
Linux 中 Makefile 的简单使用
简要的写一下Linux中的Makefile的使用,然后用Makefile文件来编译一个小型的自己写的 FTP server。当make命令执行的时候,需要一个makefile文件,来告诉make命令该怎么去编译和链接程序,注意,make并不真正的去进行编译,它只是调用执行gcc这种编译命令而已。Makefile 可以简单的认为是一个工程文件的编译规则,描述了整个工程的编译和链接等规则。其中包含了那
前言:
简要的写一下Linux中的Makefile的使用,然后用Makefile文件来编译一个小型的自己写的 FTP server。
一、编译、链接、静态链接库
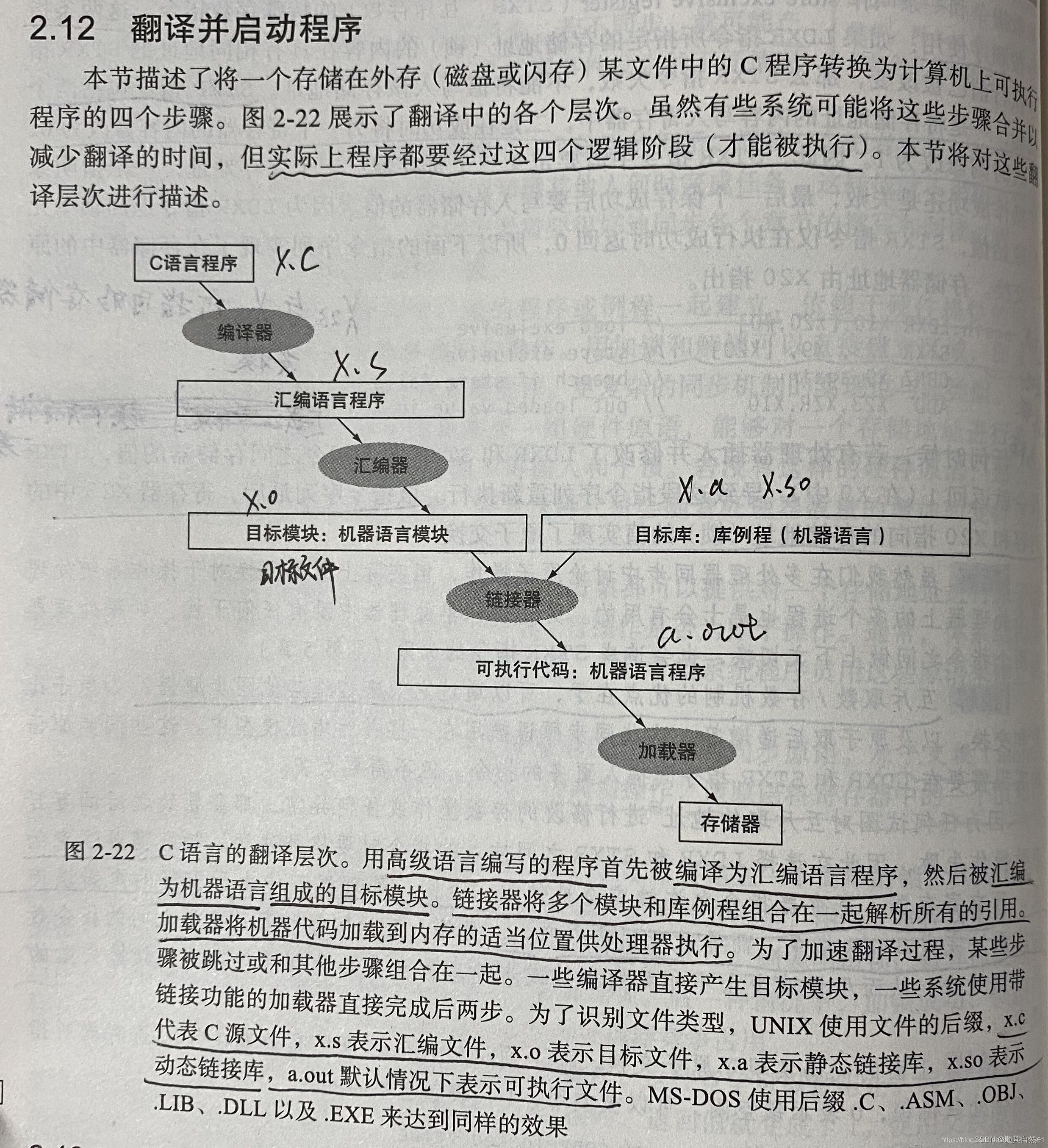
对于这个,如果要理解makefile,我想,一定要先理解一下什么是编译,什么是链接,什么是静态链接库。我贴一个图叭,如下:
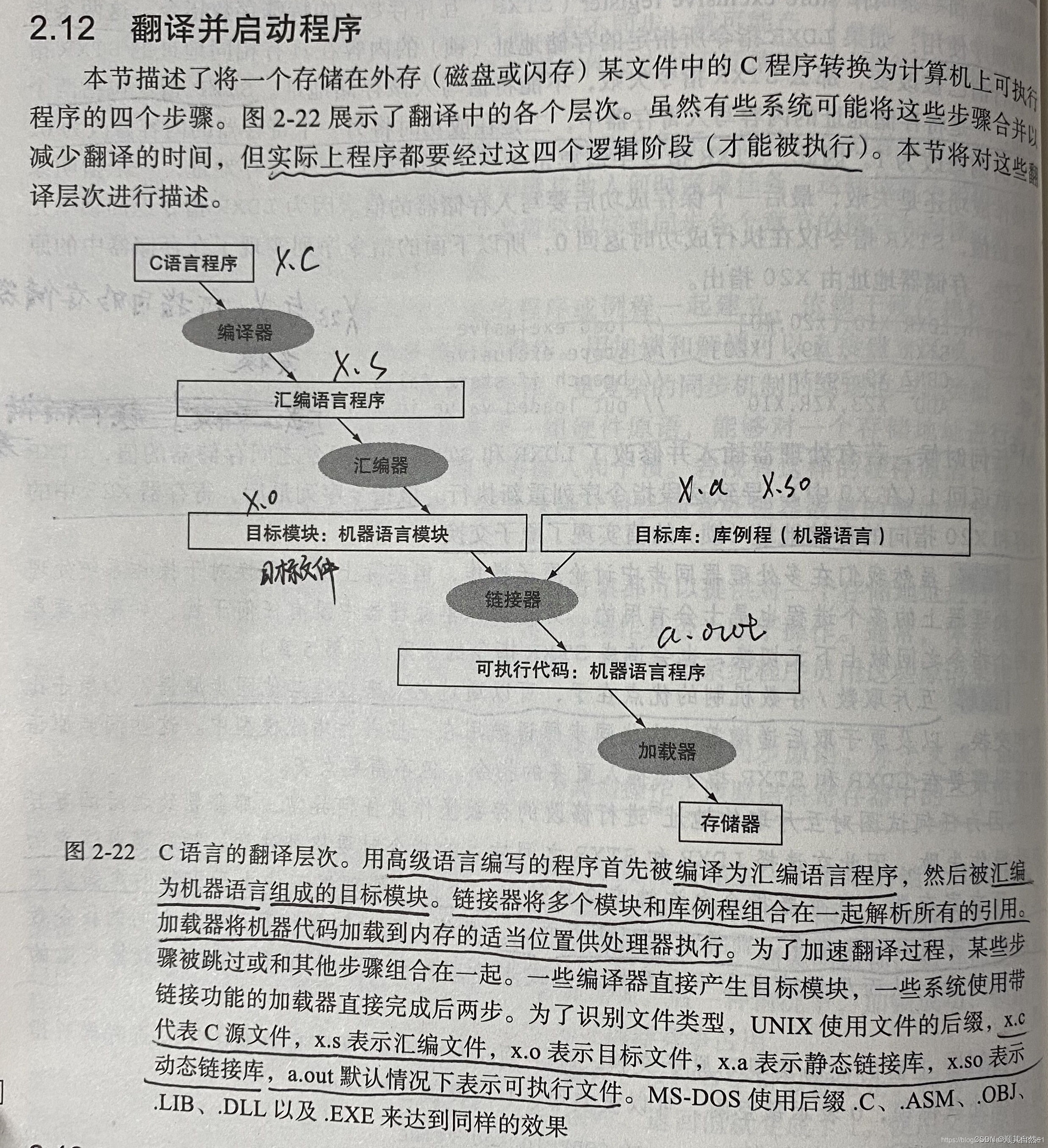
编译器负责将C语言的源文件转换成机器所能理解的符号形式的汇编语言程序。汇编器将汇编语言程序转换成目标文件,该文件包括机器语言指令、数据,以及将指令正确放入内存所需要的信息。链接器也称为链接编辑器,是一个系统程序,把各个独立汇编的机器语言程序组合起来并且解决所有未定义的标签,最后生成了可执行文件(可以在计算机上直接运行)。可执行文件,一个具有目标文件格式的功能程序,不包含未解决的引用。
在链接过程中,如果我们链接的目标文件过多,那么挨个指出目标文件名称,就很不方便,所以,给这些目标文件打个包,在Windows下这种包叫“库文件”(Library File),也就是 .lib 文件,在UNIX下,是Archive File,也就是 .a 文件。链接过程中将从静态库中恢复这些目标文件,并把他们和已经汇编好的其他目标文件一起链接,来生成可执行文件,这个过程称为" 静态链接 "。
二、gcc的简单使用
gcc (option) (file)
1、选项部分
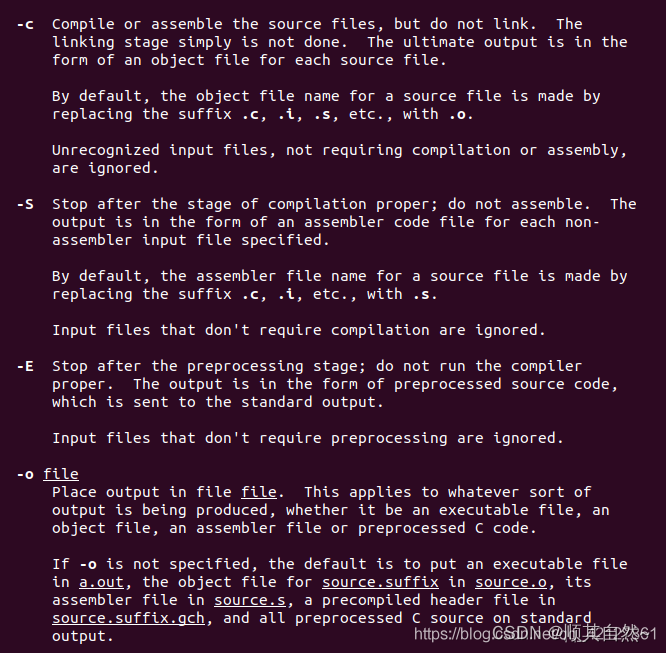
-c 编译或汇编源文件,生成目标文件 *.o
-S 编译完成后,生成汇编文件,汇编器不进行汇编操作 *.s
-E 预编译阶段完成后就结束 *.i
-o 将最后的output放到指定文件中,默认为a.out ,这里其实就是可执行文件的意思了
gcc 可以编译单个文件,也可以编译多个文件,如下:

