能改变的),将当前服务的ip和端口信息注册到nacos上。它的作用是起到一个解耦的作用。
在市面上有很多注册中心产品:nacos(Alibaba)、eureka(Spring Cloud本身产品)、consul(go语言)、redis、zookeeper。
2.1.1 nacos的搭建
第一步,解压 nacos-server-2.0.4.zip
第二步,修改
$NACOS_HOME/bin/startup.cmd这个文件,修改第26行代码,然后 双击$NACOS_HOME/bin/startup.cmd启动nacos
# 修改之前的配置
set MODE="cluster"
# 修改之后的配置
set MODE="standalone"
第三步,在浏览器输入 http://localhost:8848/nacos,使用 nacos/nacos 用户名/密码来登录nacos
2.1.2 注册应用的信息
在应用的依赖中加入如下的依赖:
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
在
yml中加入如下的依赖即可
server:
port: 8083
spring:
application:
# 应用的服务名词
name: ms-provider
cloud:
nacos:
discovery:
# nacos 的地址
server-addr: localhost:8848
# 是否将自己的服务注册到nacos上去
register-enabled: true
调用服务的代码实现:
@RestController
@RequestMapping("/tc")
public class TestController {
@Resource
private DiscoveryClient discoveryClient;
private AtomicInteger num = new AtomicInteger();
@GetMapping
public List<String> get() {
List<ServiceInstance> instances = discoveryClient.getInstances("ms-provider");
ServiceInstance serviceInstance = instances.get(num.incrementAndGet() % instances.size());
String url = String.format("http://%s:%d/user", serviceInstance.getHost(), serviceInstance.getPort());
System.out.println(url);
ResponseEntity<List> responseEntity = restTemplate.getForEntity(url, List.class);
return responseEntity.getBody();
}
}
2.1.3 修改nacos的登陆信息
- 在数据中新建一个数据库,例如名为:nacos
- 将
$NACOS_HOME\conf\nacos-mysql.sql脚本在 nacos 数据库中执行,修改 users 中的密码(使用Spring Security中密码)
- 修改
$NACOS_HOME\conf\application.properties文件,指定要连接的数据库的信息
# spring.datasource.platform=mysql
# 数据库的类型
spring.datasource.platform=mysql
### Count of DB:
# 数据库的数量
db.num=1
### Connect URL of DB:
# 0表示索引
db.url.0=jdbc:mysql://127.0.0.1:3306/nacos?characterEncoding=utf8&connectTimeout=1000&socketTimeout=3000&autoReconnect=true&useUnicode=true&useSSL=false&serverTimezone=UTC
db.user.0=root
db.password.0=123456
2.2 配置中心
配置中心就是将所有的微服务的配置进行集中化的管理,统一运维。
第一步,在项目中导入如下的依赖
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
