

nnUNet详细笔记教程(Linux下,只有实验没有原理)
nnUNet网址:GitHub - MIC-DKFZ/nnUNet 本文使用所有nnUNet代码均来源于以上网址。一、配置虚拟环境本人使用anaconda配置虚拟环境,首先是在Linux终端打开conda。输入如下指令,打开conda,其中路径PATH是anaconda中bin文件夹的路径。另外,本人使用Linux复制路径的方法为在目标文件夹下打开终端,输入pwd回车后即可得到当前文件夹路径,直接
nnUNet网址:GitHub - MIC-DKFZ/nnUNet 本文使用所有nnUNet代码均来源于以上网址。
一、配置虚拟环境
本人使用anaconda配置虚拟环境,首先 是在Linux终端打开conda。输入如下指令,打开conda,其中路径PATH是anaconda中bin文件夹的路径。另外,本人使用Linux复制路径的方法为在目标文件夹下打开终端,输入pwd回车后即可得到当前文件夹路径,直接复制即可。
export PATH=/home/anaonda3/bin:$PATH输入以上命令,回车后,再输入如下命令,然后回车。
source activate输入完成后,终端界面如下所示。
当显示终端中显示(base)时,说明成功进入conda。
然后, 创建虚拟环境,将上图中的conda activate nnUNet替换为如下代码,其中nnUNet是虚拟环境的名字,怎么写看个人喜好。因为nnUNet要求python版本为3.9及以上,所以安装python3.9。
conda create -n nnUNet python=3.9输入命令后,回车,输入y,回车,会出现如下界面:
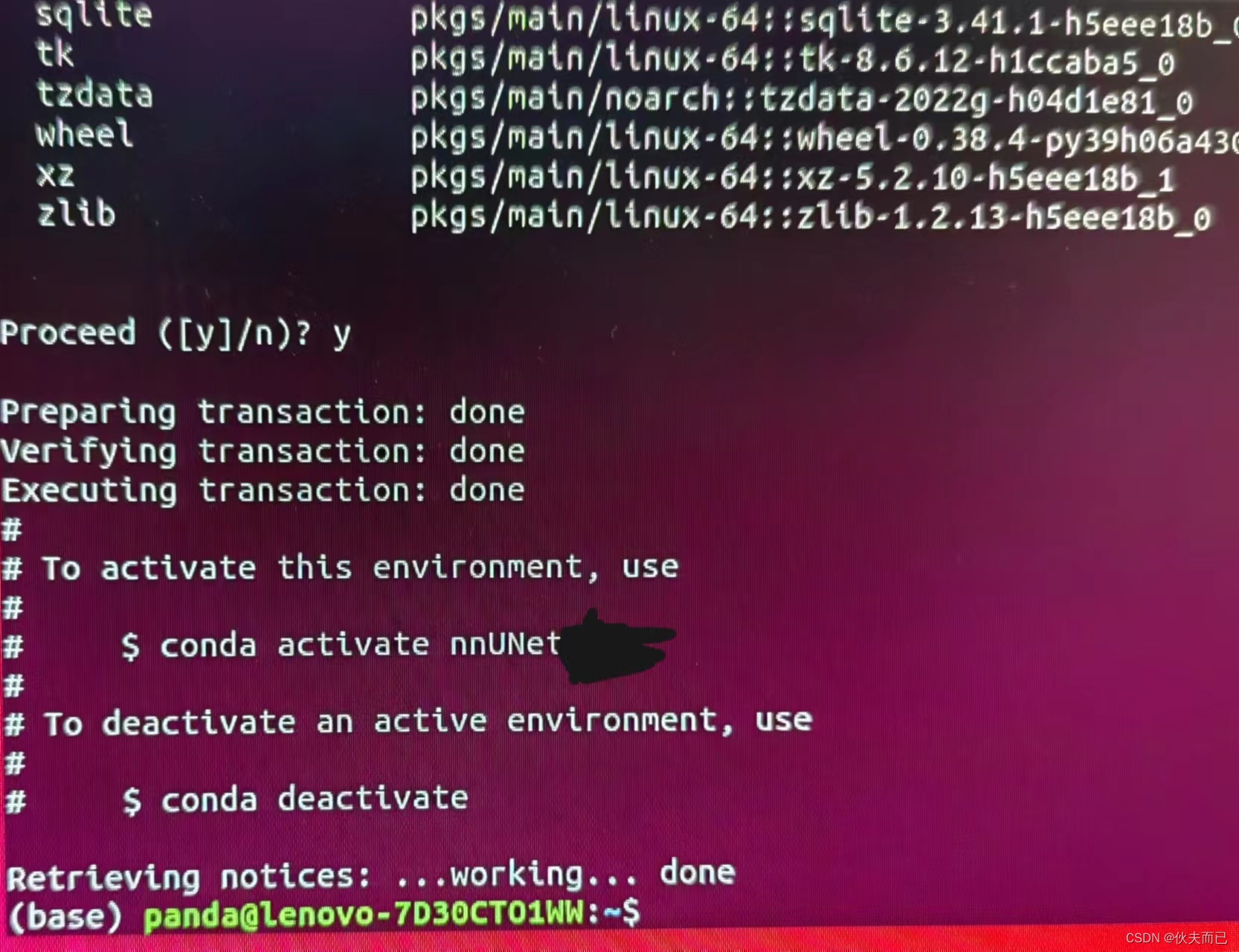 这样虚拟环境就创建好了,接着输入conda activate nnUNet,进入虚拟环境。
这样虚拟环境就创建好了,接着输入conda activate nnUNet,进入虚拟环境。

