HA RabbitMQ on K8s helm部署实战
将需要消费的队列变为镜像队列,存在于多个节点,这样就可以实现 RabbitMQ 的 HA 高可用性。该模式带来的副作用也很明显,除了降低系统性能外,如果镜像队列数量过多,加之大量的消息进入,集群内部的网络带宽将会被这种同步通讯大大消耗掉。MQ 中的消息消费的时候是会先加载到内存中的,接受消息的时候同样也会。镜像节点在集群中的其他节点拥有从队列拷贝,一旦主节点不可用,最老的从队列将被选举为新的主队列
RabbitMQ on K8s helm部署实战
获取helm chart
chart选择bitnami公司制作的。
找一台有外网的机器
1、helm repo add bitnami https://charts.bitnami.com/bitnami
"bitnami" has been added to your repositories
2、helm pull bitnami/rabbitmq
⚡ root@localhost ~ ll
-rw-r--r--. 1 root root 54K Oct 11 17:38 rabbitmq-10.3.9.tgz
修改必要参数
-
image
10.50.10.185/rabbitmq/docker.io/bitnami/rabbitmq:3.10.8-debian-11-r4
10.50.10.185/kafka/docker.io/bitnami/bitnami-shell:11-debian-11-r22
-
storageClass 使用nfs存储类
-
persistence.mountPath 默认的持久化存储/bitnami/rabbitmq/mnesia
外部如何访问?
默认使用的clusterIP,只能在集群内部使用,如何暴露在内网局域网使用呢?
只需要将我们ap使用的amqp和管理界面的端口进行nodeport暴露即可。
## Service ports
## @param service.ports.amqp Amqp service port
## @param service.ports.amqpTls Amqp TLS service port
## @param service.ports.dist Erlang distribution service port
## @param service.ports.manager RabbitMQ Manager service port
## @param service.ports.metrics RabbitMQ Prometheues metrics service port
## @param service.ports.epmd EPMD Discovery service port
##
ports:
amqp: 5672
amqpTls: 5671
dist: 25672
manager: 15672
metrics: 9419
epmd: 4369
## Node ports to expose
## @param service.nodePorts.amqp Node port for Ampq
## @param service.nodePorts.amqpTls Node port for Ampq TLS
## @param service.nodePorts.dist Node port for Erlang distribution
## @param service.nodePorts.manager Node port for RabbitMQ Manager
## @param service.nodePorts.epmd Node port for EPMD Discovery
## @param service.nodePorts.metrics Node port for RabbitMQ Prometheues metrics
##
nodePorts:
amqp: "30100"
amqpTls: ""
dist: ""
manager: "30101"
metrics: "30102"
epmd: ""
安装rabbitmq
安装完毕后会有如下提示,根据提示可以尝试访问访问amqp和manager管理界面.
/opt/helm/rabbitmq]#helm install chot-rabbitmq -n rabbitmq /opt/helm/rabbitmq/
NAME: chot-rabbitmq
LAST DEPLOYED: Wed Oct 12 10:16:52 2022
NAMESPACE: rabbitmq
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
CHART NAME: rabbitmq
CHART VERSION: 10.3.9
APP VERSION: 3.10.8** Please be patient while the chart is being deployed **
Credentials:
echo "Username : user"
echo "Password : $(kubectl get secret --namespace rabbitmq chot-rabbitmq -o jsonpath="{.data.rabbitmq-password}" | base64 -d)"
echo "ErLang Cookie : $(kubectl get secret --namespace rabbitmq chot-rabbitmq -o jsonpath="{.data.rabbitmq-erlang-cookie}" | base64 -d)"
Note that the credentials are saved in persistent volume claims and will not be changed upon upgrade or reinstallation unless the persistent volume claim has been deleted. If this is not the first installation of this chart, the credentials may not be valid.
This is applicable when no passwords are set and therefore the random password is autogenerated. In case of using a fixed password, you should specify it when upgrading.
More information about the credentials may be found at https://docs.bitnami.com/general/how-to/troubleshoot-helm-chart-issues/#credential-errors-while-upgrading-chart-releases.
RabbitMQ can be accessed within the cluster on port 15673 at chot-rabbitmq.rabbitmq.svc.cluster.local
To access for outside the cluster, perform the following steps:
Obtain the NodePort IP and ports:
export NODE_IP=$(kubectl get nodes --namespace rabbitmq -o jsonpath="{.items[0].status.addresses[0].address}")
export NODE_PORT_AMQP=$(kubectl get --namespace rabbitmq -o jsonpath="{.spec.ports[?(@.name=='amqp')].nodePort}" services chot-rabbitmq)
export NODE_PORT_STATS=$(kubectl get --namespace rabbitmq -o jsonpath="{.spec.ports[?(@.name=='http-stats')].nodePort}" services chot-rabbitmq)
To Access the RabbitMQ AMQP port:
echo "URL : amqp://$NODE_IP:$NODE_PORT_AMQP/"
To Access the RabbitMQ Management interface:
echo "URL : http://$NODE_IP:$NODE_PORT_STATS/"
To access the RabbitMQ Prometheus metrics, get the RabbitMQ Prometheus URL by running:
kubectl port-forward --namespace rabbitmq svc/chot-rabbitmq 19419:19419 &
echo "Prometheus Metrics URL: http://127.0.0.1:19419/metrics"
Then, open the obtained URL in a browser.
也可以在安装时指定登录dashboard的账密
helm install chot-rabbitmq -n rabbitmq --set auth.username=admin,auth.password=admin@mq /opt/helm/rabbitmq/
登录管理界面
http://10.50.10.31:30101/#/
首次登录如果没有指定账密则使用如下命令获取:
echo "Username : user"
echo "Password : $(kubectl get secret --namespace rabbitmq chot-rabbitmq -o jsonpath="{.data.rabbitmq-password}" | base64 -d)"