</dependency>
第二步,在
resources目录下新建一文件,bootstrap.yml。在springboot启动的过程,会优先加载bootstrap.yml文件,所有在 bootstrap.yml 文件执行配置中心的位置,以及要加载的配置文件
# 在项目启动的时候,在到nacos上名为 ms-consumer-dev.yml 文件
spring:
cloud:
nacos:
config:
# nacos 的地址
server-addr: localhost:8848
# 文件的后缀名
file-extension: yml
profiles:
# 配置文件的环境
active: dev
application:
# 服务名
name: ms-consumer
第三步,在nacos加入对应环境的配置
四. Ribbon
Ribbon 是一个客户端的负载均衡器,用来控制服务的调用. 使用它可以轻松的配置不同的负载均衡策略。
只需要加上 @LoadBalanced 注即可使用
@GetMapping
public List<String> get() {
ResponseEntity<List> responseEntity = restTemplate.getForEntity("http://ms-provider/user", List.class);
return responseEntity.getBody();
}
五. Feign
Feign是在Ribbon的基础上开发的另外一个负载均衡器,目的是让我们像调用本地服务一样去调用远程服务。
第一步,需要在项目中引入如下的依赖:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
第二步,要开启 Feign,在启动类上加上
@EnableFeignClients这个注解开启 feign
@SpringBootApplication
@EnableFeignClients
public class ConsumerApplication {
public static void main( String[] args ) {
SpringApplication.run(ConsumerApplication.class, args);
}
}
第三步,编写服务层接口
@FeignClient("ms-provider")
public interface TestService {
@GetMapping("/user")
List<User> get();
/**
* 1.如果有参数,并且没有加 @RequestParam 注解,那么Feign就认为我们发送的是一个 POST 请求,一旦认定是POST, 就必须只能有一个参数;
* 2.如果要想发送GET 请求,并且传递参数,那么要加上 @RequestParam 注解
*/
@GetMapping("/user/single") // http://localhost:8082/user/single?id=3
User getUser(@RequestParam Integer id);
// 有参数,但是参数没有加 @RequestParam,那么Feign就认为你发送的一个 post请求,就只能有一个参数;
@GetMapping("/user/multi-param")
User getUser(@RequestParam String name, @RequestParam Integer id);
@GetMapping("/user/path/{id}")
User getUserWithId(@PathVariable("id") Integer id);
@PostMapping("/user")
String add(User user);
@DeleteMapping("/user/{id}")
String delete(@PathVariable("id")Integer id);
@PutMapping("/user")
String edit(User user);
}
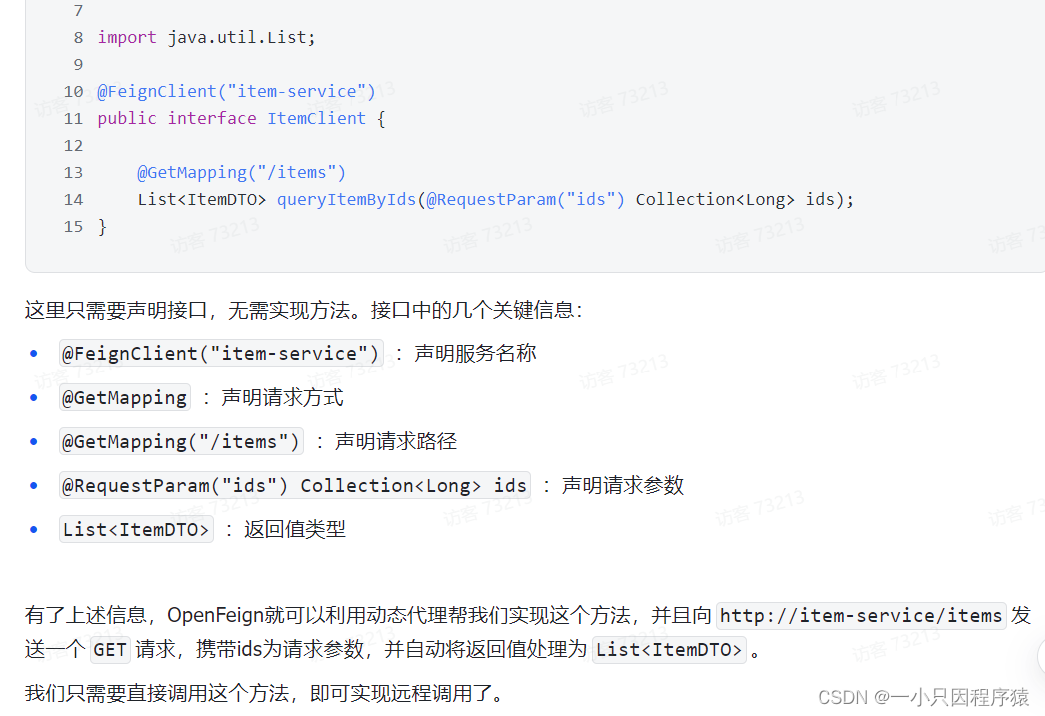
```
### 六. 服务的熔断与降级
> 分布式系统中一个微服务需要依赖于很多的其他的服务,那么服务就会不可避免的失败。例如A服务依赖于B、C、D等很多的服务,当B服务不可用的时候,会一直阻塞或者异常,更不会去调用C服务和D服务。同时假设有其他的服务也依赖于B服务,也会碰到同样的问题,这就及有可能导致雪崩效应。