二、添加数据路径(nnUNet中的documentation/set_environment_variables.md)
因为在修改 .bashrc文件时,没有权限,所以使用另外一种添加路径方式,即Temporary。

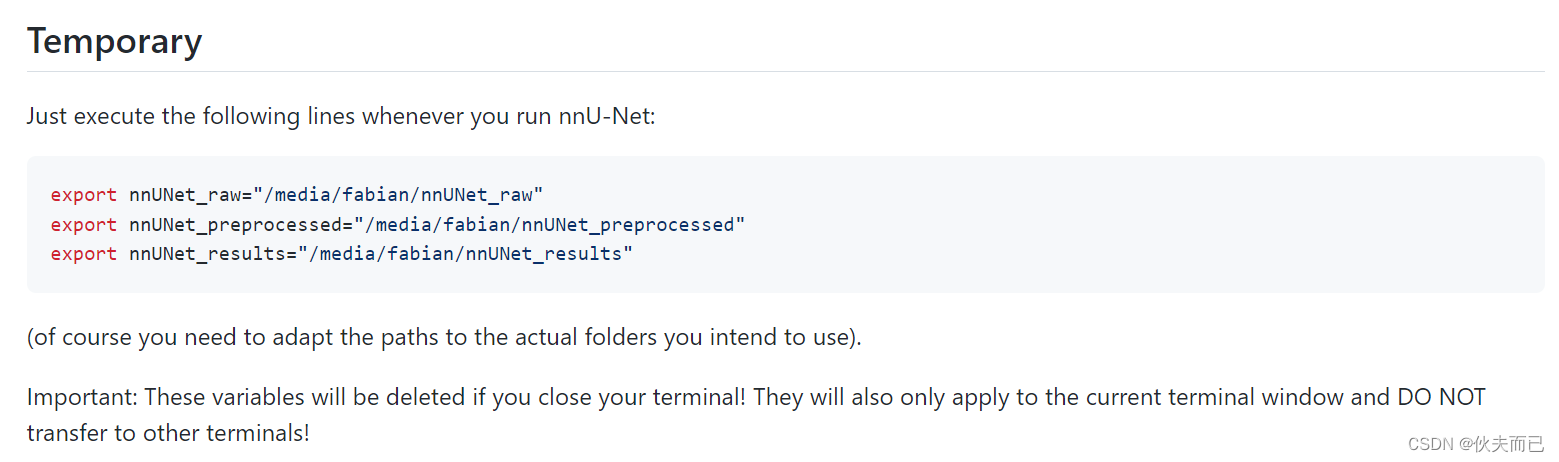
按照Temporary要求,输入如下代码,其中三个文件夹的名称必须与代码中保持一致,文件夹之间的关系如下图。
export nnUNet_raw="/media/fabian/nnUNet_raw"
export nnUNet_preprocessed="/media/fabian/nnUNet_preprocessed"
export nnUNet_results="/media/fabian/nnUNet_results"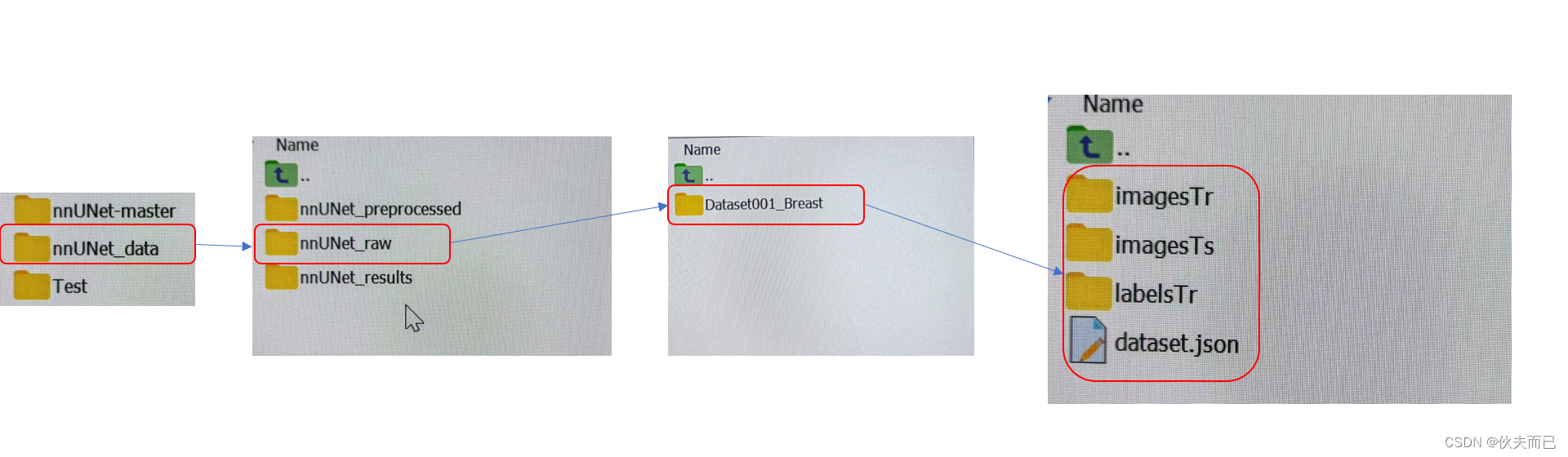
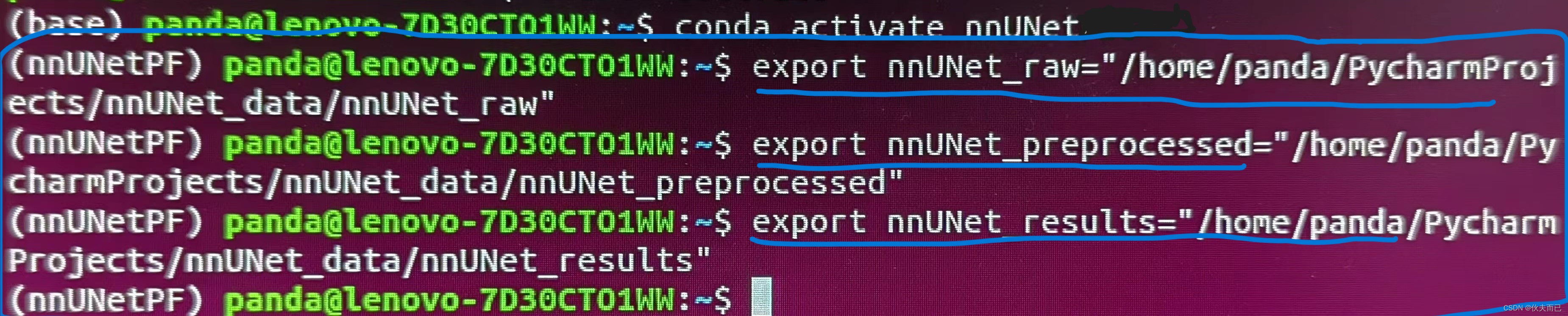
根据我自己的文件夹存放位置和关系,在终端中输入的命令如下图:
附上生成dataset.json代码:
"""
创建数据集的json
"""
import os
import json
from collections import OrderedDict
path_originalData = r"D:\Code_Python\Final_Breast_Segmentation\nnUNet_raw\Dataset001_Breast"
train_real_image = os.listdir((path_originalData+"\\imagesTr"))
train_real_label = os.listdir((path_originalData+"\\labelsTr"))
test_real_image = os.listdir((path_originalData+"\\imagesTs"))
print(train_real_image)
