
详解:MySQL自增ID与UUID的优缺点及选择建议,MySQL有序uuid与自定义函数实现
自增ID的优缺点,不适合以自增ID主键作为主键的情况,UUID介绍说明,uuid是什么,uuid的组成,UUID作为主键优缺点,mysql8.0的uuid_to_bin()函数分析及实现,mysql有序UUID实战,自定义uuid,自增id主键与自定义主键的选择建议,JDBCUtilsByDruid工具类,mysql数据类型binary,mysql函数hex(),mysql函数unhex(),bi
文章目录
1.自增ID的优缺点
1.1 优点
- 主键页以近乎顺序的方式填写,提升了页的利用率
- 索引更加紧凑,性能更好查询时数据访问更快
- 节省空间
- 连续增长的值能避免 b+ 树频繁合并和分裂
- 简单易懂,几乎所有数据库都支持自增类型,只是实现上各自有所不同而已
1.2 缺点
-
可靠性不高
存在
自增ID回溯的问题,这个问题直到最新版本的MySQL 8.0才修复。 -
安全性不高
ID不够随机,对外暴露的接口可以非常容易猜测对应的信息。比如:/User/1/这样的接口,可以非常容易猜测用户ID的值为多少,总用户数量有多少(泄露发号数量的信息),也可以非常容易地通过接口进行数据的爬取,因此不太安全。
-
性能差
自增ID的性能较差,需要在
数据库服务器端生成。对于高并发的负载,innodb在按主键进行插入的时候会造成明显的锁争用,主键的上界会成为争抢的热点,因为所有的插入都发生在这里,并发插入会导致间隙锁竞争。 -
交互多
业务还需要额外执行一次类似
last_insert_id()的函数才能知道刚才插入的自增值,这需要多一次的网络交互。在海量并发的系统中,多1条SQL,就多一次性能上的开销。 -
局部唯一性
最重要的一点,自增ID是
局部唯一,只在当前数据库实例中唯一,而不是全局唯一,在任意服务器间都是唯一的。对于目前分布式系统来说,这简直就是噩梦。 -
不利于数据迁移与扩展
1.3 不适合以自增ID主键作为主键的情况
- 数据量多需要分库分表,可能会造成ID重复
- 经常会遇到数据迁移的情况
- 新数据需要和老数据进行合并
2.UUID作为主键
2.1 介绍
虽然UUID() 值是 旨在独一无二,它们不一定是不可猜测的 或不可预测。如果需要不可预测性,UUID 值应该以其他方式生成。
UUID:Universally Unique ldentifier 通用 唯一 标识符
对于所有的UUID它可以保证在空间和时间上的唯一性。它是通过MAC地址,时间戳,命名空间,随机数,伪随机数来保证生成ID的唯一性,有着固定的大小(128bit)。它的唯一性和一致性特点使得可以无需注册过程就能够产生一个新的UUID。UUID可以被用作多种用途,既可以用来短时间内标记一个对象,也可以可靠的辨别网络中的持久性对象。
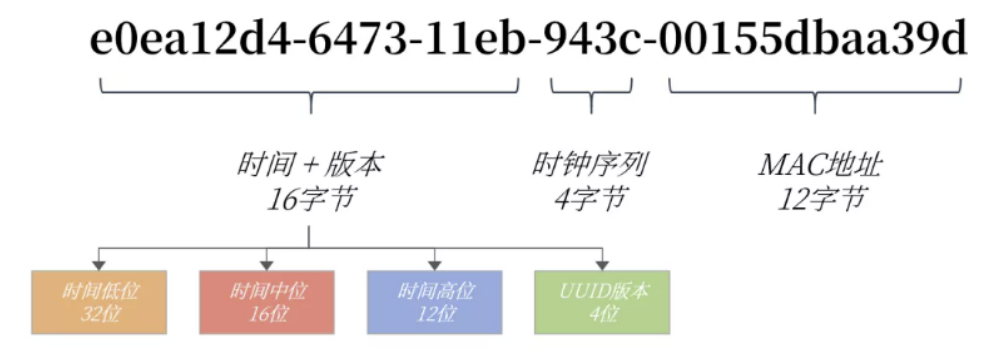
MySQL中的UUID组成 = [时间低位+时间中位+时间高位](16字节)- 时钟序列(4字节) - MAC地址(12字节)
mysql> select uuid();
+--------------------------------------+
| uuid() |
+--------------------------------------+