>
> 如下案例:一个用户通过通过web容器访问应用,他要先后调用A、H、I、P四个模块,一切看着都很美好。
> 由于某些原因,导致I服务不可用,与此同时我们没有快速处理,会导致该用户一直处于阻塞状态。
> 当其他用户做同样的请求,也会面临着同样的问题,tomcat支持的最大并发数是有限的,资源都是有限的,将整个服务器拖垮都是有可能的。
> Sentinel是一个用于分布式系统的延迟和容错的开源库,在分布式系统中,许多依赖会不可避免的调用失败,例如超时,异常等,Sentinel能保证在一个依赖出现问题的情况下,不会导致整体服务失败,避免级联故障,以提高分布式系统的弹性。
>
> 断路器本身是一种开关装置,当某个服务单元发生故障后,通过断路器的故障监控(类似于保险丝),向调用者返回符合预期的,可处理的备选响应,而不是长时间的等待或者抛出无法处理的异常,这样就保证了服务调用的线程不会被长时间,不必要的占用,从而避免故障在分布式系统中的蔓延,乃至雪崩。
>
> Sentinel在网络依赖服务出现高延迟或者失败时,为系统提供保护和控制;可以进行快速失败,缩短延迟等待时间;提供失败回退(Fallback)和相对优雅的服务降级机制;提供有效的服务容错监控、报警和运维控制手段。
>
> 下载地址:<https://github.com/alibaba/Sentinel/releases>
#### 6.1 sentinel的使用
> 第一步,启动sentinel的服务,java -jar sentinel-dashboard-1.8.4.jar
> 第二步,在项目中加入如下的依赖
```xml
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-sentinel</artifactId>
</dependency>
第三步,在yml文件中加入如下的配置:
spring:
application:
name: ms-consumer
datasource:
url: jdbc:mysql://localhost:3306/qf?characterEncoding=utf8&useSSL=false&serverTimezone=Asia/Shanghai
username: root
password: 123456
driver-class-name: com.mysql.cj.jdbc.Driver
hikari:
minimum-idle: 3
maximum-pool-size: 8
# nacos的配置
cloud:
nacos:
discovery:
server-addr: localhost:8848
register-enabled: false
# sentnel的配置
sentinel:
transport:
# 将系统的接口访问清况进行上报
dashboard: localhost:8080
6.2 sentinel的服务限流
- QPS(Query Per Second),每秒钟系统的请求数量,衡量一个接口好坏一个指标;
- 单机阈值,每秒钟接口的访问的最大QPS;
- 快速失败:就是超过阈值,直接访问不了了;
- Warm Up: 就是在系统刚启动之初的时候,第一秒的QPS是
单机阈值 / coldFactor(冷因子,默认值为3);在指定时间之后,阈值才能达到指定的值;- 排队等待:就是超过阈值的请求不会立即失败,排队等待,等待指定的时间如果还没有处理,就失败;
6.3 熔断
针对上图:如果在1000ms之内,有5个及以上的请求,如果有50%以上的请求相应时间超过80ms,那么在未来3s之内,都是无法访问该接口的。
七. Gateway网关
网关的作用是请求的分发和过滤。
假如我们的应用有很多的微服务,前端数据来源与不同的微服务,而且有些微服务可能还存在者集群,前端的配置的会变得非常的混乱,后端一旦发生了调整,前端也需要调整,所以亟需一个统一的入口,来将请求分发到不同的微服务中以及某个服务的集群中。
在微服务中,很多服务的接口必须满足某些条件才能访问,我们在每个服务单独来实现条件的控制,所所以需要一个统一的过滤;
spring cloud 最早的网关使用的 zuul,但是其现在已经停止维护了,而且其性能也很低。Gateway是spring cloud 第二代网关,它底层使用 netty来实现,它的服务器是使用的netty,不需要依赖web容器(tomcat).
