
python数据挖掘系列(一)
python数据挖掘系列(一)

一:python数据分析课程介绍
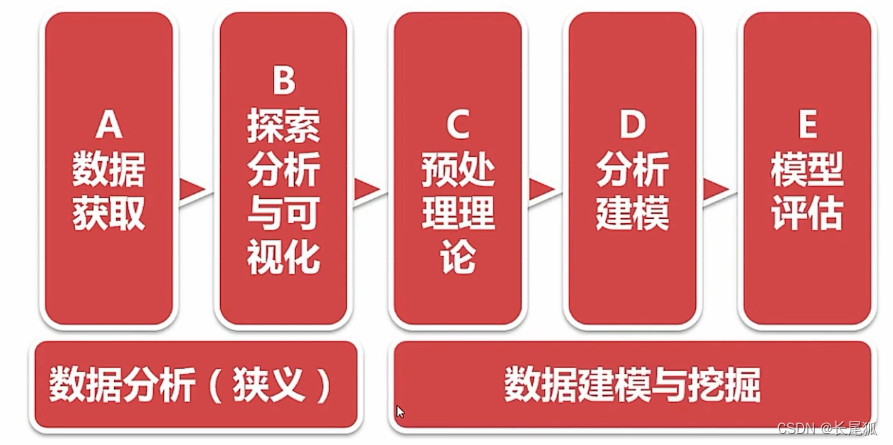
1.数据挖掘流程:
数据获取——探索分析——预处理——挖掘建模——模型评估
2.课程内容
3.课程注意点
(1)基础数学知识
(2)前置知识:python
(3)环境
python3.6.3
pycharm
annaconda5.0.1这里面都包含了(选择python3.6的版本)
二、数据分析概述:
1.用pandas包导入数据:
import pandas as pd
df=pd.read_csv("./data/HR_comma_sep.csv") #导入csv文件
df.mean() #查看均值
df["satisfaction_level"].median() #查看某一列众数
df.quantile(q=0.25) #分位数 上下四分位数可以监测是否有异常值
df.mode()
df.std()
df.var()
df.sum() #查看各种参数
df.skew()
df.kurt()
df.max()
df.min()
import scipy.stats as ss
ss.norm #创建正态分布
ss.norm.pdf(0.0) #查看正态分布中的某一个点
ss.norm.pdf(1.0) #查看积分性质
ss.norm.ppf(0.995) #查看积分性质
import numpy as np
sl_s=df["satisfaction_level"] #抽取其中一行
sl_s.isnull() #检验数据中有无null
sl_s[sl_s.isnull()] #列出数据中的null行
df[df["satisfaction_level"].isnull()] #列出数据中的null行
sl_s=sl_s.fillna() #将数据行中的null行用数据替代
sl_s=sl_s.dropna() #将数据行中的null行直接剔除
################################################################################
2.进行分布特性的初步分析
#按照0.0~0.1~1.0分段统计数量的多少
np.histogram(sl_s.values,bins=np.arange(0.0,1.1,0.1))
运行结果
Out[39]:
(array([ 195, 1214, 532, 974, 1668, 2146, 1972, 2074, 2220, 2004], dtype=int64),
array([ 0. , 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1. ]))
3.进行离群值的去除
ls_e=df["last_evaluation"]
q_low=le_s.quantile(q=0.25)
q_high=le_s.quantile(q=0.75)
q_interval=q_high-q_low
k=1.5
三:数据可视化管理
1.python可视化工具
其中matplotlib是用来初步绘图的
以及seaborn是基于matplotlib的封装,用来进一步美化图像的
以及plotly可以将图像直接用于网页中
关于pandas分组的操作,参考以下链接:Pandas分组(GroupBy) - Pandas教程 (yiibai.com)
2.代码实战
2.1 显示柱状图
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
df = pd.read_csv("./data/HR_comma_sep.csv")
plt.bar(np.arange(len(df["salary"].value_counts())),df["salary"].value_counts())
plt.show()
理解:
(1)其中 df["salary"].value_counts() 是一个计数函数,会生成一个二维数组
