
Spark高手之路1—Spark简介
Spark官网Spark 是一种基于内存的快速、通用、可扩展的大数据分析计算引擎,相对于 Hadoop MapReduce 将中间结果保存在磁盘中, Spark 使用了内存保存中间结果, 能在数据尚未写入硬盘时在内存中进行运算.Spark 只是一个计算框架, 不像 Hadoop 一样包含了分布式文件系统和完备的调度系统, 如果要使用 Spark, 需要搭载其它的文件系统和更成熟的调度系统。
文章目录
Spark 概述
1. Spark 是什么


Spark 是一种基于内存的快速、通用、可扩展的大数据分析计算引擎,相对于 Hadoop MapReduce 将中间结果保存在磁盘中, Spark 使用了内存保存中间结果, 能在数据尚未写入硬盘时在内存中进行运算.
Spark 只是一个计算框架, 不像 Hadoop 一样包含了分布式文件系统和完备的调度系统, 如果要使用 Spark, 需要搭载其它的文件系统和更成熟的调度系统
2. Spark与Hadoop比较
在之前的学习中,Hadoop 的 MapReduce 是大家广为熟知的计算框架,那为什么咱们还要学习新的计算框架 Spark 呢,这里就不得不提到 Spark 和 Hadoop 的关系。
2.1 从时间节点上来看
➢ Hadoop
⚫ 2006 年 1 月,Doug Cutting 加入 Yahoo,领导 Hadoop 的开发
⚫ 2008 年 1 月,Hadoop 成为 Apache 顶级项目
⚫ 2011 年 1.0 正式发布
⚫ 2012 年 3 月稳定版发布
⚫ 2013 年 10 月发布 2.X (Yarn)版本
⚫ 2014-2017:Spark成为Apache顶级项目Hadoop3.0.0版本发布。
➢ Spark
⚫ 2009 年,Spark 诞生于伯克利大学的 AMPLab 实验室
⚫ 2010 年,伯克利大学正式开源了 Spark 项目
⚫ 2013 年 6 月,Spark 成为了 Apache 基金会下的项目
⚫ 2014 年 2 月,Spark 以飞快的速度成为了 Apache 的顶级项目
⚫ 2014 年 11 月, Spark的母公司Databricks团队使用Spark刷新数据排序世界记录
⚫ 2015 年至今,Spark 变得愈发火爆,大量的国内公司开始重点部署或者使用 Spark
2.2 从功能上来看
➢ Hadoop
⚫ Hadoop 是由 java 语言编写的,在分布式服务器集群上存储海量数据并运行分布式分析应用的开源框架
⚫ 作为 Hadoop 分布式文件系统,HDFS 处于 Hadoop 生态圈的最下层,存储着所有的 数 据 , 支 持 着 Hadoop 的 所 有 服 务 。 它 的 理 论 基 础 源 于 Google 的TheGoogleFileSystem 这篇论文,它是 GFS 的开源实现。
⚫ MapReduce 是一种编程模型,Hadoop 根据 Google 的 MapReduce 论文将其实现,作为 Hadoop 的分布式计算模型,是 Hadoop 的核心。基于这个框架,分布式并行程序的编写变得异常简单。综合了 HDFS 的分布式存储和 MapReduce 的分布式计算,Hadoop 在处理海量数据时,性能横向扩展变得非常容易。
⚫ HBase 是对 Google 的 Bigtable 的开源实现,但又和 Bigtable 存在许多不同之处。HBase 是一个基于 HDFS 的分布式数据库,擅长实时地随机读/写超大规模数据集。它也是 Hadoop 非常重要的组件。
➢ Spark
⚫ Spark 是一种由 Scala 语言开发的快速、通用、可扩展的大数据分析引擎
⚫ Spark Core 中提供了 Spark 最基础与最核心的功能
⚫ Spark SQL 是 Spark 用来操作结构化数据的组件。通过 Spark SQL,用户可以使用SQL 或者 Apache Hive 版本的 SQL 方言(HQL)来查询数据。
⚫ Spark Streaming 是 Spark 平台上针对实时数据进行流式计算的组件,提供了丰富的处理数据流的 API。
Spark 和 Hadoop 的异同
| Hadoop | Spark | |
|---|---|---|
| 类型 | 基础平台, 包含计算, 存储, 调度 | 分布式计算工具 |
| 场景 | 大规模数据集上的批处理 | 迭代计算,交互式计算,流计算 |
| 延迟 | 大 | 小 |
| 易用性 | API较为底层,算法适应性差 | API较为顶层,方便使用 |
| 价格 | 对机器要求低,便宜 | 对内存有要求,相对较贵 |
由上面的信息可以获知,Spark 出现的时间相对较晚,并且主要功能主要是用于数据计算,所以其实 Spark 一直被认为是 Hadoop 框架的升级版。
3. Spark Or Hadoop
Hadoop 的 MR 框架和 Spark 框架都是数据处理框架,那么我们在使用时如何选择呢?