如下图所示为gateway的工作过程
7.1 路由配置
spring:
application:
name: ms-gateway
cloud:
# 配置nacos的地址
nacos:
discovery:
server-addr: localhost:8848
gateway:
discovery:
locator:
# 表示可以通过 服务名的方式来访问对应的服务; 我们通常的做法是设置false, 因为这种方式暴露了我们的服务名
# http://localhost:9090/ms-consumer/msg-info
# http://localhost:9090/ms-provider/user
enabled: false
# 配置网关路由,就类似与vue中的路由表
routes:
#每个路由都有一个唯一id, 这个名字随便,但是需要保证唯一性; 通常写服务名
- id: ms-consumer
# ms-consumer 就表示服务名的意思;bl:// 是固定的写法,lb(load balance)
uri: lb://ms-consumer
# 谓词,断言
predicates:
# 当用用户访问 http://localhost:9090/msg-info 或者 http://localhost:9090/tc
# 都会定位 ms-consumer这个服务器中
- Path=/mc/**
# 表示请求的时候,必须要携带 token 参数; 而且参数值必须为数字
#- Query=token,\d+
# 表示请求头中必须要携带 Authorization 这样一个参数
#- Header=Authorization
- After=2023-02-08T14:00:00+08:00[Asia/Shanghai]
- Before=2023-02-21T14:00:00+08:00[Asia/Shanghai]
# - RemoteAddr=192.168.50.48/28 # 192.168.50.48 ~ 192.168.50.63
- RemoteAddr=192.168.50.160/27 # 192.168.50.160 ~ 192.168.50.191
filters:
# 表示将用户请求路径的第一个段路径去掉,用剩下的 uri, 定位到对应的服务中,例如:
# http://localhost:9090/mc/msg-info, 根据 Path的配置,这个请求会到 ms-consumer这个服务中
# 根据 /mc/msg-info 到ms-consumer中去请求资源,因为配置 StripPrefix=1, 就将 /ms 去掉,最终就根据
# /msg-info 到ms-consumer中找到对应的资源
- StripPrefix=1
Path: 表示用户的请求路径
Query: 表示用户请求必须要携带指定的参数
Header:表示用户请求的请求头必须要携带指定的参数
After:表示只能在指定的时间之后才能访问
Before:表示只能在指定的时间之前才能访问;
RemoteAddr:限制ip段访问
7.2 IP访问限制
GateWay提供了很多内置的过滤器让我们使用,具体的过滤器在spring-cloud-gateway-server-2.2.9.RELEASE.jar下的org.springframework.cloud.gateway.filter.factory包下,接下来我们挑其中一个非常常用的过滤来讲解用法,在实际的开发过程中,有这样一种业务需求,就是限制同一个IP对服务器频繁的请求,例如我们限制每个IP在每秒只能访问3次,那么要怎么实现呢?其实spring-boot已经帮我们实现好了一个,只需要做一定的配置就可以了。
IP限制的原理就是令牌桶算法,随着时间流逝,系统会按恒定 1/QPS 时间间隔(如果 QPS=100,则间隔是 10ms)往桶里加入 Token,如果桶已经满了就不再加了。新请求来临时,会各自拿走一个 Token,如果没有 Token 可拿了就阻塞或者拒绝服务。如下图所示:
添加依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis-reactive</artifactId>
</dependency>
编写获取要进行限流的方式(IP、mac地址、IMEI号等)的类:
// 这个实例在容器中的名字:remoteIpResolver
@Component
public class RemoteIpResolver implements KeyResolver {
/**
* 1.获取我们想要限制用户的方式,可以获取设备号,IP,Mac地址等
* 2.WebFlux编程,反应式编程, 受限于数据库; 彻底抛弃 tomcat; 反应式编程底层用 netty.