ftp.h 内容如下:
#include<stdio.h>
int t();
main.c 内容如下:
#include "ftp.h"
int main(){
t();
return 0;
}
common.c 内容如下:
#include "ftp.h"
int t(){
printf("hello this is common.c");
return 0;
}
三、makefile简介
当make命令执行的时候,需要一个makefile文件,来告诉make命令该怎么去编译和链接程序,注意,make并不真正的去进行编译,它只是调用执行gcc这种编译命令而已。
Makefile 可以简单的认为是一个工程文件的编译规则,描述了整个工程的编译和链接等规则。其中包含了那些文件需要编译,那些文件不需要编译,那些文件需要先编译,那些文件需要后编译,那些文件需要重建等等。编译整个工程需要涉及到的,在 Makefile 中都可以进行描述。换句话说,Makefile 可以使得我们的项目工程的编译变得自动化,不需要每次都手动输入一堆源文件和参数。
当我们输入make命令的时候,make命令会在当前目录下找寻名字是Makefile或者makefile的文件。

当然,makefile的名字未必非得去这两种,可以自定义,如:
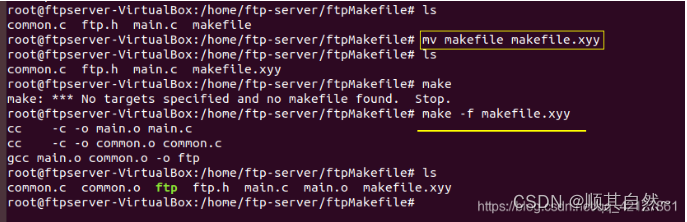
执行make命令的时候,用 -f 指明一下文件即可。
1. makefile文件格式
makefile文件格式主要是这个样子

命令必须以TAB键开始。
也就是这神奇的三要素:目标(target)、依赖文件(prerequisites,先决条件)、命令(command【make需要执行的命令,可以是任意的shell命令,并且可以有多行,每条命令占一行】)
可以看一下,我写的简单的makefile文件:

简单的说一下,这个目标,可以是任意我们想生成的东西,如上图所示,可以是可执行文件,也可以是目标文件(*.o),都行,后面的依赖文件,是生成目标的需要依赖的文件,下面的命令是真正的需要执行的命令。
说白了,意思就是,生成这个目标,需要这些依赖,有了依赖了,通过下面的命令来生成目标。
一个makefile可以有很多很多目标,上图中就有三个:main、main.o、common.o,但是make在执行makefile文件的时候,如果单单只是一个make命令没有指定生成的目标的话,会默认生成第一个target,即main。
2. make工作流程
这个生成target的流程,有必要说一下,如果target不存在的话,那么肯定是根据后面的依赖以及命令,来生成target,这时候如果后面的依赖存在的话,还好说,直接用命令生成target即可,如果后面的依赖项缺失,比如没有main.o中间目标文件,这时候,就会先生成依赖文件(main.o),也就是会转到依赖文件作为目标的语句上,就是main.o作为target的部分,先生成依赖文件,生成依赖文件之后,最后再生成target。这就像一个递归过程。
还有如果已经生成了target文件,这时候再次执行了make命令,这时候会比较target的最新时间与依赖项的最新时间,换句话说,就是看自上次make之后,后面的依赖项又没有被改变过,如果被改变了,那么依赖项的最新时间就会比target要新,这时候才会再次生成target。如果target比依赖项要新,那么就不做任何改变。
怎么说呢,这里也有一个类似于递归的概念,正如上图所示,如果common.o依赖的common.c被修改了,这时候在生成main的时候,会先生成最新的common.o,再生成最新的main
总之,如果我们运行make命令,make命令会以第一个target作为最终的目标,并以第一个target为起点,开始递归的编译所有的文件。
附: 如果嘴笨的我说不明白,可以看这个

四、makefile书写规则
这个书写makefile,我个人感觉,把它当成一门语言来学最好。虽然它不是真正意义上的语言。本文就是按照学习一门语言来进行布局的。
1. 注释
在makefile中只有行注释,没有那种/**/这样子的多行注释,makefile的行注释是和python的行注释一样,以 # 开始,当然,如果非要写多行,makefile中有一个反斜杠( \ ),意思是这一样写不完了,写在下一行,但是本质上还是一行。
2. 变量
这里的变量,我说一下,其实就是一个类似宏的概念,它是替换的意思,本质上我感觉就是一个字符串,字符串如果表示一个列表的话,每一个元素以空格隔开。在makefile执行的时候,会被扩展到对应的位置。变量这里,我说几点:
1)内置环境变量
在makefile中有一些隐含变量,你可以在makefile中改变这些变量的值,或者在make的命令行中传入这些值。
与命令相关的变量(就是这些变量可以当作命令使用):
AR
函数库打包程序。默认命令是“ar”。
AS
汇编语言编译程序。默认命令是“as”。
CC
C语言编译程序。默认命令是“cc”。
CXX
C++语言编译程序。默认命令是“g++”。
CO
从 RCS文件中扩展文件程序。默认命令是“co”。
CPP
C程序的预处理器(输出是标准输出设备)。默认命令是“$(CC) –E”。
FC
Fortran 和 Ratfor 的编译器和预处理程序。默认命令是“f77”。
GET
从SCCS文件中扩展文件的程序。默认命令是“get”。
LEX
Lex方法分析器程序(针对于C或Ratfor)。默认命令是“lex”。
PC
Pascal语言编译程序。默认命令是“pc”。
YACC
Yacc文法分析器(针对于C程序)。默认命令是“yacc”。
YACCR
Yacc文法分析器(针对于Ratfor程序)。默认命令是“yacc –r”。
MAKEINFO
转换Texinfo源文件(.texi)到Info文件程序。默认命令是“makeinfo”。
TEX
从TeX源文件创建TeX DVI文件的程序。默认命令是“tex”。
TEXI2DVI
从Texinfo源文件创建军TeX DVI 文件的程序。默认命令是“texi2dvi”。
WEAVE
转换Web到TeX的程序。默认命令是“weave”。
CWEAVE
转换C Web 到 TeX的程序。默认命令是“cweave”。
TANGLE
转换Web到Pascal语言的程序。默认命令是“tangle”。
CTANGLE
转换C Web 到 C。默认命令是“ctangle”。
RM
删除文件命令。默认命令是“rm –f”。
关于命令参数可以使用的变量(这些变量可以出现在命令之后的参数中使用)(如果没有指明其默认值,那么其默认值都是空。 ):
ARFLAGS
函数库打包程序AR命令的参数。默认值是“rv”。
ASFLAGS
汇编语言编译器参数。(当明显地调用“.s”或“.S”文件时)。
CFLAGS
C语言编译器参数。
CXXFLAGS
C++语言编译器参数。
COFLAGS
RCS命令参数。
CPPFLAGS
C预处理器参数。( C 和 Fortran 编译器也会用到)。
FFLAGS
Fortran语言编译器参数。
GFLAGS
SCCS “get”程序参数。
LDFLAGS
链接器参数。(如:“ld”)
LFLAGS
Lex文法分析器参数。
PFLAGS
Pascal语言编译器参数。
RFLAGS
Ratfor 程序的Fortran 编译器参数。
YFLAGS
Yacc文法分析器参数。
2)自动化变量
关于自动化变量,我只说几个比较简单的叭,能力有限,一些恶心的,我弄的也不是很清楚。

简单的说一下其中的几个变量:
$@
这个表示当前被执行的target的名字
$<
表示第一个依赖的名字
$^
表示所有的依赖文件列表,每个依赖项之间以空格隔开
3)普通变量
普通变量的定义很简单,也不需要啥类型,因为就像一个宏定义,是扩展上去的,所以不需要类型,直接写就行。
接下来我写一个简单的makefile,验证一下:


由以上两图,首先可以明确的看到,这些变量都是在makefile执行的时候被扩展上去的,所以在执行echo的时候,这些宏就已经被替换了,然后其实就是echo它们本身而已。
可以看到:
与命令相关的变量有默认值,
与命令参数相关的变量默认为空,
$@就是当前被执行的target,
$<就是第一个依赖项
$^就是所有依赖项
$(XYY)就是普通变量的引用
4)命令包变量(名字是抄别人的,他们这么叫,我就跟着叫了)
忘了还有一个这个变量没说,这个变量是可以多行定义一个命令块的,演示一下叭:

可以看到这里我定义了一个命令块,注意这里的命令最好用【tab】键开头,当然不用【tab】也无所谓,因为在运行makefile的时候,这个命令块就被扩展到对应的位置上了,而调用它的位置之前就有一个【tab】正好拼接上。
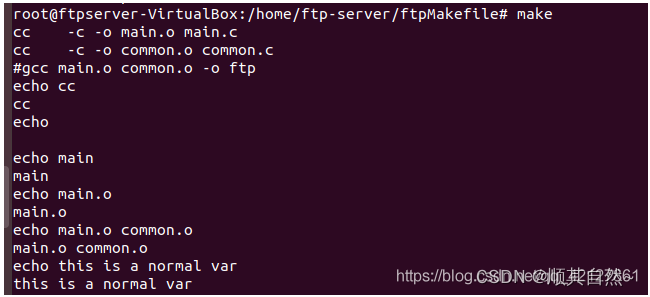
5)变量的赋值
接下来说一下变量的赋值操作,主要有四种赋值操作:

害,找不到我当初看的那个文章了,我就自己简单的说一下叭。
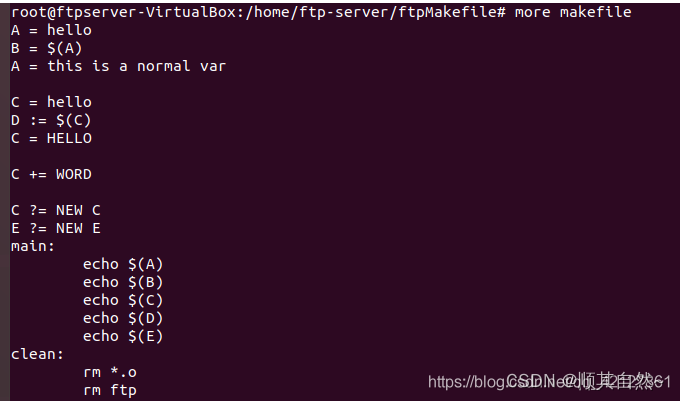

看图,分析:
首先,分析一下 = 这个有点像JavaScript中的预编译的操作,就是这个感觉像是先看完了所有变量,然后根据变量的最终的值,来进行赋值,也就是它会看完了A的所有赋值,然后将A的值赋值给B,B的值并不是一开始的hello,而是他所赋值的$(A)中的A的最后的值。
其次分析一下 := 这个就是常规的编程语言的赋值特点,赋值完毕之后,之后再怎么改动,都不会影响这次赋值,可以看到D的值就是hello,而不是C之后改的HELLO
再次分析一下 += 这个就是常规语言中的追加操作,但是这个追加,相当于再列表中进行追加,每项之间自动的以一个空格作为间隔。
最后分析一下 ?= 这个就是如果定义了变量,那么这个表达式就是失效的,如果没有定义过这个变量,那么进行这次赋值操作。为了验证失效情况,此时假设有一个E的定义再?=之前,那么?=失效,如果有一个定义在?=之后,我个人感觉,?=定义相当于 = ,之后又有E的定义操作,那么就相当于给E又赋值了一次,所以,无论什么情况,都会使得?=失效。
6)变量的引用
根据之前的例子,已经很明显的看到了,变量的引用是通过$()来进行引用的,这是一般情况,接下来说一个比较特殊的例子。
在shell语句中,如果想要使用shell中定义的变量,要使用$$var来引用shell中的变量。【注意,在shell语句中,如果一个shell语句位于一个情景下,那么一定要写一行,一行写不下用反斜杠( \ )】

说明一下叭,因为在makefile中 $ 的意思是引用,如果想要在命令执行的时候就打印出 $ ,那么就需要$$,就像C语言中的 \ \ 输出 \ 一样
这里再说一下 $(var:%.c=%.o),这种神奇的变量调用方式,它的意思是,将var中的所有元素,如果是以 .c结尾的,则换成 .o形式,返回转换后的结果。如图:

3. 语句

就这?就这?
就这四个语句,我感觉都不需要说,主要就说一下格式叭。
ifeq - else - endif
ifneq - else - endif
ifdef - else - endif
ifndef - else - endif
演示:
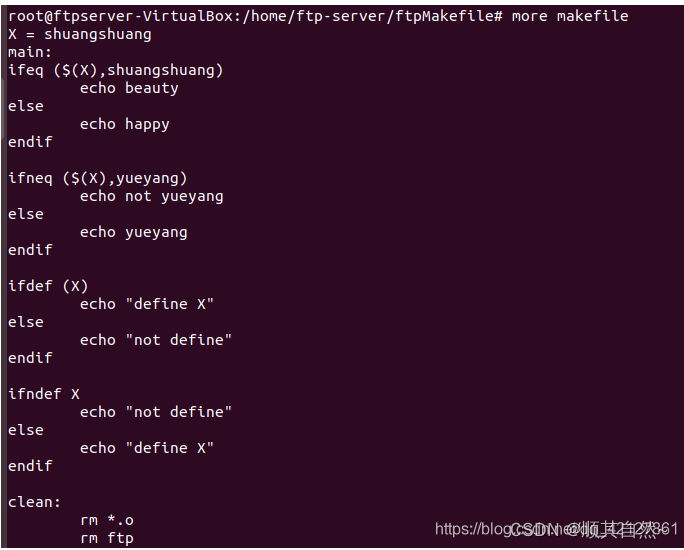
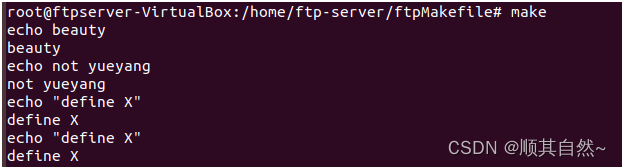
注,这里说一下注意事项叭:
可能有些博客上说ifeq 'arg' 'arg'这样也可以,确实可以,如下所示:
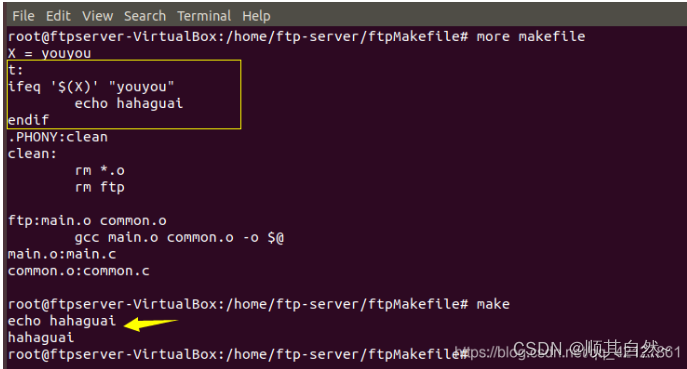
再加括号上,ifeq ifneq ifdef ifndef 这四个关键字,如果加括号的话,括号与关键字之间必须有一个空格,否则会报语法错误。然后就是如果用的是上图所示的双引号单引号的,这个可以任意搭配。
在格式上,这四个关键字书写的时候前面不能有【tab】键,要顶格书写,如果有【tab】的话,会被make解析成shell命令来执行。
4. 函数
好了,到了最重要的部分了,这里说的都是makefile内置函数,可以直接调用执行的。
在调用函数之前,函数调用格式如下:
$(<function> <arguments>) 或者是 ${<function> <arguments>}
其中,function 是函数名,arguments 是函数的参数,参数之间要用逗号分隔开。而参数和函数名之间使用空格分开。调用函数的时候要使用字符“$”,后面可以跟小括号也可以使用花括号。
1)字符串处理函数
字符串替代函数:
$(patsubst <pattern>,<replacement>,<text>)
函数说明:函数功能是查找 text 中的单词是否符合模式 pattern,如果匹配的话,则用 replacement 替换。返回值为替换后的新字符串。
$(subst <from>,<to>,<text>)
函数说明:函数的功能是把字符串中的 form 替换成 to,返回值为替换后的新字符串。
对于上面这俩函数,可以看到都有substitute string,即替代字符串,不同的是,有一个加了pattern ,也就是上一个函数可以使用通配符匹配,比较高端。
去空格函数
$(strip <string>)
函数说明:函数的功能是去掉字符串的开头和结尾的字符串,并且将其中的多个连续的空格合并成为一个空格。返回值为去掉空格后的字符串。
查找字符串函数
$(findstring <find>,<in>)
函数说明:函数的功能是查找 in 中的 find ,如果我们查找的目标字符串存在。返回值为目标字符串,如果不存在就返回空。
过滤函数
$(filter <pattern>,<text>)
函数说明:函数的功能是过滤出 text 中符合模式 pattern 的字符串,可以有多个 pattern 。返回值为过滤后的字符串。
反过滤函数
$(filter-out <pattern>,<text>)
函数说明:函数的功能是功能和 filter 函数正好相反,但是用法相同。去除符合模式 pattern 的字符串,保留符合的字符串。返回值是保留的字符串。
排序函数
$(sort <list>)
函数说明:函数的功能是将 <list> 中的单词排序(升序)。返回值为排列后的字符串。【注:sort会去除重复的字符串】
去单词函数
$(word <n>,<text>)
函数说明:函数的功能是取出函数 <text> 中的第n个单词。返回值为我们取出的第 n 个单词。
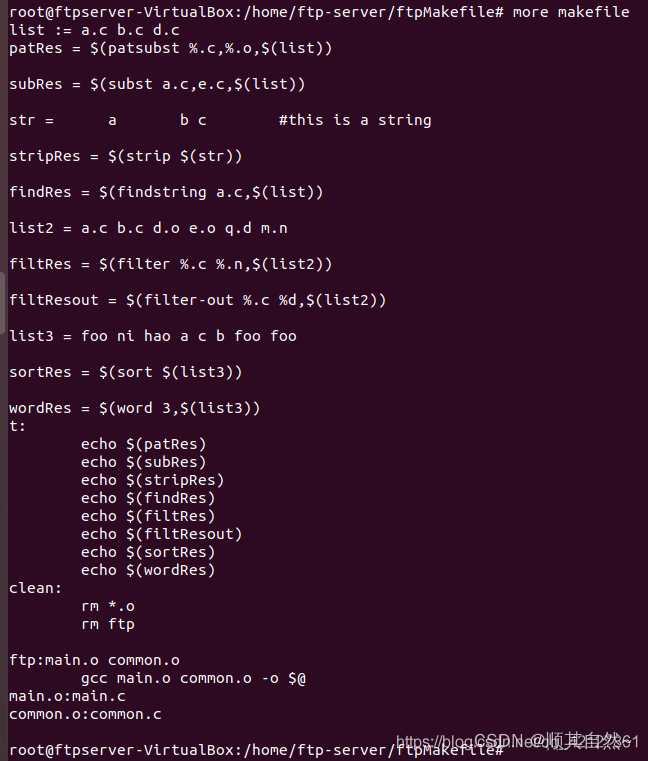
上面个就是对于字符串的操作函数,下面我给一个例子吧,对照着看看效果