导入mq metadata
将测试区mq的定义导入新集群

优化
如果需要对rabbitmq 在k8s上的细节,分析helm chart 生成的yaml文件是一个好的途径。
helm chart 生成的statefuleset yaml
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
annotations:
meta.helm.sh/release-name: chot-rabbitmq
meta.helm.sh/release-namespace: rabbitmq
labels:
app.kubernetes.io/instance: chot-rabbitmq
app.kubernetes.io/managed-by: Helm
app.kubernetes.io/name: rabbitmq
helm.sh/chart: rabbitmq-10.3.9
name: chot-rabbitmq
namespace: rabbitmq
resourceVersion: '36898567'
spec:
podManagementPolicy: OrderedReady
replicas: 2
revisionHistoryLimit: 10
selector:
matchLabels:
app.kubernetes.io/instance: chot-rabbitmq
app.kubernetes.io/name: rabbitmq
serviceName: chot-rabbitmq-headless
template:
metadata:
annotations:
checksum/config: 6bab8ac30e6ddbabb2cd23a7f08cba082380b36d7bbdaebd2b2b72b4a8c77b8b
checksum/secret: de0d40f863444485a2cc2386799625ed9afdffa30dc36fe0a2aecb5a1224ef93
prometheus.io/port: '9419'
prometheus.io/scrape: 'true'
creationTimestamp: null
labels:
app.kubernetes.io/instance: chot-rabbitmq
app.kubernetes.io/managed-by: Helm
app.kubernetes.io/name: rabbitmq
helm.sh/chart: rabbitmq-10.3.9
spec:
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- podAffinityTerm:
labelSelector:
matchLabels:
app.kubernetes.io/instance: chot-rabbitmq
app.kubernetes.io/name: rabbitmq
namespaces:
- rabbitmq
topologyKey: kubernetes.io/hostname
weight: 1
containers:
- env:
- name: BITNAMI_DEBUG
value: 'false'
- name: MY_POD_IP
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: status.podIP
- name: MY_POD_NAME
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: metadata.name
- name: MY_POD_NAMESPACE
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: metadata.namespace
- name: K8S_SERVICE_NAME
value: chot-rabbitmq-headless
- name: K8S_ADDRESS_TYPE
value: hostname
- name: RABBITMQ_FORCE_BOOT
value: 'yes'
- name: RABBITMQ_NODE_NAME
value: >-
rabbit@$(MY_POD_NAME).$(K8S_SERVICE_NAME).$(MY_POD_NAMESPACE).svc.cluster.local
- name: K8S_HOSTNAME_SUFFIX
value: .$(K8S_SERVICE_NAME).$(MY_POD_NAMESPACE).svc.cluster.local
- name: RABBITMQ_MNESIA_DIR
value: /bitnami/rabbitmq/mnesia/$(RABBITMQ_NODE_NAME)
- name: RABBITMQ_LDAP_ENABLE
value: 'no'
- name: RABBITMQ_LOGS
value: '-'
- name: RABBITMQ_ULIMIT_NOFILES
value: '65536'
- name: RABBITMQ_USE_LONGNAME
value: 'true'
- name: RABBITMQ_ERL_COOKIE
valueFrom:
secretKeyRef:
key: rabbitmq-erlang-cookie
name: chot-rabbitmq
- name: RABBITMQ_LOAD_DEFINITIONS
value: 'no'
- name: RABBITMQ_DEFINITIONS_FILE
value: /app/load_definition.json
- name: RABBITMQ_SECURE_PASSWORD
value: 'yes'
- name: RABBITMQ_USERNAME
value: guest
- name: RABBITMQ_PASSWORD
valueFrom:
secretKeyRef:
key: rabbitmq-password
name: chot-rabbitmq
- name: RABBITMQ_PLUGINS
value: >-
rabbitmq_management, rabbitmq_peer_discovery_k8s,
rabbitmq_auth_backend_ldap, rabbitmq_prometheus
image: '10.50.10.185/rabbitmq/docker.io/bitnami/rabbitmq:3.10.8-debian-11-r4'
imagePullPolicy: IfNotPresent
lifecycle:
preStop:
exec:
command:
- /bin/bash
- '-ec'
- >
if [[ -f /opt/bitnami/scripts/rabbitmq/nodeshutdown.sh ]];
then
/opt/bitnami/scripts/rabbitmq/nodeshutdown.sh -t "120" -d "false"
else
rabbitmqctl stop_app
fi
livenessProbe:
exec:
command:
- /bin/bash
- '-ec'
- rabbitmq-diagnostics -q ping
failureThreshold: 6
initialDelaySeconds: 120
periodSeconds: 30
successThreshold: 1
timeoutSeconds: 20
name: rabbitmq
ports:
- containerPort: 5672
name: amqp
protocol: TCP
- containerPort: 25672
name: dist
protocol: TCP
- containerPort: 15672
name: stats
protocol: TCP
- containerPort: 4369
name: epmd
protocol: TCP
- containerPort: 9419
name: metrics
protocol: TCP
readinessProbe:
exec:
command:
- /bin/bash
- '-ec'
- >-
rabbitmq-diagnostics -q check_running && rabbitmq-diagnostics
-q check_local_alarms
failureThreshold: 3
initialDelaySeconds: 10
periodSeconds: 30
successThreshold: 1
timeoutSeconds: 20
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /bitnami/rabbitmq/conf
name: configuration
- mountPath: /bitnami/rabbitmq/mnesia
name: data
dnsPolicy: ClusterFirst
initContainers:
- args:
- '-ec'
- >
mkdir -p "/bitnami/rabbitmq/mnesia"
chown "0:1001" "/bitnami/rabbitmq/mnesia"
find "/bitnami/rabbitmq/mnesia" -mindepth 1 -maxdepth 1 -not -name
".snapshot" -not -name "lost+found" | \
xargs -r chown -R "0:1001"
command:
- /bin/bash
image: '10.50.10.185/kafka/docker.io/bitnami/bitnami-shell:11-debian-11-r22'
imagePullPolicy: IfNotPresent
name: volume-permissions
resources: {}
securityContext:
runAsUser: 0
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /bitnami/rabbitmq/mnesia
name: data
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
serviceAccount: chot-rabbitmq
serviceAccountName: chot-rabbitmq
terminationGracePeriodSeconds: 120
volumes:
- name: configuration
secret:
defaultMode: 420
items:
- key: rabbitmq.conf
path: rabbitmq.conf
secretName: chot-rabbitmq-config
updateStrategy:
type: RollingUpdate
volumeClaimTemplates:
- apiVersion: v1
kind: PersistentVolumeClaim
metadata:
creationTimestamp: null
labels:
app.kubernetes.io/instance: chot-rabbitmq
app.kubernetes.io/name: rabbitmq
name: data
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 200Gi
storageClassName: nfs-storage-179sc
volumeMode: Filesystem
status:
phase: Pending
helm chart 生成的pod yaml
---
apiVersion: v1
kind: Pod
metadata:
annotations:
checksum/config: 601d28e7aba31d1937034ce699a1ab755ca9ba176e13c0033b78fcfce55d4b48
checksum/secret: d8c9218d24755350e7f93e4906bee00014b369ec3507bc7632d4cc7486b475a3
cni.projectcalico.org/containerID: 08d2ac4cb82eba9fad8d989d532e99b3e9f0390fc5b169e337de67c620861f6f
cni.projectcalico.org/podIP: 10.244.104.45/32
