【重识云原生】第六章容器6.3.3节——Kube-Scheduler使用篇
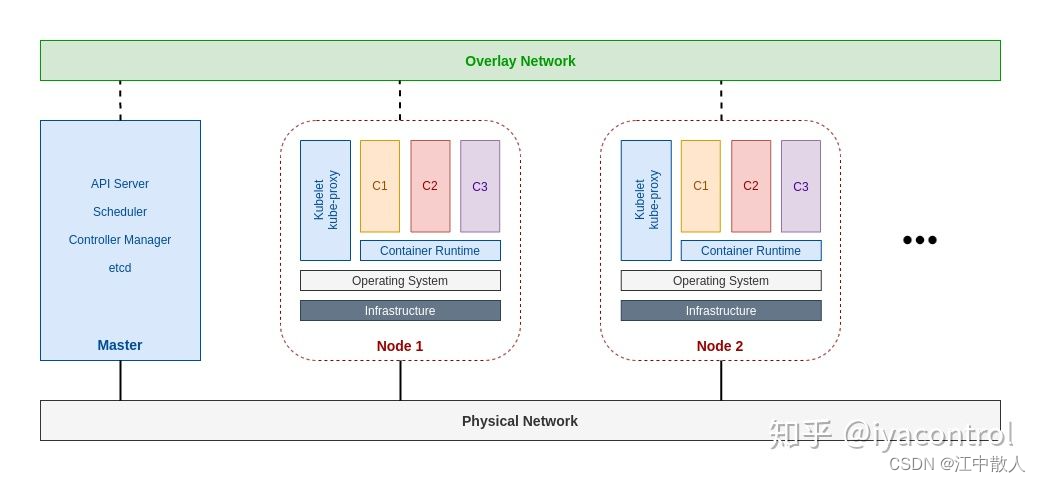
scheduler是任务调度器,在K8S中实现组件名为kube-scheduler,负责任务调度、选择合适的节点来执行任务。Scheduler 负责决定将 Pod 放在哪个 Node 上运行。Scheduler 在调度时会充分考虑 Cluster 的拓扑结构,当前各个节点的负载,以及应用对高可用、性能、数据亲和性的需求。它监听 kube-apiserver,查询还未分配 Node 的 Pod,然后

《重识云原生系列》专题索引:
- 第一章——不谋全局不足以谋一域
- 第二章计算第1节——计算虚拟化技术总述
- 第二章计算第2节——主流虚拟化技术之VMare ESXi
- 第二章计算第3节——主流虚拟化技术之Xen
- 第二章计算第4节——主流虚拟化技术之KVM
- 第二章计算第5节——商用云主机方案
- 第二章计算第6节——裸金属方案
- 第三章云存储第1节——分布式云存储总述
- 第三章云存储第2节——SPDK方案综述
- 第三章云存储第3节——Ceph统一存储方案
- 第三章云存储第4节——OpenStack Swift 对象存储方案
- 第三章云存储第5节——商用分布式云存储方案
- 第四章云网络第一节——云网络技术发展简述
- 第四章云网络4.2节——相关基础知识准备
- 第四章云网络4.3节——重要网络协议
- 第四章云网络4.3.1节——路由技术简述
- 第四章云网络4.3.2节——VLAN技术
- 第四章云网络4.3.3节——RIP协议
- 第四章云网络4.3.4节——OSPF协议
- 第四章云网络4.3.5节——EIGRP协议
- 第四章云网络4.3.6节——IS-IS协议
- 第四章云网络4.3.7节——BGP协议
- 第四章云网络4.3.7.2节——BGP协议概述
- 第四章云网络4.3.7.3节——BGP协议实现原理
- 第四章云网络4.3.7.4节——高级特性
- 第四章云网络4.3.7.5节——实操
- 第四章云网络4.3.7.6节——MP-BGP协议
- 第四章云网络4.3.8节——策略路由
- 第四章云网络4.3.9节——Graceful Restart(平滑重启)技术
- 第四章云网络4.3.10节——VXLAN技术
- 第四章云网络4.3.10.2节——VXLAN Overlay网络方案设计
- 第四章云网络4.3.10.3节——VXLAN隧道机制
- 第四章云网络4.3.10.4节——VXLAN报文转发过程
- 第四章云网络4.3.10.5节——VXlan组网架构
- 第四章云网络4.3.10.6节——VXLAN应用部署方案
- 第四章云网络4.4节——Spine-Leaf网络架构
- 第四章云网络4.5节——大二层网络
- 第四章云网络4.6节——Underlay 和 Overlay概念
- 第四章云网络4.7.1节——网络虚拟化与卸载加速技术的演进简述
- 第四章云网络4.7.2节——virtio网络半虚拟化简介
- 第四章云网络4.7.3节——Vhost-net方案
- 第四章云网络4.7.4节vhost-user方案——virtio的DPDK卸载方案
- 第四章云网络4.7.5节vDPA方案——virtio的半硬件虚拟化实现
- 第四章云网络4.7.6节——virtio-blk存储虚拟化方案
- 第四章云网络4.7.8节——SR-IOV方案
- 第四章云网络4.7.9节——NFV
- 第四章云网络4.8.1节——SDN总述
- 第四章云网络4.8.2.1节——OpenFlow概述
- 第四章云网络4.8.2.2节——OpenFlow协议详解
- 第四章云网络4.8.2.3节——OpenFlow运行机制
- 第四章云网络4.8.3.1节——Open vSwitch简介
- 第四章云网络4.8.3.2节——Open vSwitch工作原理详解
- 第四章云网络4.8.4节——OpenStack与SDN的集成
- 第四章云网络4.8.5节——OpenDayLight
- 第四章云网络4.8.6节——Dragonflow
1 scheduler
1.1 scheduler简介
scheduler是任务调度器,在K8S中实现组件名为kube-scheduler,负责任务调度、选择合适的节点来执行任务。Scheduler 负责决定将 Pod 放在哪个 Node 上运行。Scheduler 在调度时会充分考虑 Cluster 的拓扑结构,当前各个节点的负载,以及应用对高可用、性能、数据亲和性的需求。它监听 kube-apiserver,查询还未分配 Node 的 Pod,然后根据调度策略为这些 Pod 分配节点(更新 Pod 的 NodeName 字段)。

