
DeepLabv3+:经典语义分割方法DeepLabv3的升级版本
语义分割经典算法DeepLabv3的升级版。代码已开源。
分享谷歌在ECCV2018上发表的一篇语义分割的论文——DeepLabv3+,这是DeepLabv3的升级版本。
开源代码地址:
● Tensorflow版本:https://github.com/tensorflow/models/tree/master/research/deeplab
● Pytorch版本:https://github.com/open-mmlab/mmsegmentation/tree/master/configs/deeplabv3plus

1.动机
语义分割是计算机视觉领域中非常重要的任务之一,语义分割的目的是为图像中的每个像素分配标签。相比于传统方法,以深度学习为基础的全卷积网络极大地提高了语义分割算法的性能。
在语义分割网络中,常用到如下2种结构:
- 空间金字塔池化(spatial pyramid pooling,简称SPP)模块,如下图所示,SPP模块能够通过池化操作提取丰富的上下文信息,DeepLabv3使用了类似的模块。

- Encoder-Decoder结构,如下图所示,该结构能够提取丰富的边界细节特征。

作者认为,DeepLabv3使用的空洞卷积能够在提取全局上下文特征的同时,将feature map保持在比较大的尺寸上,从而保留空间细节信息。然而,由于DeepLabv3中最小的feature map尺寸一般为输入图像尺寸的1/4或1/8,导致较大的显存占用和计算量。这种现象在层数较多的网络中更为明显。
与之相比,Encoder-Decoder结构的计算效率更高,而且Decoder便于恢复空间细节信息。