cni.projectcalico.org/podIPs: 10.244.104.45/32
prometheus.io/port: '9419'
prometheus.io/scrape: 'true'
generateName: chot-rabbitmq-dev-
labels:
app.kubernetes.io/instance: chot-rabbitmq-dev
app.kubernetes.io/managed-by: Helm
app.kubernetes.io/name: rabbitmq
controller-revision-hash: chot-rabbitmq-dev-95c8c5876
helm.sh/chart: rabbitmq-10.3.9
statefulset.kubernetes.io/pod-name: chot-rabbitmq-dev-1
name: chot-rabbitmq-dev-1
namespace: rabbitmq-dev
ownerReferences:
- apiVersion: apps/v1
blockOwnerDeletion: true
controller: true
kind: StatefulSet
name: chot-rabbitmq-dev
uid: 0dcbd9a1-cc16-49f5-974e-f59f88ced47c
resourceVersion: '29760134'
spec:
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- podAffinityTerm:
labelSelector:
matchLabels:
app.kubernetes.io/instance: chot-rabbitmq-dev
app.kubernetes.io/name: rabbitmq
namespaces:
- rabbitmq-dev
topologyKey: kubernetes.io/hostname
weight: 1
containers:
- env:
- name: BITNAMI_DEBUG
value: 'false'
- name: MY_POD_IP
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: status.podIP
- name: MY_POD_NAME
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: metadata.name
- name: MY_POD_NAMESPACE
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: metadata.namespace
- name: K8S_SERVICE_NAME
value: chot-rabbitmq-dev-headless
- name: K8S_ADDRESS_TYPE
value: hostname
- name: RABBITMQ_FORCE_BOOT
value: 'yes'
- name: RABBITMQ_NODE_NAME
value: >-
rabbit@$(MY_POD_NAME).$(K8S_SERVICE_NAME).$(MY_POD_NAMESPACE).svc.cluster.local
- name: K8S_HOSTNAME_SUFFIX
value: .$(K8S_SERVICE_NAME).$(MY_POD_NAMESPACE).svc.cluster.local
- name: RABBITMQ_MNESIA_DIR
value: /bitnami/rabbitmq/mnesia/$(RABBITMQ_NODE_NAME)
- name: RABBITMQ_LDAP_ENABLE
value: 'no'
- name: RABBITMQ_LOGS
value: '-'
- name: RABBITMQ_ULIMIT_NOFILES
value: '65536'
- name: RABBITMQ_USE_LONGNAME
value: 'true'
- name: RABBITMQ_ERL_COOKIE
valueFrom:
secretKeyRef:
key: rabbitmq-erlang-cookie
name: chot-rabbitmq-dev
- name: RABBITMQ_LOAD_DEFINITIONS
value: 'no'
- name: RABBITMQ_DEFINITIONS_FILE
value: /app/load_definition.json
- name: RABBITMQ_SECURE_PASSWORD
value: 'yes'
- name: RABBITMQ_USERNAME
value: guest
- name: RABBITMQ_PASSWORD
valueFrom:
secretKeyRef:
key: rabbitmq-password
name: chot-rabbitmq-dev
- name: RABBITMQ_PLUGINS
value: >-
rabbitmq_management, rabbitmq_peer_discovery_k8s,
rabbitmq_auth_backend_ldap, rabbitmq_prometheus
image: '10.50.10.185/rabbitmq/docker.io/bitnami/rabbitmq:3.10.8-debian-11-r4'
imagePullPolicy: IfNotPresent
lifecycle:
preStop:
exec:
command:
- /bin/bash
- '-ec'
- |
if [[ -f /opt/bitnami/scripts/rabbitmq/nodeshutdown.sh ]]; then
/opt/bitnami/scripts/rabbitmq/nodeshutdown.sh -t "120" -d "false"
else
rabbitmqctl stop_app
fi
livenessProbe:
exec:
command:
- /bin/bash
- '-ec'
- rabbitmq-diagnostics -q ping
failureThreshold: 6
initialDelaySeconds: 120
periodSeconds: 30
successThreshold: 1
timeoutSeconds: 20
name: rabbitmq
ports:
- containerPort: 5672
name: amqp
protocol: TCP
- containerPort: 25672
name: dist
protocol: TCP
- containerPort: 15672
name: stats
protocol: TCP
- containerPort: 4369
name: epmd
protocol: TCP
- containerPort: 9419
name: metrics
protocol: TCP
readinessProbe:
exec:
command:
- /bin/bash
- '-ec'
- >-
rabbitmq-diagnostics -q check_running && rabbitmq-diagnostics -q
check_local_alarms
failureThreshold: 3
initialDelaySeconds: 10
periodSeconds: 30
successThreshold: 1
timeoutSeconds: 20
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /bitnami/rabbitmq/conf
name: configuration
- mountPath: /bitnami/rabbitmq/mnesia
name: data
- mountPath: /var/run/secrets/kubernetes.io/serviceaccount
name: kube-api-access-x25nz
readOnly: true
dnsPolicy: ClusterFirst
enableServiceLinks: true
hostname: chot-rabbitmq-dev-1
initContainers:
- args:
- '-ec'
- >
mkdir -p "/bitnami/rabbitmq/mnesia"
chown "0:1001" "/bitnami/rabbitmq/mnesia"
find "/bitnami/rabbitmq/mnesia" -mindepth 1 -maxdepth 1 -not -name
".snapshot" -not -name "lost+found" | \
xargs -r chown -R "0:1001"
command:
- /bin/bash
image: '10.50.10.185/kafka/docker.io/bitnami/bitnami-shell:11-debian-11-r22'
imagePullPolicy: IfNotPresent
name: volume-permissions
resources: {}
securityContext:
runAsUser: 0
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /bitnami/rabbitmq/mnesia
name: data
- mountPath: /var/run/secrets/kubernetes.io/serviceaccount
name: kube-api-access-x25nz
readOnly: true
nodeName: node2
nodeSelector:
nodemq: dev
preemptionPolicy: PreemptLowerPriority
priority: 0
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
serviceAccount: chot-rabbitmq-dev
serviceAccountName: chot-rabbitmq-dev
subdomain: chot-rabbitmq-dev-headless
terminationGracePeriodSeconds: 120
tolerations:
- effect: NoExecute
key: node.kubernetes.io/not-ready
operator: Exists
tolerationSeconds: 300
- effect: NoExecute
key: node.kubernetes.io/unreachable
operator: Exists
tolerationSeconds: 300
volumes:
- name: data
persistentVolumeClaim:
claimName: data-chot-rabbitmq-dev-1
- name: configuration
secret:
defaultMode: 420
items:
- key: rabbitmq.conf
path: rabbitmq.conf
secretName: chot-rabbitmq-dev-config
- name: kube-api-access-x25nz
projected:
defaultMode: 420
sources:
- serviceAccountToken:
expirationSeconds: 3607
path: token
- configMap:
items:
- key: ca.crt
path: ca.crt
name: kube-root-ca.crt
- downwardAPI:
items:
- fieldRef:
apiVersion: v1
fieldPath: metadata.namespace
path: namespace
调整mq log等级
生产环境mq负载大,打印info层级log并没有用,建议loglevel开到error等级
extraEnvVars:
- name: LOG_LEVEL
value: error
promethrus 监控mq
bitnima已经帮我们把prometheus的监控做好了,只需要配置即可。enable即可,如果需要其他细节,例如读个实例如何处理?serviceMonitor?阅读bitnima的文档完成。


