

深度学习|BP神经网络
讲述BP神经网络原理,并通过Python语言,分别导入numpy、sklearn和pytorch库完成编程。
一、人工神经网络
1.1 人工神经网络理论
人工神经网络(Artificial Neural Network, ANN)是由大量神经元相互连接,模拟人的大脑神经处理信息的方式,进行信息并行处理和非线性转换的复杂网络系统。从生物学角度来看,人脑中的神经细胞主要结构分为树突、细胞体和轴突,分别用于接收信息、处理信息和传出信息,如下图所示:
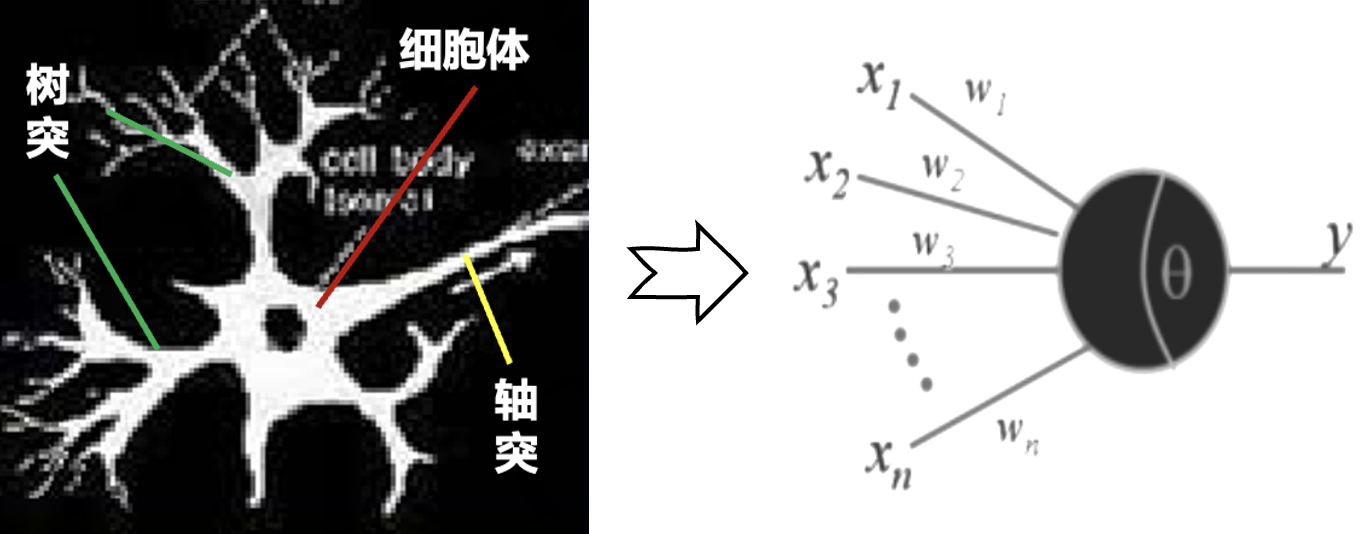
将生物神经元看成一张有向图,图中的节点就是神经元,定义神经的输入和输出为神经元左右的边。对于一个神经元,应包含信息的输入、输出渠道和当前状态及阈值,右图中x代表输入信号,w代表输入权值,θ表示阈值,y表示输出信号,则神经元内部状态u可表示为:
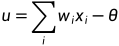
一般情况下,神经元的输出函数由f表示,通常用分段线性函数、阶跃函数、Sigmoid函数等来表示网络的非线性特征,如图所示:

一般认为,神经网络是一个高度复杂的非线性动力学系统,在模式识别、函数逼近及贷款风险评估等诸多领域有广泛的应用,能解决传统问题难以解决的问题。根据连接方式的不同,神经网络的神经元之间的连接有如下几种:
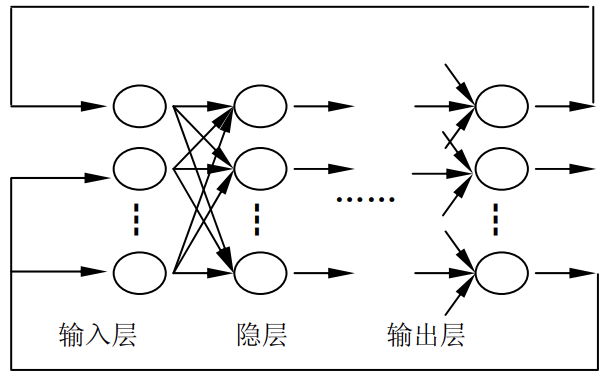
(1)前向网络
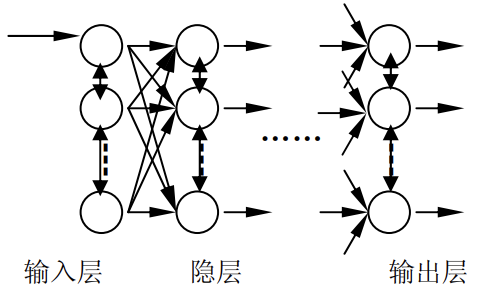
前向网络的神经元分层排列分为输入层、隐含层和输出层。每一层的神经元只接受来自前一层神经元的输入,后面的层对前面的层没有信号反馈。输入模式经过各层次的顺序传播,最后在输出层上得到输出。感知器网络和BP神经网络均属于前向网络,此类网络的结构形态如下:

(2)有反馈的前向网络
输出层对输入层有信息反馈,这种网络可用于存储某种模式序列,如神经感知机和回归BP网络都属于这种类型,此类网络的结构形态如下:
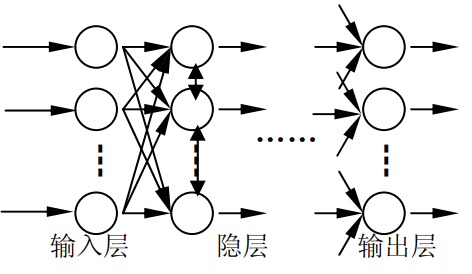
(3)层内有相互结合的前向网络
通过层内神经元的相互结合,可以实现同一层内神经元之间的横向抑制或兴奋机制,这样可以限制每层内可以同时动作的神经元素,或者把每层内的神经元分为若干组,让每一组作为一个整体进行运行,此类网络的结构形态如下:
(4)相互结合型网络
该网络又称全互联网络,这种网络在任意两个神经元之间都有可能连接。Hopfield网络和Boltzmann机均属于这种类型。在无反馈的前向网络中,信号一旦通过某神经元,该神经元的处理就结束了。而在相互结合网络中,信号要在神经元之间反复传递,网络处于一种不断改变状态的动态之中。信号从某初始状态开始,经过若干次变化才会达到某种平衡状态。根据网络的结构和神经元的特性,网络的运行还有可能进入周期震荡或其它如混沌等平衡状态。
1.2 人工神经网络学习方式
神经网络的学习也称为训练,指的是通过神经网络所在环境的刺激作用调整神经网络的参数(权值和阈值),使神经网络以一种新的方式对外部环境做出反应的过程。根据学习过程的组织方式不同,学习方式分为有监督学习和无监督学习,其中BP算法是最典型的有监督学习算法。
对于不同的神经网络结构和模型,在网络学习的过程中,有不同的学习规则,通过这些规则来调整神经元之间的连接权重,实现神经网络的学习,常见的学习规则如下:
1.2.1 Hebb规则
Donall Hebb 根据生理学中的条件反射机理于 1949 年提出神经元连接强度变化的规则。Hebb规则主要思想为如果两个神经元同时兴奋,即同时被激活,则它们之间的突触连接加强,否则被减弱。常用于自联想网络,例如 Hopfield 网络。
1.2.2 Delta规则
Delta规则根据输出节点的外部反馈来改变权系数,在方法上和梯度下降法等效,按局部改善最大的方向一步步进行优化,从而最终找到全局优化值。感知器学习就采用这种纠错学习机制,如 BP 算法。用于统计性算法的模拟退火算法也属于这种学习规则。
1.2.3 相近学习规则
相近学习规则根据神经元之间的输出决定权值的调整,如果两个神经元的输出比较相似,则连接它们的权值增,反之减小。相近学习规则多用于竞争型神经网络的学习,ART和SOFM等自组织竞争型网络均采用该学习规则。
二、BP神经网络
2.1 BP神经网络算法原理
BP神经网络的全称为Back-Propagation Network,即反向传播网络,它是一个前向多层网络,利用误差反向传播算法对网络进行训练。BP神经网络的结构由输入层、隐含层和输出层构成,结构简单、可塑性强,输入层的节点只起到缓冲器的作用,负责把网络的输入数据传递给第一隐含层,因而各节点之间没有传递函数的功能。BP神经网络的结构形态属于前向网络,如下:
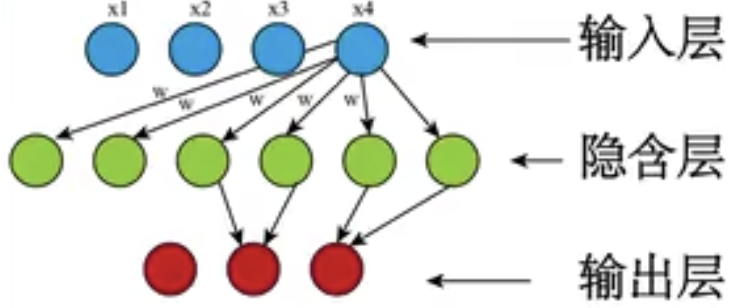