scheduler通过 kubernetes 的监测(Watch)机制来发现集群中新创建且尚未被调度到 Node 上的 Pod。 scheduler会将发现的每一个未调度的 Pod 调度到一个合适的 Node 上来运行。 scheduler会依据下文的调度原则来做出调度选择。
实际上调度完成之后,scheduler只需更新 Pod 的NodeName字段即可。
1.2 Scheduler调度策略
1.2.1 调度器需要充分考虑诸多的因素:
调度器需要充分考虑诸多的因素:
- 公平调度
- 资源高效利用
- QoS
- affinity 和 anti-affinity
- 数据本地化(data locality)
- 内部负载干扰(inter-workload interference)
- deadlines
1.2.2 指定node节点调度
有三种方式可以指定 Pod 只运行在指定的 Node 节点上:
- nodeSelector:只调度到匹配指定 label 的 Node 上
- nodeAffinity:功能更丰富的 Node 选择器,比如支持集合操作
- podAffinity:调度到满足条件的 Pod 所在的 Node 上
1.2.3 taints和tolerations
Taints 和 tolerations 用于保证 Pod 不被调度到不合适的 Node 上,其中 Taint 应用于 Node 上,而 toleration 则应用于 Pod 上。目前支持的 taint 类型:
- NoSchedule:新的 Pod 不调度到该 Node 上,不影响正在运行的 Pod
- PreferNoSchedule:soft 版的 NoSchedule,尽量不调度到该 Node 上
- NoExecute:新的 Pod 不调度到该 Node 上,并且删除(evict)已在运行的 Pod。Pod 可以增加一个时间(tolerationSeconds)
然而,当 Pod 的 Tolerations 匹配 Node 的所有 Taints 的时候可以调度到该 Node 上;当 Pod 是已经运行的时候,也不会被删除(evicted)。另外对于 NoExecute,如果 Pod 增加了一个 tolerationSeconds,则会在该时间之后才删除 Pod。
1.2.4 优先级调度
从 v1.8 开始,kube-scheduler 支持定义 Pod 的优先级,从而保证高优先级的 Pod 优先调度。并从 v1.11 开始默认开启。
注:在 v1.8-v1.10 版本中的开启方法为apiserver 配置 --feature-gates=PodPriority=true 和 --runtime-config=scheduling.k8s.io/v1alpha1=truekube-scheduler 配置 --feature-gates=PodPriority=true
在指定 Pod 的优先级之前需要先定义一个 PriorityClass(非 namespace 资源),如
apiVersion: v1
kind: PriorityClass
metadata:
name: high-priority
value: 1000000
globalDefault: false
description: "This priority class should be used for XYZ service pods only."其中
- value 为 32 位整数的优先级,该值越大,优先级越高
- globalDefault 用于未配置 PriorityClassName 的 Pod,整个集群中应该只有一个 PriorityClass 将其设置为 true
然后,在 PodSpec 中通过 PriorityClassName 设置 Pod 的优先级:
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
env: test
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
priorityClassName: high-priority1.2.5 多调度器
如果默认的调度器不满足要求,还可以部署自定义的调度器。并且,在整个集群中还可以同时运行多个调度器实例,通过 podSpec.schedulerName 来选择使用哪一个调度器(默认使用内置的调度器)。
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
app: nginx
spec:
# 选择使用自定义调度器 my-scheduler
schedulerName: my-scheduler
containers:
- name: nginx
image: nginx:1.101.2.6 调度器扩展
kube-scheduler 还支持使用 --policy-config-file 指定一个调度策略文件来自定义调度策略,比如:
{
"kind" : "Policy",
"apiVersion" : "v1",
"predicates" : [
{"name" : "PodFitsHostPorts"},
{"name" : "PodFitsResources"},
{"name" : "NoDiskConflict"},
{"name" : "MatchNodeSelector"},
{"name" : "HostName"}
],
"priorities" : [
{"name" : "LeastRequestedPriority", "weight" : 1},
{"name" : "BalancedResourceAllocation", "weight" : 1},
{"name" : "ServiceSpreadingPriority", "weight" : 1},
{"name" : "EqualPriority", "weight" : 1}
],
"extenders":[
{
"urlPrefix": "http://127.0.0.1:12346/scheduler",
"apiVersion": "v1beta1",
"filterVerb": "filter",
"prioritizeVerb": "prioritize",
"weight": 5,
"enableHttps": false,
"nodeCacheCapable": false
}
]
}1.2.7 其他影响调度的因素
- 如果 Node Condition 处于 MemoryPressure,则所有 BestEffort 的新 Pod(未指定 resources limits 和 requests)不会调度到该 Node 上
- 如果 Node Condition 处于 DiskPressure,则所有新 Pod 都不会调度到该 Node 上
- 为了保证 Critical Pods 的正常运行,当它们处于异常状态时会自动重新调度。Critical Pods 是指
- annotation 包括 scheduler.alpha.kubernetes.io/critical-pod=''
- tolerations 包括 [{"key":"CriticalAddonsOnly", "operator":"Exists"}]
- priorityClass 为 system-cluster-critical 或者 system-node-critical
1.3 启动 kube-scheduler 示例
kube-scheduler --address=127.0.0.1 --leader-elect=true --kubeconfig=/etc/kubernetes/scheduler.conf2 scheduler工作原理
2.1 scheduler工作流程
scheduler工作流程基本上如下:
- scheduler维护待调度的podQueue并监听APIServer。
- 创建Pod时,我们首先通过APIServer将Pod元数据写入etcd。
- scheduler通过Informer监听Pod状态。添加新的Pod时,会将Pod添加到podQueue。
- 主程序不断从podQueue中提取Pods并按照一定的算法将节点分配给Pods。
- 节点上的kubelet也侦听ApiServer。如果发现有新的Pod已调度到该节点,则将通过CRI调用高级容器运行时来运行容器。
- 如果scheduler无法调度Pod,则如果启用了优先级和抢占功能,则首先进行抢占尝试,删除节点上具有低优先级的Pod,然后将要调度的Pod调度到该节点。如果未启用抢占或抢占尝试失败,则相关信息将记录在日志中,并且Pod将添加到podQueue的末尾。

2.2 Pod调度选择原理
具体scheduler 给一个 pod 做调度选择包含两个步骤:
- 过滤(预选)阶段,过滤阶段会将所有满足 Pod 调度需求的 Node 选出来。 例如,PodFitsResources 过滤函数会检查候选 Node 的可用资源能否满足 Pod 的资源请求。 在过滤之后,得出一个 Node 列表,里面包含了所有可调度节点;通常情况下, 这个 Node 列表包含不止一个 Node。如果这个列表是空的,代表这个 Pod 不可调度。
- 打分(优选)阶段,在打分阶段,scheduler会为 Pod 从所有可调度节点中选取一个最合适的 Node。 根据当前启用的打分规则,scheduler会给每一个可调度节点进行打分。
- 最后,scheduler 会将 Pod 调度到得分最高的 Node 上。 如果存在多个得分最高的 Node,scheduler 会从中随机选取一个。

2.2.1 预选策略(Predicates)