配置prometheus采集metrics
使用file_sd文件动态发现目标节点
]#cat /etc/prometheus/prometheus.yml
############################################################################
# job: rabbitmq
# path: targets/rabbitmq/*.yaml
# date: 2022-10-12
############################################################################
- job_name: rabbitmq
metrics_path: /metrics
file_sd_configs:
- refresh_interval: 10s
files: [ targets/rabbitmq/*.yml ]
]#cat /etc/prometheus/targets/rabbitmq/chot0rabbitmq.yml
- labels: { ip: 10.50.10.31 , ins: rabbitmq-1 , cls: rabbitmq }
targets: [ 10.50.10.31:30102 ]
上面的文件发现模块为何无法在首页注册一个panel呢?
修改为直接获取rabbitmq cluster name
targets: [ '10.50.10.31:30102','10.50.10.151:9090','10.50.10.152:9090','10.50.10.155:9090','10.50.10.156:9090' ]
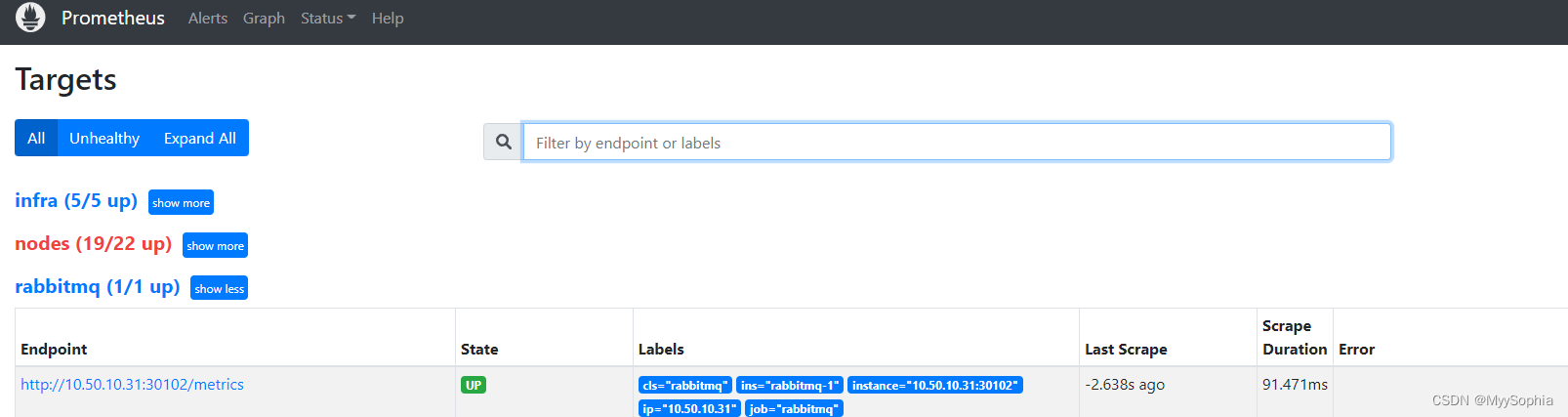
查看prometheus rabbitmq target status

