大数据_Spark常见组件
它还会将所有的 Spark 操作转换为 DAG 运算,并负责调度,还要将这些计算分成任务分发到 Spark 执行器上。因为集群管理器不需要知道它实际在哪里运行(只要能管理Spark 的执行器,并满足资源请求就行),所以Spark 可以部署在 Apache Hadoop YARN 和Kubernetes 等一些常见环境中,并且以不同的模式运行。出于数据本地性要求,在分配任务时,根据要读取的数据分区与
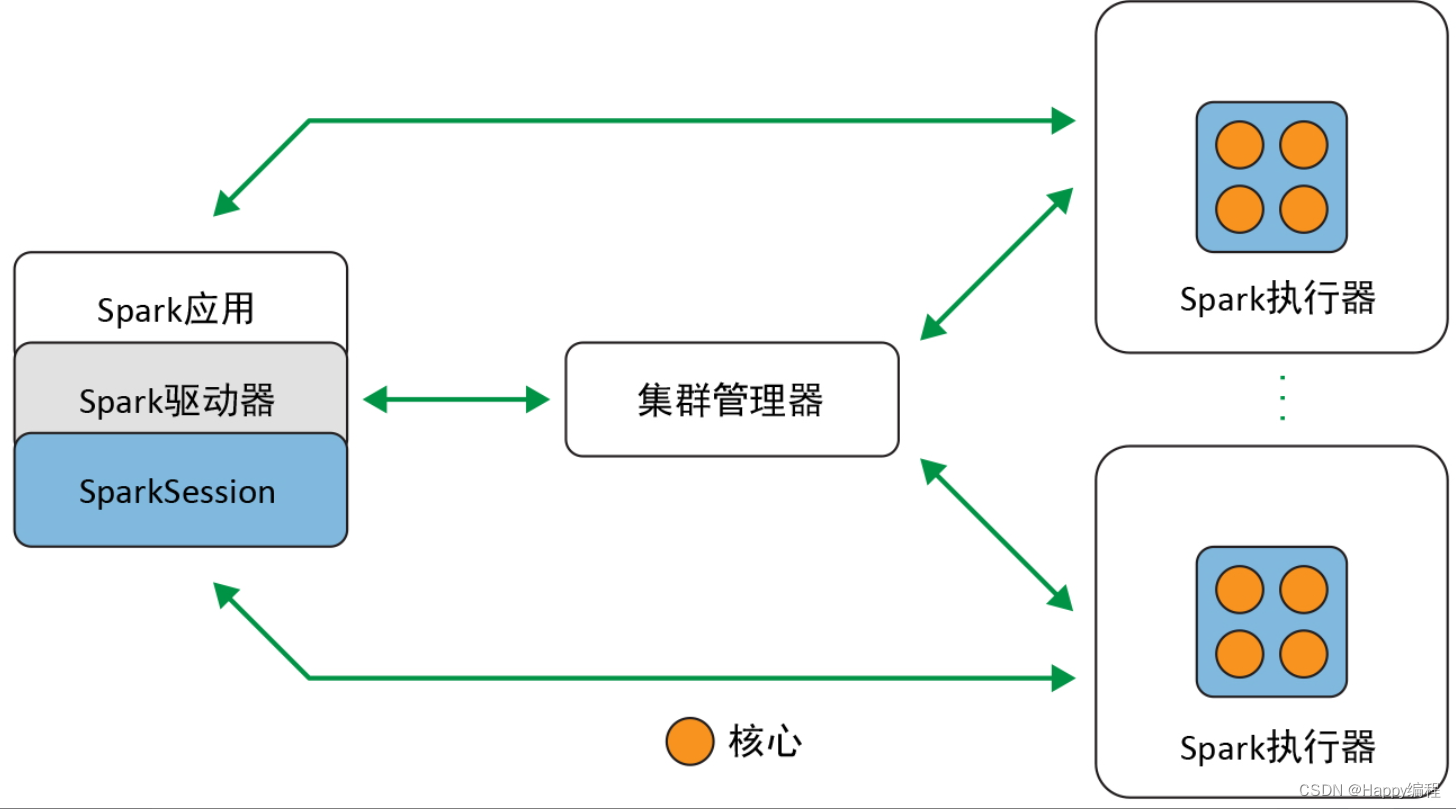
Spark 是一个分布式数据处理引擎,其各种组件在一个集群上协同工作,下面是各个组件之间的关系图。
Spark驱动器
作为 Spark 应用中负责初始化 SparkSession 的部分,Spark 驱动器扮演着多个角色:它与集群管理器打交道;它向集群管理器申请 Spark 执行器(JVM)所需要的资源(CPU、内存等);它还会将所有的 Spark 操作转换为 DAG 运算,并负责调度,还要将这些计算分成任务分发到 Spark 执行器上。一旦资源分配完成,创建好执行器后,驱动器就会直接与执行器通信。
SparkSession
在 Spark 2.0 中,SparkSession 是所有 Spark 操作和数据的统一入口。它不仅封装了 Spark 程序之前的各种入口(如 SparkContext、SQLContext、HiveContext、SparkConf,以及 StreamingContext 等),还让 Spark 变得更加简单、好用。
通过这个入口,可以创建 JVM 运行时参数、定义 DataFrame 或 Dataset、从数据源读取数据、访问数据库元数据,并发起 Spark SQL 查询。SparkSession 为所有的 Spark 功能提供了统一的入口。
集群管理器
集群管理器负责管理和分配集群内各节点的资源,以用于 Spark 应用的执行。目前,Spark 支持 4种集群管理器:Spark 自带的独立集群管理器、Apache Hadoop YARN、Apache Mesos,以及Kubernetes。
Spark执行器
Spark 执行器在集群内各工作节点上运行。执行器与驱动器程序通信,并负责在工作节点上执行任务。在大多数部署模式中,每个工作节点上只有一个执行器。
部署模式
支持多种部署模式是 Spark 的一大优势,这让Spark 可以在不同的配置和环境中运行。因为集群管理器不需要知道它实际在哪里运行(只要能管理Spark 的执行器,并满足资源请求就行),所以Spark 可以部署在 Apache Hadoop YARN 和Kubernetes 等一些常见环境中,并且以不同的模式运行。

