OpenEuler上下游分析项目-开发人员测试
我们的项目是:OpenEuler上下游分析。
·
我们的项目是:OpenEuler上下游分析
- 注:本文为开发人员测试并演示项目的使用流程,具体操作指南请您移步用户使用手册,本文也可参考查看。
1、上游数据分析
上游分析工作分为两数据爬取和数据分析。
-
数据爬取
首先运行/code/UpStream/crawler.py,即爬虫文件,此代码中的URL链接是Index of /openEuler-20.03-LTS/source/repodata/,
 爬取后,目标文件出现在
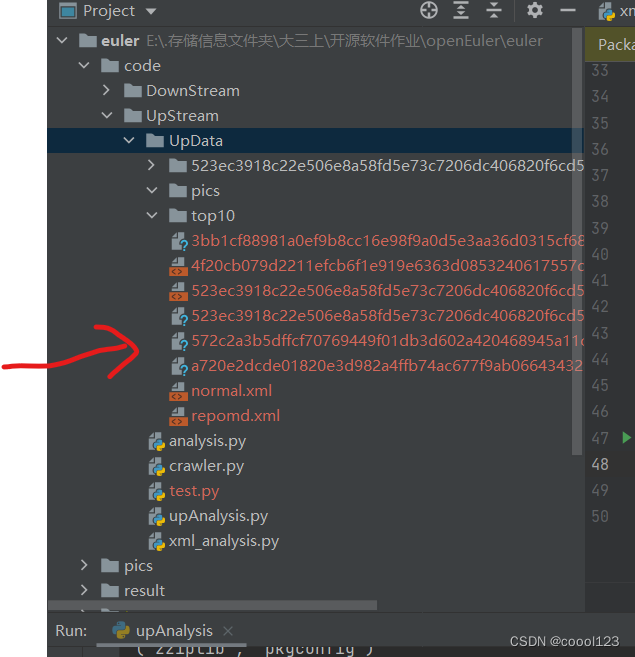
爬取后,目标文件出现在/code/UpStream/UpData,即如图所示的位置(上面两个文件不是)。
-
数据分析
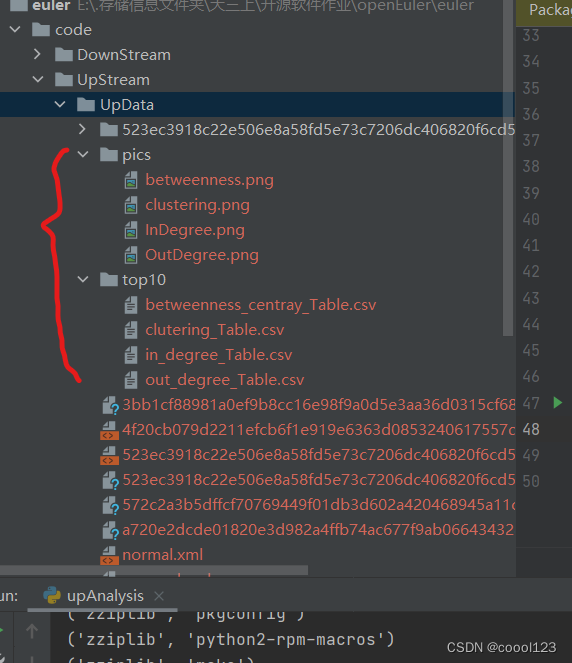
直接运行/code/UpStream/upAnalysis.py,可以得到结果:4个.csv和4张图像,它们分别存放在/code/UpStream/UpData/top10和/code/UpStream/UpData/pics,如图:
2、下游数据分析
下游数据分也包括数据爬取和分析两部分。
- 数据爬取
运行/code/DownStream/OpenEuler_Crawler.py中的main(),注意:
if __name__ == '__main__':
main()
# repo()
- 爬取结果保存在了该文件夹下的result.html,效果如下:
- 在
/code/DownStream/html_parser.py,将main()函数中的filename修改为:result.html,并运行parse(doc),注意:
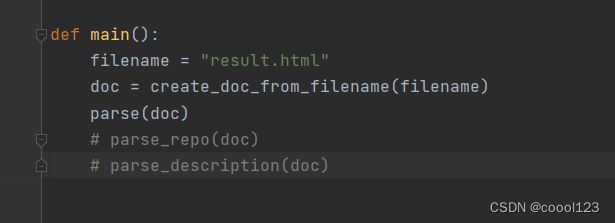
得到OpenEuler_repo.csv文件。 - 然后在修改