BP神经网络的上下层之间实现全连接,而每层神经元之间无连接。当一对学习样本提供给网络后,神经元的激活值从输入层经各隐含层传递至输出层。按照减少目标输出和实际输出之间误差的方向,从输出层反向经过中间层回到输入层,从而逐步修正各连接权值。与感知机不同的是由于误差反向传播中会对传递函数进行求到计算,BP神经网络的传递函数必须是可微的,所以不能使用感知机网络中的硬阈值传递函数,而通常使用的传递函数仍是上文所述的分段线性函数、阶跃函数、Sigmoid函数。
BP算法使用广义的δ规则,可以在多网络上进行有效学习,其关键是对隐含层节点的偏差δ如何定义计算。设有n个节点的任意网络,任意节点i的输出为O,并设有N个样本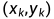 ,对某一输入
,对某一输入 网络输出为
网络输出为 ,阶点的输出为
,阶点的输出为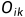 ,节点j的输入则为:
,节点j的输入则为:
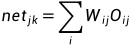
使用平方型误差函数:
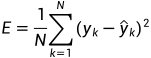
式中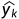 为网络的实际输出,定义如下:
为网络的实际输出,定义如下:
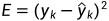
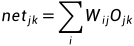
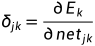
式中 ,因此:
,因此:

当j为输出节点时,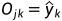 ,则:
,则:

若j不是输出节点时,有:
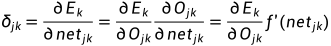

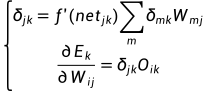
如果网络共有M层,而第M层仅含输出节点,第一层为输入节点,则 BP神经网络可以描述为:
选定初始权值W;
重复下述过程直到收敛:
(1)对k=1到N,计算、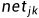 和
和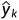 (前向传播过程),对各层从M到2方向计算
(前向传播过程),对各层从M到2方向计算 ;
;
(2)修正权值
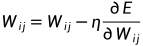
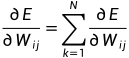
η称为学习步长,用以调整梯度下降的幅度,决定了网络学习的稳定性和训练的速度。此处算法采用批量模式,用全局误差对网络权值进行调整。
2.2 BP神经网络优缺点
2.2.1 BP神经网络优点
网络由很多微处理单元连接而成,每个单元功能简单,但集成后的整体功能强大,处理速度较快;
具有较强容错性,局部神经元损坏后,不会对全局造成太大影响;
网络记忆的信息存储于神经元之间的连接权值上,是分布式存储方式;
学习功能强大,连接权值和连接结构可通过学习得到。
2.2.2 BP神经网络缺点
网络学习和记忆不稳定,增加样本时需要重新训练;
隐含层层数和每层神经元个数需根据经验值或反复试算确定;
网络收敛较慢,对于复杂问题训练时间较长,可通过变化学习速率或自适应学习速率加以改进;
网络可以使权值收敛到一定的值,但难以保证其为误差平面的全局最小值,因为梯度下降法可能产生一个局部最小值,可采用附加动量法解决此问题。
三、使用Python实现BP神经网络
以下通过两个案例,说明如何使用Python实现BP神经网络的编程。
3.1 XOR异或运算
逻辑运算之中,除了AND和OR,还有一种XOR运算,中文称为“异或运算”。它的定义是:两个值相同时,返回false,否则返回true。也就是说,XOR可以用来判断两个值是否不同。例如有列表a,想对其中的元素进行异或判断:
a = [[0, 0], [0, 1], [1, 1], [1, 0]]Python中提供了异或运算符号“^”,可直接得出运算结果:
b = []
for item in a:
b.append(item[0]^item[1])
print(b)
## 输出结果:
[0, 1, 0, 1]如果不借用“^”运算符,我们希望构建一个具有两层隐含层的人工神经网络对此运算过程进行学习,达到异或运算的目的。按照构建BP神经网络的逻辑,主要步骤分为:
(1)导入工具包:
import numpy as np为说明构建原理,此处只调用numpy包
(2)初始化神经网络权重:
class NeuralNetwork:
def __init__(self, input_size, hidden_size, output_size):
self.weights1 = np.random.randn(input_size, hidden_size) ## 输入层与隐含层的权重
self.weights2 = np.random.randn(hidden_size, hidden_size) ## 隐含层与隐含层的权重
self.weights3 = np.random.randn(hidden_size, output_size) ## 隐含层与输入层的权重(3)定义激活函数和激活函数的导数
def sigmoid(self, x):
# 定义sigmoid激活函数
return 1 / (1 + np.exp(-x))
def sigmoid_derivative(self, x):
# 定义sigmoid激活函数的导数
return x * (1 - x)通常使用sigmoid函数,当然也可根据需要选择线性函数或阶跃函数。
(4)定义前向传播和后向传递
def feedforward(self, X):
# 前向传播计算输出值
self.layer1 = self.sigmoid(np.dot(X, self.weights1))
self.layer2 = self.sigmoid(np.dot(self.layer1, self.weights2))
self.output = self.sigmoid(np.dot(self.layer2, self.weights3))
return self.output
def backpropagation(self, X, y, learning_rate):
# 计算输出误差
output_error = y - self.output
output_delta = output_error * self.sigmoid_derivative(self.output)
# 计算隐藏层2误差
layer2_error = output_delta.dot(self.weights3.T)
layer2_delta = layer2_error * self.sigmoid_derivative(self.layer2)
# 计算隐藏层1误差
layer1_error = layer2_delta.dot(self.weights2.T)
layer1_delta = layer1_error * self.sigmoid_derivative(self.layer1)
# 更新权重
self.weights1 += X.T.dot(layer1_delta) * learning_rate
self.weights2 += self.layer1.T.dot(layer2_delta) * learning_rate
self.weights3 += self.layer2.T.dot(output_delta) * learning_rate(5)训练与预测
def train(self, X, y, epochs, learning_rate):
for i in range(epochs):
output = self.feedforward(X)
self.backpropagation(X, y, learning_rate)
def predict(self, X):
return self.feedforward(X)(6)完整代码
import numpy as np
class NeuralNetwork:
def __init__(self, input_size, hidden_size, output_size):
# 初始化神经网络的权重
self.weights1 = np.random.randn(input_size, hidden_size)
self.weights2 = np.random.randn(hidden_size, hidden_size)
self.weights3 = np.random.randn(hidden_size, output_size)
def sigmoid(self, x):
# 定义sigmoid激活函数
return 1 / (1 + np.exp(-x))
def sigmoid_derivative(self, x):
# 定义sigmoid激活函数的导数
return x * (1 - x)
def feedforward(self, X):
# 前向传播计算输出值
self.layer1 = self.sigmoid(np.dot(X, self.weights1))
self.layer2 = self.sigmoid(np.dot(self.layer1, self.weights2))
self.output = self.sigmoid(np.dot(self.layer2, self.weights3))