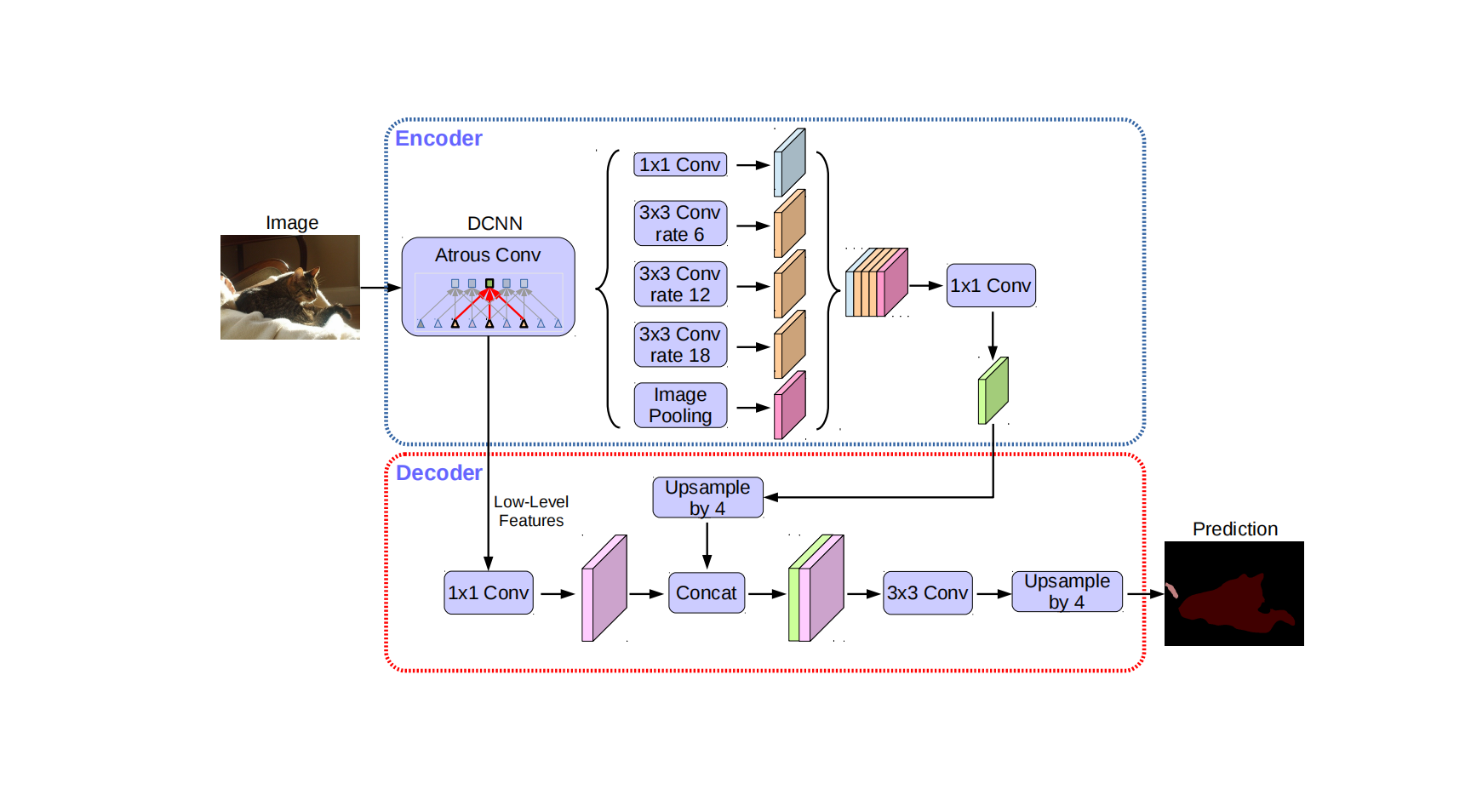
作者提出了DeepLabv3+,该网络将SPP模块和Encoder-Decoder结构融合,在Encoder中引入SPP模块,能使Encoder-Decoder结构提取多尺度的上下文特征。
2.DeepLabv3+
2.1 深度可分离空洞卷积
空洞卷积 能通过调整感受野提取不同尺度的特征,同时还能控制输出feature map的尺寸。空洞卷积的公式如下:
y [ i ] = ∑ k x [ i + r ⋅ k ] w [ k ] \boldsymbol{y}[\boldsymbol{i}]=\sum_{\boldsymbol{k}} \boldsymbol{x}[\boldsymbol{i}+r \cdot \boldsymbol{k}] \boldsymbol{w}[\boldsymbol{k}] y[i]=∑kx[i+r⋅k]w[k]
在上式中, x \boldsymbol{x} x表示输入feautre map, y \boldsymbol{y} y表示输出feature map, y [ i ] \boldsymbol{y}[\boldsymbol{i}] y[i]表示输出featrue map中某个位置处的值。 r r r表示空洞系数,即卷积核在输入feature map上的采样步长。当 r = 1 r=1 r=1时,上式表示普通卷积操作,因此,空洞卷积是普通卷积的一般性拓展。
深度可分离卷积(depthwise separable convolution) 将一个普通的卷积操作分解为depthwise卷积和pointwise卷积,以降低计算量。depthwise卷积负责每个单独通道的空间特征提取,pointwise卷积负责跨通道的特征融合,如下图所示:

作者将空洞卷积和深度可分离卷积融合,得到空洞分离卷积(atrous separable convolution),能够在保证一定性能的同时极大地减少计算量。空洞分离卷积的结构如下图所示,图中的空洞系数 r = 2 r=2 r=2。

2.2 使用DeepLabv3作为Encoder
DeepLabv3中的ASPP(atrous Spatial Pyramid Pooling)通过不同空洞系数的空洞卷积在多个尺度上提取特征。通过使用空洞卷积代替 s t r i d e = 2 stride=2 stride=2的卷积操作,DeepLabv3的输出feature map尺寸是输入图像尺寸的1/8或1/16。
作者将DeepLabv3中输出分割结果的部分删掉,其余部分作为Encoder结构。Encoder结构能够提取丰富的语义特征,该结构中最后一个卷积层输出256个通道的特征。根据可用计算资源的多少,可以灵活调整Encoder输出feature map的尺寸。
2.3 Decoder
若令DeepLabv3的输出feature map尺寸是输入图像尺寸的1/16,一个原始的做法是将DeepLabv3输出的feature map进行16倍上采样,作为最终的分割结果,显然这种简单的上采样方式并不能够成功地恢复出空间细节信息。因此作者在DeepLabv3后面增加了Decoder模块,如下图所示:
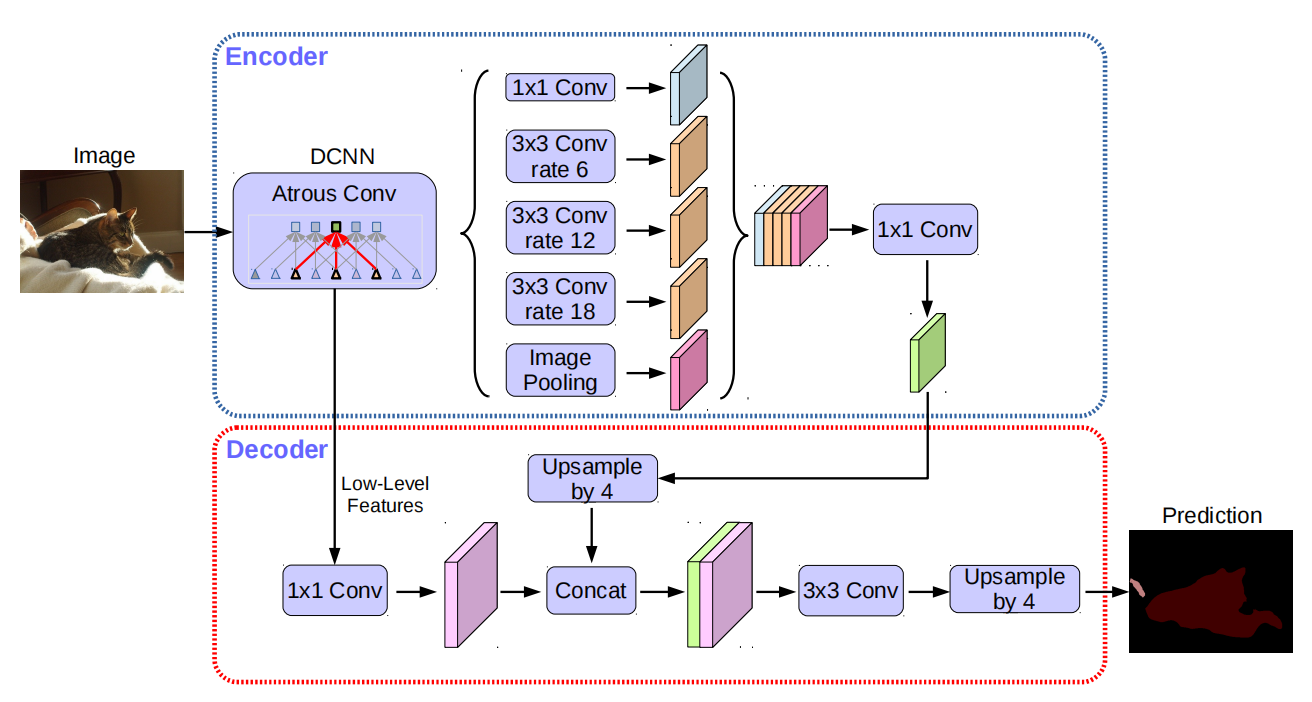
Decoder可以分为3部分:
(1)获取Encoder中间的低层次特征,并且使用 1 × 1 1 \times 1 1×1卷积降低通道数。
(2)获取Encoder最终输出的feature map,进行4倍上采样,将上采样结果与低层次特征通过concat操作融合。
(3)使用 3 × 3 3 \times 3 3×3卷积对融合结果进行平滑,然后经过4倍上采样得到最终结果。
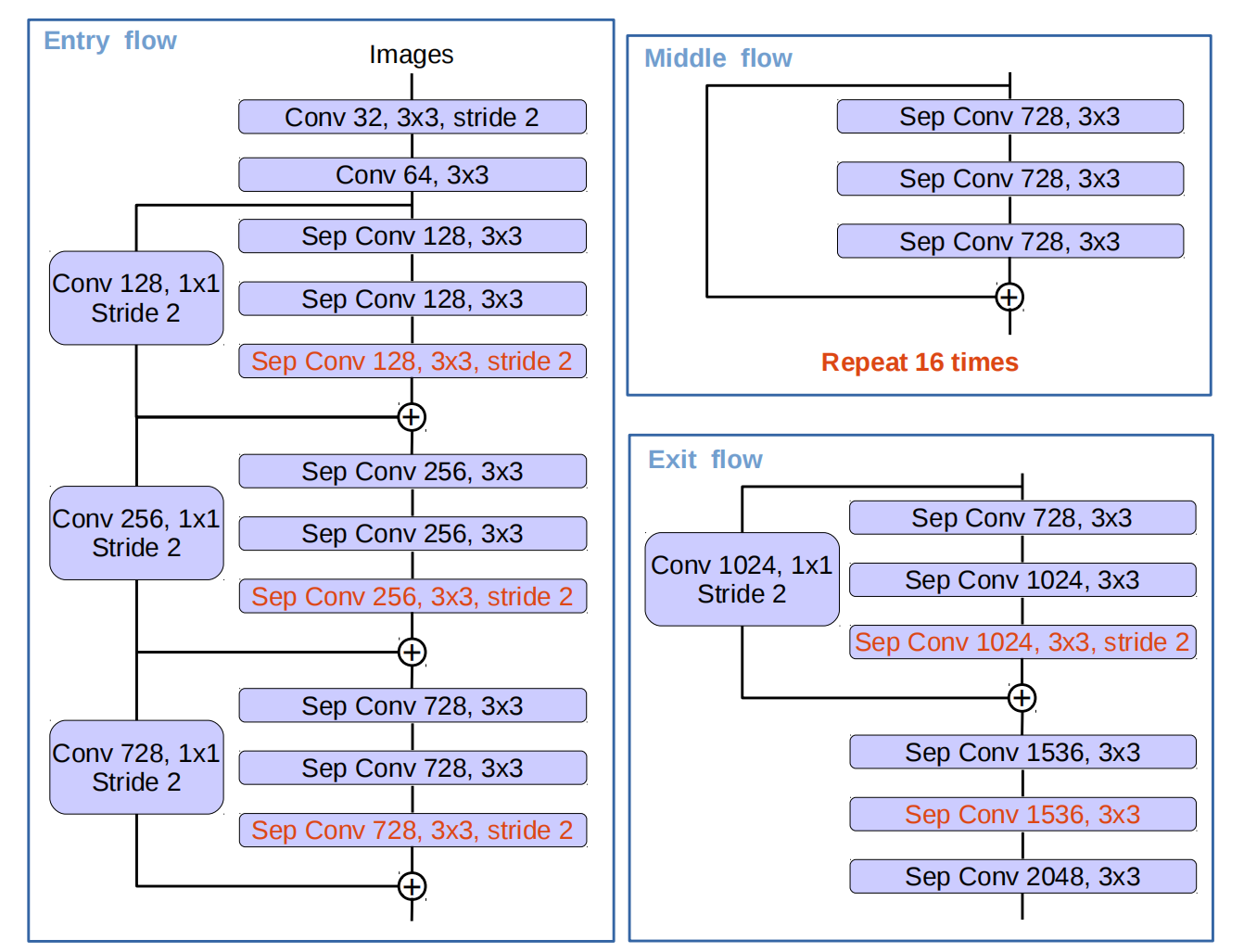
3.使用改进的Xception作为Backbone