当调用 df["salary"].value_counts()会出现以下结果
low 7316
medium 6446
high 1237
Name: salary, dtype: int64
当调用 df["salary"].value_counts().index 会出现以下结果
Index(['low', 'medium', 'high'], dtype='object')
(2)而 len(df["salary"].value_counts()) 会对数组进行计数,结果为3
(3)np.arange(len(df["salary"].value_counts())) 会形成一个顺序数列,作为直方图的横坐标
2.2 柱状图标注参数
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
df = pd.read_csv("./data/HR_comma_sep.csv")
sns.set_style(style="white")
sns.set_context(context="poster",font_scale=0.8)
sns.set_palette([sns.color_palette("RdBu",n_colors=7)[2]])
plt.title("SALARY")
plt.xlabel("salary")
plt.ylabel("Number")
plt.xticks(np.arange(len(df["salary"].value_counts()))+0.5,df["salary"].value_counts().index())
# 添加纵坐标标注
plt.axis([0, 4, 0, 10000]) # 横轴最小值 横轴最大值 纵轴最小值 纵轴最大值
plt.bar(np.arange(len(df["salary"].value_counts()))+0.5, df["salary"].value_counts(), width=0.5)
for x,y in zip(np.arange(len(df["salary"].value_counts()))+0.5,df["salary"].value_counts()):
plt.text(x,y,y,ha="center",va="bottom")
plt.show()
或者直接用seaborn绘制
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
df = pd.read_csv("./data/HR_comma_sep.csv")
sns.set_style(style="white")
sns.set_context(context="poster",font_scale=0.8)
sns.set_palette(sns.color_palette("RdBu",n_colors=7))
sns.countplot(x="salary",data=df)
plt.show()
2.3 用seaborn绘制直方图
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
df = pd.read_csv("./data/HR_comma_sep.csv")
sns.set_style(style="white")
sns.set_context(context="poster", font_scale=0.8)
sns.set_palette(sns.color_palette("RdBu", n_colors=7))
f = plt.figure() # 建立一个figure
f.add_subplot(1, 3, 1) # 建立子图1
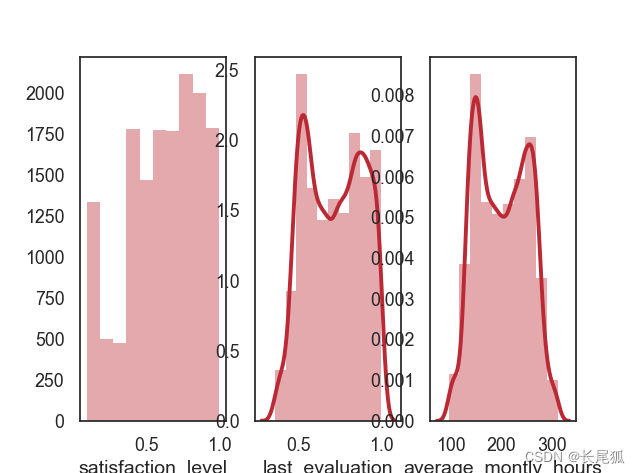
sns.distplot(df["satisfaction_level"], bins=10, kde=False)
f.add_subplot(1, 3, 2) # 建立子图2
sns.distplot(df["last_evaluation"], bins=10, kde=True)