return self.output
def backpropagation(self, X, y, learning_rate):
# 计算输出误差
output_error = y - self.output
output_delta = output_error * self.sigmoid_derivative(self.output)
# 计算隐藏层2误差
layer2_error = output_delta.dot(self.weights3.T)
layer2_delta = layer2_error * self.sigmoid_derivative(self.layer2)
# 计算隐藏层1误差
layer1_error = layer2_delta.dot(self.weights2.T)
layer1_delta = layer1_error * self.sigmoid_derivative(self.layer1)
# 更新权重
self.weights1 += X.T.dot(layer1_delta) * learning_rate
self.weights2 += self.layer1.T.dot(layer2_delta) * learning_rate
self.weights3 += self.layer2.T.dot(output_delta) * learning_rate
def train(self, X, y, epochs, learning_rate):
for i in range(epochs):
output = self.feedforward(X)
self.backpropagation(X, y, learning_rate)
def predict(self, X):
return self.feedforward(X)
# 创建神经网络对象
nn = NeuralNetwork(2, 5, 1)
# 训练神经网络
X = np.array([[0, 0], [0, 1], [1, 0], [1, 1]])
y = np.array([[0], [1], [1], [0]])
nn.train(X, y, 10000, 0.1)
# 使用神经网络进行预测
print(nn.predict(np.array([[0, 0], [1, 1], [1, 1], [0, 1]])))输出结果为:
[[0.02377718]
[0.03460649]
[0.03460649]
[0.96909858]]预测结果接近于[0, 0, 0, 1],与实际情况相吻合,说明模型训练有效并能成功实现预测。
3.2 油价预测案例
假设某地市场连续20个周期的油价(元/升)如下:7.82、7.89、7.46、8.23、7.99、7.97、7.78、7.66、7.97、8.01、8.10、8.15、8.16、8.02、7.87、7.89、8.03、8.04、8.28、8.34。我们期望建立一个具有可行性的油价预测模型,以上数据共20项,我们可以将前10项作为输入数据,后10项作为输出数据训练一个神经网络,假设只建立一层隐含层,则可构建如下程序:
3.2.1 使用numpy库
import numpy as np
# 定义sigmoid函数和其导数
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def sigmoid_derivative(x):
return x * (1 - x)
# 定义神经网络类
class NeuralNetwork:
def __init__(self, input_size, hidden_size, output_size):
self.input_size = input_size
self.hidden_size = hidden_size
self.output_size = output_size
# 初始化权重矩阵
self.weights1 = np.random.randn(self.input_size, self.hidden_size)
self.weights2 = np.random.randn(self.hidden_size, self.output_size)
def forward(self, X):
# 前向传播
self.hidden_layer = sigmoid(np.dot(X, self.weights1))
self.output_layer = sigmoid(np.dot(self.hidden_layer, self.weights2))
return self.output_layer
def backward(self, X, y, output):
# 反向传播
output_error = y - output