2)文件名操作函数
注意:下面的每个函数的参数字符串都会被当作或是一个系列的文件名来看待。
取目录函数
$(dir <names>)
函数说明:函数的功能是从文件名序列 names 中取出目录部分,如果没有 names 中没有 “/” ,取出的值为 “./” 。返回值为目录部分,指的是最后一个反斜杠之前的部分。如果没有反斜杠将返回“./”。
取文件函数
$(notdir <names>)
函数说明:函数的功能是从文件名序列 names 中取出非目录的部分。非目录的部分是最后一个反斜杠之后的部分。返回值为文件非目录的部分。
取后缀名函数
$(suffix <names>)
函数说明:函数的功能是从文件名序列中 names 中取出各个文件的后缀名。返回值为文件名序列 names 中的后缀序列,如果文件没有后缀名,则返回空字符串。
取前缀函数
$(basename <names>)
函数说明:函数的功能是从文件名序列 names 中取出各个文件名的前缀部分。返回值为被取出来的文件的前缀名,如果文件没有前缀名则返回空的字符串。
添加后缀名函数
$(addsuffix <suffix>,<names>)
函数说明:函数的功能是把后缀 suffix 加到 names 中的每个单词后面。返回值为添加上后缀的文件名序列。
添加前缀名函数
$(addprefix <prefix>,<names>)
函数说明:函数的功能是把前缀 prefix 加到 names 中的每个单词的前面。返回值为添加上前缀的文件名序列。
链接函数
$(join <list1>,<list2>)
函数说明:函数功能是把 list2 中的单词对应的拼接到 list1 的后面。如果 list1 的单词要比 list2的多,那么,list1 中多出来的单词将保持原样,如果 list1 中的单词要比 list2 中的单词少,那么 list2 中多出来的单词将保持原样。返回值为拼接好的字符串。
获取匹配模式文件名函数
$(wildcard PATTERN)
函数说明:函数的功能是列出当前目录下所有符合模式的 PATTERN 格式的文件名。返回值为空格分隔并且存在当前目录下的所有符合模式 PATTERN 的文件名。
上面个的基于文件的函数就这些了,下面我给出一个例子,加一些我的个人看法

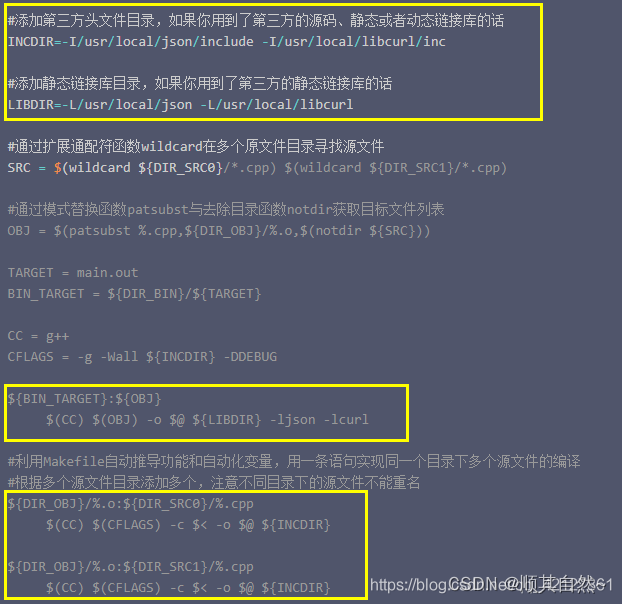
下面我谈一下,我的个人看法,真正的makefile其实很少涉及到具体的名字啥的,然后我感觉应该都是一种统一的格式,具有普适性,所以真正的写法应该是,从wildcard入手,获取当前目录下的文件,然后再用其他的文件名操作函数,可以看到,上面的8个函数,说是文件名操作函数,其实就是本质上处理字符串而已,只有wildcard函数是真正的去当前目录下去获取当前目录下符合pattern的文件名。
然后其他需要注意的地方就是join函数的处理,它涉及到了两个list的长度比大小,请仔细看一下我贴上来的图片结果。
3)其他常用函数
foreach函数
$(foreach <var>,<list>,<text>)
函数的功能是:把参数<list>中的单词逐一取出放到参数 <var> 所指定的变量中,然后再执行<text>所包含的表达式。每一次 <text> 会返回一个字符串,循环过程中,<text> 所返回的每个字符串会以空格分割,最后当整个循环结束的时候,<text> 所返回的每个字符串所组成的整个字符串(以空格分隔)将会是 foreach 函数的返回值。所以<var>最好是一个变量名,<list> 可以是一个表达式,而<text>中一般会只用 <var>这个参数来一次枚举<list>中的单词。【注意:这里的var是一个局部变量,函数结束之后,var变量会消失】
if函数
$(if <condition>,<then-part>)或(if<condition>,<then-part>,<else-part>)
可见,if 函数可以包含else部分,或者是不包含,即if函数的参数可以是两个,也可以是三个。condition参数是 if 表达式,如果其返回的是非空的字符串,那么这个表达式就相当于返回真,于是,then-part就会被计算,否则else-part会被计算。
而if函数的返回值是:如果condition为真(非空字符串),那么then-part会是整个函数的返回值。如果condition为假(空字符串),那么else-part将会是这个函数的返回值。此时如果else-part没有被定义,那么整个函数返回空字串符。所以,then-part和else-part只会有一个被计算。
call函数
$(call <expression>,<parm1>,<parm2>,<parm3>,...)
call 函数是唯一 一个可以调用参数化表达式的函数。我们可以用来写一个非常复杂的表达式,这个表达式中,我们可以定义很多的参数,然后你可以用 call 函数来向这个表达式传递参数。
当 make 执行这个函数的时候,expression参数中的变量$(1)、$(2)、$(3)等,会被参数parm1,parm2,parm3依次取代。而expression的返回值就是 call 函数的返回值。
origin函数
$(origin <variable>)
origin 函数不像其他的函数,它并不操作变量的值,它只是告诉你这个变量是哪里来的。【注意: variable 是变量的名字,不应该是引用,所以最好不要在 variable 中使用“$”字符。origin 函数会员其返回值来告诉你这个变量的“出生情况”。】

shell函数
$(shell <command>)
shell函数把执行操作系统命令后的输出作为函数返回。
注意: 这个函数会新生成一个Shell程序来执行命令,所以你要注意其运行性能,如果你的Makefile中有一些比较复杂的规则,并大量使用了这个函数,那么对于你的系统性能是有害的。特别是Makefile的隐晦的规则可能会让你的shell函数执行的次数比你想像的多得多。
好了看完了,那我就弄一个小例子,贴上来,上面的shell函数,我单独测试一下
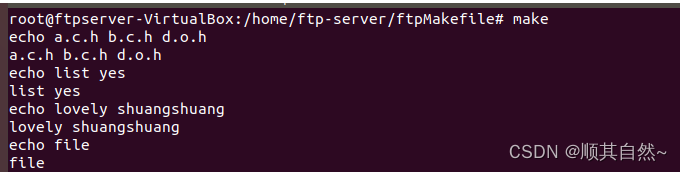
在这里补充一点,关于那个call的函数,如下图:

shell函数的测试:

五、通配符
想必之前已经看到了很多关于通配符的东西了,下面简单的说一下通配符。
通配符主要说两个,* 与 %
makefile是可以使用shell命令的,所以shell支持的通配符,在makefile中也同样适用。
对于这俩通配符,我只能谈一下我的个人理解:*是应用在系统中的,%是应用在这个Makefile文件中的。
啥意思呢,就是凡是要到系统中去匹配的,就得用 * ,%通配符,仅限在makefile文件中用来匹配规则而已,也就是%匹配的东西(可以看成字符串)在makefile(可以看成普通文档)中是可以找到的,而 * 匹配的东西,就需要跳出makefile去系统中匹配对应的文件之类的东西。
下面说一下一些简单的应用场景:
-
在shell命令中可以使用
*,因为shell命令是连接系统的,shell中使用*,就是匹配系统中的文件 -
在依赖的时候可以使用
*,如:test:*.c gcc -o $@ $^因为,test,作为target,需要找它的依赖,这个找依赖的过程,makefile是做不到的,makefile只能说去决定如何编译依赖,找依赖,需要到系统中去找,所以需要用
* -
如果依赖存在,那么在makefile中决定如何编译依赖,就可以使用
%通配符test:test.o test1.o gcc -o $@ $^ %.o:%.c gcc -o $@ $^这时候,我们已经人为规定了test需要这两个依赖,但是这两个依赖,如何编译,需要在makefile中进行寻找,所以就需要%通配符,来匹配下面的规则。
-
在wildcard中使用
*,因为wildcard需要连接系统,获取当前目录下的文件名字,所以需要使用shell中的通配符*
总之,如果需要涉及到去系统中匹配,就要用*,如果仅在makefile中匹配,就用%
六、源文件搜索路径
这个第六节的名字,是我自己取的,因为这个名字我才感觉是贴合它的实际作用,有些博客起的名字有的叫目标文件搜索,有的叫文件搜寻,等等,但我感觉都不切合实际,所有就自己取了一个名字。
这个和第七个将要讲的include虽然都有包含的意思,但是不是一个东西,要注意区分,这个源文件搜索路径,是我们在编译的时候,如果工程量巨大,源文件不都在当前目录下,存放于其他目录下,那么VPATH或者vpath就派上了用场,用来指定找寻不在当前目录下的源文件的目录。
VPATH 和 vpath 的区别:VPATH 是变量,更具体的说是环境变量,Makefile 中的一种特殊变量,使用时需要指定文件的路径;vpath 是关键字,按照模式搜索,也可以说成是选择搜索。搜索的时候不仅需要加上文件的路径,还需要加上相应限制的条件。
通俗点说,就是VPATH是一个不具有筛选条件的指定路径方法,如果缺失了一个文件,makefile会去VPATH中的所有目录中挨个寻找对比,效率低。而vpath带了模式搜索,可以选择性的指定哪种类型的文件去哪个目录下寻找,比较方便。
VPATH = src ../header
或
VPATH = src:../header
VPATH的语法如上所示,多个路径之间可以用空格隔开,也可以用冒号( : )隔开。文件搜索的顺序为,先在当前目录下寻找,如果没找到,就按照VPATH中的书写顺序挨个寻找。先搜索src,再搜索header
注意:无论你定义了多少路径,make 执行的时候会先搜索当前路径下的文件,当前目录下没有我们要找的文件,才去 VPATH 的路径中去寻找。如果当前目录下有我们要使用的文件,那么 make 就会使用我们当前目录下的文件。
验证: 工程结构、程序源代码如下:

当VPATH中只写了src的路径的时候,不写header的路径,这时候会报错:
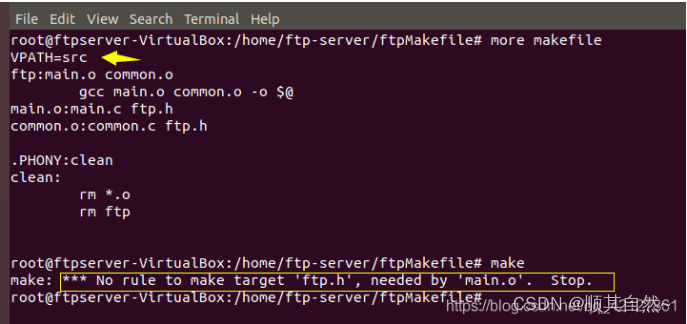
思考一下,这说明什么,说明我们的源文件其实也是一个target的形式存在,他们是最基本的target,然后一层一层的向上走。虽然我们的main.c或者common.c中已经指明了ftp.h的位置,但是指明归指明,makefile不会去看你的源代码,他只是根据你的依赖,去找对应的实体文件,,也就是说源代码是对makefile透明的,源代码属于其他逻辑,独立于makefile的逻辑。所以我们还是要显式指定header的路径。
正确如下:

1) vpath PATTERN DIRECTORIES
2) vpath PATTERN
3) vpath
上面是vpath的使用方法,PATTERN是模式(选择条件),可以带有通配符,后面的DIRECTORIES是指定的搜索目录。
例:
vpath test.c ../header:src #意思是,test.c文件去header下面找
vpath %.c ../header src #意思是,所有的.c文件都去header下面找
在路径的书写上同样用空格或者冒号隔开。
vpath test.c #意思是,清除之前定义的关于test.c的搜索路径设置
vpath #意思是,清除之前设置的所有的搜索路径
对vpath的验证如下:
注意:这里的指示的路径应该是包含的我们自己写的源文件的路径,如果包含了其他第三方源代码,或者第三方链接库的话,我看其他博客是直接将这些第三方的东西写在了编译命令上,用来指示第三方的路径,而不是用VPATH或vpath
我从别的网站上摘下了一段如何选择使用VPATH或者vpath,看看叭:
使用什么样的搜索方法,主要是基于编译器的执行效率。使用 VPATH 的情况是前路径下的文件较少,或者是搜索的文件不能使用通配符表示,这些情况下使用VPATH最好。如果存在某个路径的文件特别的多或者是可以使用通配符表示的时候,就不建议使用 VPATH 这种方法,为什么呢?因为 VPATH 在去搜索文件的时没有限制条件,所以它回去检索这个目录下的所有文件,每一个文件都会进行对比,搜索和我们目录名相同的文件,不仅速度会很慢,而且效率会很低。我们在这种情况下就可以使用 vpath 搜索,它包含搜索条件的限制,搜索的时候只会从我们规定的条件中搜索目标,过滤掉不符合条件的文件,当然查找的时候也会比较的快。
七、包含其他makefile
makefile中的include关键字是用来包含其他makefile文件的,当一个工程很大的时候,每个模块都会有一个独立的makefile来描述对应模块的编译规则,那么需要定义一组通用的变量定义或者模式规则来维护整个工程的统一,然后需要的时候,每个模块的makefile再include进来这个统一的通用makefile。
include就相当于C语言中的#include,当make读取到当前makefile中的include关键字的时候,会暂停读取当前的makefile,进而转去读取include中包含的makefile文件,读取包含的makefile文件之后,再回来继续读取当前的makefile文件。
include <filenames>
注意:“include” 关键字所在的行首可以包含一个或者是多个的空格(读取的时候空格会被自动的忽略),但是不能使用 Tab 开始,否则会把 “include” 当作式命令来处理。包含的多个文件之间要使用空格分隔开。使用 “include” 包含进来的 Makefile 文件中,如果存在函数或者是变量的引用,它们会在包含的 Makefile 中展开。
说白了,就是原封不动的将被包含的makefile文件展开在当前makefile文件中包含被包含文件的位置。
make命令开始时,会找寻include所指出的其它Makefile,并把其内容安置在当前的位置。就好像C/C++的#include指令一样。如果文件都没有指定绝对路径或是相对路径的话,make会在当前目录下首先寻找,如果当前目录下没有找到,那么,make还会在下面的几个目录:
- 执行 make 命令的时候加入的选项 “-I” 或 “–include-dir” 后面添加上指定的路径
- 其他的几个路径中搜索:“usr/gnu/include”、“usr/local/include” 和 “usr/include”。
如果在上面的路径没有找到 “include” 指定的文件,make 将会提示一个文件没有找到的警示提示,但是不会退出,而是继续执行 Makefile 的后续的内容。当完成读取整个 Makefile 后,make 将试图使用规则来创建通过 “include” 指定但不存在的文件。当不能创建的时候,文件将会保存退出。
使用时,通常用 “-include” 来代替 “include” 来忽略文件不存在或者是无法创建的错误提示,使用格式如下:
-include <filename>
sinclude <filename> #这俩一样,是一个意思。
这两种方式之间的区别:
使用 "include <filenames>" ,make 在处理程序的时候,文件列表中的任意一个文件不存在的时候或者是没有规则去创建这个文件的时候,make 程序将会提示错误并保存退出。
使用 "-include <filenames>",当包含的文件不存在或者是没有规则去创建它的时候,make 将会继续执行程序,只有真正由于不能完成终极目标重建的时候我们的程序才会提示错误保存退出。
所以综合来看还是用 -include会更好,毕竟我们的目标是最后的终极目标。至于过程嘛,无所谓的。
验证情景(一):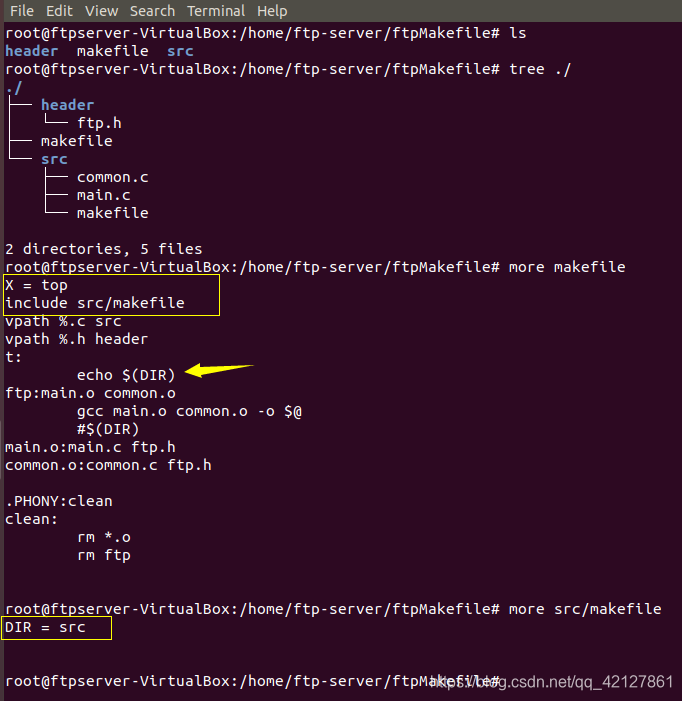
运行结果:
可以看到,就是相当于#include的感觉一样,是完全被复制进去了。
验证情景(二):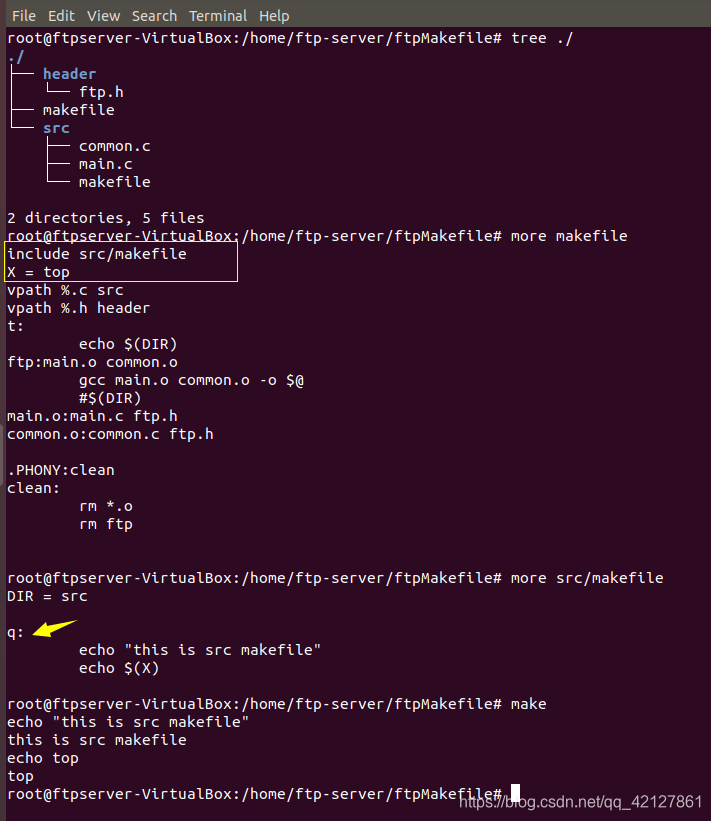
从结果可以看出,就是被复制进去了,然后在上层中运行make,运行的target却是下层的对象。并且哪怕下层makefile输出的X变量在引用的时候还未被定义,照样可以获得X的最终值,越来越感觉像是JavaScript的预编译机制了。。
八、嵌套执行make(调用其他makefile)
上面说了如何包含其他makefile到当前makefile中,现在说一下如何调用其他目录下的makefile,就是执行其他目录下的makefile,是执行而不是包含进来。注意区分。
$(Target):$(OBJS)
$(MAKE) -C $(SUBDIR)
#或者
$(Target):$(OBJS)
cd $(subdir) && $(MAKE)
这里的核心就是这两句命令,当生成target目标对象时,会执行$(MAKE) -C $(SUBDIR)这条命令,进入目录SUBDIR,该目录下有一个Makefile,并执行。其中,$(MAKE) 值make预定义的变量,一般指的就是make,无需修改,可通过make -p查看make所有的预定义的变量。当然,也可直接指明为make,即make -C $(SUBDIR)。其中-C表示改变当前目录,make的命令选项可通过make -h查看。(make维护了一个变量CURDIR,代表make的工作目录,当使用-C选项修改工作目录的时候,此变量会被重新赋值)
例:make clean -C $(SUBDIR) -f Makefile
其实本质的意思还是执行shell命令而已,只不过执行的这个命令,指定了目录,指定了文件而已,上面这个例子,就是,执行make clean命令,只不过这个命令在子目录下执行,并且指定了Makefile。
第二种方法,意思更加明确,直接cd进子目录,然后执行一下make命令。
例:循环进入多个子目录执行make命令
SUBDIRS=subdir1 subdir2 subdir3