| 4b176683-695a-11ed-a641-0a002700000c |
+--------------------------------------+
1 row in set (0.00 sec)
👇 以下是在 MySQL8.0 官方文档对 UUID 函数的说明(https://dev.mysql.com/doc/refman/8.0/en/miscellaneous-functions.html#function_uuid):
UUID() 返回一个值 符合 RFC 4122 中所述的 UUID 版本 1,表示为五个十六进制数字的字符串格式,中间用了 “-” 连接。
-
前三个数字字符串是从低处生成的, 时间戳的中间和高部分。高部分也 包括 UUID 版本号。
-
第四个数字字符串保留了时间唯一性,以防万一 时间戳值失去单调性(例如,由于 到夏令时)。
-
第五个数字字符串是 IEEE 802 节点编号,它提供 空间独特性。如果 后者不可用(例如,因为主机 设备没有以太网卡,或者不知道如何找到主机上运行的接口的硬件地址系统)。在这种情况下,空间唯一性不能 保证。然而,碰撞的概率应该非常低。
仅考虑接口的 MAC 地址 在 FreeBSD、Linux 和 Windows 上。关于其他操作 系统,MySQL使用随机生成的48位数字。
要在字符串和二进制 UUID 值之间进行转换,请使用 UUID_TO_BIN() 和 BIN_TO_UUID() 函数。自检查字符串是否为有效的 UUID 值,使用IS_UUID() 函数。
2.2 优点
- 保证了全局唯一性
- 更加安全
2.3 缺点
- 存在
隐私安全的问题,因为UUID包含了MAC地址,也就是机械的物理地址。 - 无序,随机生成与插入,聚集索引频繁页分裂,大量随机IO,内存碎片化,特别是随着数据量越来越多,插入性能会越差。
- 占用36字节,比较浪费空间。
3.有序UUID作为主键
3.1 介绍
UUID唯一性的特点使它作为主键带来了很多的优势,比较大的问题主要是无序性带来的索引性能的下降。 使用mysql8自带的
uuid_to_bin可以方便的将时间相关的字符高低位进行互换,从而解决了这个性能上的问题。
在通过 UUID()函数 生成的uuid值中,若将时间高低位互换,则时间就是单调递增的了,也就变得单调递增了。MySQL 8.0可以更换时间低位和时间高位的存储方式,这样UUID就是有序的UUID了。
MySQL 8.0还解决了UUID存在的空间占用的问题,除去了UUID字符串中无意义的"-"字符串,并且将字符串用二进制类型保存,这样存储空间降低为了16字节。
可以通过MySQL8.0提供的uuid_to_bin函数实现上述两个功能:
-- 生成一个 uuid
SET @uuid = UUID();
-- uuid_to_bin(@uuid):实现去除无意义的 "-" 字符串
-- uuid_to_bin(@uuid,TRUE):实现时间低位与时间高位的互换,实现了该函数返回值随时间递增
SELECT @uuid,uuid_to_bin(@uuid),uuid_to_bin(@uuid,TRUE);

通过函数uuid_to_bin(@uuid,true)将UUID转化为有序UUID了。全局唯一 + 单调递增,这不就是我们想要的主键!