output_delta = output_error * sigmoid_derivative(output)
hidden_error = output_delta.dot(self.weights2.T)
hidden_delta = hidden_error * sigmoid_derivative(self.hidden_layer)
# 更新权重矩阵
self.weights2 += self.hidden_layer.T.dot(output_delta)
self.weights1 += X.T.dot(hidden_delta)
def train(self, X, y, epochs):
for i in range(epochs):
output = self.forward(X)
self.backward(X, y, output)
# 定义训练函数和预测函数
def train(X, y, input_size, hidden_size, output_size, epochs):
nn = NeuralNetwork(input_size, hidden_size, output_size)
nn.train(X, y, epochs)
return nn
def predict(X, model):
return model.forward(X)
# 输入和输出数据
X = np.array([[7.82], [7.89], [7.46], [8.23], [7.99], [7.97], [7.78], [7.66], [7.97], [8.01]])
y = np.array([[8.10], [8.15], [8.16], [8.02], [7.87], [7.89], [8.03], [8.04], [8.28], [8.34]])
# 标准化输入和输出数据
X_norm = (X - X.mean()) / X.std()
y_norm = (y - y.min()) / (y.max() - y.min())
# 训练神经网络模型
model = train(X_norm, y_norm, input_size=1, hidden_size=100, output_size=1, epochs=10000)模型训练完成后,即可输入目前的油价值以预测未来周期的油价,如下:
# 预测结果并反归一化
X_new = np.array([[7.75], [7.33], [7.65], [8.34], [8.23]])
y_new_norm = predict((X_new - X.mean()) / X.std(), model)
y_new = y_new_norm * (y.max() - y.min()) + y.min()
print(y_new)
# 输出结果
[[8.25072217]
[8.33999685]
[8.31532709]
[7.87717202]
[8.00565704]]最后得到的结果即为未来五个周期的油价,分别为8.25、8.34、8.32、7.88、8.01。
3.2.2 使用sklearn库
sklearn,全称scikit-learn,是python中的机器学习库,建立在numpy、scipy、matplotlib等数据科学包的基础之上,涵盖了机器学习中的样例数据、数据预处理、模型验证、特征选择、分类、回归、聚类、降维等几乎所有环节,功能十分强大。深度学习库中存在pytorch、Tensorflow等众多选择,而sklearn是python中传统机器学习的首选库,并不存在其他的竞争者。
import numpy as np
from sklearn.neural_network import MLPRegressor
# 输入和输出数据
X = np.array([[7.82], [7.89], [7.46], [8.23], [7.99], [7.97], [7.78], [7.66], [7.97], [8.01]])
y = np.array([[8.10], [8.15], [8.16], [8.02], [7.87], [7.89], [8.03], [8.04], [8.28], [8.34]])
# 标准化输入和输出数据
X_norm = (X - X.mean()) / X.std()
y_norm = (y - y.min()) / (y.max() - y.min())
# 构建BP神经网络模型
model = MLPRegressor(hidden_layer_sizes=(100,), activation='relu', solver='adam', max_iter=1000, random_state=1)
# 训练模型
model.fit(X_norm, y_norm)同样在模型训练完成后,输入指定值后可得到预测值:
# 预测结果
X_new = np.array([[7.75], [7.33], [7.65], [8.34], [8.23]])
y_new_norm = model.predict((X_new - X.mean()) / X.std())
y_new = y_new_norm * (y.max() - y.min()) + y.min()
print(y_new)
# 输出结果
[[8.25072217]
[8.33999685]
[8.31532709]
[7.87717202]
[8.00565704]]可以看到使用sklearn库得到的结果与numpy库相同,说明其底层结构仍然建立在numpy上,方便起见,可使用sklearn库简化代码进行编程。
3.2.3 使用pytorch库
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
# 构建神经网络
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(1, 10)
self.fc2 = nn.Linear(10, 1)
def forward(self, x):
x = torch.sigmoid(self.fc1(x))
x = self.fc2(x)
return x
# 准备数据
x_train = np.array([[7.82], [7.89], [7.46], [8.23], [7.99], [7.97], [7.78], [7.66], [7.97], [8.01]])
y_train = np.array([[8.10], [8.15], [8.16], [8.02], [7.87], [7.89], [8.03], [8.04], [8.28], [8.34]])
# 转换为tensor类型
x_train = torch.from_numpy(x_train).float()
y_train = torch.from_numpy(y_train).float()
# 初始化神经网络
net = Net()
# 定义损失函数和优化器
criterion = nn.MSELoss()
optimizer = optim.SGD(net.parameters(), lr=0.1)
# 训练神经网络
for epoch in range(1000):
optimizer.zero_grad()
outputs = net(x_train)
loss = criterion(outputs, y_train)
loss.backward()
optimizer.step()
if (epoch+1) % 100 == 0:
print('Epoch [{}/{}], Loss: {:.4f}'.format(epoch+1, 1000, loss.item()))该网络同样使用一个输入节点和一个输出节点,中间含有一层10个节点的隐藏层。训练过程中使用均方误差(MSE)作为损失函数,使用随机梯度下降(SGD)作为优化器。经过1000次迭代,训练出的模型可以用来预测新的数据,如下:
# 预测并输出结果
x_test = np.array([[7.75], [7.33], [7.65], [8.34], [8.23]])
x_test = torch.from_numpy(x_test).float()
predicted = net(x_test).detach().numpy()
print('Predicted values:', predicted)
# 输出结果
Epoch [100/1000], Loss: 0.0207
Epoch [200/1000], Loss: 0.0207
Epoch [300/1000], Loss: 0.0207
Epoch [400/1000], Loss: 0.0207
Epoch [500/1000], Loss: 0.0207
Epoch [600/1000], Loss: 0.0207
Epoch [700/1000], Loss: 0.0207
Epoch [800/1000], Loss: 0.0207
Epoch [900/1000], Loss: 0.0207
Epoch [1000/1000], Loss: 0.0207
Predicted values:
[[8.086877]
[8.081727]
[8.085794]
[8.091827]
[8.091065]]由于底层逻辑不同,深度学习库的pytoch得到的预测结果和传统机器学习得到的预测结果不同,在实际预测时,可根据具体要求决定采用哪种库。

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐


 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)