单独启动rabbitmq_export
上述内容都是基于 3.8 版本及其以后的版本,对于 3.8 版本之前的版本可以使用单独的插件 prometheus_rabbitmq_exporter来暴露指标数据。该插件借助的是 RabbitMQ HTTP API来实现的。
# 1. 下载exporter
https://github.com/kbudde/rabbitmq_exporter/releases/download/v1.0.0-RC19/rabbitmq_exporter_1.0.0-RC19_linux_amd64.tar.gz
tar -zxvf rabbitmq_exporter_1.0.0-RC19_linux_amd64.tar.gz
# 2. 生成配置文件 rabbitmq.json
{
"rabbit_url": "http://127.0.0.1:15672",
"rabbit_user": "guest",
"rabbit_pass": "guest",
"publish_port": "9419",
"publish_addr": "",
"output_format": "TTY",
"ca_file": "ca.pem",
"cert_file": "client-cert.pem",
"key_file": "client-key.pem",
"insecure_skip_verify": false,
"exlude_metrics": [],
"include_exchanges": ".*",
"skip_exchanges": "^$",
"include_queues": ".*",
"skip_queues": "^$",
"skip_vhost": "^$",
"include_vhost": ".*",
"rabbit_capabilities": "no_sort,bert",
"aliveness_vhost": "/",
"enabled_exporters": [
"exchange",
"node",
"overview",
"queue",
"aliveness"
],
"timeout": 30,
"max_queues": 0
}
# 3.启动
cp rabbitmq_exporter /usr/bin/ && nohup rabbitmq_exporter -config-file conf/rabbitmq.json &
注意: 第二个不是一个二进制文件,如果是校验和那应该不至于那么大.