* 3.WebFlux编程中有非常重要3个东西:
* 1) Mono -> 用于返回单条数据
* 2) Flux -> 用于返回多条数
* 3) ServerWebExchange 包含了请求与相应
*/
@Override
public Mono<String> resolve(ServerWebExchange exchange) {
String ip = exchange.getRequest().getRemoteAddress().getAddress().getHostAddress();
return Mono.just(ip);
}
}
添加配置
spring:
application:
name: ms-gateway
redis:
host: 192.168.24.128
port: 6379
password: admin
cloud:
gateway:
routes:
filters:
- name: RequestRateLimiter
args:
# keyResolver: 是需要我们来定义限制用户的方式(ip 或者 设备号(IMEI编码,PC的mac地址)),spring 不管
# SpEL(spring的表达式语言),#{@} 是固定用法,花括号中,@符号后的内容就是spring ioc容器中某个bean的名字
keyResolver: '#{@remoteIpResolver}'
# 每秒往令牌桶中存放的数量
redis-rate-limiter.replenishRate: 3
# 令牌桶中最多的令牌数量
redis-rate-limiter.burstCapacity: 3
7.3 局部过滤器
对于一个过滤器的价值无非就是获取请求参数、请求头、url地址来进行一定的逻辑判断,true就接着往下走,false是直接打断这个请求。
局部过滤器作用的范围只针对某一个或者某个几个服务,对于局部过滤器的定义需要注意以下两点:
- 过滤器的名字必须以 GatewayFilterFactory 来结尾;
- 过滤器继承 AbstractNameValueGatewayFilterFactory
/**
* 对于一个过滤器来说,它的作用无非就是获取请求参数、url、请求头信息,然后做一些判断,通过往下走,不通过就返回信息。
*/
@Component
public class CustomizeLocalFilterGatewayFilterFactory extends AbstractNameValueGatewayFilterFactory {
@Override
public GatewayFilter apply(NameValueConfig config) {
/**
return new GatewayFilter() {
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
return null;
}
};
*/
return (exchange, chain) -> {
System.out.println(config.getName() + ":" + config.getValue());
// 获取到一个请求
ServerHttpRequest request = exchange.getRequest();
// 获取到相应
ServerHttpResponse response = exchange.getResponse();
System.out.println(request.getURI().getPath());
// 41 - 45行代码就是如何获取请求参数的。
MultiValueMap<String, String> queryParams = request.getQueryParams();
List<String> usernameList = queryParams.get("username");
if(!CollectionUtils.isEmpty(usernameList) && usernameList.size() == 1) {
System.out.println(usernameList.get(0));
}
// 如下代码就是获取请求头
List<String> list = request.getHeaders().get("Authorization");
if(!CollectionUtils.isEmpty(list) && list.size() == 1) {
System.out.println("Authorization:" + list.get(0));
return chain.filter(exchange); // 类似于web中,chain.doFilter() 接着往下走
}else { // 返回一个json
// 在 Flux编程中如何返回一个数据
Map<String, Object> result = ImmutableMap.of("code", -1, "msg", "error");
String json = JSONObject.toJSONString(result);
DataBuffer dataBuffer = new DefaultDataBufferFactory()
.wrap(json.getBytes(StandardCharsets.UTF_8));
return response.writeWith(Mono.just(dataBuffer));
}
};
}
}
添加配置:
filters:
# a,b是一对参数,可以在代码层通过config来获取
- CustomizeLocalFilter=a,b
7.4 全局过滤器
全局过滤器定义完之后,可以作用到所有的服务上
@Configuration
public class GlobalFilterDefinition {
@Bean
public GlobalFilter firstGlobalFilter() {
return (exchange, chain) -> {
// ServerHttpRequest request = exchange.getRequest();
System.out.println("全局过滤器");
return chain.filter(exchange);
};
}
}
八. 链路追踪
在微服务中,一个接口的调用链路可能会很长,在某些场景下(接口访问时间慢,需要调试),我们需要知道该接口的整个调用链路。
spring cloud中实现链路追踪需要用到 zipkin + slueth.
第一步,启动 zipkin服务,
java -jar zipkin-server-2.23.2-exec.jar
第二步,在所有的需要进行链路追的服务中添加如下的依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
第三步,就在所有需要进行链路追踪的位置,添加如下的配置
spring:
zipkin:
# zipkin的地址,将数据上报
base-url: http://localhost:9411/
# If set to false, will treat the baseUrl as a URL always.
discovery-client-enabled: false
sleuth:
sampler:
# 抽样率 100%, 默认10%
probability: 0.2
第二步,在所有的需要进行链路追的服务中添加如下的依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
第三步,就在所有需要进行链路追踪的位置,添加如下的配置
spring:
zipkin:
# zipkin的地址,将数据上报
base-url: http://localhost:9411/
# If set to false, will treat the baseUrl as a URL always.
discovery-client-enabled: false
sleuth:
sampler:
# 抽样率 100%, 默认10%
probability: 0.2

权威|前沿|技术|干货|国内首个API全生命周期开发者社区
更多推荐
 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)