3.2 演示使用
3.2.1 前提知识
3.2.1.1 数据类型 - binary
binary存储的是二进制的字符串,binary(N)中的N是指定存储的最大字节长度,和 char(N) 类型一样是 固长 存储。
CREATE TABLE test01(
-- 指定 uid 最大可以存储 16 个字节大小,也就是 128 bit
`uid` BINARY(16) PRIMARY KEY,
`num` INT NOT NULL
);
3.2.1.2 函数 - hex()
可以将一个二进制字符串转换成十六进制的字符串
3.2.1.3 函数 - unhex()
可以将一个十六进制字符串转换成二进制的字符串
3.2.2 数据库层
-- 创建测试数据库 test
DROP DATABASE IF EXISTS test;
CREATE DATABASE test;
-- 使用/定位该数据库
USE test;
-- 创建表 test01
CREATE TABLE test01(
-- 解释一下为什么定义为16个字节:
-- 因为 uuid 一共32个字符,由于每个字符是十六进制的数字,
-- 在将 uuid 字符串转为十六进制时 是用 4 个bit 表示一个字符
-- 因此 uuid 字符串转十六进制需要 128 个 bit
-- 一个 字节 等于 8 个 bit,所以 128 个 bit 一共就是 16 个 字节
`uid` BINARY(16) PRIMARY KEY,
`num` INT NOT NULL
);
-- 增加测试数据
INSERT INTO test01(`uid`,`num`) VALUES
(UUID_TO_BIN(UUID(),TRUE),1),
(UUID_TO_BIN(UUID(),TRUE),2),
(UUID_TO_BIN(UUID(),TRUE),3);
-- 以十六进制字符串方式显示 uid
SELECT HEX(uid),num FROM test01;
-- 查询 某个uid 的对应记录的其他数据
-- 将十六进制字符串转二进制字符串与 表中的uid 比较
select num from test01
where uid = unhex('11ED68FE63CC264781770A002700001A')
3.2.3 JAVA层
3.2.3.1 导入mysql的驱动jar包
1️⃣ commons-dbutils-1.7.jar
🏠 下载地址:https://repo1.maven.org/maven2/commons-dbutils/commons-dbutils/1.7/
2️⃣ druid-1.1.10.jar
🏠 下载地址:https://repo1.maven.org/maven2/com/alibaba/druid/1.1.10/
3.2.3.2 创建 druid.properties 配置文件
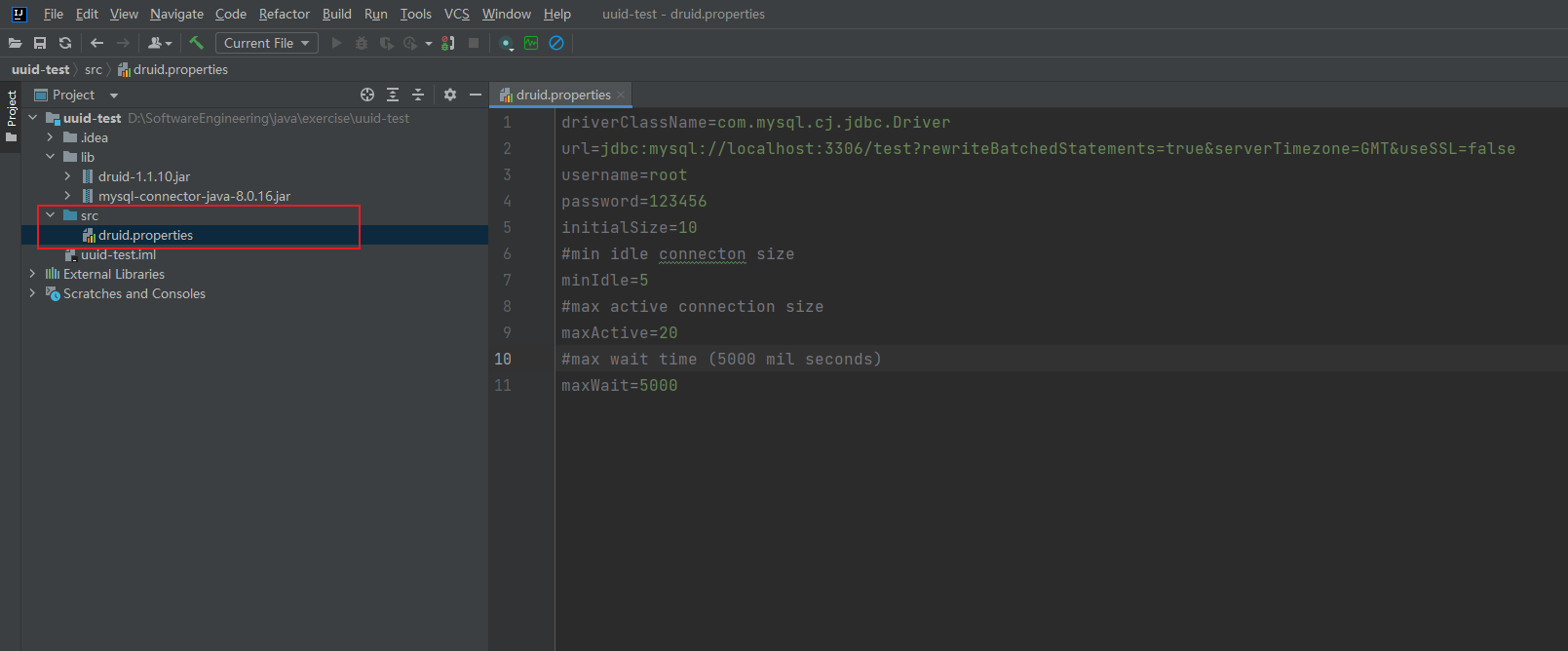
driverClassName=com.mysql.cj.jdbc.Driver