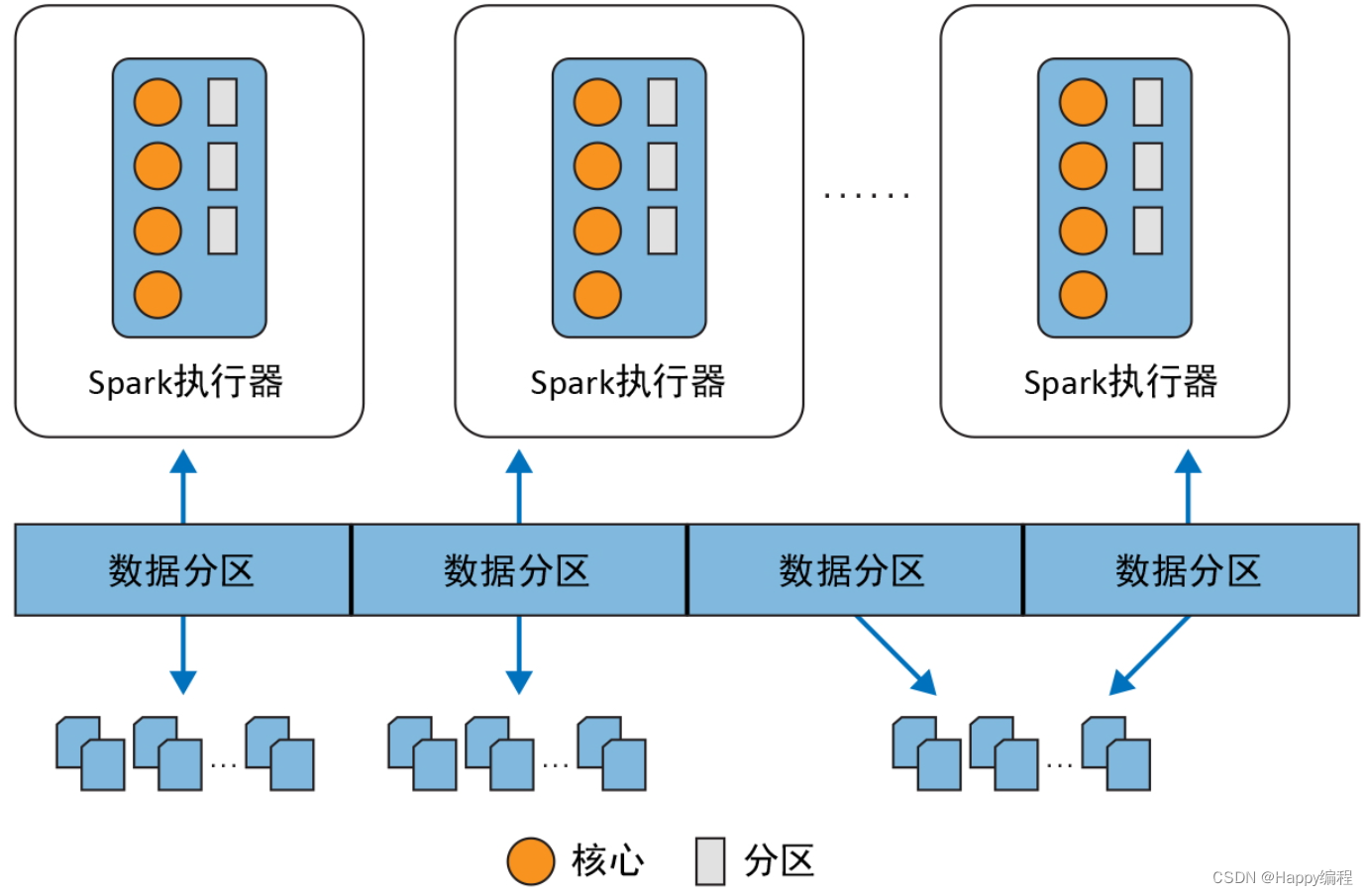
分布式数据与分区
实际的物理数据是以分区的形式分布在 HDFS 或者云存储上的,如图下图。数据分区遍布整个物理集群,而 Spark 将每个分区在逻辑上抽象为内存中的一个DataFrame4。出于数据本地性要求,在分配任务时,根据要读取的数据分区与各Spark 执行器在网络上的远近,最好将任务分配到最近的 Spark 执行器上。

分区可以实现高效的并行执行。将数据切割为数据块或分区的分布式结构可以让Spark 执行器只处理靠近自己的数据,从而最小化网络带宽使用率。也就是说,执行器的每个核心都能分到自己要处理的数据分区,如图所示:

开源、云原生的融合云平台
更多推荐
 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)