wenet实战系列-双声道音频语音识别
双声道音频语音识别demo,ASR模型使用wenet,VAD模型使用WebRTC VAD,可用于客服电话场景等
·
本文介绍如何对双声道音频进行语音识别,可以在通话场景下使用,如客服通话、电话录音等。asr模型选择wenet,vad模型选择WebRTC VAD,并给出一个简单实现的demo: Dual_Audio_ASR_Demo
背景介绍
在我们日常生活中,语音通话是必不可少的,外卖送餐、微信电话、各类客服投诉的渠道,很多都是通过电话,而通过电话产生的音频往往分为主叫和被叫两个通道,一般我们在处理该类音频时会存储为双声道的音频,这有几个好处:
- 与数据产生方式相同
- 不需要进行人声分离,方便处理
将音频保存下来之后,接下来就是语音识别处理部分。
数据分析
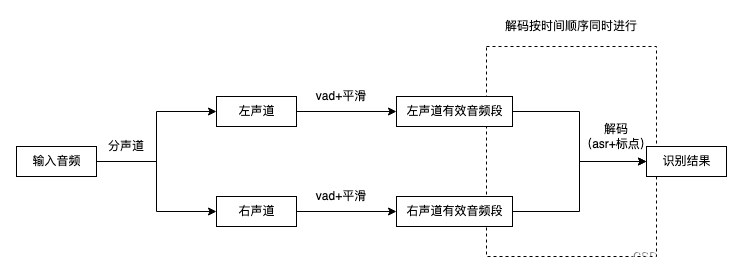
- 音频为左右双声道,因此在处理时需要分别识别左声道和右声道两个音频
- 输出时需要按照语序排列,形成一个对话,因此需要vad模块对两个声道都进行语音分割
- 对vad模块识别为1的音频片段进行语音识别
流程图
结果展示
结果进行了脱敏以及删减
{"channel_id": 1, "text": "喂", "start_time": 0, "end_time": 540}
{"channel_id": 0, "text": "喂,你好。", "start_time": 920, "end_time": 2680}
{"channel_id": 0, "text": "你那个到那个南海的啊。", "start_time": 3860, "end_time": 6380}
{"channel_id": 1, "text": "我是到南海啊,不是到南海的话。", "start_time": 8220, "end_time": 11700}
{"channel_id": 0, "text": "对啊,我知道啊。", "start_time": 12020, "end_time": 13060}
实现方法
语音读取
使用librosa分别读取左右声道音频
audio, sr = librosa.load(音频路径, sr=16000, mono=False)
左声道音频 = audio[0]
右声道音频 = audio[1]
语音分割
使用webrtcvad对每一帧进行端点检测,然后将有效声音段拼接,这里可以加入平滑操作,使分割效果更好
vad = webrtcvad.Vad(2)
vad_list = []
for frame in frames:
is_speech = vad.is_speech(frame, sample_rate=sr)
vad_list.append(is_speech)
语音识别
经过上述步骤后我们得到了两个声道的语音分割结果vad_list,接下来我们对有效帧片段进行语音识别,得到asr识别结果。
如某个vad_list=[1,1,1,1,1,0,0,0,1,1,1],我们就对连续的有效帧进行拼接得到两个需要识别的片段[1,1,1,1,1]和[1,1,1],然后使用wenet对这两个片段进行识别,就得到一个声道的语音识别结果。最后将两个声道的识别结果按时间顺序输出排列即可得到最终结果
# 有效帧片段语音识别
decoder = wenet.Decoder(lang='chs', model_dir=wenet模型地址)
# 记有效帧起始帧位置为start,结束帧位置为end
valid_frame = frames[start:end]
asr_result = decoder.decode(valid_frame)
TODO
- 完成demo,包含基础识别功能,不包含一些优化
- 画一个流程图

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)