2022年语音合成(TTS)和语音识别(ASR)年度总结
2022年语音合成和语音识别文章年度总结

论文统计每月更新一次,主要跟踪语音合成和语音识别的发展状况(很多文章都是在会议后才发出,但不影响统计。统计过程难免存在疏漏,因此统计结果仅供参考。所有文章语音合成领域统计列表请访问http://yqli.tech/page/tts_paper.html,语音识别领域论文统计请访问http://yqli.tech/page/asr_paper.html。开源语音数据查询 http://yqli.tech/page/data.html。
如何查找语音资料请参考文章https://mp.weixin.qq.com/s/eJcpsfs3OuhrccJ7_BvKOg)。读者有什么建议可以直接给我发消息,我将不断修改该统计。如有转载,请注明出处。欢迎关注微信公众号:低调奋进。
2022年语音合成和语音识别文章统计excel https://docs.google.com/spreadsheets/d/11YYOg6i6UXw19_g1JRaXGNhvt1zhG24RgOXCzZlqZGE/edit?usp=sharing
AIGC统计http://yqli.tech/page/aigc.html
文前声明:由于本人非学术圈,所写内容不能面面俱到,仅为个人见解,大家谨慎参考
前言
(本部分主要胡思乱想,读者可直接跳到语音合成和识别部分)
本打算不写吐槽,但不吐槽又感觉缺少点什么,一整年都在吐槽中度过,上半年吐槽上海下半年吐槽北京。如何总结今年的生活呢?感觉发生很多很多事情,但关于自身记忆犹新的事情却少之又少。今年,我们旁观了诸多国内外发生的载入历史画卷的事件,也亲身体验了几种截然不同的生活方式,有亢奋、有愤怒、有豁达,所有事情过后又感觉一片空白和茫然,非常不实,普通的个体对历史和超大群体来说微如尘埃。
本公众号差不多开通两年,第一个年头能保持周更,但今年只能保持每月一次的文章总结。总结起来主要以下几个原因:1)以前分享内容主要以分析论文为主,现阶段我更喜欢在某一个方向做总结,而且写文章尝尝几个钟头,所以就把分享论文停了。虽然停止论文分享,但也能坚持读读论文,后续可能会把文章总结整理到个人网站,再分享到公众号上(个人网站便于资料管理和查找,公众号后台的文章管理做的太差了)。2)公众号的封闭圈子和微薄的激励消磨了太多作者的热情。记得两年前,有好几个朋友一起做公众号,但他们更新几篇文章就停更了。一方面,公众号是在封闭的圈子进行信息传播、缺少交流机制(18年后创建公众号取消留言功能)等因素造成读者很少,这扑灭了大部分作者长久更新的热情。另一方面,公众号不挣钱,更多靠作者的激情来维护(以本公众号为例,在不接广告、不乱插入广告情况下一年也就几十元钱,买个读书会员都不够)。幸好,我把公众号当成个人网站的窗口,这也是保持长久更新原因。不积跬步无以至千里,去年计划很多事情,最终没能完成,志大才疏,缺少细微的计划。因此,本年将会步步为营,尽量恢复每周一更。
近几年,AI行业因为开销大不挣钱而被很多人看衰,我身边的前同事也有转到其它领域。今年,AIGC很争气,把AI的火焰又给鼓吹了起来,其中最璀璨的两颗明珠莫过于文生图(CompVis/stable-diffusion开源后就38.6k stars)和ChatGPT(分享一个国内体验网站https://chatgpt.sbaliyun.com,搭建该网站的仁兄真直抒胸臆)。AIGC相关的开源项目和产品增加了很多,我在个人的网站对开源的项目进行了罗列,大家可进行访问体验 (http://yqli.tech/page/aigc.html,http://yqli.tech/page/aigc_review.html)。
出于好奇,我对以上的产品进行体验。ChatGPT的确很惊艳,生成的文字内容文案可以直接发布,一些简单的代码也可以生成,也可以回答一些领域的解决方案,但想要替换掉程序员目前还有些距离(感觉一些非技术人员总喜欢夸大其作用,有些人体验ChatGPT的后感觉不把程序员辞了不后快,不想想做文案工作不是更容易被替换掉吗?)。对于文生图,我的体验没有那么惊艳,虽然有时候可以生成精美的图片,但并不是我预期的图片内容。AIGC的最终极的皇冠还是视频生成,如果视频生成走到商业落地的程度,是否可以革了视频内容平台。接下来,提一下我体验的前段时间在抖音上很火的AIGC的应用:AI绘画。AI绘画在抖音等平台火起来不仅仅出于它可以生成各种风格的动画图,更因为它生成很多离谱的翻车图片(下边选了几张具有代表性的例子),这不仅让人怀疑这些产品是否昙花一现。最后,无论是文生图、ai绘画、数字人、chatgpt等成果的闪亮登场,都给AI行业注入新的活力,让我们期待一下2023年将会有更多闪亮AI应用可以破圈,迎接下一波的AI浪潮。