rabbitmq_exporter 开机自启动
os version : redhat 6.6
[root@P1QMSPL1RTM01 init.d]# more rabbitmq_exporter
#!/bin/sh
ServName=rabbitmq_exporter
PidFile=/var/run/$ServName.pid
ServPath=/usr/local/exporter/$ServName/$ServName
ServConf=/usr/local/public/$SerName.yml
if [ -f /etc/init.d/functions ]; then
. /etc/init.d/functions
fi
start() {
if [ -s $PidFile ]; then
echo "Service $ServName is running"
else
RABBIT_CAPABILITIES=nobert RABBIT_USER=guest RABBIT_PASSWORD=guest OUTPUT_FORMAT=JSON RABBIT_URL=http://localhost:15672 nohup $ServPath &
ServPid=`ps -ef | grep $ServPath | grep -v 'grep' | awk '{print $2}'`
touch $PidFile
echo $ServPid > $PidFile
echo "Starting $ServName: [ OK ]"
fi
}
stop() {
if [ -s $PidFile ]; then
cat $PidFile | xargs kill
rm -f $PidFile
echo "Stopping $ServName: [ OK ]"
else
echo "Service $ServName not running"
fi
}
case $1 in
start)
start
;;
stop)
stop
;;
restart)
stop
sleep 1
start
;;
status)
status -p $PidFile $ServName
exit $?
;;
*)
echo "Usage: /etc/init.d/$ServName {start|stop|restart|status}" >&2
;;
esac
Q深度监控
业务中对Q深度监控的需求较多,可以使用该指标进行报警。