for idx in range(len(train_real_image)):
print({'image': "./imagesTr/%s" % train_real_image[idx],
"label": "./labelsTr/%s" % train_real_label[idx]})
# # -------下面是创建json文件的内容--------------------------
# # 可以根据你的数据集,修改里面的描述
json_dict = OrderedDict()
json_dict['name'] = "PC" # 任务名
json_dict['description'] = " Segmentation"
json_dict['tensorImageSize'] = "3D"
json_dict['reference'] = "see challenge website"
json_dict['licence'] = "see challenge website"
json_dict['release'] = "0.0"
# 这里填入模态信息,0表示只有一个模态,还可以加入“1”:“MRI”之类的描述,详情请参考官方源码给出的示例
json_dict['modality'] = {"0": "MRI"}
# 这里为label文件中的标签,名字可以按需要命名
########下面一行在参考的基础上做了修改######
json_dict['labels'] = { "Background":0, "breast":1}
# 下面部分不需要修改
json_dict['numTraining'] = len(train_real_image)
json_dict['numTest'] = len(test_real_image)
json_dict['file_ending'] = '.nii.gz'
json_dict['training'] = []
for idx in range(len(train_real_image)):
json_dict['training'].append({'image': "./imagesTr/%s" % train_real_image[idx],
"label": "./labelsTr/%s" % train_real_label[idx]})
json_dict['test'] = ["./imagesTs/%s" % i for i in test_real_image]
with open(os.path.join(path_originalData, "dataset.json"), 'w') as f:
json.dump(json_dict, f, indent=4, sort_keys=True)另外,每个数据命名格式为img_0010_0000.nii.gz,其中,img为图像名称,0010为图像序号,0000为模态名称,nii.gi为图像格式。
三、数据处理(nnUNet中的documentation/how_to_use_nnunet.md)
输入命令:
nnUNetv2_plan_and_preprocess -d DATASET_ID --verify_dataset_integrity其中DATASET_ID部分直接替换为001即可,因为我的数据集名字为Dataset001_....,其他部分不变。
输入命令回车以后会出现如下界面,等待完成即可。

四、模型训练
数据处理好之后,输入如下命令,其中DATASET_NAME_OR_ID 是数据集的名字或ID,在我的数据中为001;UNET_CONFIGURATION为使用哪种分割方法,分别有2d, 3d_fullres, 3d_lowres, 3d_cascade_lowres,我选择的是3d_fullres ;FOLD 为使用几折交叉验证,此处应注意为For FOLD in [0, 1, 2, 3, 4],也就是在0-4中选择一个,选择4的话,则为五折交叉验证。例如我输入的内容为 nnUNetv2_train 001 3d_fullres 4,也就是数据集为001,使用3d_fullres分割方法和五折交叉验证。
