利用python批量化高效实现长语音识别(任何时长语音可用)
利用python批量化实现语音切割再重组实现长语音识别
·
提示:借助本文提供的代码,把对应的文件地址修改为自己电脑的地址即可直接使用,旨在解决由于各语音识别api只能实现60s以内语音转文字的缺点,批量化实现任何时长语音转文字的任务。
一、实现思路及效果
1.实现思路
语音切割 → 调用百度api识别短语音 → 再进行短文本组合
2.实现效果
废话少说,利用本文代码,可高效实现批量化语音转文字任务。本文实验数据为抖音各up主短视频数据,主要涉及三个文件夹:
**audios文件夹**:存放各up主wav格式语音文件;
**audios_try文件夹**:临时存放已切割的语音文件
**recognize文件夹**:各语音转文字结果的txt文件
详见下图:
audios文件夹下存储各up短视频语音数据,以wav形式存储:
wav格式语音文件:
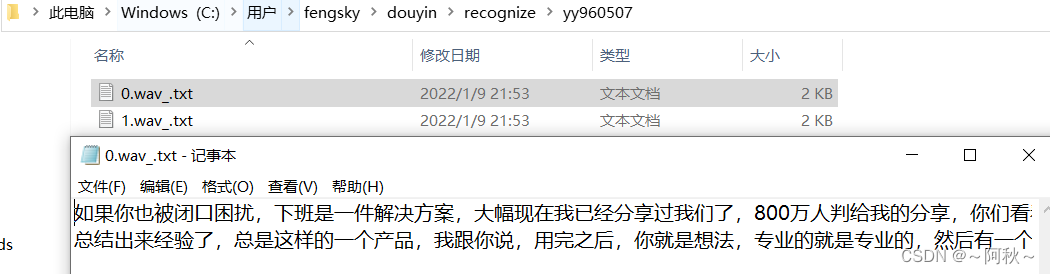
python语音转文字实现效果:
二、代码
1.引入库
import os
from aip import AipSpeech #语音识别第三方库
from pydub import AudioSegment #语音分割模块
from pydub.utils import mediainfo
from natsort import ns, natsorted #用于文件夹排序,防止文件夹乱序
import time
import pandas as pd
2.语音识别
class audio_reg(object):
def __init__(self):
self.id = input('输入作者id:')
self.video_dir = f"C:\\Users\\fengsky\\douyin\\audios\\{self.id}"
self.audio_list = natsorted(os.listdir(self.video_dir),alg=ns.PATH) #音频列表
#语音分割
def speech_seg(self,filename): # filename---未分割的音频文件名称
path = self.video_dir + "\\" + filename
#判断是否存在作者文件夹
txt_path = f"C:\\Users\\fengsky\\douyin\\recognize\\{self.id}"
folder = os.path.exists(txt_path)
if not folder:
os.makedirs(txt_path)
# 判断是否已经存在存放识别结果的文件
save_txt_path = txt_path + '\\' + filename + '_.txt'
if os.path.exists(save_txt_path):
os.remove(save_txt_path) # 如果存在即删除文件
#长语音分割为59s语音区间
sound = AudioSegment.from_wav(path) #音频文件读取
seconds_of_file = sound.duration_seconds #音频长度
seconds_per_split_file = 59 #设定每段59s
if seconds_of_file % int(seconds_per_split_file) == 0:
times = int(seconds_of_file / int(seconds_per_split_file)) # 语音长度能被59整除
else:
times = int(seconds_of_file // int(seconds_per_split_file) + 1) # 非整除
print(f'{filename}可切割 {times} 次') #输出该语音能被切割几次
start_time = 0
internal = seconds_per_split_file * 1000
end_time = seconds_per_split_file * 1000 #语音结束时间点即59s
#各分割语音的文本所含字数列表
length_list=[]
for i in range(times):
if i + 1 == times: # 最后一次切割
part = sound[start_time:]
else:
part = sound[start_time:end_time]
data_split_filename = os.path.join('C://Users//fengsky//douyin//audios_try//' + str(i) + '_.wav') # audios_try文件夹用来临时存放分割后的语音文件
part.export(data_split_filename, format="wav") # 先导入该文件
wav_version = AudioSegment.from_wav(data_split_filename) # 再读取分割好的文件
mono = wav_version.set_frame_rate(16000).set_channels(1) # 设置声道和采样率
mono.export(data_split_filename, format='wav', codec='pcm_s16le') # 存储设置后的音频文件
text = self.speech_recognize(data_split_filename) #语音转文字
length_list.append(len(text))
with open(save_txt_path,'a') as ff: #识别的文字追加写入
ff.write(text)
ff.write('\n') #换行
print(f' {str(i)}_.wav语音转换成功,开始删除')
os.remove(data_split_filename) #删除音频文件
start_time += internal
end_time += internal
time.sleep(0.5)
#百度智能云平台语音识别api调用,首次使用免费
## api地址:https://login.bce.baidu.com/?account=&redirect=http%3A%2F%2Fconsole.bce.baidu.com%2Fai%2F%3F_%3D1624804122867%26fromai%3D1#/ai/speech/overview/index
#调用接口,实现语音识别
def speech_recognize(self,seg_filename):
#对应参数输入
APP_ID = "*******"
API_KEY = "**************"
SECRET_KEY = "**********8" #api参数
aipSpeech = AipSpeech(APP_ID, API_KEY, SECRET_KEY) #传入参数
with open(seg_filename, 'rb') as fp:
audioPcm = fp.read()
json = aipSpeech.asr(audioPcm, 'wav', 16000, {'dev_pid': 1537})
if 'success' in json['err_msg']:
context = json['result'][0] #转换成功的文本
else:
context = '=====识别失败====='
print('识别失败!')
return context
def run(self):
print(f'============{self.id}共{len(self.audio_list)}个文件==============')
for i in self.audio_list:
try:
self.speech_seg(i)
print(f'-----{i}-----分析完成')
except:
print(f'-----{i}-----分析出现问题')
pass
if __name__ == '__main__':
audio2text = audio_reg()
audio2text.run() #hanzihao618
总结
功能实现起来简单,希望能帮助到需要这方面任务的同学!

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)