- PodFitsHostPorts:检查Pod容器所需的HostPort是否已被节点上其它容器或服务占用。若是已被占用,则禁止Pod调度到该节点。
- PodFitsHost:检查Pod指定的NodeName是否匹配当前节点。
- PodFitsResources:检查节点是否有足够空闲资源(例如CPU和内存)来知足Pod的要求。
- PodMatchNodeSelector:检查Pod的节点选择器(nodeSelector)是否与节点(Node)的标签匹配
- NoVolumeZoneConflict:对于给定的某块区域,判断若是在此区域的节点上部署Pod是否存在卷冲突。
- NoDiskConflict:根据节点请求的卷和已经挂载的卷,评估Pod是否适合该节点。
- MaxCSIVolumeCount:决定应该附加多少CSI卷,以及该卷是否超过配置的限制。
- CheckNodeMemoryPressure:若是节点报告内存压力,而且没有配置异常,那么将不会往那里调度Pod。
- CheckNodePIDPressure:若是节点报告进程id稀缺,而且没有配置异常,那么将不会往那里调度Pod。
- CheckNodeDiskPressure:若是节点报告存储压力(文件系统已满或接近满),而且没有配置异常,那么将不会往那里调度Pod。
- CheckNodeCondition:节点能够报告它们有一个彻底完整的文件系统,然而网络不可用,或者kubelet没有准备好运行Pods。若是为节点设置了这样的条件,而且没有配置异常,那么将不会往那里调度Pod。
- PodToleratesNodeTaints:检查Pod的容忍度是否能容忍节点的污点。
- CheckVolumeBinding:评估Pod是否适合它所请求的容量。这适用于约束和非约束PVC。
若是在predicates(预选)过程当中没有合适的节点,那么Pod会一直在pending状态,不断重试调度,直到有节点知足条件。
通过这个步骤,若是有多个节点知足条件,就继续priorities过程,最后按照优先级大小对节点排序。
2.2.2 优选策略(Priorities,即打分策略)
- SelectorSpreadPriority:对于属于同一服务、有状态集或副本集(Service,StatefulSet or ReplicaSet)的Pods,会将Pods尽可能分散到不一样主机上。
- InterPodAffinityPriority:策略有podAffinity和podAntiAffinity两种配置方式。简单来讲,就说根据Node上运行的Pod的Label来进行调度匹配的规则,匹配的表达式有:In, NotIn, Exists, DoesNotExist,经过该策略,能够更灵活地对Pod进行调度。
- LeastRequestedPriority:偏向使用较少请求资源的节点。换句话说,放置在节点上的Pod越多,这些Pod使用的资源越多,此策略给出的排名就越低。
- MostRequestedPriority:偏向具备最多请求资源的节点。这个策略将把计划的Pods放到整个工做负载集所需的最小节点上运行。
- RequestedToCapacityRatioPriority:使用默认的资源评分函数模型建立基于ResourceAllocationPriority的requestedToCapacity。
- BalancedResourceAllocation:偏向具备平衡资源使用的节点。
- NodePreferAvoidPodsPriority:根据节点注释scheduler.alpha.kubernet .io/preferAvoidPods为节点划分优先级。可使用它来示意两个不一样的Pod不该在同一Node上运行。
- NodeAffinityPriority:根据preferredduringschedulingignoredingexecution中所示的节点关联调度偏好来对节点排序。
- TaintTolerationPriority:根据节点上没法忍受的污点数量,为全部节点准备优先级列表。此策略将考虑该列表调整节点的排名。
- ImageLocalityPriority:偏向已经拥有本地缓存Pod容器镜像的节点。
- ServiceSpreadingPriority:对于给定的服务,此策略旨在确保Service的Pods运行在不一样的节点上。总的结果是,Service对单个节点故障变得更有弹性。
- EqualPriority:赋予全部节点相同的权值1。
- EvenPodsSpreadPriority:实现择优 pod的拓扑扩展约束
代码入口路径在release-1.9及之前的代码入口在plugin/cmd/kube-scheduler,从release-1.10起,kube-scheduler的核心代码迁移到pkg/scheduler目录下面,入口也迁移到cmd/kube-scheduler
2.3 如何扩展scheduler?