(终于到正文了~_~)
2022年12月份语音合成和语音识别 文章总结可阅读该文章https://mp.weixin.qq.com/s/uMCyEi_yL0kxJnw6WeLGcA
一 语音合成篇
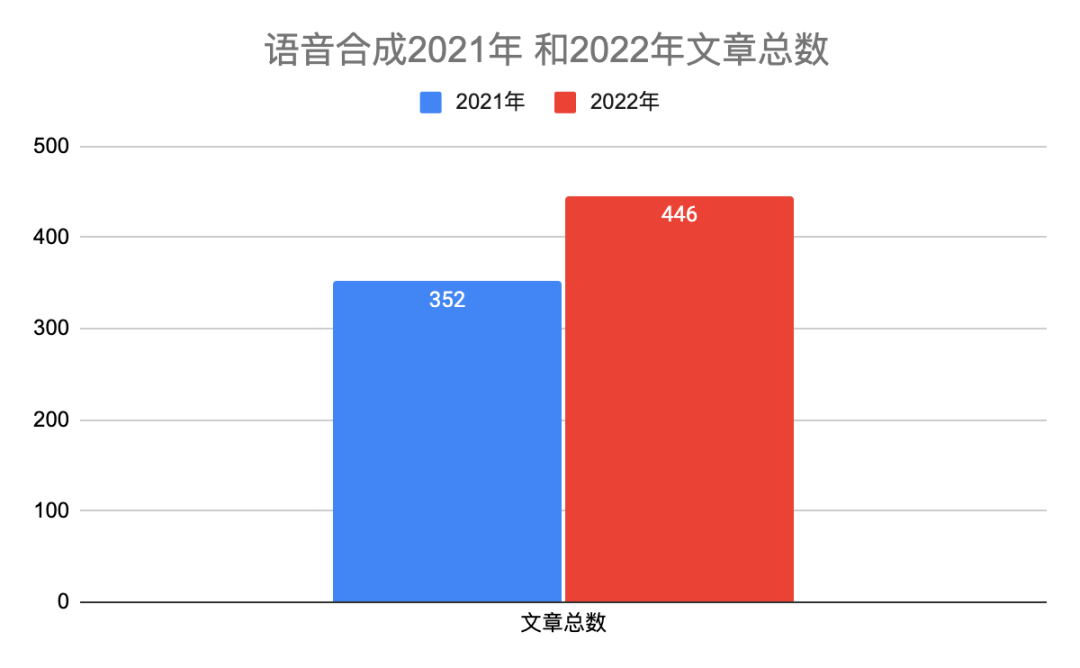
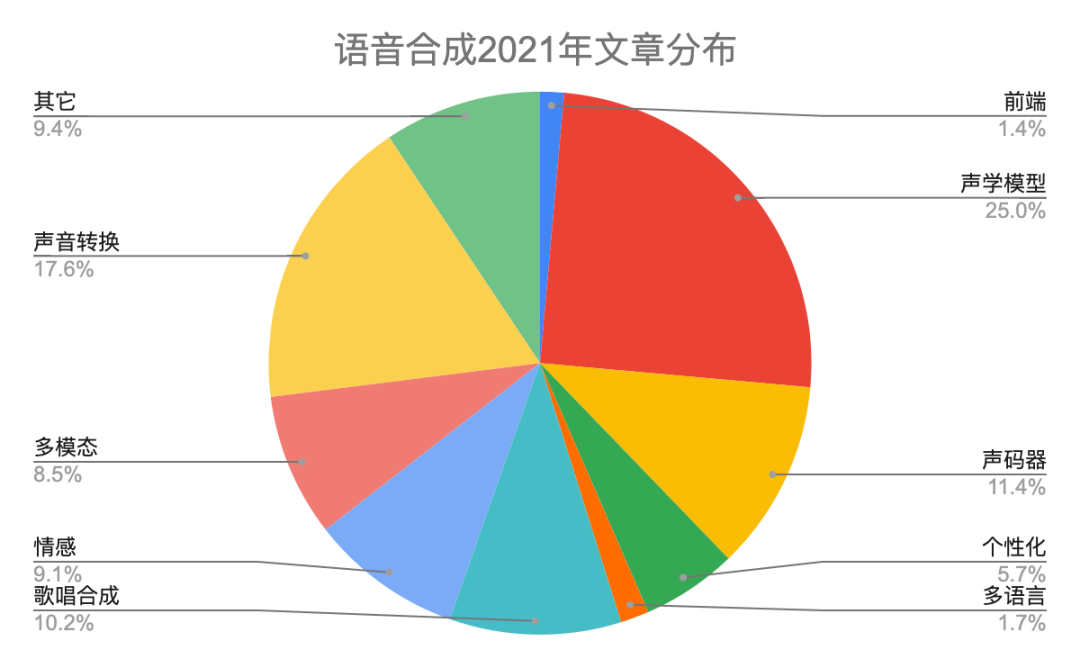
表一给出具体分类说明。2022年语音合成有446篇文章,比2021多一些。图二和图三是2022年和2021年在每个研究方向上对比柱状图和饼状图,除了声学模型网络结构和声音转换相对稍微下降,其它方向都有上升。本年度的热点主要分布在声学模型、声码器、歌唱合成、声音转换和多模态。我们知道Diffusion模型在图像领域很火,同样在语音合成领域有24篇文章采用该技术。最后,自从vits端到端以来,很多开源平台也都支持该网络,今年也有十来篇文章做端到端,比如trinitts naturalspeech等等,端到端依然会是接下来几年的研究热点。
表一 语音合成分类说明
| 分类 | 说明 |
| 多音字,韵律,g2p等等。 | |
| 声学模型 | 语言特征转声学特征,attention工作,多说话人以及双重学习 |
| 声码器 | 波形生成 |
| 个性化 | 少数据,脏数据应用等自适应 |
| 多语言和多说话人 | 多语言模型、多说话人模型 |
| 歌唱合成 | 歌唱和音乐合成 |
| 情感 | 风格和情感 |
| 多模态 | 主要搜集talking head文章 |
| 声音转换 | 基于GAN方案和特征解耦方案 |
| S2S | speech-to-speech |
| 其它 | 基于EEG合成,开源数据,MOS评测以及语音合成的应用 |
图一 2022和2021语音合成论文总量
图二 2022年和2021年语音合成各领域文章分布柱状图

