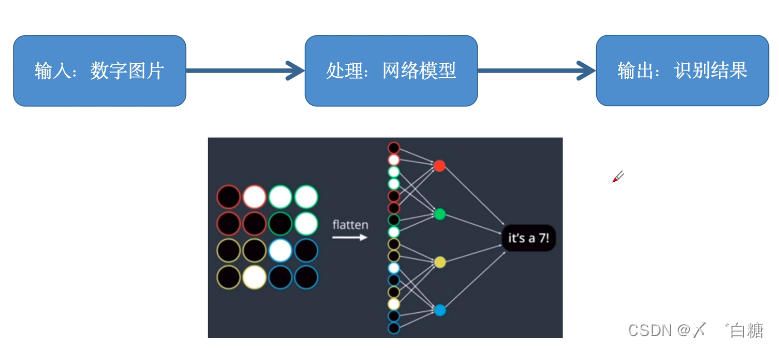
MNIST手写体数字识别数据集
MNIST的加载及实现
·
一、总体介绍
1.1 什么是机器识别手写数字?

1.2 MNIST数据集是什么?
(1)该数据集包含60,000个用于训练的示例和10,000个用于测试的示例。
(2)数据集包含了0-9共10类手写数字图片,每张图片都做了尺寸归一化,都是28x28大小的灰度图。
(3)MNIST数据集包含四个部分:
训练集图像:train-images-idx3-ubyte.gz(9.9MB,包含60000个样本)
训练集标签:train-labels-idx1-ubyte.gz(29KB,包含60000个标签)
测试集图像:t10k-images-idx3-ubyte.gz(1.6MB,包含10000个样本)
测试集标签:t10k-labels-idx1-ubyte.gz(5KB,包含10000个标签)
下载地址MNIST
1.3 手写字体的识别流程
( 1)定义超参数;
(2〉构建transforms,主要是对图像做变换;
(3)下载、加载数据集MNIST;
(4)构建网络模型;
(5)定义训练方法;
(6)定义测试方法;
(7)开始训练模型,输出预测结果;
二、代码实现
2.1 导入相应的库
# 1 加载必要的库
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets,transforms
2.2 定义超参数
# 2 定义超参数
BATCH_SIZE = 16 # 每批处理的数据
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 是否用GPU还是CPU训练
EPOCHS = 10 # 训练数据集的轮次
2.3 构建pipeline,对图像做处理
# 3 构建pipeline,对图像做处理
pipeline = transforms.Compose([
transforms.ToTensor(),# 将图片转换成tensor
transforms.Normalize((0.1307,),(0.3081,)) # 正则化降低模型复杂度
])
2.4 下载、加载数据
# 4 下载、加载数据
from torch.utils.data import DataLoader
# 下载数据集
train_set = datasets.MNIST("data", train=True, download=False, transform=pipeline)
test_set = datasets.MNIST("data", train=False, download=False, transform=pipeline)
# 加载数据
train_loader = DataLoader(train_set, batch_size=BATCH_SIZE, shuffle=True) # 顺序打乱shuffle=True
test_loader = DataLoader(test_set, batch_size=BATCH_SIZE, shuffle=True)
2.5 查看一下数据集图片(可跳过)
## 插入代码,显示MNIST中的图片
with open("./data/MNIST/raw/train-images-idx3-ubyte","rb") as f:
file = f.read()
imagel = [int(str(item).encode('ascii'),16) for item in file[16 : 16+784]]
print(imagel)
import cv2
import numpy as np
imagel_np = np.array(imagel, dtype=np.uint8).reshape(28, 28, 1)
print(imagel_np.shape)
cv2.imwrite("gigit.jpg", imagel_np)
2.6 构建网络模型
# 5 构建网络模型
class Digit(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 10, 5) # 1:灰度图片的通道, 10:输出通道, 5:kernel 5x5
self.conv2 = nn.Conv2d(10, 20, 3) # 10:输入通道, 20:输出通道, 3:kernel 3x3
self.fc1 = nn.Linear(20*10*10, 500) # 20*10*10:输入通道, 500:输出通道
self.fc2 = nn.Linear(500, 10) # 500:输入通道, 10:输出通道
#前向传播
def forward(self, x):
input_size = x.size(0) # batch_size
x = self.conv1(x) # 输入:batch*1*28*28, 输出:batch*10*24*24 (28 - 5 + 1 = 24)
x = F.relu(x) # 激活函数,保持shape不变, 输出batch*10*24*24
x = F.max_pool2d(x, 2, 2) # 输入:batch*10*24*24 输出:batch*10*12*12
x = self.conv2(x) # 输入:batch*10*12*12, 输出:batch*20*10*10 (12 - 3 + 1 = 10)
x = F.relu(x)
x = x.view(input_size, -1) # 拉平, -1 自动计算维度,20*10*10 = 2000
x = self.fc1(x) # 输入:batch*2000,输出:batch*500
x = F.relu(x)
x = self.fc2(x) # 输入:batch*500,输出:batch*10
output = F.log_softmax(x, dim=1) # 计算分类后,每个数字的概率值
return output
2.6 定义优化器(更新参数,是训练测试结果达到最优值)
model = Digit().to(DEVICE)
optimizer = optim.Adam(model.parameters())
2.7 定义训练方法
# 7 定义训练方法
def train_model(model, device, train_loader, optimizer, epoch):
# 模型训练
model.train()
for batch_index, (data, target) in enumerate(train_loader):
# 部署到DEVICE上去
data, target = data.to(device), target.to(device)
# 梯度初始化为0
optimizer.zero_grad()
# 训练后的结果
output = model(data)
# 计算损失
loss = F.cross_entropy(output, target) # 交叉熵用于分类比较多的情况
# 反向传播
loss.backward()
# 参数优化
optimizer.step()
if batch_index % 3000 == 0:
print("Train Epoch : {} \t Loss : {:.6f}".format(epoch, loss.item()))
2.8 定义测试方法
# 8 定义测试方法
def model_test(model, device, test_loader):
# 模型验证
model.eval()
# 正确率
correct = 0.0
# 测试损失
test_loss = 0.0
with torch.no_grad(): # 不会计算梯度,也不会反向传播
for data, target in test_loader:
# 部署到device上
data, target = data.to(device), target.to(device)
# 测试数据
output = model(data)
# 计算测试损失
test_loss += F.cross_entropy(output, target).item()
# 找到概率值最大的下标
pred = output.max(1, keepdim=True)[1] # 值,索引
# pred = torch.max(output, dim=1)
# pred = output.argmax(dim=1)
#累计正确的值
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print("Test — Average loss : {:.4f}, Accuracy : {:.3f}\n".format(
test_loss, 100.0 * correct / len(test_loader.dataset)))
2.9 调用 方法7 / 8
# 9 调用 方法7 / 8
for epoch in range(1, EPOCHS +1):
train_model(model, DEVICE, train_loader, optimizer, epoch)
model_test(model, DEVICE, test_loader)
2.10 结果

三、总结
本文观看b站的“唐国梁Tommy”up主的轻松学 PyTorch 手写字体识别 MNIST,讲解十分详细,推荐观看。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 14
14 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容
目录

所有评论(0)