/code/DownStream/OpenEuler_Crawler.py,运行repo()函数,注意:
if __name__ == '__main__':
# main()
repo()
-
运行中,不断reading

-
爬取每一个仓库页面,保存到repo_result.html中,该过程的时间较长。
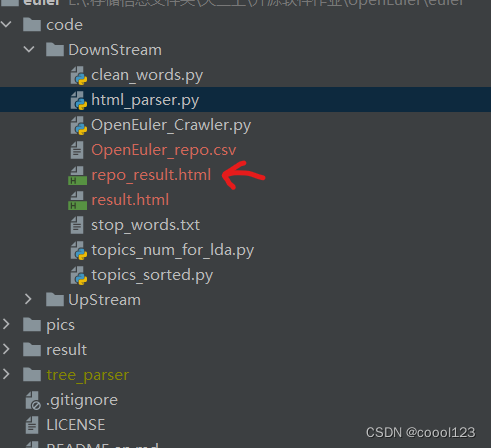
-
回到
/code/DownStream/html_parser.py,将main()函数中的filename修改为:repo_result.html,并运行parse_repo(doc),得到OpenEuler_description.csv,注意:
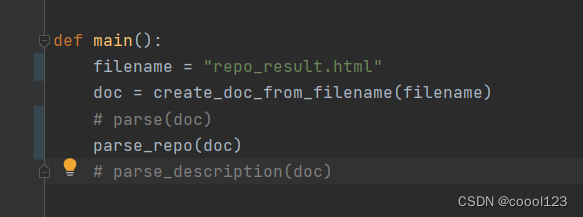
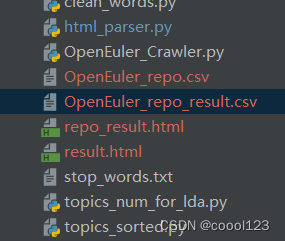
-
接着,运行
parse_description(doc),即可得到OpenEuler_description.csv,存放了所有仓库的描述。
- 分析过程
- 进入
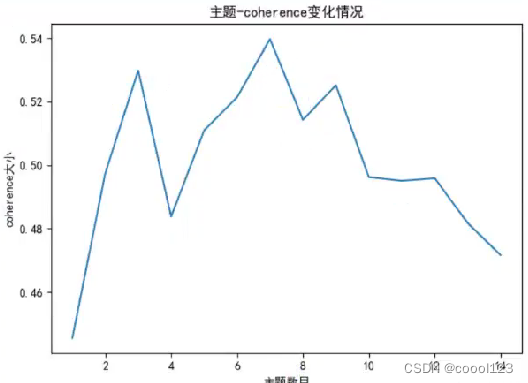
/code/DownStream/topics_num_for_lda.py,运行draw()函数,得到推荐的主题数7。
填入代码:
lda = LdaModel(corpus=corpus, id2word=dictionary, num_topics=7, passes=30, random_state=1)
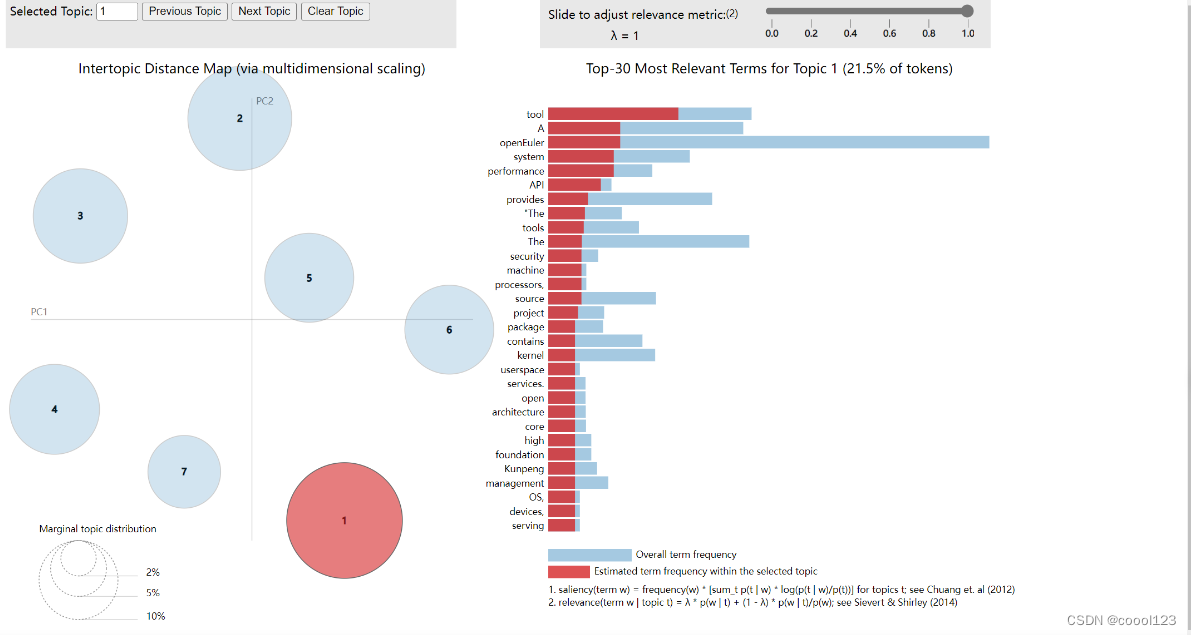
- 运行
build()函数,查看网页即可。
以上即为完整的测试流程,可供参考。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)