作者使用了改进的Xception结构作为Encoder的Backbone,该结构如下图所示。在Xception的基础上,作者做了如下改进:
(1)使用更多的卷积,使得网络更深。
(2)使用 s t r i d e = 2 stride=2 stride=2的深度可分离卷积代替max pooling操作。
(3)借鉴MobileNet,在 3 × 3 3 \times 3 3×3的depthwise卷积后增加BN和ReLU操作。
4.实验结果
4.1 训练
Backbone预训练 改进的Xception网络在ImageNet-1k数据集上进行预训练
学习率设置 使用poly学习率衰减策略,每次迭代的学习率是初始学习率乘以 ( 1 − iter max_iter ) power \left(1-\frac{\text { iter }}{\text { max\_iter }}\right)^{\text {power }} (1− max_iter iter )power ,power的值为0.9,初始学习率为0.007。
数据增强 在训练时使用了随机缩放、水平随机翻转进行数据增强。
BN的学习 为了提高BN中参数的学习效果,需要令batch size大一些,因此刚开始训练时,令output_stride=16,减少网络的显存占用,以提高训练的batch size。训练一段时间后,固定BN的参数,令output_stride=8继续训练。需要特别指出的是,output_stride值为16到8的切换,是通过用空洞卷积代替下采样操作实现的,而空洞卷积只是在普通卷积的卷积核中增加0,因此仍然可以复用普通卷积的可学习参数,不会引入额外的可学习参数。
4.2 结果
DeepLabv3+在VOC2012测试集上的结果如下,下表中最后一行表示Backbone在ImageNet-1k和JFT-300M这2个数据集上进行预训练。

关于实验设置细节、消融实验以及DeepLabv3+在Cityscapes数据集上的性能,请参考原文。

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)