在真实的生产环境中,Kube-scheduler 可能不能满足我们的需求,我们需要扩展其功能。一般来说有以下4种扩展方式:
- clone 官方 kube-schedule,然后对其进行代码级更改,这种方式有一定的局限性,比如你使用的是托管k8s集群,我们压根无法替换默认的调度器。此外,kubernetes 社区更新迭代比较快,每年会发4个正式版本,我们需要不断地merge上游的代码。
- 实现一个新的调度器,配置 pod.spec.schedulerName 来选择使用哪一个调度器。由于两个调度器并行运行,非常有可能出现资源冲突的问题。
- Scheduler extender。侵入性比较小,可以独立于原生 Scheduler 运行,并且无需修改原生 Scheduler 的代码,只需要在运行原生 Scheduler 的时候加一个配置即可。但是该方式也有一些劣势,比如scheduler extender 和默认调度器之间有一些通信成本,扩展点有限,scheduler extender 和默认调度器无法共享cache。
- Scheduler Framework 。Scheduler Framework 是 Kubernetes Scheduler 的一种可插入架构,可以简化调度器的自定义。 它向现有的调度器增加了一组新的“插件” API。插件被编译到scheduler程序中。 这些 API 允许大多数调度功能以插件的形式实现,同时使调度“核心”保持简单且可维护。
发展至今,Scheduler Framework 是最佳的扩展方案。
2.3.1 Scheduler Framework
Scheduler Framework定义了一些扩展点。调度器插件注册后在一个或多个扩展点处被调用。 这些插件中的一些可以改变调度决策,而另一些仅用于提供信息。
2.3.1.1 工作流程
每次调度一个 Pod 的尝试都分为两个阶段,即 调度周期 和 绑定周期。
调度周期为 Pod 选择一个节点,绑定周期将该决策应用于集群。 调度周期和绑定周期一起被称为“调度上下文”。
调度周期是串行运行的,而绑定周期可能是同时运行的。
2.3.1.2 扩展点

如上图所示,我们简单介绍一下支持的扩展点:
- QueueSort: 对队列中的 Pod 进行排序
- PreFilter: 预处理 Pod 的相关信息,或者检查集群或 Pod 必须满足的某些条件。 如果 PreFilter 插件返回错误,则调度周期将终止。
- Filter: 过滤出不能运行该 Pod 的节点。对于每个节点, 调度器将按照其配置顺序调用这些过滤插件。如果任何过滤插件将节点标记为不可行, 则不会为该节点调用剩下的过滤插件。节点可以被同时进行评估。
- PostFilter: 在筛选阶段后调用,但仅在该 Pod 没有可行的节点时调用。 插件按其配置的顺序调用。如果任何后过滤器插件标记节点为“可调度”, 则其余的插件不会调用。典型的后筛选实现是抢占,试图通过抢占其他 Pod 的资源使该 Pod 可以调度。
- PreScore: 运行评分任务以生成可评分插件的共享状态
- Score: 通过调用每个评分插件对过滤的节点进行排名
- NormalizeScore: 结合分数并计算节点的最终排名
- Reserve: 在绑定周期之前选择保留的节点
- Permit: 批准或拒绝调度周期的结果
- PreBind: 用于执行 Pod 绑定前所需的任何工作。例如,一个预绑定插件可能需要提供网络卷并且在允许 Pod 运行在该节点之前 将其挂载到目标节点上。
- Bind: 用于将 Pod 绑定到节点上。直到所有的 PreBind 插件都完成,Bind 插件才会被调用。
- PostBind: 这是个信息性的扩展点。 绑定后插件在 Pod 成功绑定后被调用。这是绑定周期的结尾,可用于清理相关的资源。
2.3.1.3 Plugin API
插件 API 分为两个步骤。首先,插件必须完成注册并配置,然后才能使用扩展点接口。 扩展点接口具有以下形式。
type Plugin interface {
Name() string
}
type QueueSortPlugin interface {
Plugin Less(*v1.pod, *v1.pod) bool
}
type PreFilterPlugin interface {
Plugin
PreFilter(context.Context, *framework.CycleState, *v1.pod) error
}你可以在调度器配置中启用或禁用插件。 如果你在使用 Kubernetes v1.18 或更高版本,大部分调度插件都在使用中且默认启用。
参考链接
k8s基础介绍(详细)_南柯一梦,笑谈浮生的博客-CSDN博客_k8s基础
kube-scheduler概念与工作流程 - Cylon - 博客园

K8S/Kubernetes社区为您提供最前沿的新闻资讯和知识内容
更多推荐
 1
1 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)