

深度学习入门(2)
小白的深度学习笔记
七、计算机视觉
1.卷积神经网络(CNN)
① 边缘检测
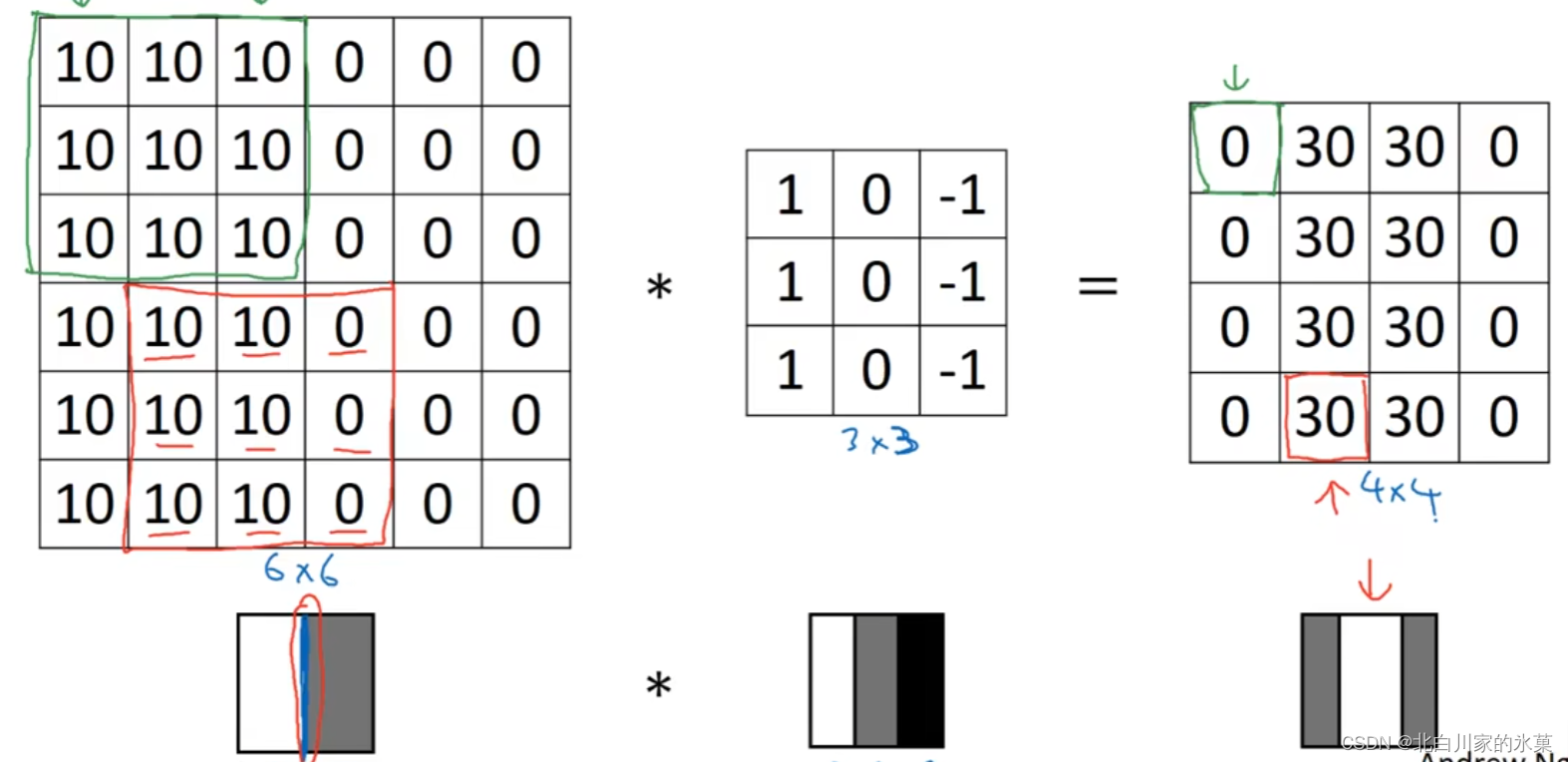
(1)垂直边缘检测器:

这个小矩阵成为filter(过滤器),有时也成为(卷积)核
计算过程如下:


原理:
如图:
(2)正边和负边
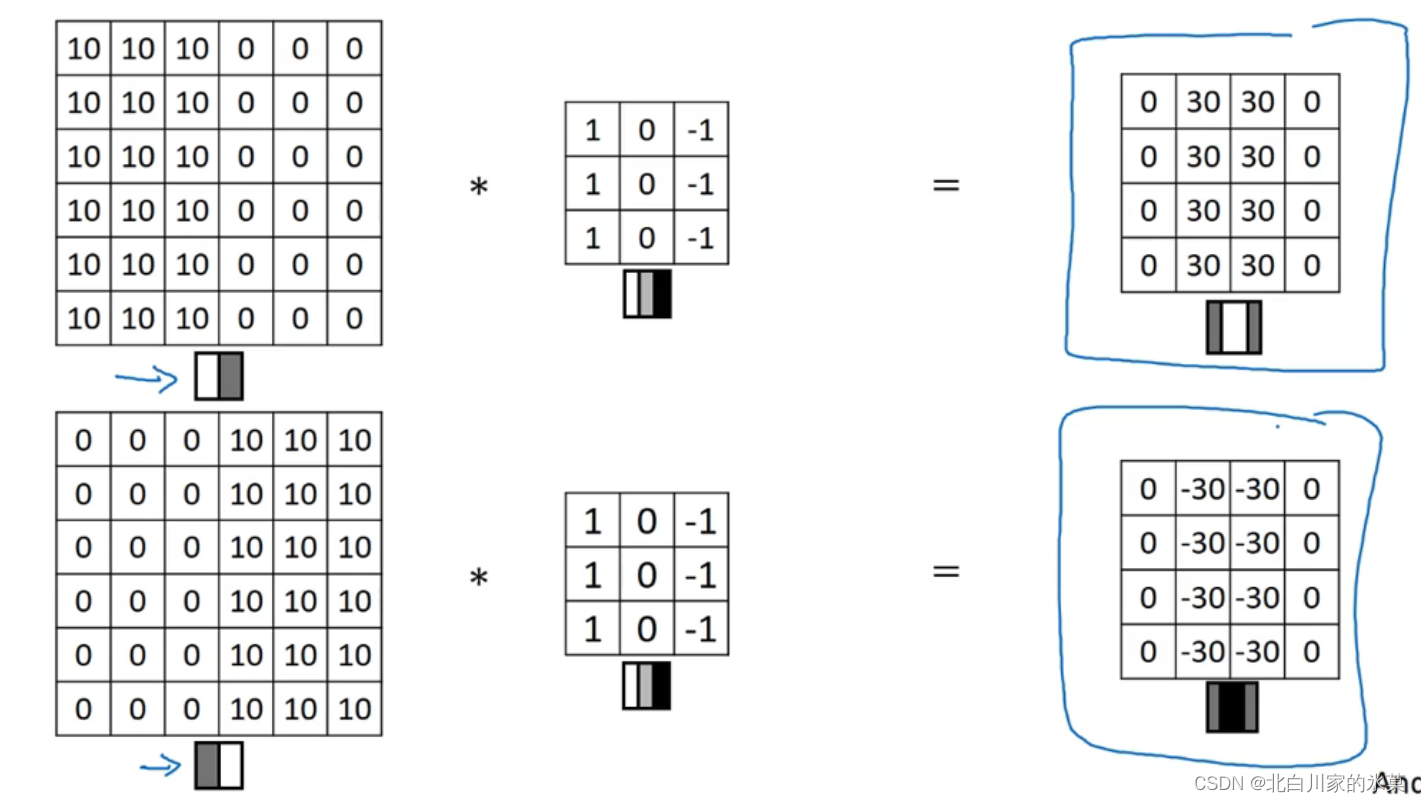
与上面的对比,下面的这个明暗反了过来
(3)横向边缘检测