url=jdbc:mysql://localhost:3306/test?rewriteBatchedStatements=true&serverTimezone=GMT&useSSL=false
username=root
password=123456
initialSize=10
#min idle connecton size
minIdle=5
#max active connection size
maxActive=20
#max wait time (5000 mil seconds)
maxWait=5000
3.2.3.3 创建 JDBCUtilsByDruid 工具类
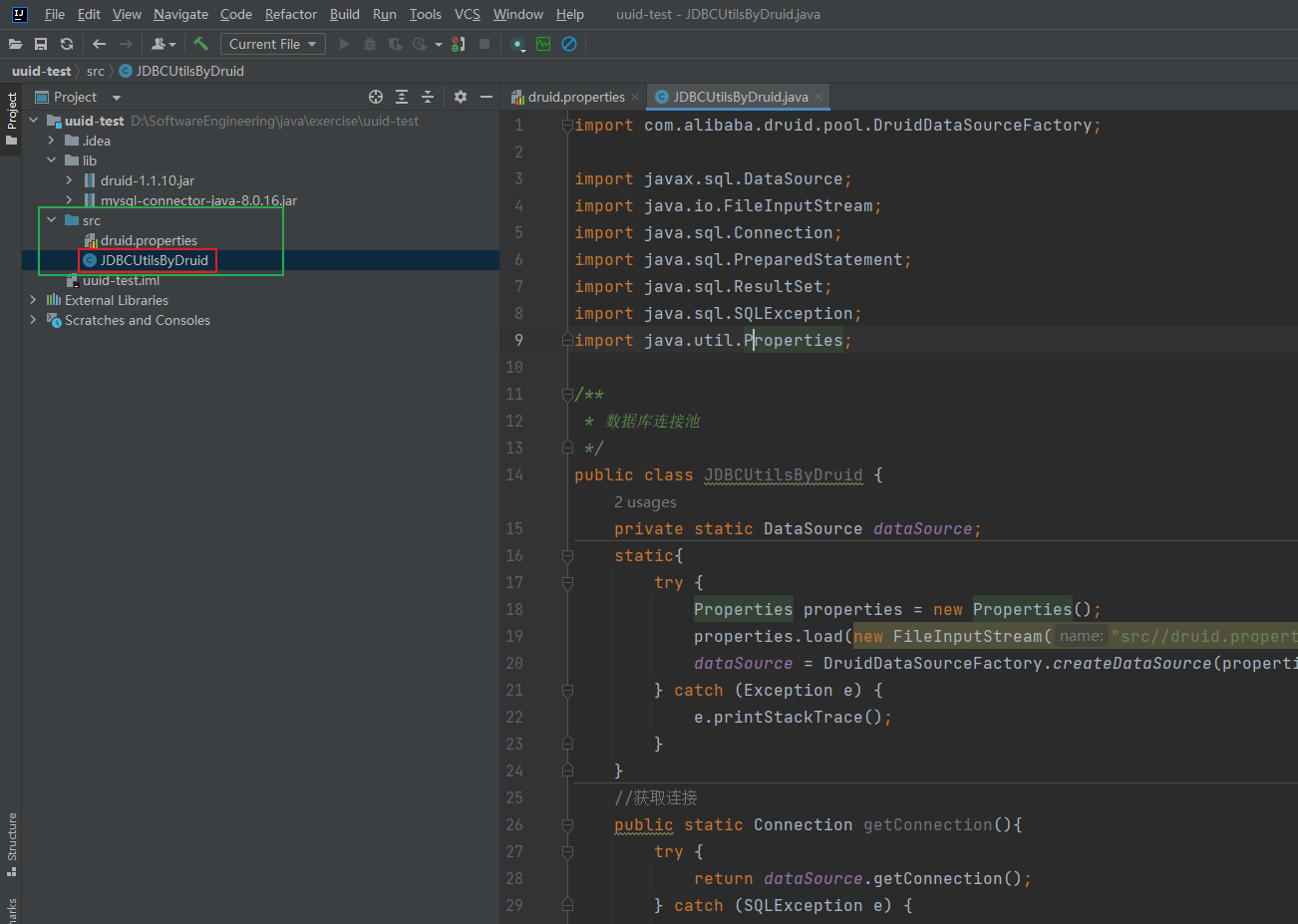
import com.alibaba.druid.pool.DruidDataSourceFactory;
import javax.sql.DataSource;
import java.io.FileInputStream;
import java.sql.*;
import java.util.Properties;
/**
* 数据库连接池
*/
public class JDBCUtilsByDruid {
private static DataSource dataSource;
static{
try {
Properties properties = new Properties();
properties.load(new FileInputStream("src//druid.properties"));
dataSource = DruidDataSourceFactory.createDataSource(properties);
} catch (Exception e) {
e.printStackTrace();
}
}
//获取连接
public static Connection getConnection(){
try {
return dataSource.getConnection();
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
//关闭连接
public static void close(ResultSet resultSet, PreparedStatement preparedStatement, Connection connection){
try {
if(resultSet!=null){
resultSet.close();
}
if(preparedStatement!=null){
preparedStatement.close();
}
if(connection!=null){
connection.close();
}
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
}
3.2.3.4 测试 - 查询全部记录