内存优化
memoryHighWatermark.value 默认为0.4. 修改为0.85。 MQ 中的消息消费的时候是会先加载到内存中的,接受消息的时候同样也会。
增大此参数避免OOM
修改集群名称
1.查看集群名称
rabbitmq-diagnostics -q cluster_status | grep "Cluster name"
2. 修改集群名称
rabbitmqctl -q set_cluster_name cls-name
高可用方案
镜像节点在集群中的其他节点拥有从队列拷贝,一旦主节点不可用,最老的从队列将被选举为新的主队列。但镜像队列不能作为负载均衡使用,因为每个操作在所有节点都要做一遍。该模式带来的副作用也很明显,除了降低系统性能外,如果镜像队列数量过多,加之大量的消息进入,集群内部的网络带宽将会被这种同步通讯大大消耗掉。所以在对可靠性要求较高的场合中适用。

镜像模式
将需要消费的队列变为镜像队列,存在于多个节点,这样就可以实现 RabbitMQ 的 HA 高可用性。作用就是消息实体会主动在镜像节点之间实现同步,而不是像普通模式那样,在 consumer 消费数据时临时读取。缺点就是,集群内部的同步通讯会占用大量的网络带宽。
- sts 扩容
一键扩容
查看高可用策略
rabbitmqctl list_policies

ha-mode含义
ha-mode:策略键
1.all 队列镜像在群集中的所有节点上。当新节点添加到群集时,队列将镜像到该节点
2.exactly 集群中的队列实例数。
3.nodes 队列镜像到节点名称中列出的节点。
ha-sync-mode的含义
1.manual手动<默认模式>.新的队列镜像将不会收到现有的消息,它只会接收新的消息。
2.automatic自动同步.当一个新镜像加入时,队列会自动同步。队列同步是一个阻塞操作。

设定自动同步的命令
rabbitmqctl set_policy ha-all "^" '{"ha-mode":"all" , "ha-sync-mode":"automatic"}'
这些操作在dashboard都可以完成。
域名访问
- 增加ingress 使用域名访问
压测
官方的perf-test
由于bitnami 的容器是no-rootusert 且修改chart的中value.yaml 的参数无效。
Why use a non-root container?
Non-root container images add an extra layer of security and are generally recommended for production environments. However, because they run as a non-root user, privileged tasks are typically off-limits. Learn more about non-root containers in our docs.
我也提了一个issue:
https://github.com/bitnami/charts/issues/13017
curl 调用API + 脚本压测
#!/bin/bash
#############################################################################################################
# NAME........... publish_rmq.sh
# Project .......
# AUTHOR......... ninesun
# DATE........... 2022年10月19日13:40:27
# PURPOSE........ Push the NFS monitoring alerts to RMQ
# HISTORY ....... Created the initial draft
#
#############################################################################################################
#set your RMQ variables here
rmq_url='ip'
user="guest"
pass="guest"
exchange="test"
echo '
{"properties":{"delivery_mode":2},"routing_key":"test",
"payload":"{
\"alertnotes\":\"NFS Mount missing\",
\"device\":\"'"$(hostname)"'\",
\"servicename\":\"NFS Mount\",
\"eventsource\":\"NFS monitoring\",
\"message\":\"Docker NFS mount missing\",
\"last_occurance\":\"'"$(date -u +'%Y-%m-%d %H:%M:%S')"'\",
\"first_time\":\"'"$(date -u +'%Y-%m-%d %H:%M:%S')"'\",
\"eventgroups\":\"IT-Ops\",
\"severity\":\"3\",
\"eventtype\": \"CREATE\",
\"eventid\": \"123456789012345678901234\"
}",
"payload_encoding":"string"
}' >payload.json
#POST/Publish it to RMQ # Note: RMQ api access should be enabled (port#15672)
curl -s -u ${user}:${pass} -H "Accept: application/json" -H "Content-Type:application/json" -X POST -d @payload.json http://${rmq_url}:15672/api/exchanges/%2f/${exchange}/publish
这个脚本测试curl 发消息没测试通,放弃了使用rabbitmqadmin。
rabbitmqadmin publish + 脚本压测
while循环处理。
while true;do cat payload.json | rabbitmqadmin -H 10.50.10.31 -P 30101 -q publish exchange=qmsExchange routing_key=test1 && sleep 0.5s done
后台开启子进程放大并发.
这种方式并发无异于自杀。 玩坏别找我。
while true;do( cat glass.json | rabbitmqadmin -H 10.50.10.31 -P 30101 -q publish exchange=qmsExchange routing_key=test1 && sleep 0.5s)&done
更优雅的并发应该配合管道开启多个子进程并行处理才稳妥