RECURSIVE_CLEAN=for subdir in $(SUBDIRS);\
do\
echo cleaning in $${subdir};\
(cd ${subdir} && $(MAKE) clean -f Makefile)||exit 1;\
done
.PHONY: clean
clean:
$(RECURSIVE_CLEAN)
shell脚本中,分号是多个语句之间的分隔符号,当一行只有一条语句的时候,末尾无需分号,当然加了也没错。将for循环写成一行时,do后面需要有空格符或者tab符来分隔。如果done后面还有语句的话,需要再加上分号。
注意: 当Makefile内嵌shell脚本时,Makefile中每一行的shell脚本需要一个shell进程来执行,不同行之间变量值不能传递。所以,Makefile中的shell不管多长也要写在一行。因此,多行的shell需要在Makefile使用反斜杠“\”连接为一行。此时,shell脚本中的一条语句后需要添加分号分隔。
注意: Makefile中对一些简单变量的引用,可以不使用”()”和”{}”来标记变量名,而直接使用$x的格式来实现,此种用法仅限于变量名为单字符的情况。另外自动化变量也使用这种格式。对于一般多字符变量的引用必须使用括号,否则make将把变量名的首字母作为作为变量而不是整个字符串($PATH在Makefile中实际上是$(P)ATH)。
makefile中的变量传递,当makefile嵌套执行的时候,可以使用
export <variable>
将指定变量传递给下层makefile,如果不需要传了,可以使用:
unexport <variable>
<variable>是变量的名字,不需要使用 "$" 这个字符。如果所有的变量都需要传递,那么只需要使用 “export” 就可以,不需要添加变量的名字。
Makefile 中还有两个变量不管是不是使用关键字 “export” 声明,它们总会传递到下层的 Makefile 中。这两个变量分别是 SHELL 和 MAKEFLAGS,特别是 MAKEFLAGS 变量,包含了 make 的参数信息。如果执行总控(最顶层) Makefile 时,make 命令带有参数或者在上层的 Makefile 中定义了这个变量,那么 MAKEFLAGS 变量的值将会是 make 命令传递的参数,并且会传递到下层的 Makefile 中,这是一个系统级别的环境变量。
如果我们不想传递 MAKEFLAGS 变量的值,在 Makefile 中可以这样来写:
subsystem:
cd $(subdir) && $(MAKE) MAKEFLAGS=
验证: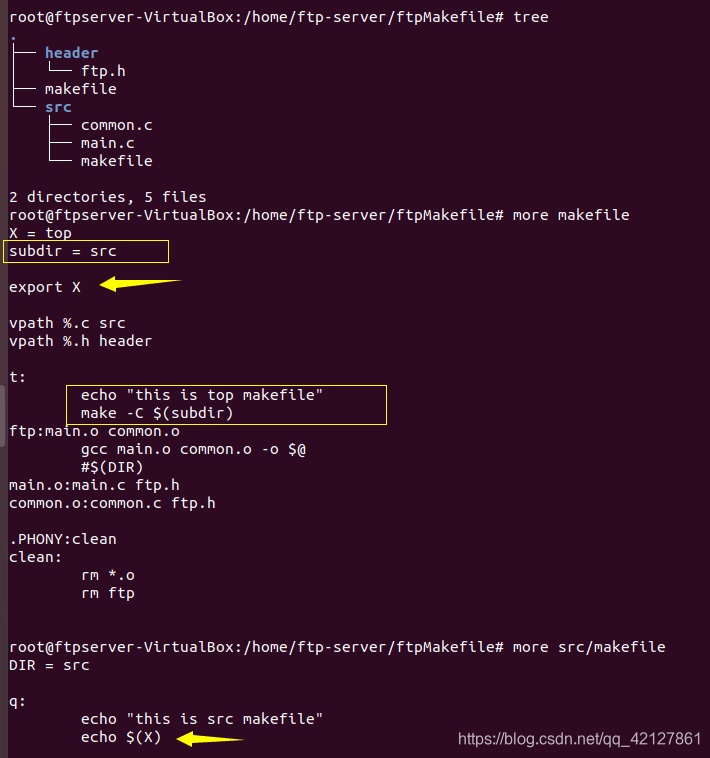
执行结果: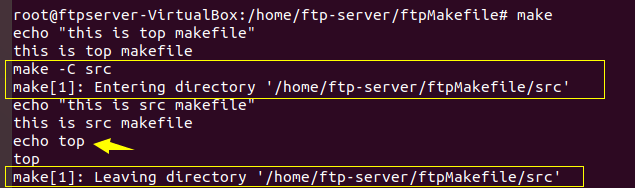
可以看到X传递到下层makefile中去了,并且有很明显的进入src提示,离开src提示。
九、伪目标
所谓的伪目标可以这样来理解,它并不会创建目标文件,只是想去执行这个目标下面的命令。伪目标的存在可以帮助我们找到命令并执行。
这个伪目标我只会很简单的操作,深奥的决定嵌套makefile执行顺序的操作,我是真学不来,以后真正在大工程上用到了,再说吧。
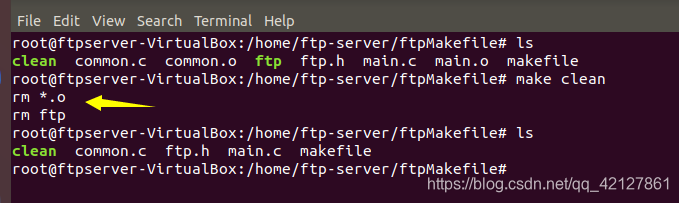
说一下简单操作吧,细心的可能会注意到,我之前的makefile的操作,clean都是这么写的:
其实这么写是不对的,第一是影响效率,第二是有些情况下,shell命令不会被执行。
规则中 rm 命令不是创建target目标 clean 的命令,而是执行删除任务,删除当前目录下的所有的 .o 结尾和文件名为 ftp的文件。当工作目录下不存在以 clean 为名字的文件时,在 shell 中输入 make clean 命令,命令 rm 总会被执行 ,这也是我们期望的结果。
如果当前目录下存在文件名为 clean 的文件时情况就会不一样了,当我们在 shell 中执行命令 make clean,由于这个规则没有依赖文件,所以目标被认为是最新的而不去执行规则所定义的命令。因此命令 rm 将不会被执行,如下图所示: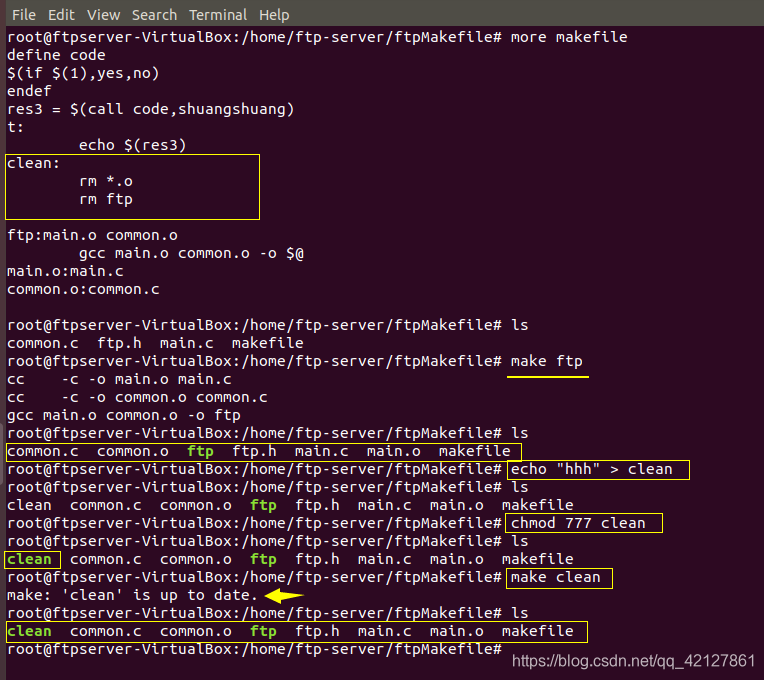
可以看到,并没有出现我们预想的情况,为了解决这个问题,需要在 Makefile 中将目标 clean 声明为伪目标。将一个目标声明称伪目标的方法是将它作为特殊的目标.PHONY的依赖,如下:
.PHONY:clean
这样 clean 就被声明成一个伪目标,无论当前目录下是否存在 clean 这个文件,当我们执行 make clean 后 rm 都会被执行。而且当一个目标被声明为伪目标之后,make 在执行此规则时不会去试图去查找隐含的关系去创建它。这样同样提高了 make 的执行效率,同时也不用担心目标和文件名重名而使我们的编译失败。
.PHONY:clean
clean:
rm -rf *.o ftp
伪目标使用格式如上所示,要先声明,然后再定义伪目标规则。
正确运行如下: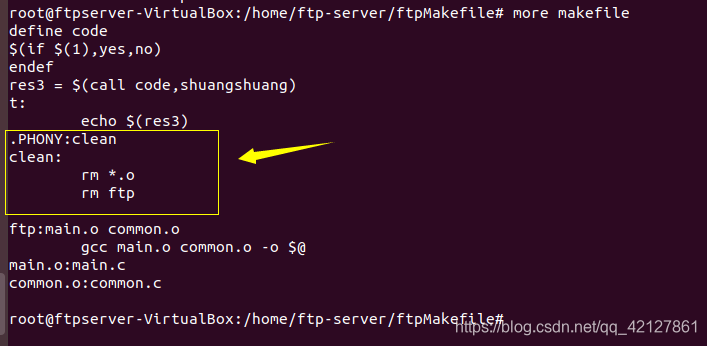
十、隐含规则
关于隐含规则这里,我就只说一点点,深了我也不会,,,
就是在我们编写makefile的时候,有一个这样的情况: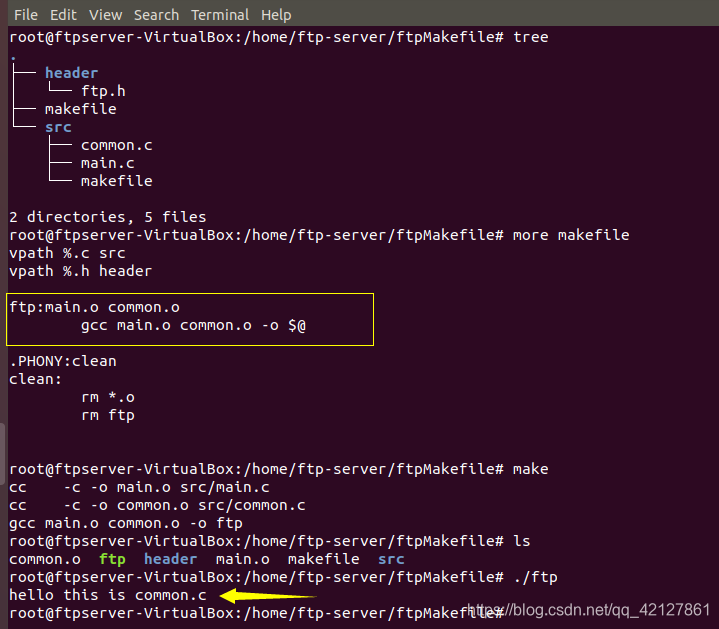
就是这里我们没有写生成main.o和common.o的规则,但是照样可以正常编译链接,然后运行。这就是隐含规则的作用。
注:隐含条件只能省略中间目标文件重建的命令和规则,但是最终目标的命令和规则不能省略。
隐含规则简要理解就是:正常的规则是三要素一个都不能少,就是目标、依赖、命令一个都少不了,如果少了,就不能正确运行,但是由于隐含规则的存在,可以自动补全,自动利用隐含规则推导,补充上缺失的部分。
可以联想到,如果没有显式指出命令的话,会推导命令,但是命令就真的凭空产生吗?不是的,还记得说变量的时候,第一个就说的是默认得隐含变量,这些推到出来的就会用这些默认变量来生成命令。
再说一句,隐含规则是有优先级的,至于隐含规则的优先级,读者自行百度吧。实在不行,就不要用隐含规则了,全部显式写出规则来,或者在执行make时,加入-r或-n-builtin-rules取消所有隐含规则。
隐含规则的具体的工作流程:make 执行过程中遇到没有提供显式规则的中间目标文件,则根据其后缀 .o 找到隐含规则,隐含规则提供了此中间目标的基本依赖关系。确定中间目标的依赖文件和重建中间目标需要使用的命令行。隐含规则所提供的依赖文件只是一个基本的依赖关系(在C语言中,通常他们之间的对应关系是:test.o 对应的是 test.c 文件)。如果需要增加其他的自定义的文件作为依赖,则需要 在Makefile 中使用没有命令行的规则给出。
如下: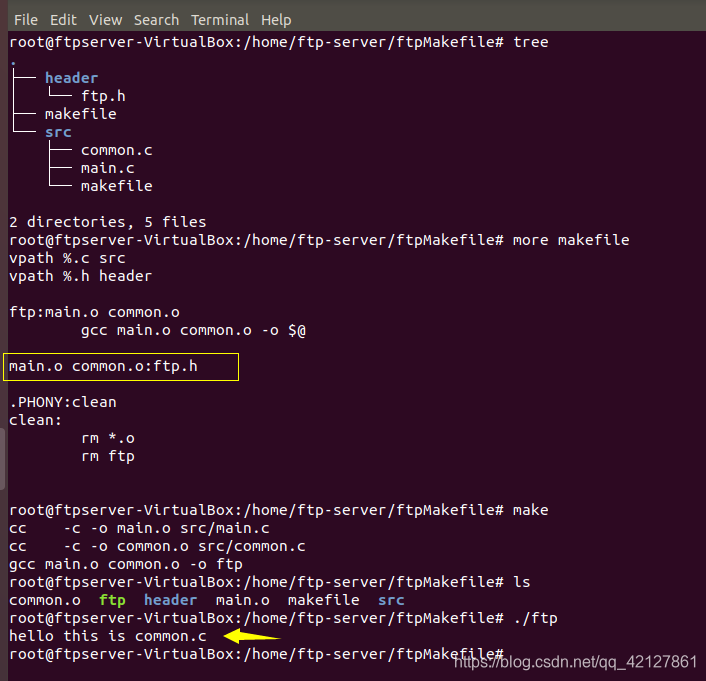
十一、其他小技巧
再说几个其他小技巧
-
@的使用:
makefile在make的时候会输出执行的指令,然后再输出结果,如果我们只想要结果,不要指令显示,那么在指令面前加上@就行了。如下: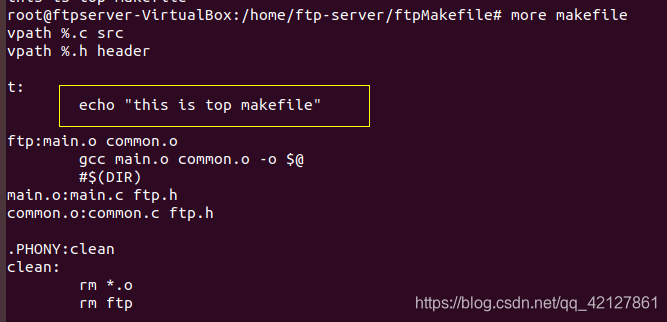