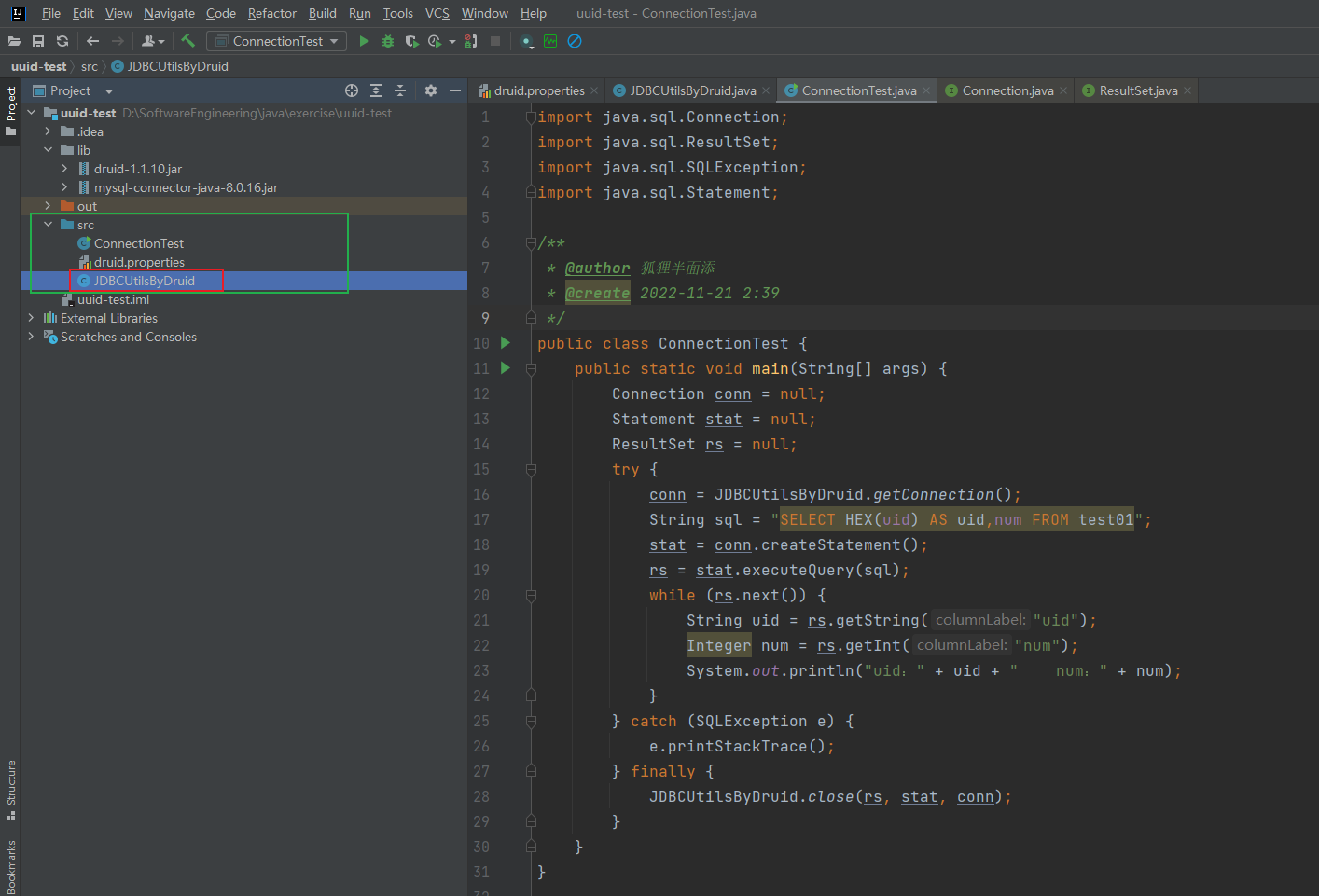
import java.sql.*;
/**
* @author 狐狸半面添
* @create 2022-11-21 2:39
*/
public class ConnectionTest {
public static void main(String[] args) {
Connection conn = null;
PreparedStatement stat = null;
ResultSet rs = null;
try {
conn = JDBCUtilsByDruid.getConnection();
String sql = "SELECT HEX(uid) AS uid,num FROM test01";
stat = conn.prepareStatement(sql);
rs = stat.executeQuery();
while (rs.next()) {
String uid = rs.getString("uid");
Integer num = rs.getInt("num");
System.out.println("uid:" + uid + " num:" + num);
}
} catch (SQLException e) {
e.printStackTrace();
} finally {
JDBCUtilsByDruid.close(rs, stat, conn);
}
}
}
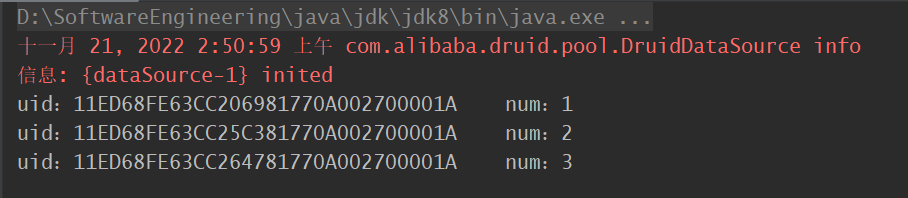
运行上述代码:
3.2.3.5 查询某条记录
import java.sql.*;
/**
* @author 狐狸半面添
* @create 2022-11-21 2:39
*/
public class ConnectionTest {
public static void main(String[] args) {
Connection conn = null;
PreparedStatement stat = null;
ResultSet rs = null;
try {
conn = JDBCUtilsByDruid.getConnection();
String sql = "SELECT num FROM test01 WHERE uid = UNHEX('11ED68FE63CC264781770A002700001A')";
stat = conn.prepareStatement(sql);
rs = stat.executeQuery();
while (rs.next()) {
Integer num = rs.getInt("num");
System.out.println("num:" + num);
}
} catch (SQLException e) {
e.printStackTrace();
} finally {
JDBCUtilsByDruid.close(rs, stat, conn);