问题
prometheus status正常为何dashboard抓取不到metrics?
dashboard取的是metrics 的rabbitmq_cluster这个指标。

原因: rabbitmq 3.8 自带的api会收集上来这个指标
rabbitmq_identity_info{rabbitmq_node="rabbit@chot-rabbitmq-0.chot-rabbitmq-headless.rabbitmq.svc.cluster.local",rabbitmq_cluster="rabbit@P1QMSARC01",rabbitmq_cluster_permanent_id="rabbitmq-cluster-id-SQeZUBPG7atPfpwViPK6bw"} 1
使用自定义rabbitmq_export 的版本是v0.29 ,我猜可能是metrics已经变化了。后来经实际测试是mq版本的问题,升级exporter到最新版本也没有这个指标。
只能找mq版本对应的dashboard。所以会有两个mq监控dashboard
Q数量太大导致监控卡顿
Q数量多超过4500+,其实只需要关注几个必要的MQ 即可. 这里需要写一个正则去匹配需要的Qname

rabbitmq pod都无法启动时,重新安装之后保证数据正常
当rabbitmq启用持久化存储时,若rabbitmq所有pod同时宕机,将无法重新启动,因此有必要提前开启clustering.forceBoot
容器没有root权限
Why use a non-root container?
Non-root container images add an extra layer of security and are generally recommended for production environments. However, because they run as a non-root user, privileged tasks are typically off-limits. Learn more about non-root containers in our docs.
理论上修改container的runAsUser就可以 以root权限启动. 我需要root权限是因为需要在容器中安装压测软件。 特别是在别人build的镜像中安装软件是一件难事。 如果非要实现可以自己build镜像。

重启pod报错
模拟故障,直接删除了pod-0. 导致起不起来。

if is_boolean_yes "$RABBITMQ_FORCE_BOOT" && ! is_dir_empty "${RABBITMQ_DATA_DIR}/${RABBITMQ_NODE_NAME}"; then
# ref: https://www.rabbitmq.com/rabbitmqctl.8.html#force_boot
warn "Forcing node to start..."
debug_execute "${RABBITMQ_BIN_DIR}/rabbitmqctl" force_boot
fi
解决: https://stackoverflow.com/questions/60407082/rabbit-mq-error-while-waiting-for-mnesia-tables
helm upgrade rabbitmq --set clustering.forceBoot=true
The problem happens for the following reason:
- All RMQ pods are terminated at the same time due to some reason (maybe because you explicitly set the StatefulSet replicas to 0, or something else)
- One of them is the last one to stop (maybe just a tiny bit after the others). It stores this condition (“I’m standalone now”) in its filesystem, which in k8s is the PersistentVolume(Claim). Let’s say this pod is rabbitmq-1.
- When you spin the StatefulSet back up, the pod rabbitmq-0 is always the first to start (see here).
- During startup, pod rabbitmq-0 first checks whether it’s supposed to run standalone. But as far as it can see on its own filesystem, it’s part of a cluster. So it checks for its peers and doesn’t find any. This results in a startup failure by default. (应该就是这点启动失败)
- rabbitmq-0 thus never becomes ready.
- rabbitmq-1 is never starting because that’s how StatefulSets are deployed - one after another. If it were to start, it would start successfully because it sees that it can run standalone as well.
So in the end, it’s a bit of a mismatch between how RabbitMQ and StatefulSets work. RMQ says: “if everything goes down, just start everything and the same time, one will be able to start and as soon as this one is up, the others can rejoin the cluster.” k8s StatefulSets say: “starting everything all at once is not possible, we’ll start with the 0”.
Solution
To fix this, there is a force_boot command for rabbitmqctl which basically tells an instance to start standalone if it doesn’t find any peers. How you can use this from Kubernetes depends on the Helm chart and container you’re using. In the Bitnami Chart, which uses the Bitnami Docker image, there is a value
clustering.forceBoot = true, which translates to an env variableRABBITMQ_FORCE_BOOT = yesin the container, which will then issue the above command for you.But looking at the problem, you can also see why deleting PVCs will work (other answer). The pods will just all “forget” that they were part of a RMQ cluster the last time around, and happily start. I would prefer the above solution though, as no data is being lost.
如何debug ?
diagnosticMode.enabled=true
参考
【1】 csdn安装参考

K8S/Kubernetes社区为您提供最前沿的新闻资讯和知识内容
更多推荐
 0
0 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)