nnUNetv2_train DATASET_NAME_OR_ID UNET_CONFIGURATION FOLD 输入命令之后,部分界面显示如下,开始训练。

五、预测分割结果
以下是预测分割结果部分:
因为之前在训练部分输入五折交叉验证,,输入为5,输入错误(第四部分:FOLD 为使用几折交叉验证,此处应注意为For FOLD in [0, 1, 2, 3, 4],也就是在0-4中选择一个,选择4的话,则为五折交叉验证),导致输出结果是文件夹名称也为5,如下图(fold_5):
所以在预测时,输入代码为画对号的命令,而非叉号的部分,其中-i为想要分割的文件夹,-o为保存结果文件夹,-c为之前训练模型时选择的模式,-f为交叉验证折数,与上图文件夹fold_5的5相对应。
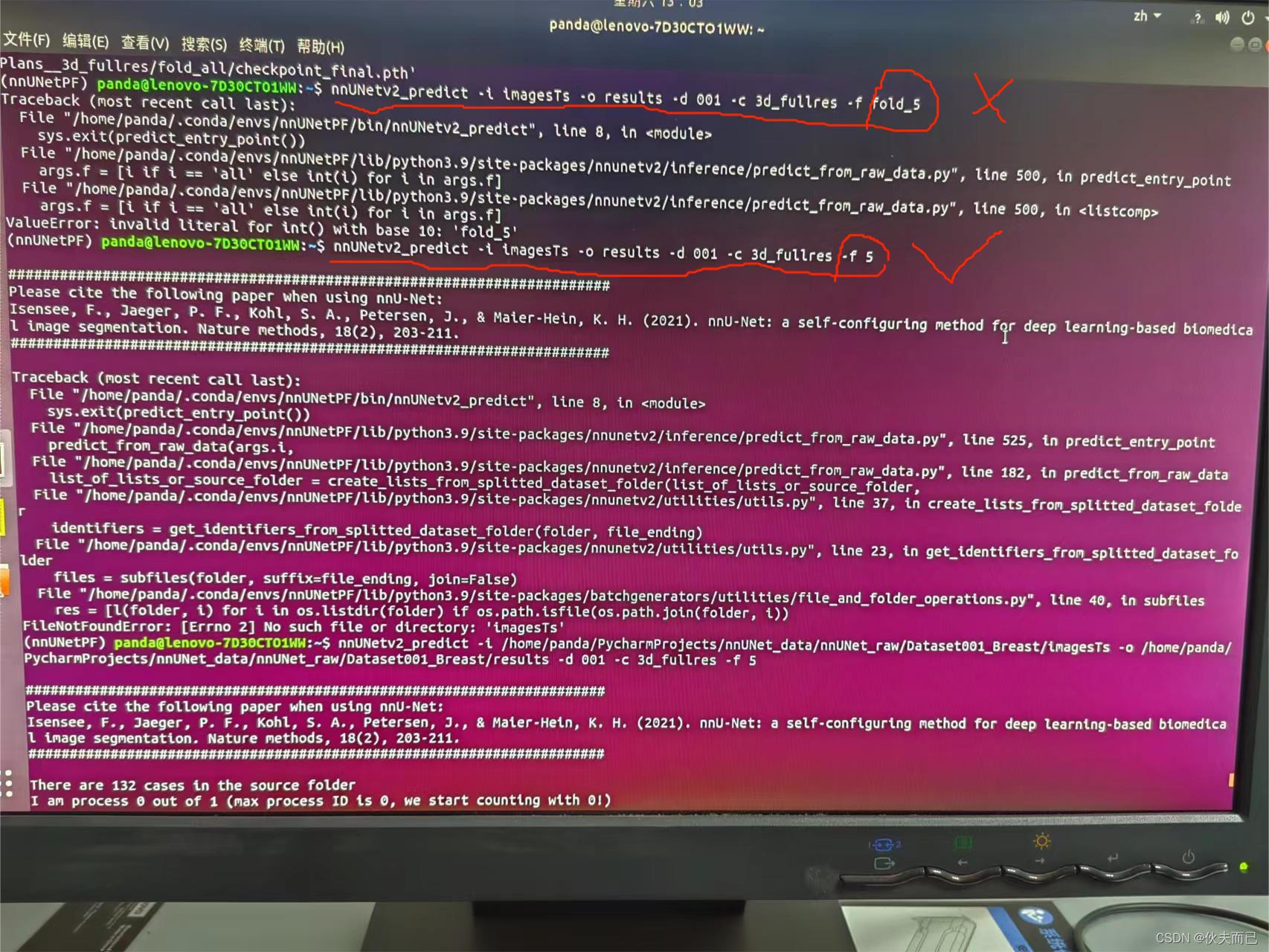
输入命令以后就等待结果就好了,这里边保存的结果为二值化的结果,想要达到分割,后续实验就是直接将二值化结果和原图做乘法就得到的最后的分割结果。
附读取及保存nii.gz格式文件代码:
import SimpleITK
path = r'image_path'##文件路径
itk_image = SimpleITK.ReadImage(path)
image_array = SimpleITK.GetArrayFromImage(itk_image)
## 将图像矩阵保存为nii.gz格式
output = SimpleITK.GetImageFromArray(image_array)
SimpleITK.WriteImage(output, 'file_name.nii.gz')
旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 3
3 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)