}
}
}
3.2.3.6 增加一条记录
import java.sql.*;
/**
* @author 狐狸半面添
* @create 2022-11-21 2:39
*/
public class ConnectionTest {
public static void main(String[] args) {
Connection conn = null;
PreparedStatement stat = null;
ResultSet rs = null;
try {
conn = JDBCUtilsByDruid.getConnection();
//添加一条记录
String insertSql = "INSERT INTO test01(`uid`,`num`) VALUES(UUID_TO_BIN(UUID(),TRUE),4)";
stat = conn.prepareStatement(insertSql);
int info = stat.executeUpdate();
if(info!=0){
System.out.println("记录添加成功");
}else{
System.out.println("记录添加失败");
}
//查询全部数据
String selectSql = "SELECT HEX(uid) AS uid,num FROM test01";
rs = stat.executeQuery(selectSql);
while (rs.next()) {
String uid = rs.getString("uid");
Integer num = rs.getInt("num");
System.out.println("uid:" + uid + " num:" + num);
}
} catch (SQLException e) {
e.printStackTrace();
} finally {
JDBCUtilsByDruid.close(rs, stat, conn);
}
}
}

3.3 手撕uuid_to_bin(uuid(),true)方法实现
3.3.1 过程分析
-- 1. 得到uuid
SELECT UUID();
-- 2. 在第一步的基础上将 uuid 字符串的 "-" 删除
SELECT REPLACE(UUID(),'-','');
-- 3. 在第二步的基础上调换时间低位与时间高位
SET @uuid = REPLACE(UUID(),'-','');
SELECT CONCAT(SUBSTR(@uuid,13,4),SUBSTR(@uuid,9,4),SUBSTR(@uuid,1,8),SUBSTR(@uuid,17,16));
-- 4. 在第三步的基础上将小写字母全变为大写
SET @uuid = REPLACE(UUID(),'-','');
SELECT UPPER(CONCAT(SUBSTR(@uuid,13,4),SUBSTR(@uuid,9,4),SUBSTR(@uuid,1,8),SUBSTR(@uuid,17,16)));