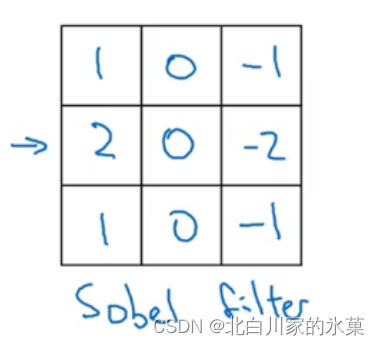
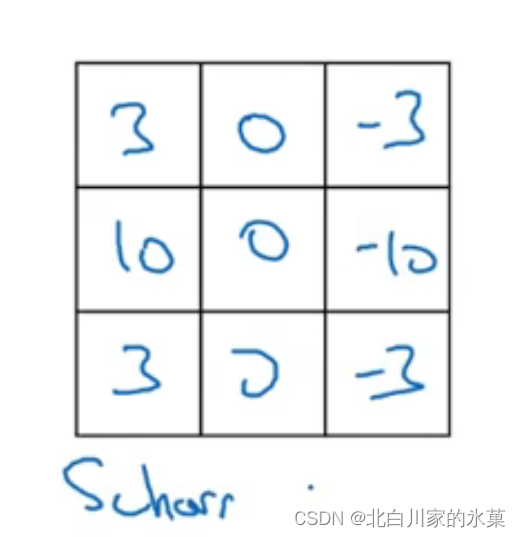
(4)sobel filter 和scharr filter(可以增强鲁棒性)
② padding
使用① 中的方法的弊端:
(1)图片会越来越小,新的图片的维度为n-f+1
(2)角落的像素只触碰一次,但是中间的像素多次被触碰
解决方法:卷积之前填充原图像的边缘,比如用0填充
输出为(n+2p-f+1)维,p为padding(填充)数
valid convolution:不进行填充
same convolution:进行填充,卷积前后图片大小不变 →
③ 卷积步长
若进行卷积的时候,一次不是移动一格,而是两格,则:
新矩阵维度为(若不整除向下取整)
④ 三维卷积
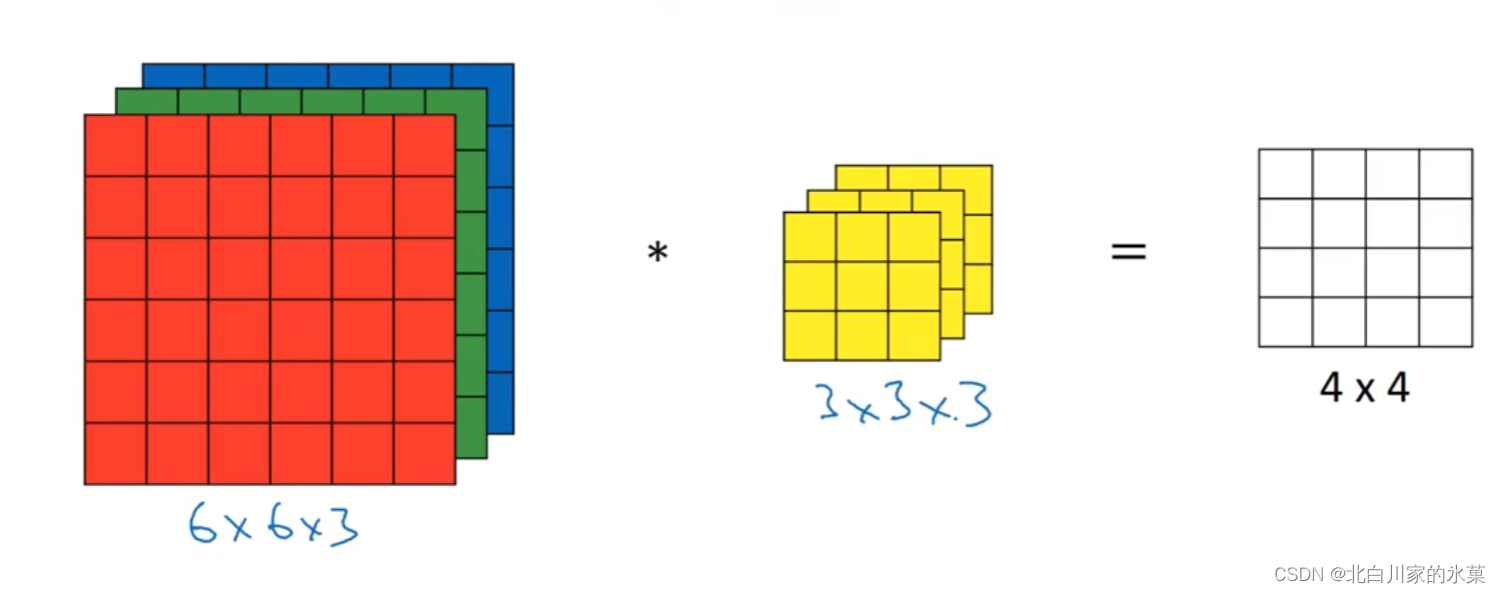
计算过程和平面卷积相似
多个过滤器的结果可以堆叠,如图:
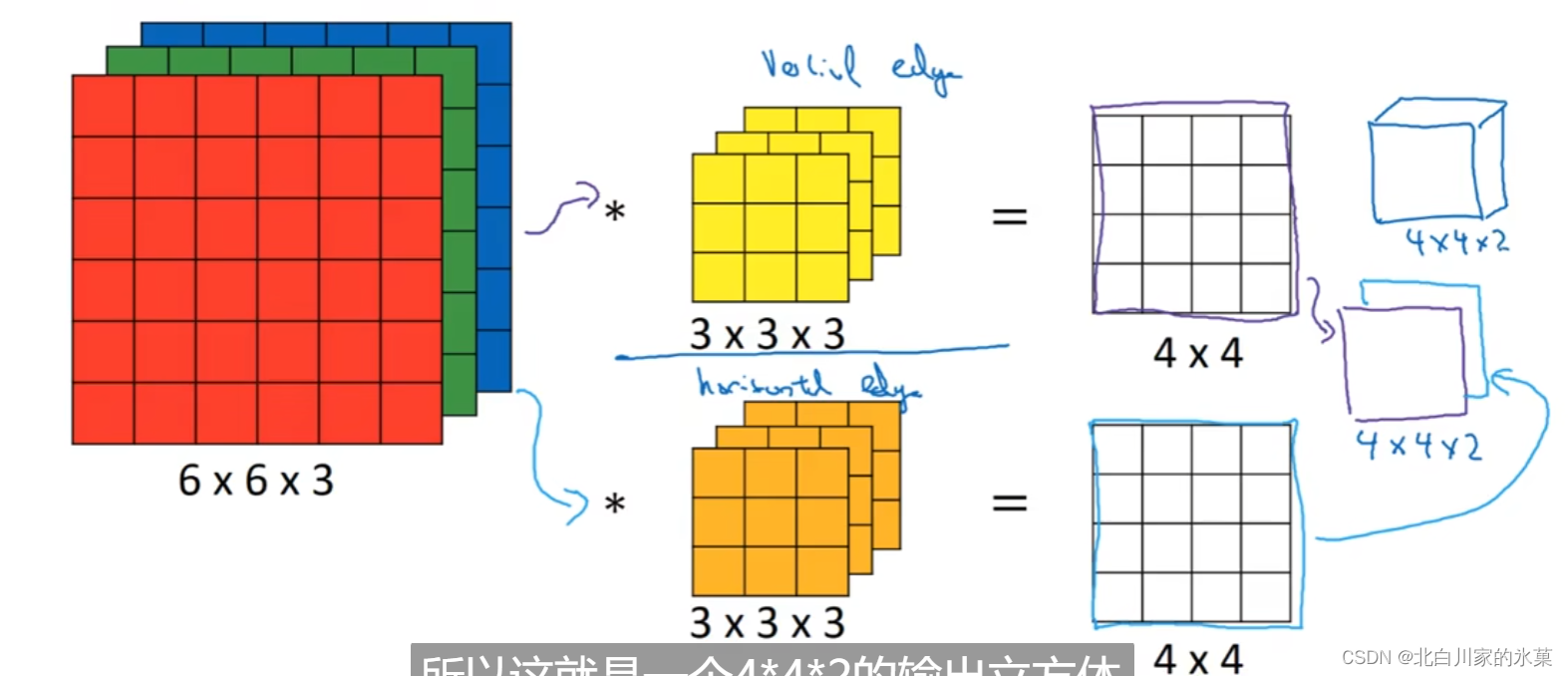
⑤ 单层卷积网络的构造
处理流程:
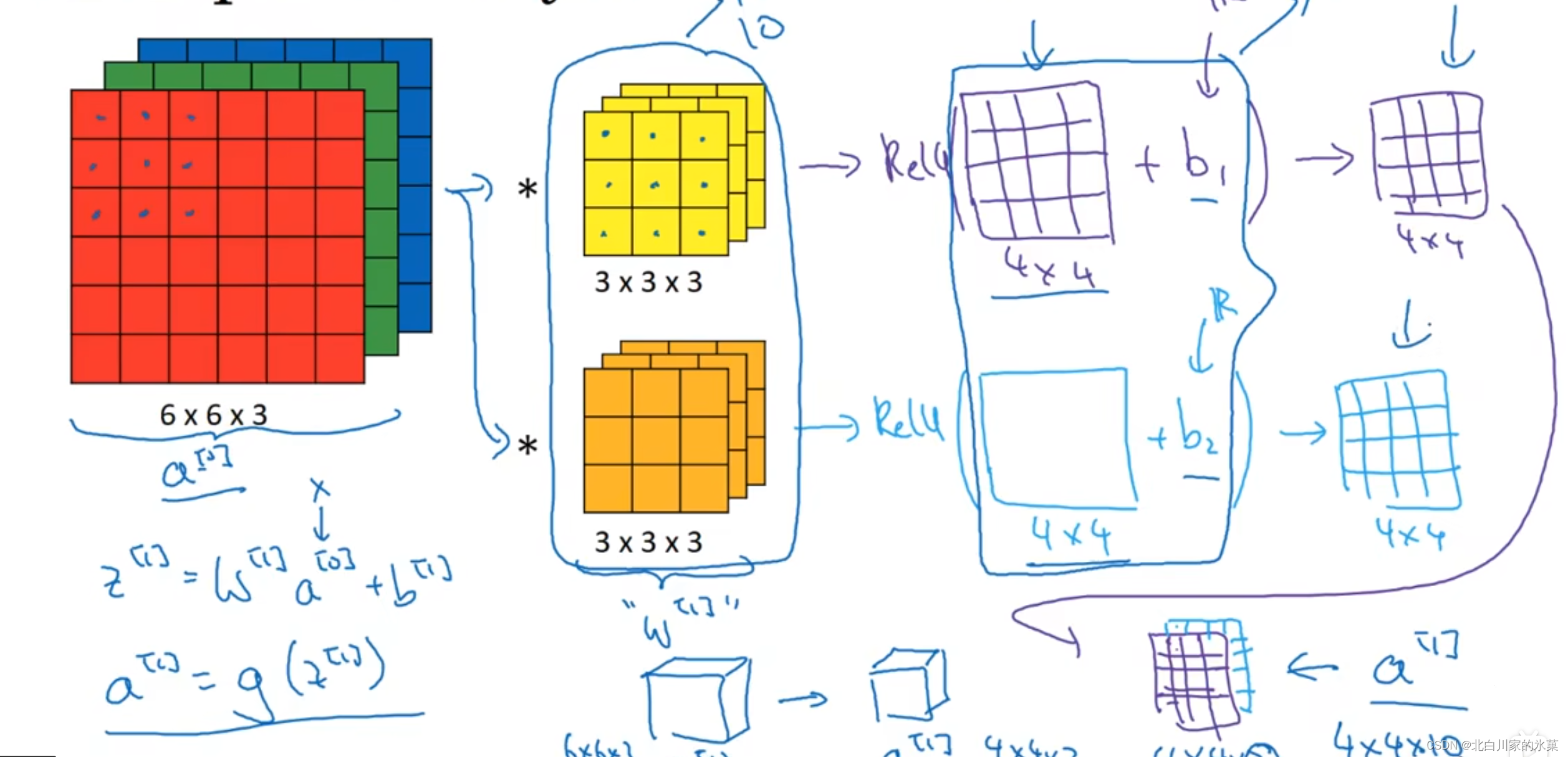
(1)原图像经过卷积,可能是一种处理(如纵向边缘检测),也可能是多种,卷积后获得若干(处理途径的数量决定)个单层图像,这些图像要加上偏差后进行Relu处理,再进行叠加,这就是到
的变化过程
常见负号表示:
:卷积核大小
:补充的大小
:步长大小

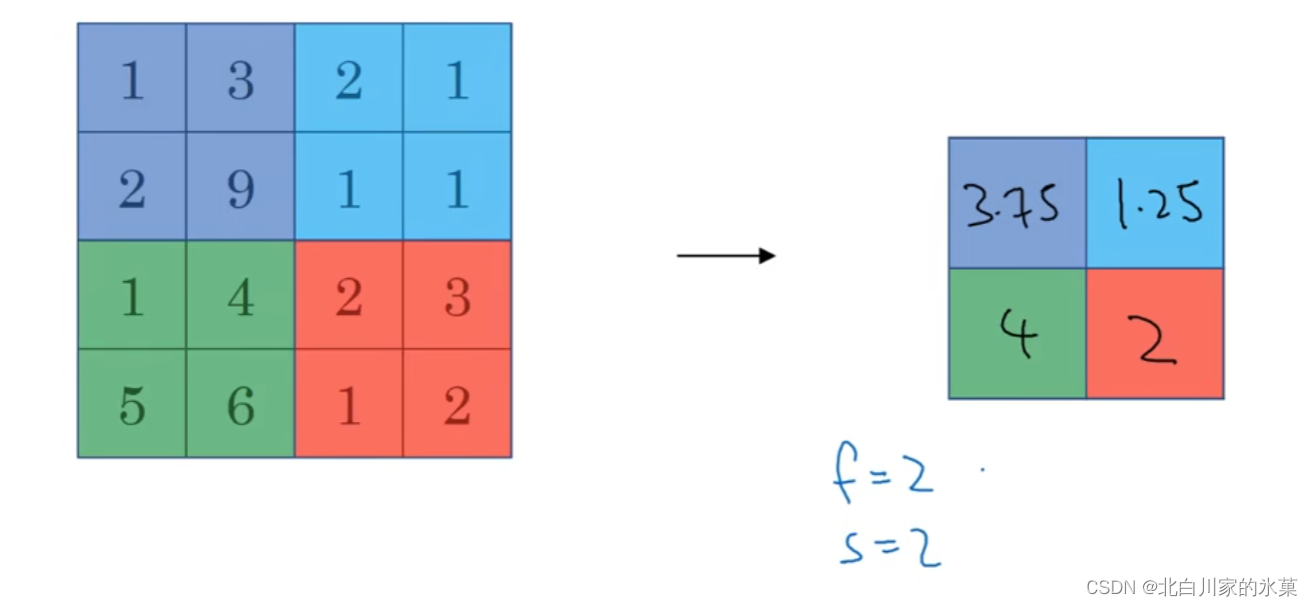
⑥ 池化层
作用:提高运算速度,提高所提取特征的鲁棒性
i.max pooling

最大化操作的功能:在任何一个象限内提取到的特征会保存在池化层
最大化池化只有f和s两个超参数,没有学习过程
注:一般情况下,max pooling不用进行padding填充
ii.average pooling
⑦ CNN实例

一般地 ,在处理过程中,图片的宽和高都会下降,通道数则不断上升
最后将池化层平整化成一个向量(长长的),然后通过全连接层再进行几次影射,最后送入sm层
卷积的好处:
大大减小了参数的量,如果使用传统网络,参数规模要比卷积网络大得多。
原因:参数共享;输出之间关联较弱