⚫ Hadoop MapReduce 由于其设计初衷并不是为了满足循环迭代式数据流处理,因此在多并行运行的数据可复用场景(如:机器学习、图挖掘算法、交互式数据挖掘算法)中存在诸多计算效率等问题。认识到这个问题后, 学术界的 AMPLab 提出了一个新的模型, 叫做 RDDs。RDDs 是一个可以容错且并行的数据结构, 它可以让用户显式的将中间结果数据集保存在内中, 并且通过控制数据集的分区来达到数据存放处理最优化。同时 RDDs 也提供了丰富的 API 来操作数据集。后来 RDDs 被 AMPLab 在一个叫做 Spark 的框架中提供并开源。Spark 就是在传统的 MapReduce 计算框架的基础上,利用其计算过程的优化,从而大大加快了数据分析、挖掘的运行和读写速度,并将计算单元缩小到更适合并行计算和重复使用的 RDD 计算模型。
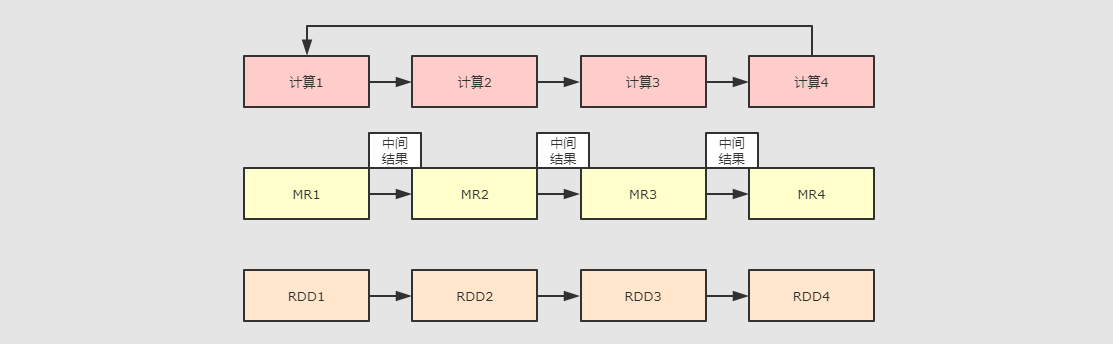
⚫ 机器学习中 ALS、凸优化梯度下降等。这些都需要基于数据集或者数据集的衍生数据反复查询反复操作。MR 这种模式不太合适,即使多 MR 串行处理,性能和时间也是一个问题。数据的共享依赖于磁盘。另外一种是交互式数据挖掘,MR 显然不擅长。而Spark 所基于的 scala 语言恰恰擅长函数的处理。
⚫ Spark 是一个分布式数据快速分析项目。它的核心技术是弹性分布式数据集(Resilient Distributed Datasets),提供了比 MapReduce 丰富的模型,可以快速在内存中对数据集进行多次迭代,来支持复杂的数据挖掘算法和图形计算算法。
⚫ Spark 和Hadoop 的根本差异是多个作业之间的数据通信问题 : Spark 多个作业之间数据通信是基于内存,而 Hadoop 是基于磁盘。
⚫ Spark Task 的启动时间快。Spark 采用 fork 线程的方式,而 Hadoop 采用创建新的进程的方式。
⚫ Spark 只有在 shuffle 的时候将数据写入磁盘,而 Hadoop 中多个 MR 作业之间的数据交互都要依赖于磁盘交互
⚫ Spark 的缓存机制比 HDFS 的缓存机制高效。
经过上面的比较,我们可以看出在绝大多数的数据计算场景中,Spark 确实会比 MapReduce更有优势。但是 Spark 是基于内存的,所以在实际的生产环境中,由于内存的限制,可能会由于内存资源不够导致 Job 执行失败,此时,MapReduce 其实是一个更好的选择,所以 Spark 并不能完全替代 MR。
4. Spark
4.1 速度快
- Spark 的在内存时的运行速度是 Hadoop MapReduce 的100倍
- 基于硬盘的运算速度大概是 Hadoop MapReduce 的10倍
- Spark 实现了一种叫做 RDDs 的 DAG 执行引擎, 其数据缓存在内存中可以进行迭代处理
4.2 易用
- Spark 支持 Java, Scala, Python, R, SQL 等多种语言的API.