-- 5. 在第四步的基础上将这个十六进制字符串转为二进制字符串
SET @uuid = REPLACE(UUID(),'-','');
SELECT UNHEX(UPPER(CONCAT(SUBSTR(@uuid,13,4),SUBSTR(@uuid,9,4),SUBSTR(@uuid,1,8),SUBSTR(@uuid,17,16))));
3.3.2 存储函数封装
-- 先执行这条语句,否则创建函数时会报错
SET GLOBAL log_bin_trust_function_creators = 1;
-- 6. 进行函数封装
DELIMITER //
CREATE FUNCTION my_uuid_to_bin()
RETURNS BINARY(16)
BEGIN
DECLARE my_uuid CHAR(32);
SET my_uuid = REPLACE(UUID(), '-', '');
RETURN (SELECT UNHEX(UPPER(CONCAT(SUBSTR(my_uuid,13,4),SUBSTR(my_uuid,9,4),SUBSTR(my_uuid,1,8),SUBSTR(my_uuid,17,16)))));
END //
DELIMITER ;
3.3.3 使用自定义方法增添数据
INSERT INTO test01(`uid`,`num`) VALUES
(my_uuid_to_bin(),13),
(my_uuid_to_bin(),14)
4.自定义UUID
4.1 为什么要有自定义UUID
在上面我们谈论到了关于 UUID() 函数的隐私安全的问题,因为UUID包含了MAC地址,也就是机械的物理地址,即用户的地址信息。
而在当今的海量数据的互联网环境中,非常不推荐自增ID作为主键的数据库设计,推荐类似有序UUID的全局唯一的实现。
另外在真实的业务系统中,主键还可以加入业务和系统属性,如用户的尾号,机房的信息等。这样的主键设计就更为考验架构师的水平了。
4.2 自定义UUID实例演示
因此如果我们打算以 有序uuid 这样的类型作为主键,可以对之前提到的有序uuid加以改进:
【仅供参考】由于最近在做数据库课设,需要建立一张订单表,那么我可以在 上面的自定义my_uuid_to_bin()函数 中把 mac地址 部分的12个字节删除,以用户的手机号码后六位加以代替。
这里进行一个简单演示:
-- 如果存在则删除数据库 test
DROP DATABASE IF EXISTS test;
-- 创建数据库 test
CREATE DATABASE test CHARSET=utf8mb4;
-- 使用该数据库
USE test;
-- 在 test 数据库中创建表 test01
CREATE TABLE test01(
`order_id` BINARY(13) PRIMARY KEY,
`num` INT NOT NULL
)ENGINE=INNODB DEFAULT CHARSET=utf8mb4;