总结:先卷积,再池化,最后全连接层进行梯度下降
2.经典网络
① LeNet
用途:针对灰度图像训练

因为是灰度图像,所以一开始只有一个维度
② Alexnet
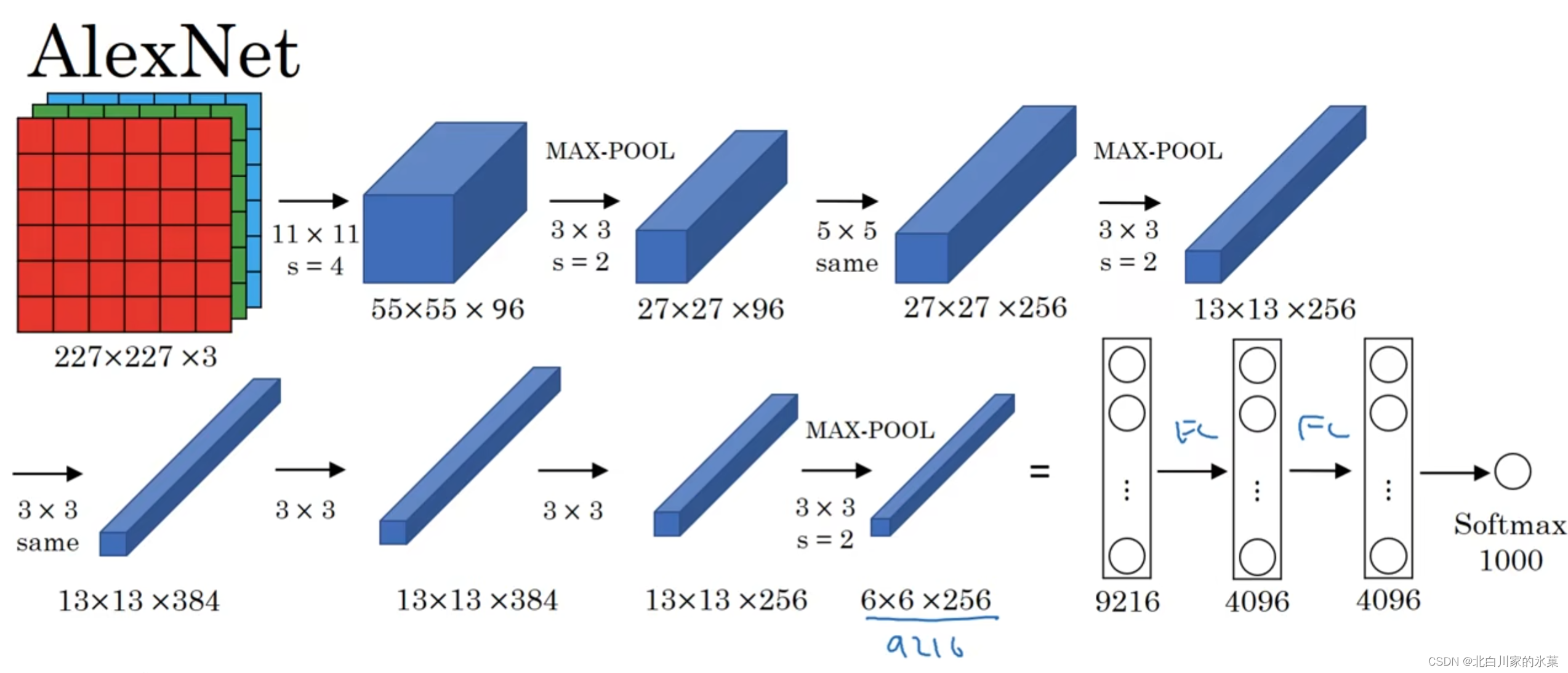
大约有6000w个参数,使用了Reluctant激活函数
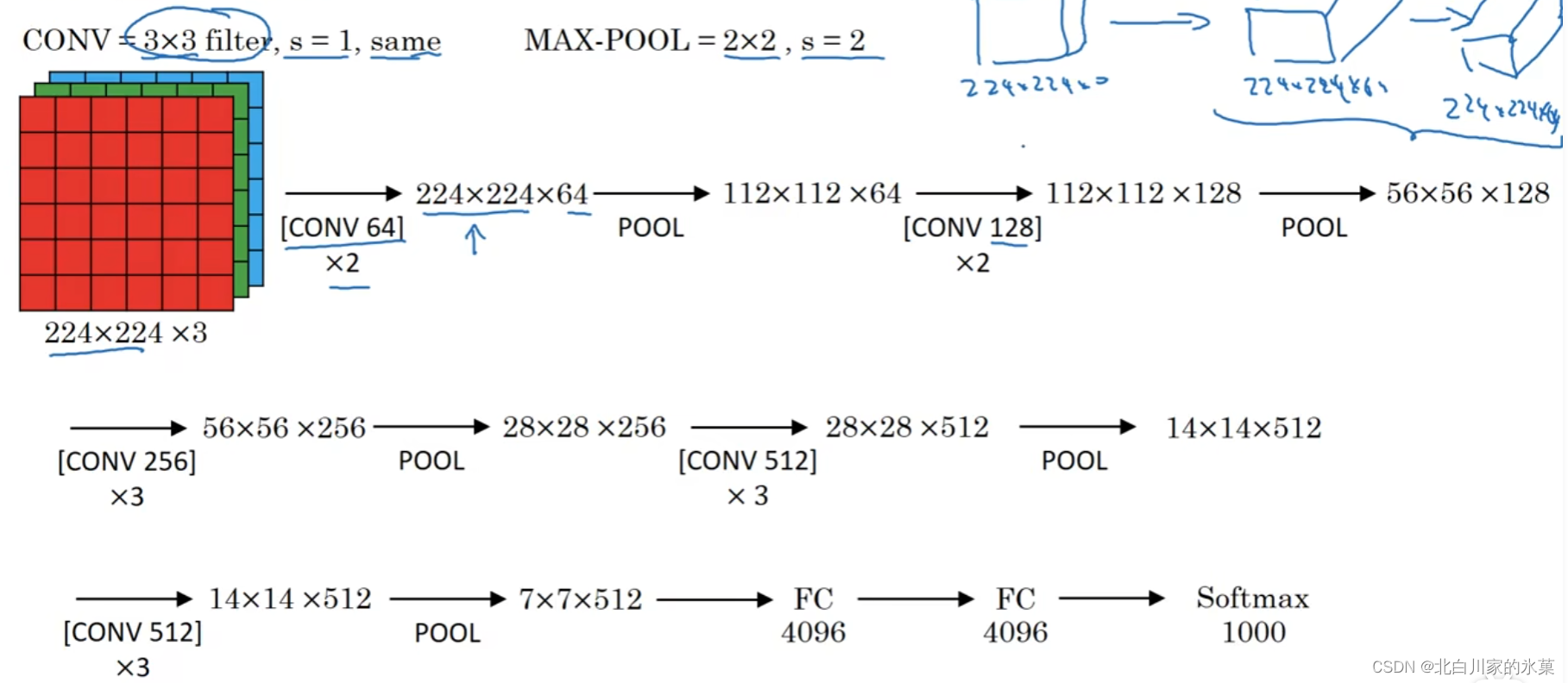
③ VGG-16
优点:大大简化了网络架构
④ ResNet(残差网络)
本质上是一个前馈神经网络,如图:

即把某一层直接前馈到两层或更多层之后
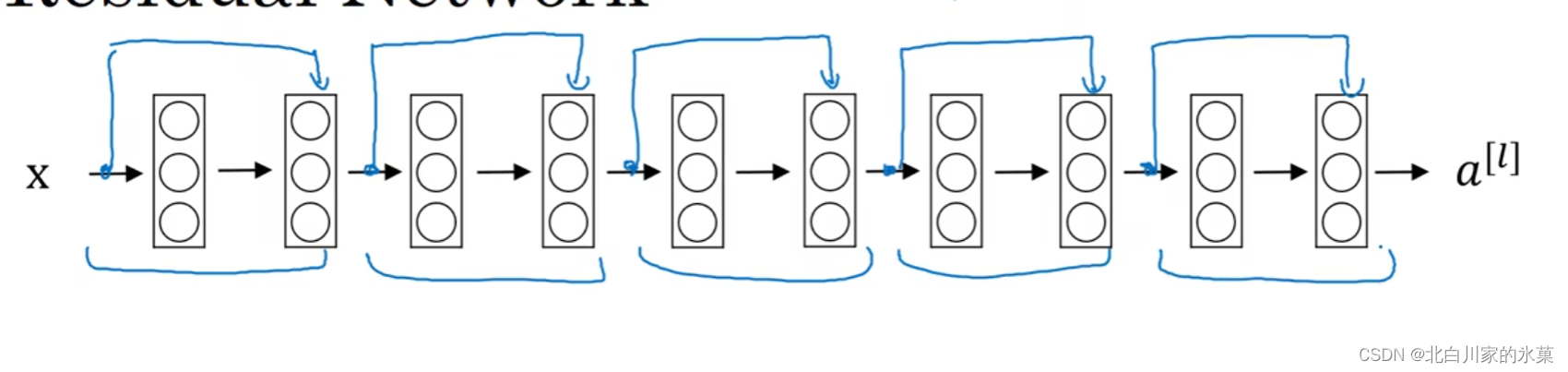
对于一般的神经网络,如果网络层数过多的话,虽然理论上是越多越好,但是实际上层数过多导致学习困难,因此导致错误越来越多。
但是有了ResNet后,随着网络变深,也不会提高错误,可以解决梯度爆炸和梯度消失问题
⑤ 1×1 卷积
可以用来压缩、提高通道数,即升降维度,如图:

可以大大降低计算量
⑥ inception 网络
基本原理:当我们不确定哪种维度的计算比较好时,我们可以将所有的计算都做出来,然后将输出合并
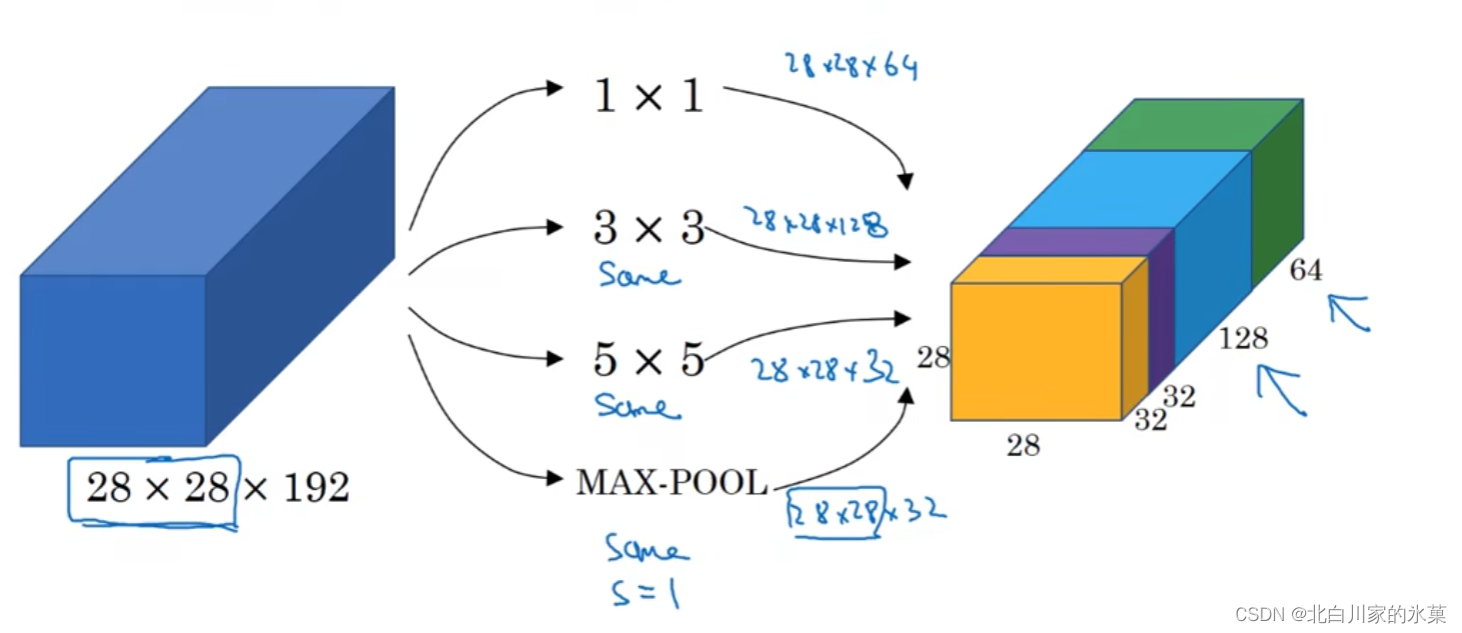
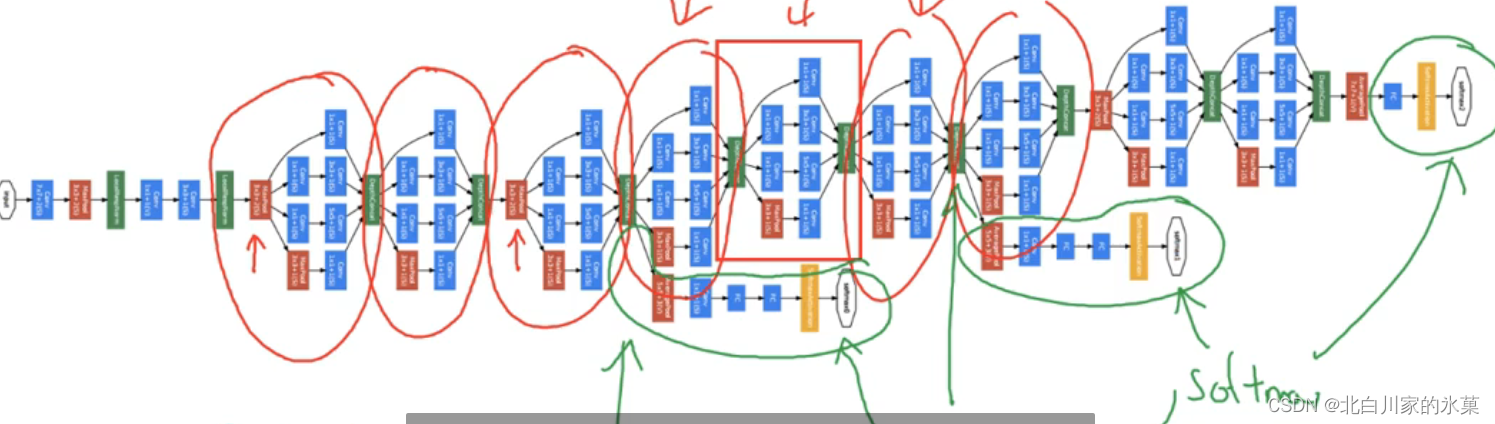
上图为Googlenet
3.目标检测
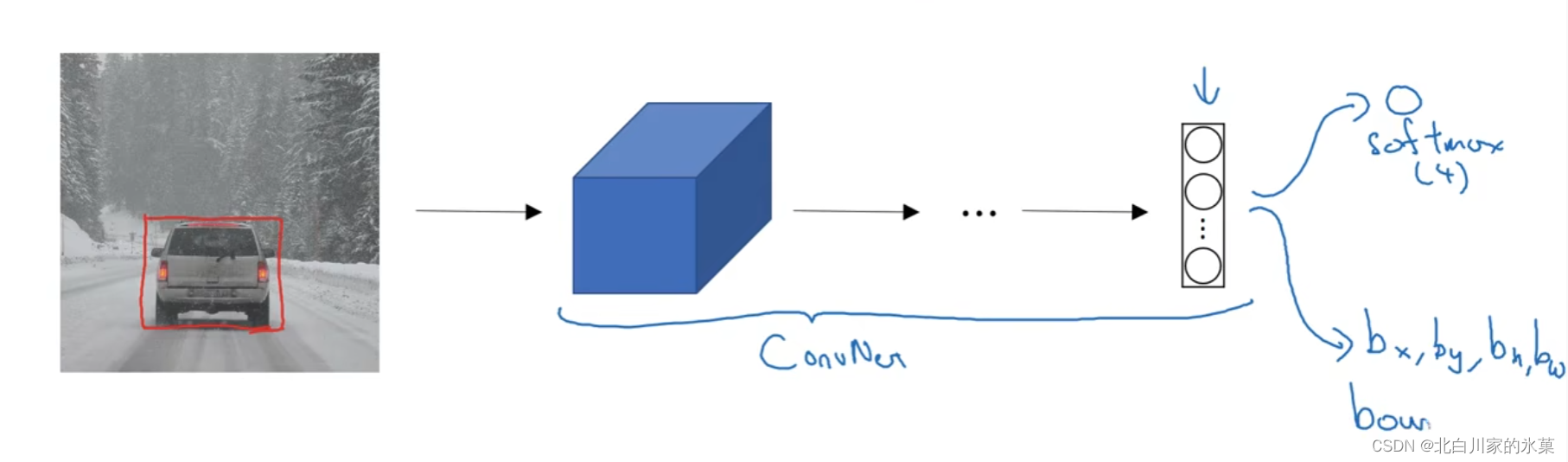
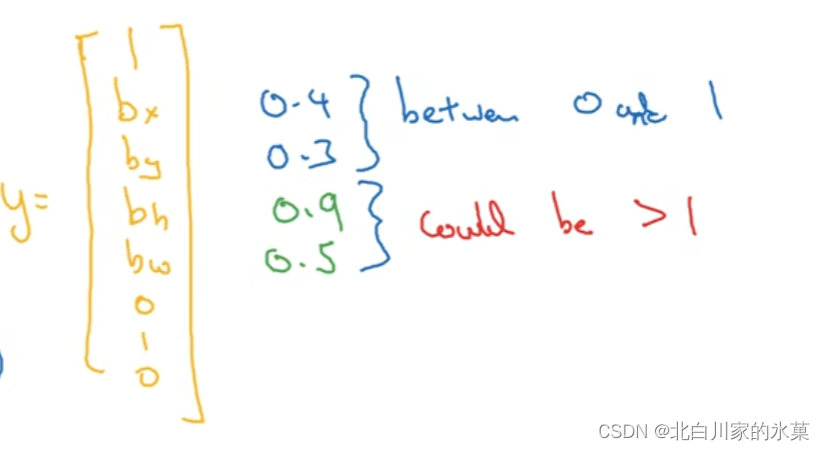
方法:让网络多输出四个对象,即边框的四个参数:中心的x,y坐标,以及宽和高
输出向量如下:
有两种情况,
| 有目标 | 无目标 | |
| 向量 | ||
| 代价函数 |
① 特征点检测
输入是图像,输出是感兴趣的若干组点的坐标,这里训练集的标签上的坐标都是手动标记的,输出的结果的坐标点顺序也应该和训练集标记的顺序一样

② 窗口滑动检测
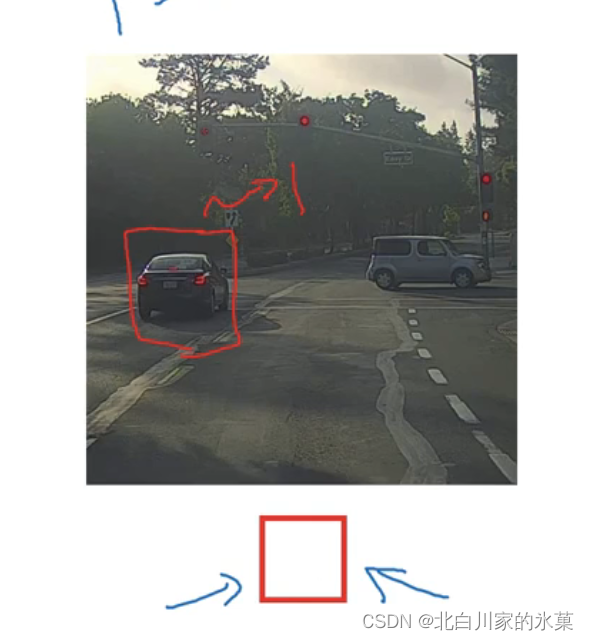 问题:计算量很大
问题:计算量很大
在卷积层实现滑动窗口:

上图是用卷积层代替全连接层的过程

假如14×14是想要去识别的区域,在第一步先用神经网络训练好,接下来我们希望在16×16中找到他,本来有四种取法,但是如果直接在原图取,重复性太大,所以我们先做卷积,处理成2×2后再滑动窗口
说白了就是卷积的过程等效了滑动窗口地方过程
③ 边界框的预测
如果按照滑动窗口法,无法完美圈出目标,怎么办?
将图像分割,将待检测对象分配给对象中心所在的区域,如图:(YOLO)
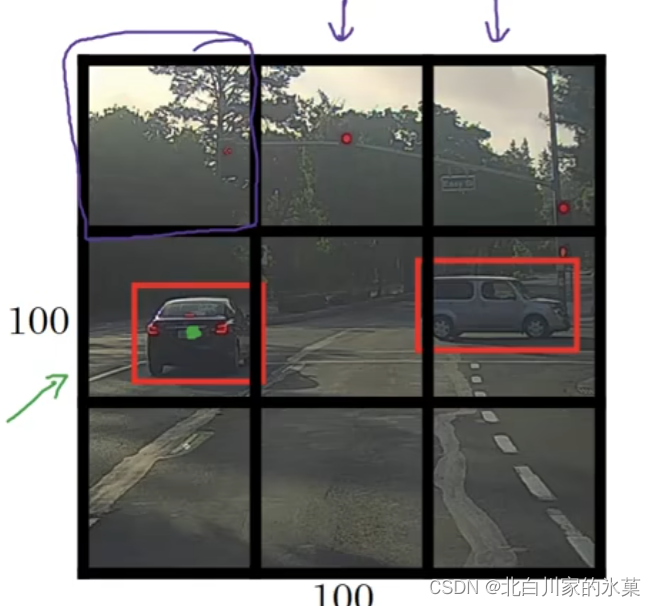
输出为3×3×8的向量,3×3是因为有九个格,89是因为向量是8维,第一位是有没有目标,2345是框的位置和大小,最后三维是具体是什么东西

翻译上面的流程:输入一个100×100,3通道图片,经过CNN卷积池化一顿算,搞成3×3×8向量,这个向量就是相当于原图像分为了9份
这个算法的优势是并没有把每个分割区域都计算一遍,导致大量重复计算,大大减小了计算量
框框的确定:
我们可以根据前面的分析确定中心在那个格子里面,那么接下来就是分析框框大小。首先中心的位置和框框的大小都进行了归一化,都是相对格子的边长的相对值。边框的边长可以大于格子长度
④ 交并比(IoU)

交并比=相交面积/总面积
若交并比大于0.5,说明预测正确
⑤ 非最大值抑制(NMS)
作用:防止一个对象被检测过多次
通过上面的计算,我们得到的结果中可能出现对于一个对象,有多个格子认为该对象就在自己里面
具体步骤:

NMS的做法是,首先,对每个类别,NMS先统计每个预测结果输出的属于该类别概率,并将预测结果按该概率由高至低排序。其次,NMS认为对应概率很小的预测结果并没有找到目标,所以将其抑制。然后,NMS在剩余的预测结果中,找到对应概率最大的预测结果,将其输出,并抑制和该包围盒有很大重叠(如IoU大于0.3)的其他包围盒。重复上一步,直到所有的预测结果均被处理。
⑥ anchor boxes(一个框内找到多个目标)



⑦ R-CNN

在感兴趣的区域判断是否存在目标
改进:


参考:(二)计算机视觉四大基本任务(分类、定位、检测、分割) - 知乎
4.人脸识别
① similarity 函数
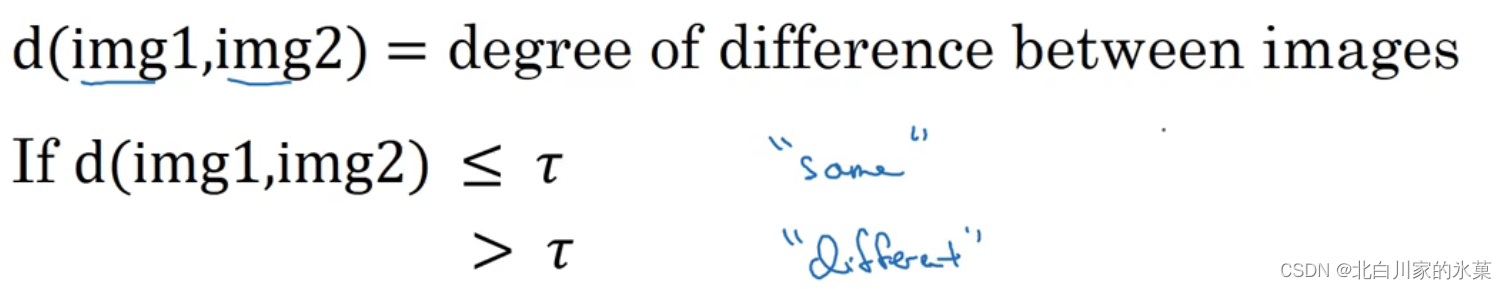
由于用已有人的照片去训练训练集太小,而且如果人变多了还得重新训练,所以定义了以上”找不同“函数
② siamese 网络
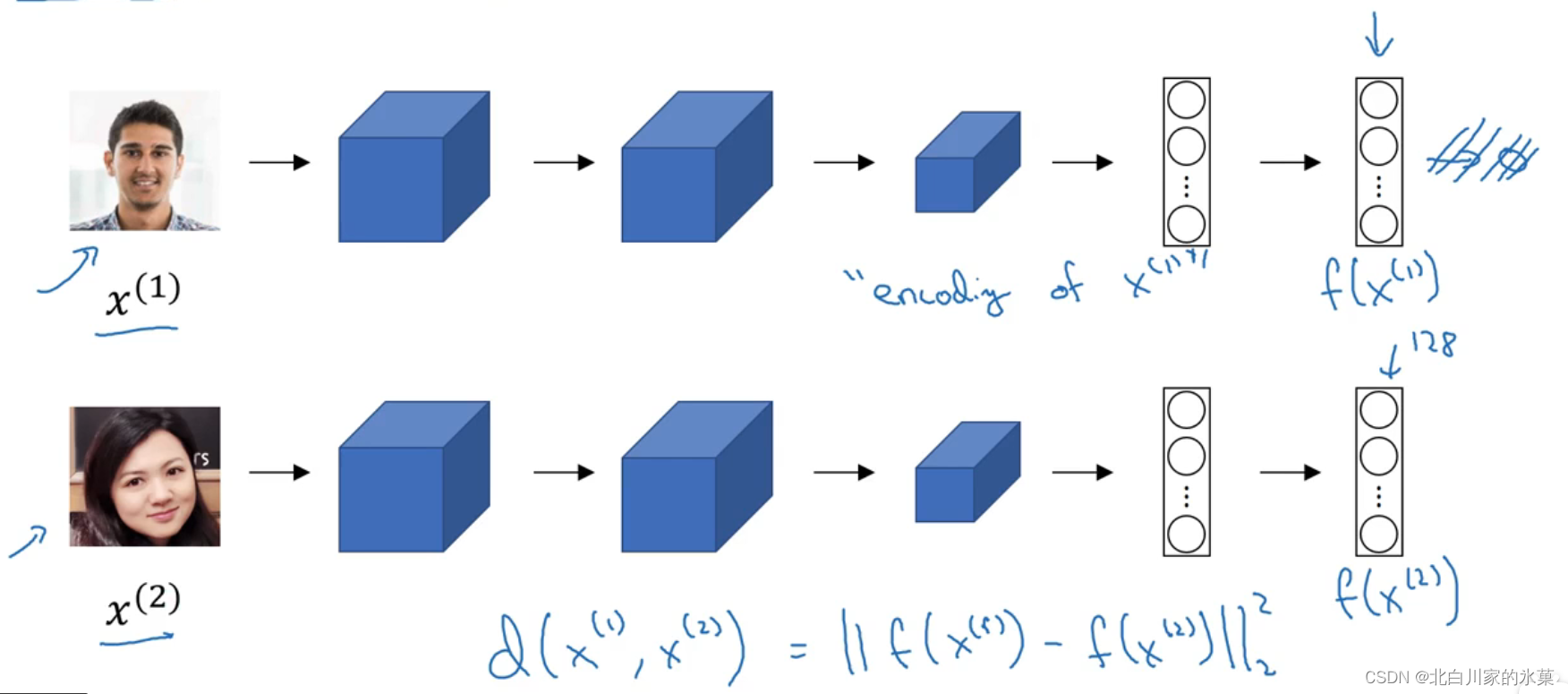 比较经过网络处理的128维度的向量,求他们的欧几里得距离,如果距离足够小,则判定为是同一人
比较经过网络处理的128维度的向量,求他们的欧几里得距离,如果距离足够小,则判定为是同一人
③ triplet损失
(1)APN
A:anchor 即用于对比的图片
P:positive 即与anchor一样的图片
N:negative 即与anchor不一样的图片

我们希望:
移相后:
为了防止所有的输出都是0(也满足上面的方程),我们让等式右侧不能是0,而是一个值
这个值也是个超参数
注:为了定义三元组的数据集,我们需要成对A,P,每个人不能只有1张图片
同时,不同人的图片虽然满足A,N,但是这很容易达成
所以我们要选择更难以训练的训练集,使得:

经过训练后,该网络有能力将照片编码成一个128元素向量,相似的图片编码出来的向量起码应该是差不多的,相差较大的图片编码出来的向量相差较大
④ 另一种方法——二分类

我们提前会算好,当一个人接近时,我们用网络计算出向量,最后作差计算输出,判断是否是本人
⑥ 神经风格转换

![]()
内容代价函数:

风格代价函数:
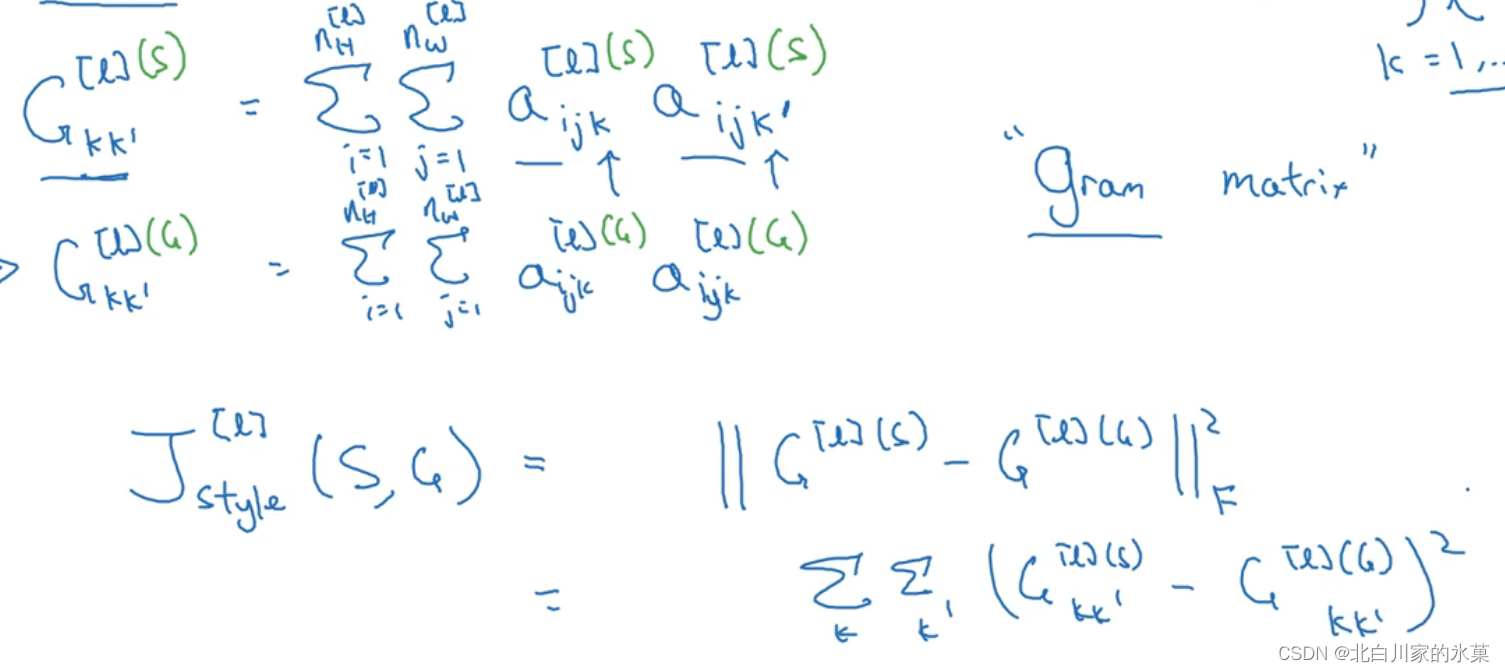
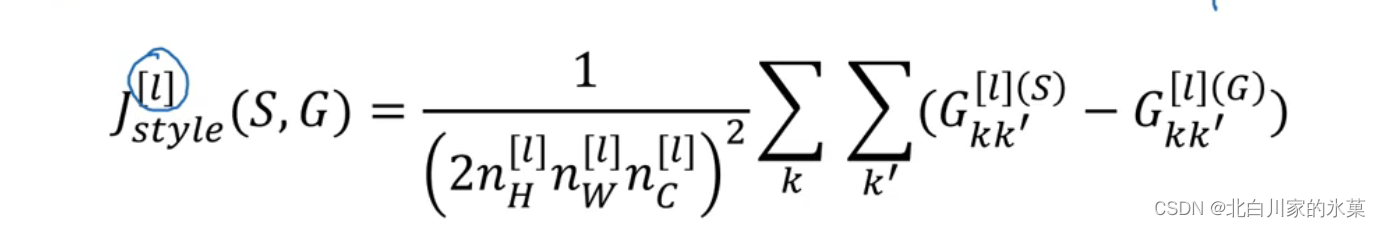
八、序列模型
1.序列的表示
,其中i表示第i个样本,t表示序列中第t个元素
,表示第i个样本的长度,其中不同样本的长度可能不一样
单词的表示方法:
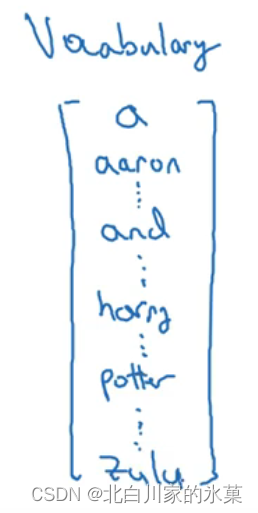
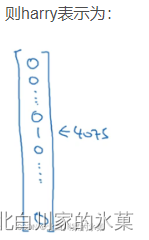
<UNK>表示不在单词表里的单词
2.RNN
若使用标准神经网络,如图:
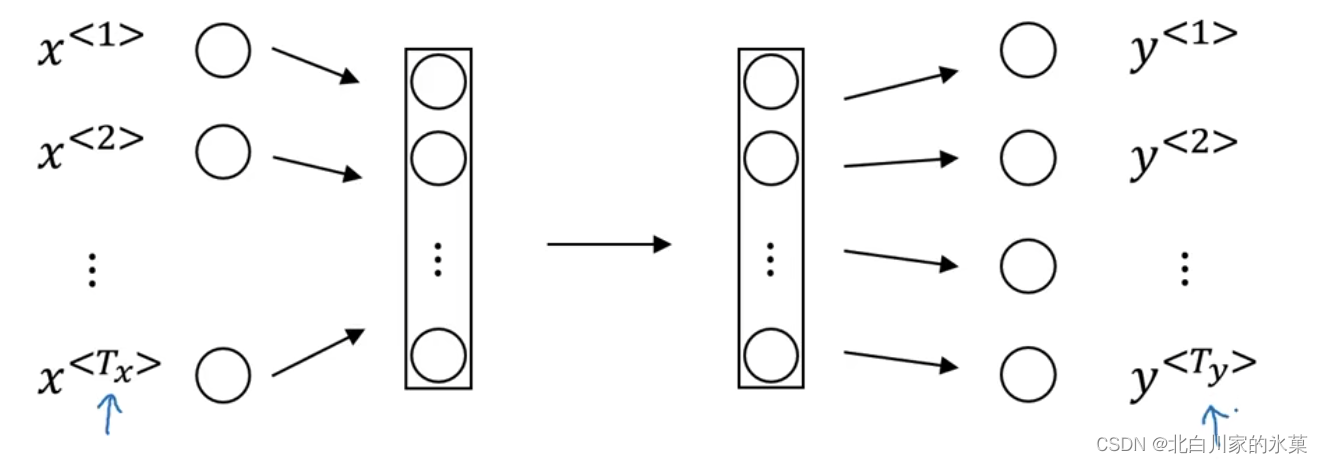
有一个问题,每个输入的句子长度不一样,同时推广性比较差,如果在第一个位置识别出harry是人名,我们希望在第t个位置也能识别出来,因此引入循环神经网络
正向传播过程:


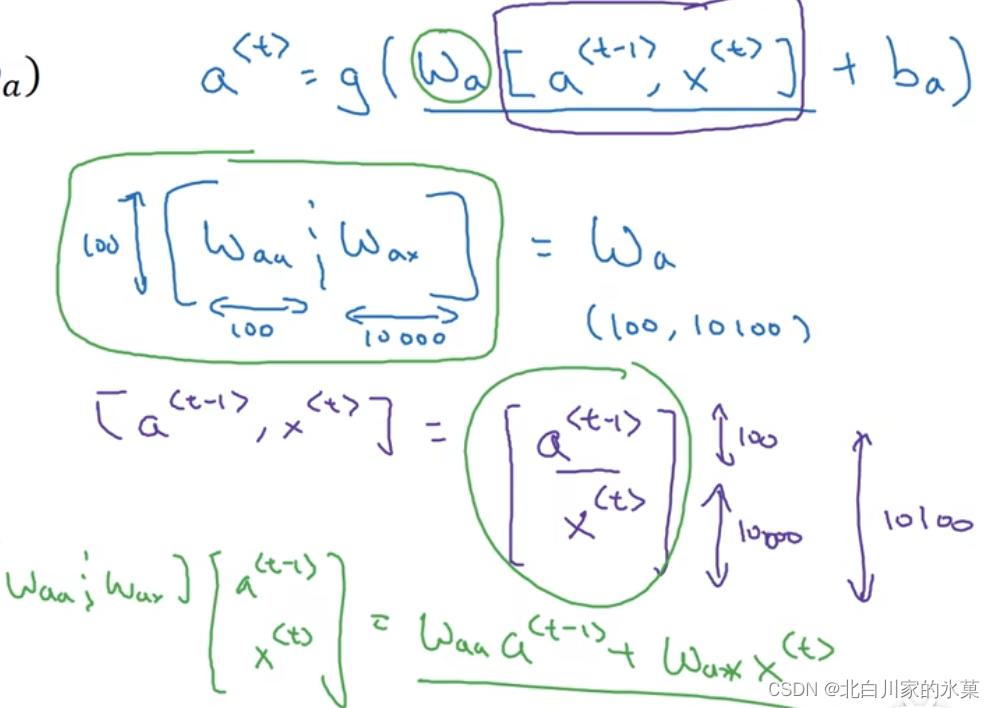
反向传播过程:
损失函数:
不同类型的RNN:
① 当时 →many to one/one to many/many to many
例:输入评价,输出评分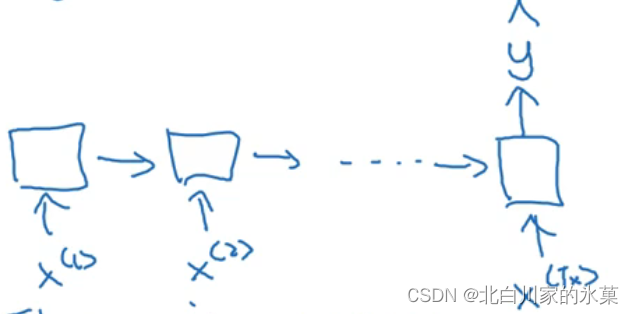
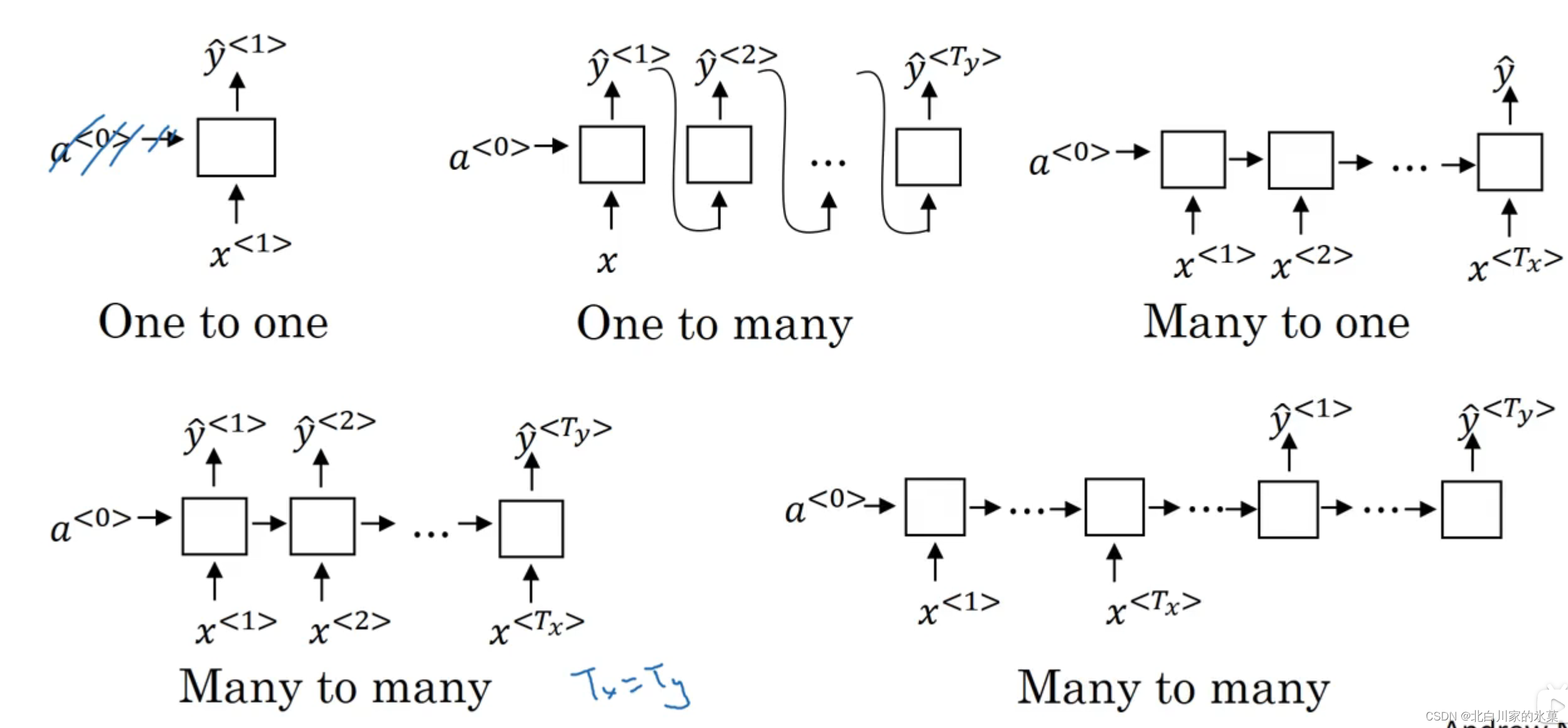
3.语言模型和序列生成
<EOS>:end of sentense
<UNK>:不在单词表中的单词
以语音识别为例,如何判断人说的是什么,是根据这个句子出现的概率判断的

每一个输出都是一个softmax,数量是字典的大小加上EOS和UNK
新序列采样:了解模型学到了什么
采样方法:

注意这是采样的过程
4.带有神经网络的梯度消失
由于梯度消失问题,序列中隔得比较远的元素很难互相影响,比如
![]()
输出基本只是靠附近的输入影响,而很难受很远的地方的输入的影响,这就是RNN的缺点,即不擅长处理长期依赖问题
5.Gated Recurrent Unit (GNU) →解决梯度消失
该结构具有memory cell(c),
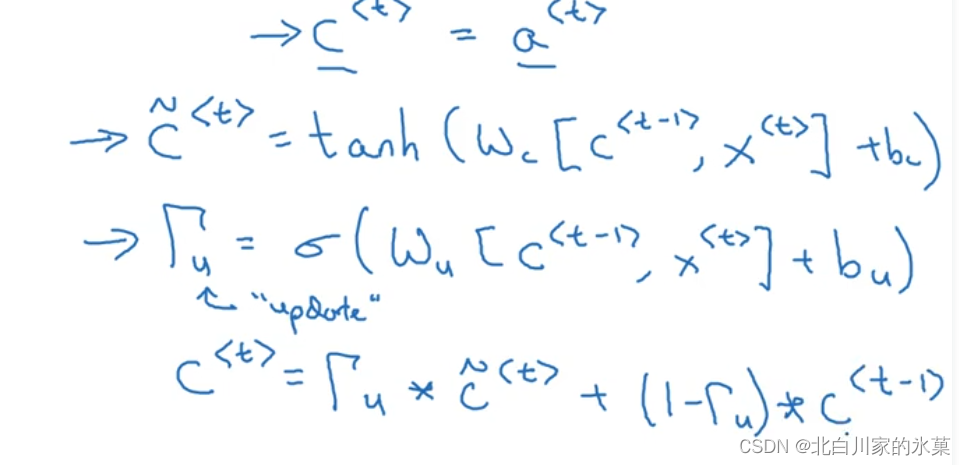
其中,是用来代替
的候选
以这句话为例:
The car ,which already ate ....,was full.
到cat时,发现是单数,将记忆细胞更新为1,中间的单词不用更新,所以门的值一直是0,直到was那里再更新
Full GRU
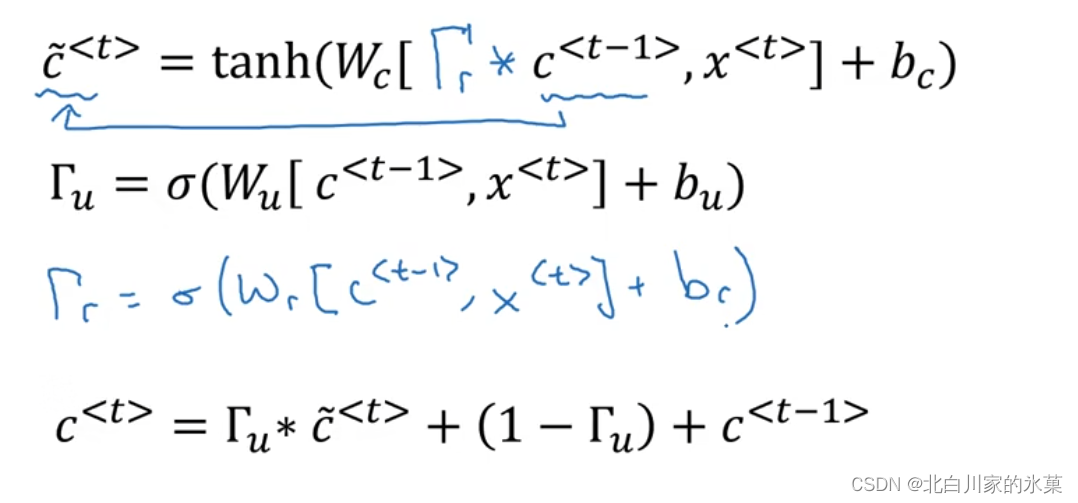
6.LSTM
作用:也可以一定程度减轻梯度爆炸和梯度消失两个问题
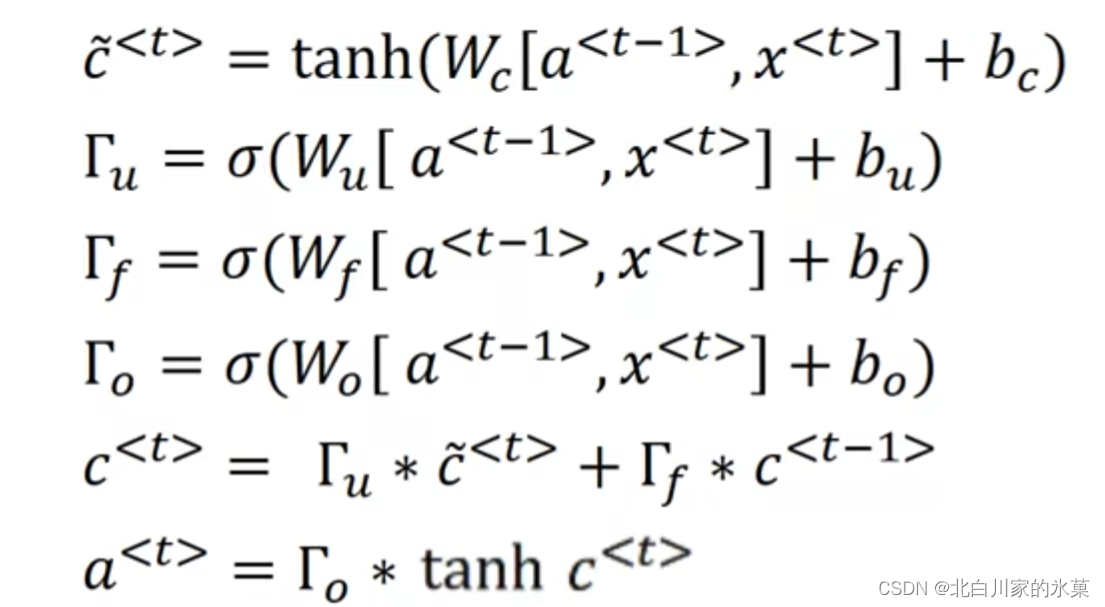
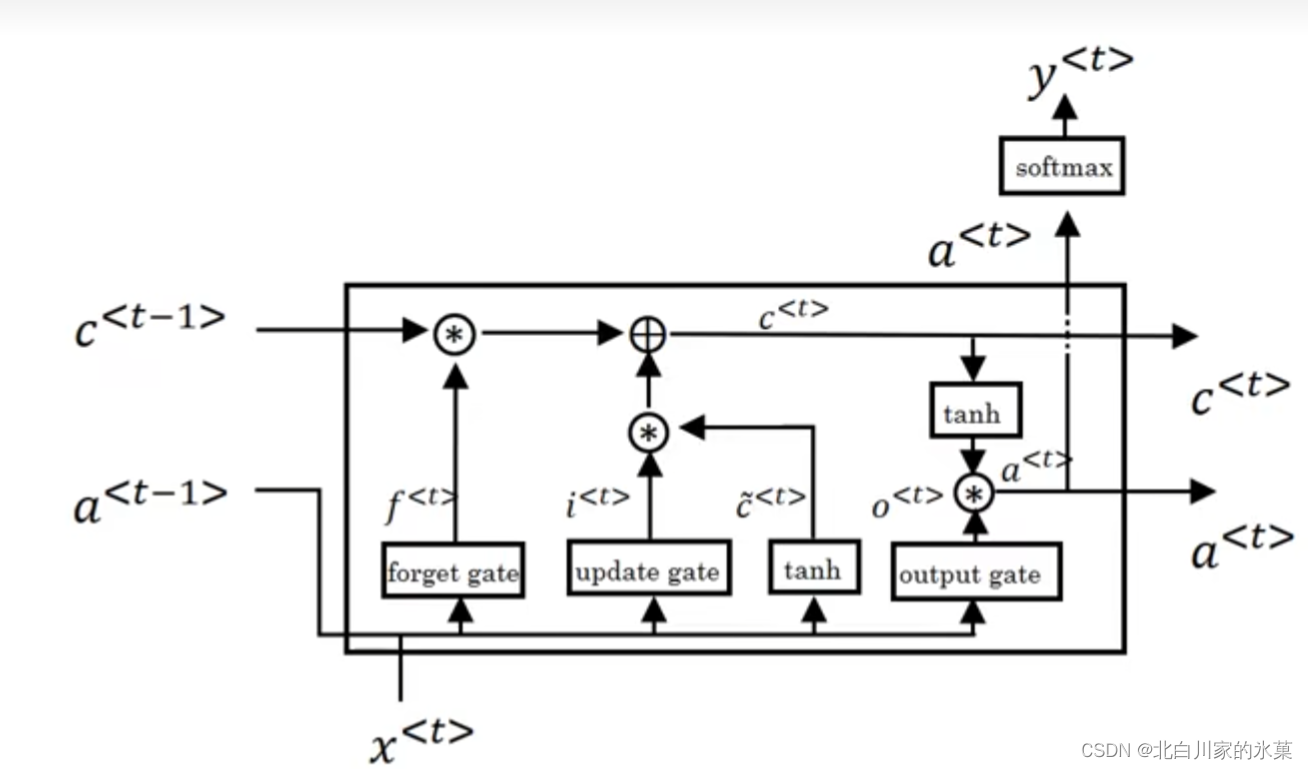
如何从RNN起步,一步一步通俗理解LSTM_v_JULY_v的博客-CSDN博客
7.双向神经网络
双向神经网络可以解决序列第一个元素难以处理的问题,比如:

通过前三个单词很难确定Teddy到底是人还是熊

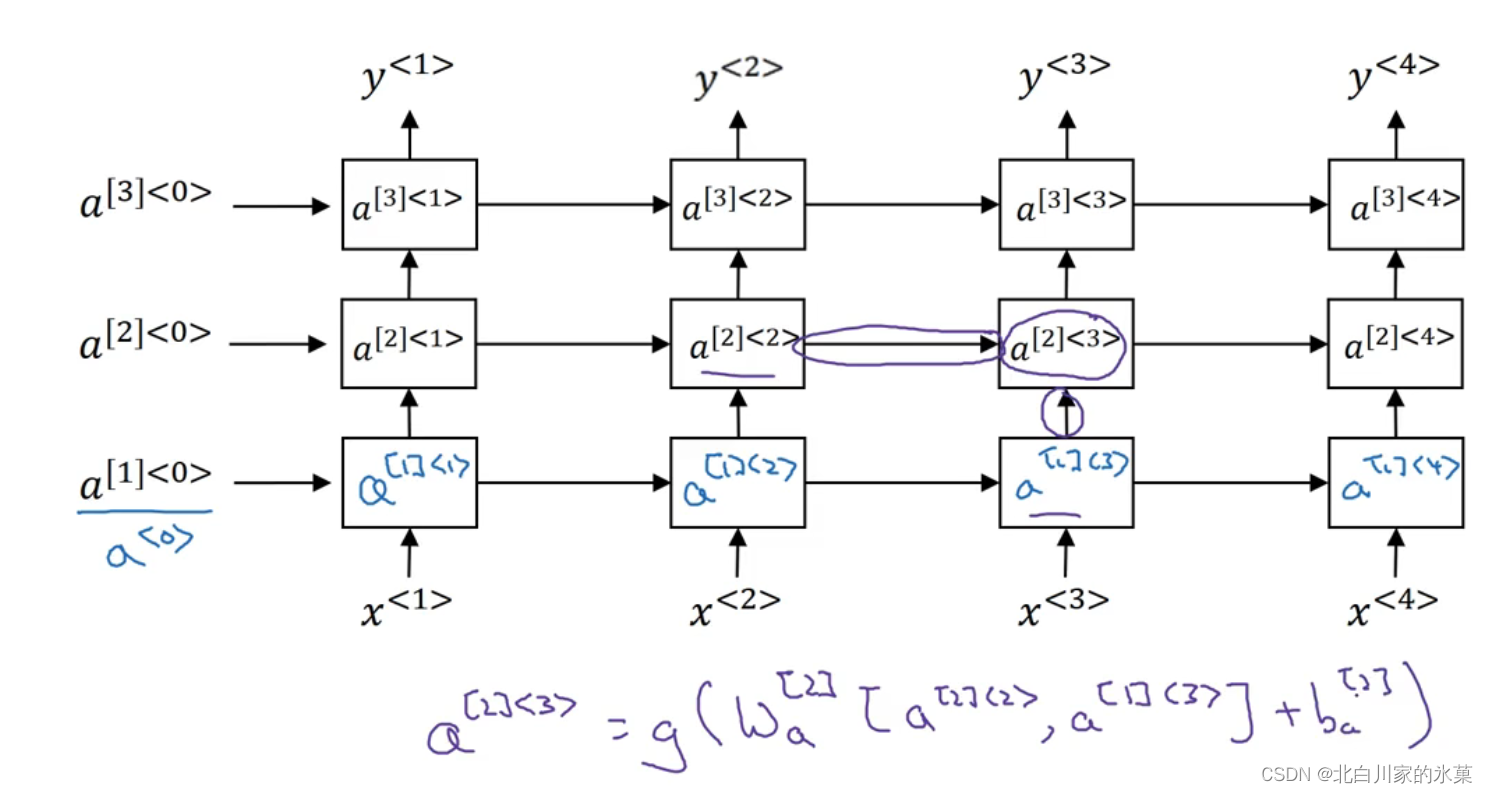
8.深度RNN
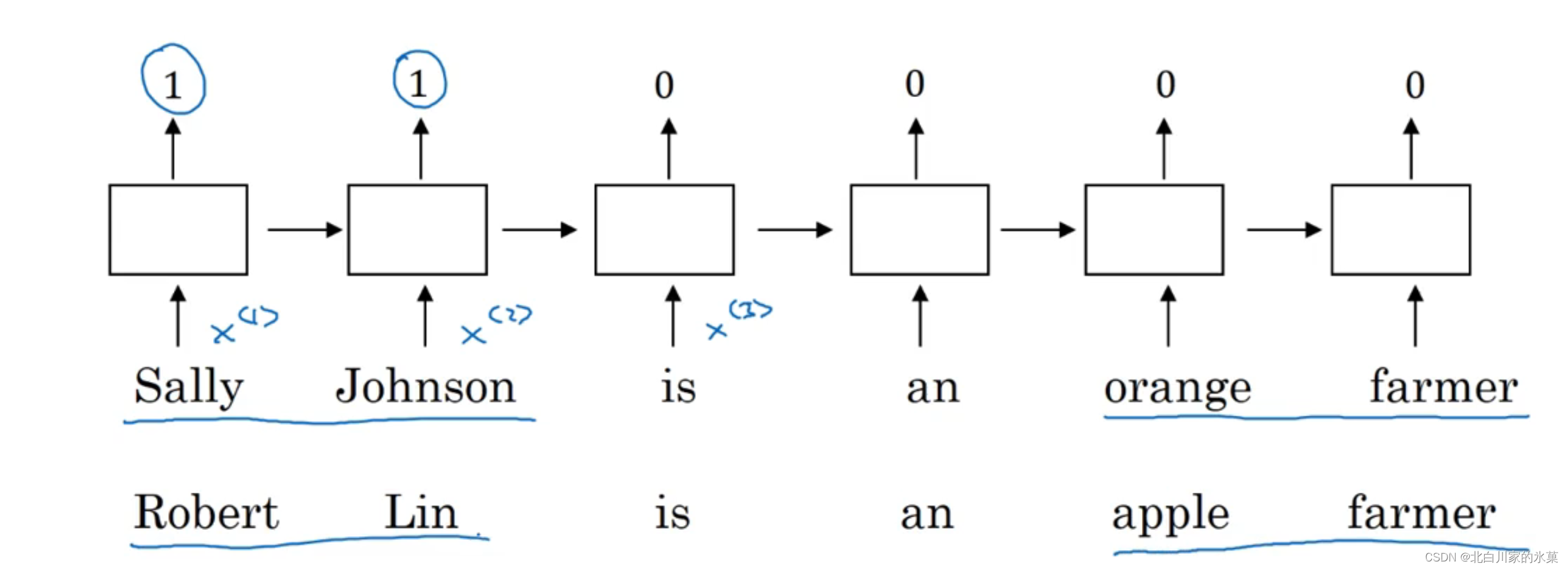
9.词汇表征

若用这种one-hot方式表示,由于任意两个向量之间的内积都是0,所以我们难以将两个词之间建立关系
比如:I want a glass of orange ______
显然这里应该是juice,但是如果把orange换成apple,如果不知道二者的关系,就难以推断
所以我们可以用 word embedding