f.add_subplot(1, 3, 3) # 建立子图3
sns.distplot(df["average_montly_hours"], bins=10, kde=True)
# bins表示分成10个等级,kde表示趋势线,hist表示矩形
plt.show()
运行结果:
2.4 箱线图
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
df = pd.read_csv("./data/HR_comma_sep.csv")
sns.set_style(style="white")
sns.set_context(context="poster", font_scale=0.8)
sns.set_palette(sns.color_palette("RdBu", n_colors=7))
g = plt.figure()
g.add_subplot(1, 2, 1) # 建立子图1
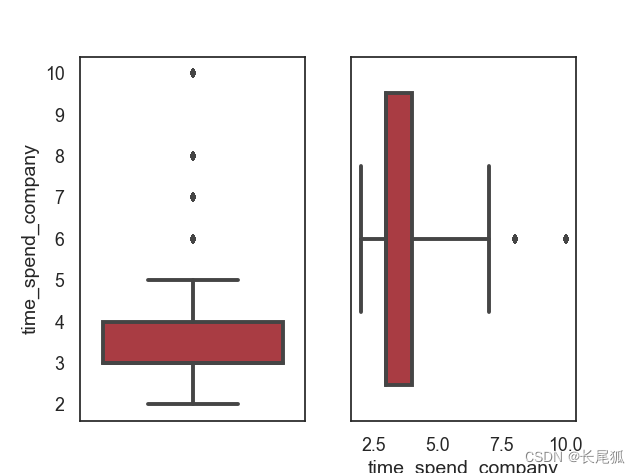
sns.boxplot(y=df["time_spend_company"])
g.add_subplot(1, 2, 2) # 建立子图2
sns.boxplot(x=df["time_spend_company"], saturation=0.75, whis=3)
# 其中x,y代表方向,saturation代表上四分位数,whis 代表上界
plt.show()
运行结果:
2.5 折线图
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
df = pd.read_csv("./data/HR_comma_sep.csv")
sns.set_style(style="white")
sns.set_context(context="poster", font_scale=0.8)
sns.set_palette(sns.color_palette("RdBu", n_colors=7))
sub_df = df.groupby("time_spend_company").mean()
# groupby 的作用是分组,按照 groupby 的数值将数据分成不同的组
# 该项操作将数据按照"time_spend_company"进行分类然后求取平均值
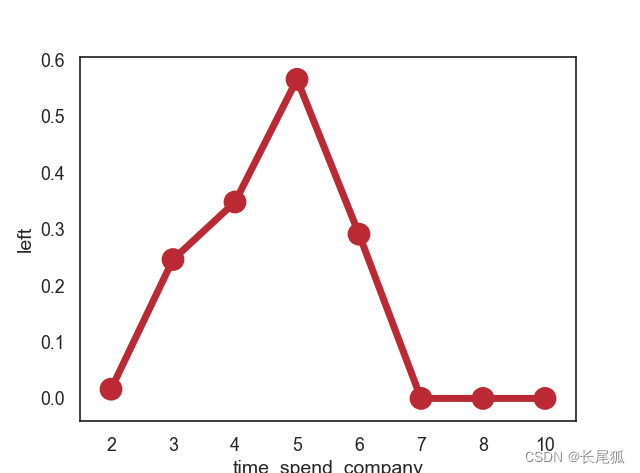
sns.pointplot(sub_df.index, sub_df["left"])
plt.show()
其中,print(sub_df)输出结果如下:
time_spend_company
2 0.016338
3 0.246159
4 0.348064
5 0.565513
6 0.291086
7 0.000000
8 0.000000
10 0.000000
运行结果如下:
或者直接采用:
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
df = pd.read_csv("./data/HR_comma_sep.csv")
sns.set_style(style="white")
sns.set_context(context="poster", font_scale=0.8)
sns.set_palette(sns.color_palette("RdBu", n_colors=7))
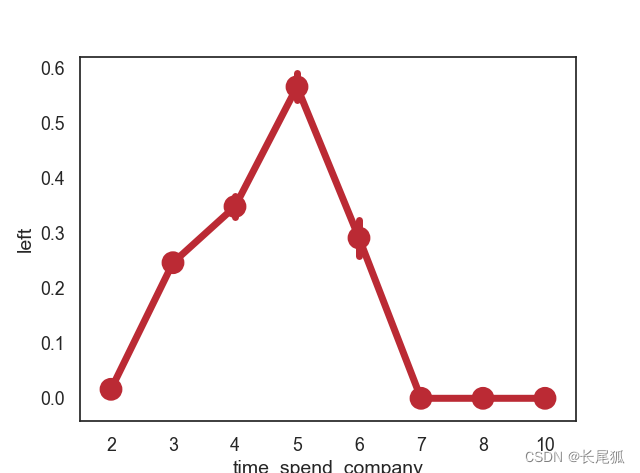
sns.pointplot(x="time_spend_company", y="left", data=df)
plt.show()
运行结果如下:

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐



 0
0 0
0- 0


 已为社区贡献1条内容
已为社区贡献1条内容










 服务器0元试用
服务器0元试用
所有评论(0)