图三 2022年和2021年语音合成各领域文章分布饼状图


语音合成的文章列表请访问http://yqli.tech/page/tts_paper.html

二 语音识别篇
语音识别的文章分类参照表二说明。2022年语音识别文章有641篇,由于今年刚开始统计语音识别文章,所以没有对比2021年情况。由图四和图五可知,声学模型性能优化、无监督学习、多语言系统、个性化、speech translation以及speaker diarization等领域研究较多,其中开源工具espnet、wenet、k2、paddlespeech等都搞得如火如荼 (可参见煮酒论开源语音工具包https://mp.weixin.qq.com/s/ZFD2mUAC1B6ZH5JEf5yJmg)。
表二 语音识别分类说明
| 分类 | 说明 |
| general | 包括传统、混合语音识别,以及对asr的优化 |
| ctc | ctc优化 |
| rnn-t | rnn-t的优化 |
| aed | aed优化 |
| dataset | 开源数据库 |
| data aug | 数据增广 |
| lm | 语言模型研究 |
| multilingual | 多语音系统以及code-switch |
| personal | 少数据量自适应以及个性化ASR |
| rescoring | 多种模型联合打分 |
| unsupervised | 无监督,半监督或者自监督学习 |
| accent ,dialect | 口音和方言 |
| other | 其它方向研究,包括系统评价标准等等 |
| robust | 鲁棒性 |
| speaker diarization | speaker diarization |
| multichannel | 多通道 |
| speech translation | 语音翻译 |
| multi-modal | 多模态 |
图四 语音识别文章分布柱状图(单位:篇)

图五 语音识别文章分布饼状图

语音识别的文章列表请访问http://yqli.tech/page/asr_paper.html

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 0
0 0
0- 0



 已为社区贡献53条内容
已为社区贡献53条内容

所有评论(0)