-- 先执行这条语句,否则创建函数时会报错
SET GLOBAL log_bin_trust_function_creators = 1;
DELIMITER //
CREATE FUNCTION my_uuid_to_bin(phone CHAR(11))
RETURNS BINARY(13)
BEGIN
DECLARE my_uuid CHAR(32);
SET my_uuid = REPLACE(UUID(), '-', '');
RETURN (SELECT UNHEX(UPPER(CONCAT(SUBSTR(my_uuid,13,4),SUBSTR(my_uuid,9,4),SUBSTR(my_uuid,1,8),SUBSTR(my_uuid,17,4),SUBSTR(phone,6,6)))));
END //
DELIMITER ;
INSERT INTO test01(`order_id`,`num`) VALUES
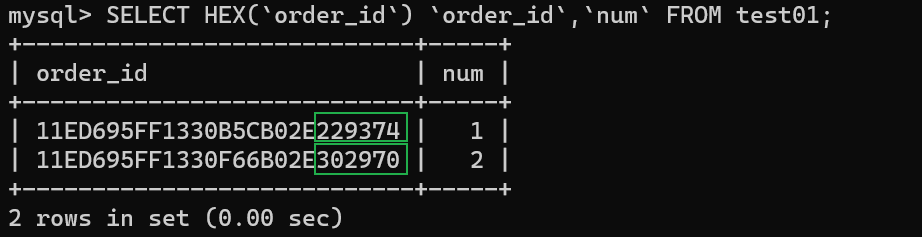
(my_uuid_to_bin('15675229374'),1),
(my_uuid_to_bin('13789302970'),2);
-- 查看表记录
SELECT HEX(`order_id`) `order_id`,`num` FROM test01;
5.总结
5.1 自增id主键与自定义主键的选择
- 从数据在数据库的存储角度来看,自增id 是int 型,一般比自定义的属性(uuid等)作为主键,所占的磁盘空间要小。但即使我们插入
一亿数据,使用有序uuid的表大小比自增id也只多了 3G,在当今的环境下,3G确实不算很多,所以还能接受。 - 从数据库的设计来看,mysql的底层是InnoDB,它的数据结构是B+树。所以对于InnoDB的主键,尽量用
整型,而且是递增的整型。这样在存储/查询上都是非常高效的。
因此如果只是简单的单库单表的场景或者是一些简单的非核心业务,使用自增id主键是没有问题的。但如果是在高并发场景与分布式架构中,就不是很推荐使用自增id,那这时我们就可以选用自增步长id,改造uuid,雪花算法自造全局自增id等方案来作为我们表的主键。
5.2 建议与说明
-
建议尽量不要用跟业务特别紧密相关的字段做主键。毕竟,作为项目设计的技术人员,我们谁也无法预测在项目的整个生命周期中,哪个业务字段会因为项目的业务需求而有重复,或者重用之类的情况出现。
很多初学者都很容易犯的错误是喜欢用业务字段做主键,想当然地认为了解业务需求,但实际情况往往出乎意料,而更改主键设置的成本非常高。
-
非核心业务 :对应表的主键自增ID,如告警、日志、监控等信息。
-
核心业务 :**主键设计至少应该是全局唯一且是单调递增。**全局唯一保证在各系统之间都是唯一的,单调递增是希望插入时不影响数据库性能。

无需安装部署,在线快速体验 Byzer
更多推荐
 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)