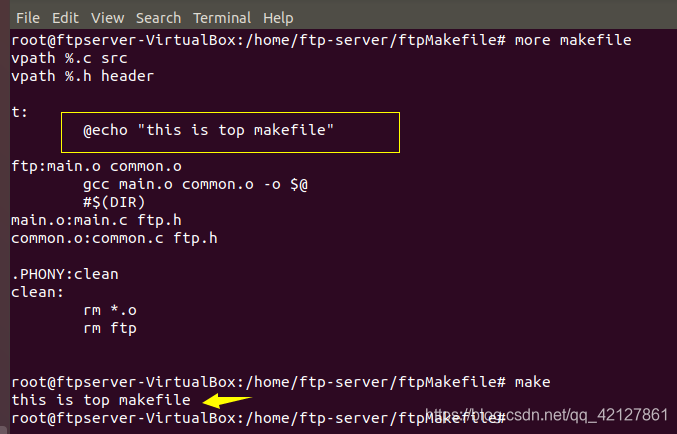
-
定义变量的值为一个空格
在makefile中,等式右面是很难定义一个空格的,所以这里有一个小技巧。用一个empty变量作为起始,用注释表示结束,如下:
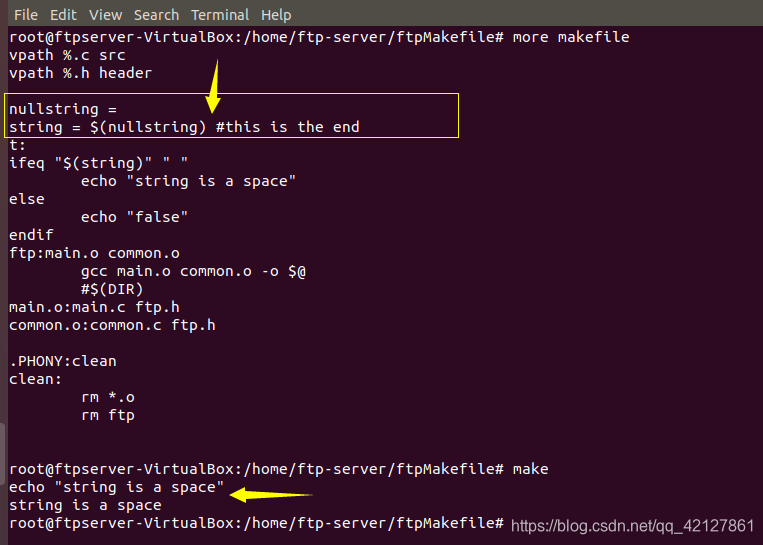
nullstring 是一个Empty变量,其中什么也没有,而space的值是一个空格。所以这里先用一个 Empty变量来标明变量的值开始了,而后面采用“#”注释符来表示变量定义的终止,这样,我们可以定义出其值是一个空格的变量。请注意这里关于“#”的使用,注释符“#”的这种特性值得我们注意。也就是以后定义变量的时候,要格外注意,注释符”#“才是一个变量定义的结束。如果注释符之前有空格的话,那些空格也会算到所定义的变量之中。
十二、makefile小结,谈感受
历时三天,终于把这篇博客大概的写了下来,其实makefile博大精深,我还有很多没有涉猎的地方,例如:多目标,静态模式,自动生成依赖,错误信息,override指示符,make命令大全,等等这些,我目前是没有精力去弄这些了,等以后真的需要了,再回过头来重新钻研吧。
十三、编译FTP文件
写了三天,我都快忘了,这篇博客一开始是要干啥,我要编译一个FTP源文件呀,天呐,忘了快。。。
现在是凌晨1:13分,我终于解决了为什么登录不上的问题,为了解决这个问题,我把这个FTP的源代码看了一遍,后来发现,是我的习惯问题,我习惯在一段字符串之后敲一个空格,然后这个自己写的FTP服务端呢,还没有删除两端空格的操作,也就是这个随手敲得空格变成了用户名,然后识别不了,然后就失败了。
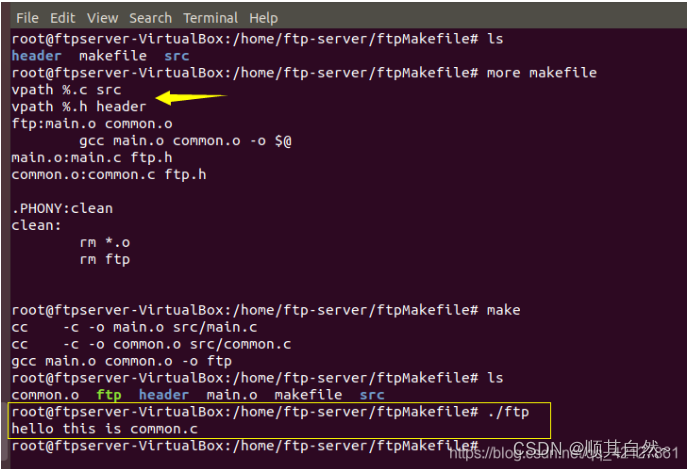
解决问题后,就用我学过的makefile知识,编译一下这个FTP文件吧。
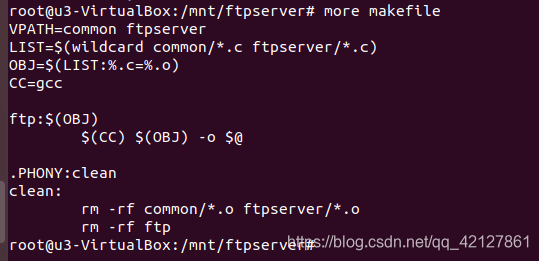
运行: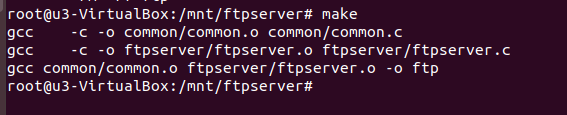
启动FTP服务器,使用Linux的通用客户端进行连接: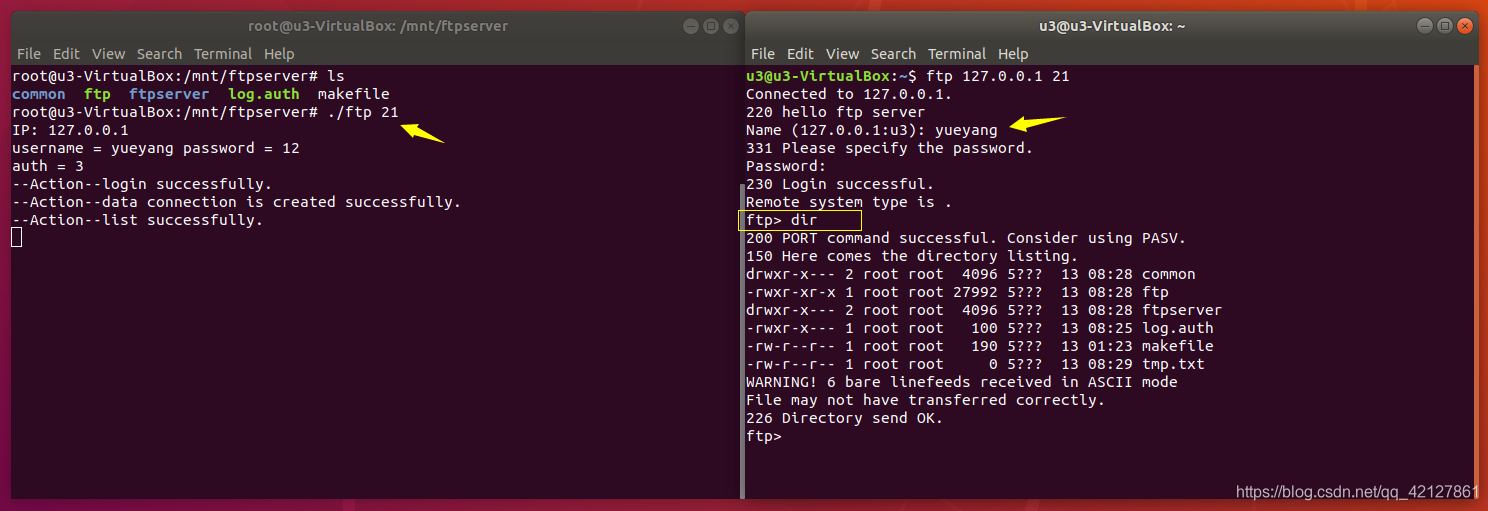
可以看到FTP成功运行起来了。撒花撒花,哈哈哈哈
十四、结语
终于把这篇博客完成了,现在已经凌晨两点了,舍友都睡着了,就我一个人还在肝,历时三天多,终于肝完了,收获很大,这波不亏,好了,散会。

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐


 8
8 0
0- 0



 已为社区贡献88条内容
已为社区贡献88条内容

所有评论(0)