- Spark 支持超过80个高级运算符使得用户非常轻易的构建并行计算程序
- Spark 可以使用基于 Scala, Python, R, SQL的 Shell 交互式查询.
4.3 通用
- Spark 提供一个完整的技术栈, 包括 SQL执行, Dataset命令式API, 机器学习库MLlib, 图计算框架GraphX, 流计算SparkStreaming
- 用户可以在同一个应用中同时使用这些工具, 这一点是划时代的
4.4 兼容
- Spark 可以运行在 Hadoop Yarn, Apache Mesos, Kubernets, Spark Standalone等集群中
- Spark 可以访问 HBase, HDFS, Hive, Cassandra 在内的多种数据库
5. Spark 核心模块

5.1 Spark-Core 和 弹性分布式数据集(RDDs)
- Spark 最核心的功能是 RDDs, RDDs 存在于 Spark-core 这个包内,,Spark 其他的功能如:Spark SQL,Spark Streaming,GraphX, MLlib 都是在 Spark Core 的基础上进行扩展的
- Spark-Core 是整个 Spark 的基础, 提供了分布式任务调度和基本的 I/O 功能
- Spark 的基础的程序抽象是弹性分布式数据集(RDDs), 是一个可以并行操作, 有容错的数据集合
- RDDs 可以通过引用外部存储系统的数据集创建(如HDFS, HBase), 或者通过现有的 RDDs 转换得到
- RDDs 抽象提供了 Java, Scala, Python 等语言的API
- RDDs 简化了编程复杂性, 操作 RDDs 类似通过 Scala 或者 Java8 的Streaming 操作本地数据集合
5.2 Spark SQL
- Spark SQL 是 Spark 用来操作结构化数据的组件。通过 Spark SQL,用户可以使用 SQL或者 Apache Hive 版本的 SQL 方言(HQL)来查询数据。
- Spark SQL 在 spark-core 基础之上带出了一个名为 DataSet 和 DataFrame 的数据抽象化的概念
- Spark SQL 提供了在 Dataset 和 DataFrame 之上执行 SQL 的能力
- Spark SQL 提供了 DSL, 可以通过 Scala, Java, Python 等语言操作 DataSet 和 DataFrame
- 它还支持使用 JDBC/ODBC 服务器操作 SQL 语言
5.3 Spark Streaming
- Spark Streaming 是 Spark 平台上针对实时数据进行流式计算的组件,提供了丰富的处理数据流的 API。
- Spark Streaming 充分利用 spark-core 的快速调度能力来运行流分析
- 它截取小批量的数据并可以对之运行 RDD Transformation
- 它提供了在同一个程序中同时使用流分析和批量分析的能力
5.4 Spark MLlib
- MLlib 是 Spark 提供的一个机器学习算法库。MLlib 不仅提供了模型评估、数据导入等额外的功能,还提供了一些更底层的机器学习原语。
- MLlib 是 Spark 上分布式机器学习的框架. Spark分布式内存的架构 比 Hadoop磁盘式 的 Apache Mahout 快上 10 倍, 扩展性也非常优良
- MLlib 可以使用许多常见的机器学习和统计算法, 简化大规模机器学习
- 汇总统计, 相关性, 分层抽样, 假设检定, 随即数据生成
- 支持向量机, 回归, 线性回归, 逻辑回归, 决策树, 朴素贝叶斯
- 协同过滤, ALS
- K-means
- SVD奇异值分解, PCA主成分分析
- TF-IDF, Word2Vec, StandardScaler
- SGD随机梯度下降, L-BFGS
5.5 Spark GraphX
- GraphX 是 Spark 面向图计算提供的框架与算法库。
- GraphX 是分布式图计算框架, 提供了一组可以表达图计算的 API, GraphX 还对这种抽象化提供了优化运行

鲲鹏展翅 立根铸魂 深耕行业数字化
更多推荐
 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)