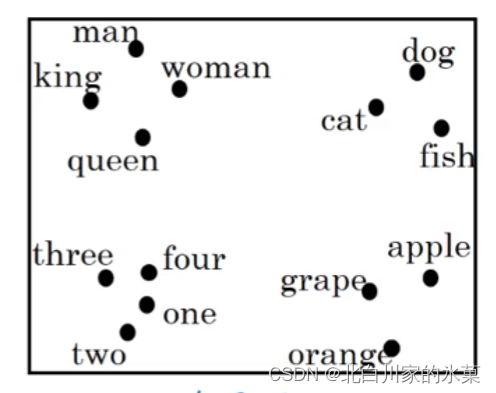
该表中数字是名词与相应特征的相关度
t-SNE算法:将名词进行分类
如果有300个特征,可以认为每个名词是个向量,那么每个向量在这个300维空间里都有一个对应坐标
t-SNE负责将这些高纬度向量进行非线性影射,到一个二维平面上
步骤:

特性:
若 man ----woman 则 King---?
如何获得呢?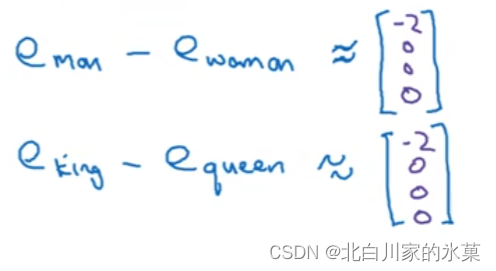
使二者作差大致相同,即二者的区别都是性别
我们要找到一个词语,使得这个相似函数最大:

常用相似函数:
cosine similarity
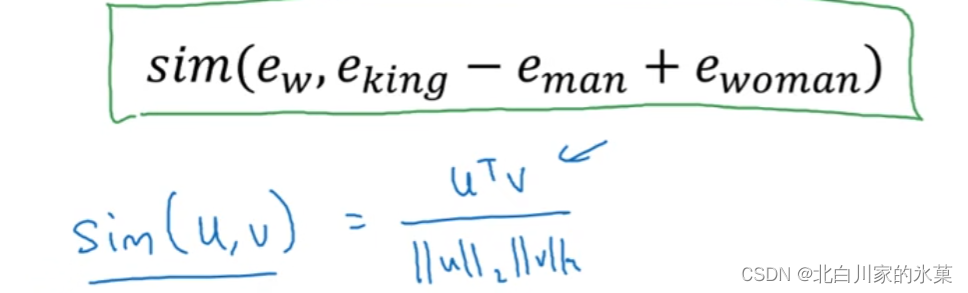
我们期望这个余弦值接近1,说明这俩向量在空间中平行
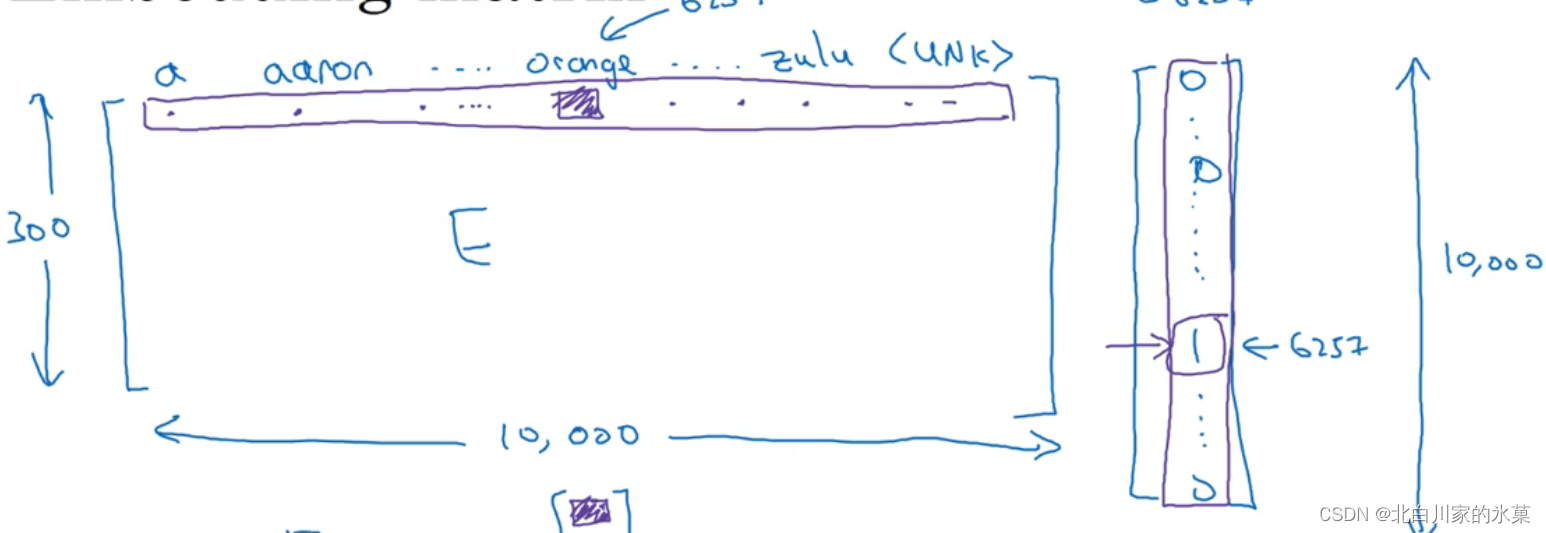
上面的这个矩阵成为矩阵E,横向是单词,纵向是单词的特征

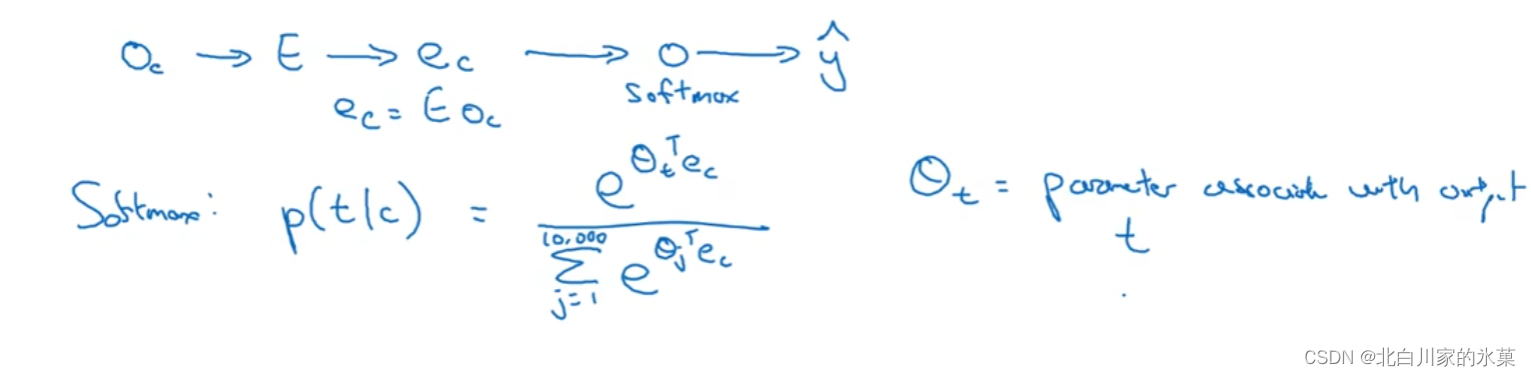
10. Word2Vec
原理:建立序列中的两个元素之间的影射
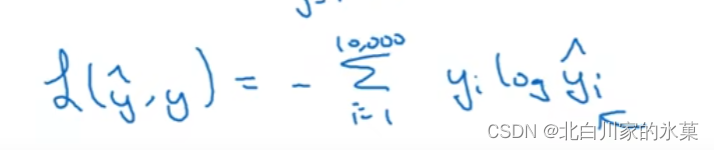
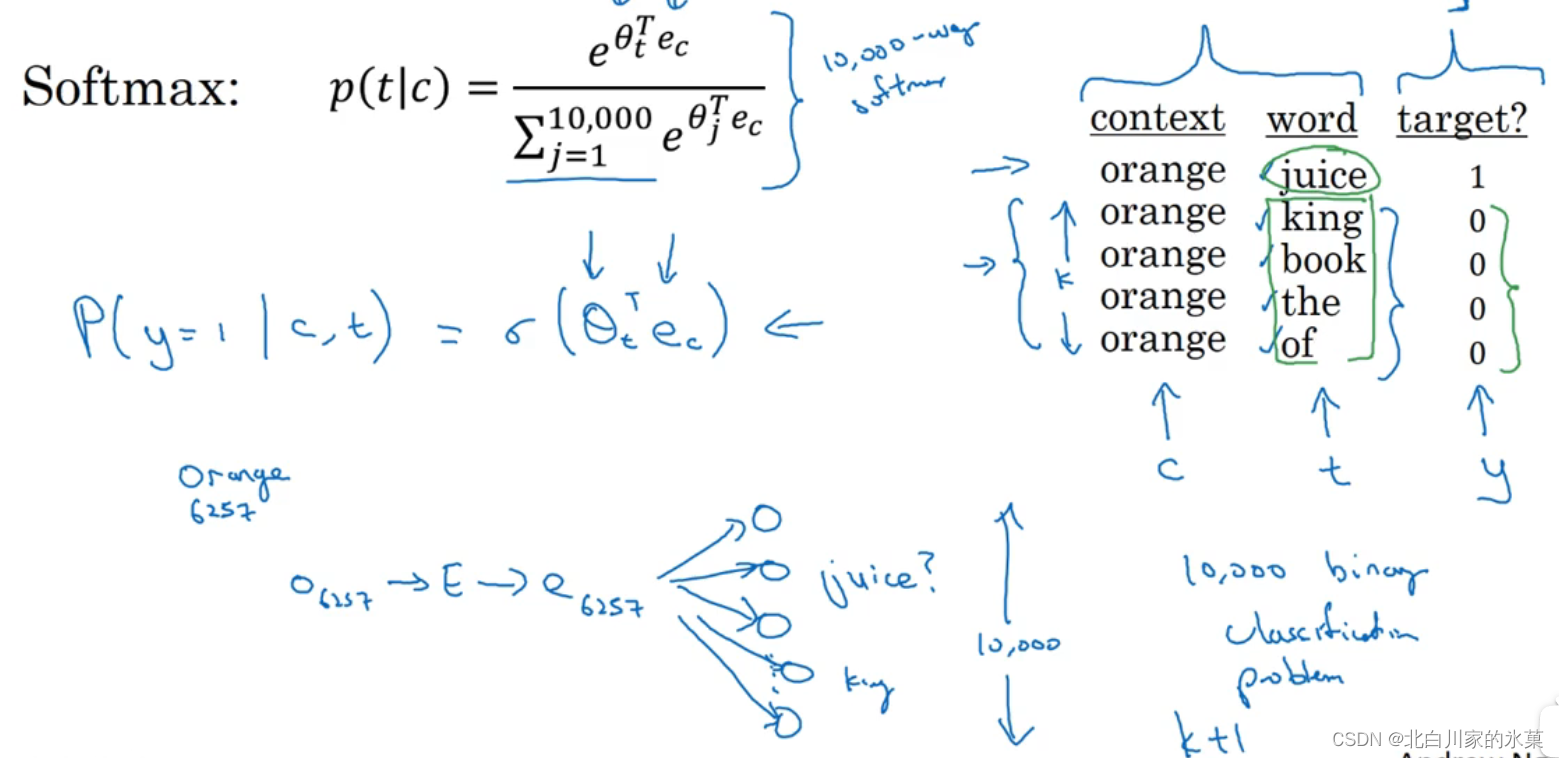
11.负采样
可以改正Word2Vec的softmax计算缓慢的问题
具有正样本和负样本,在已知正样本的情况下,用若干数量的负样本训练二分类问题
12.Golve词向量
之前,我们列举过上下文和目标词词对,GloVe算法就是使其关系开始明确化。假定X_ij表示单词i在单词j上下文中出现的次数,那么i和j与t和c的功能一样,所以X_ij等同于X_tc。事实上,如果你将上下文和目标词的范围定义为出现于左右各10词以内的话,有一种对称关系(symmetric relationship)。如果你选择的上下文总是目标词前一个单词的话,那么X_ij和X_ji就不对称。不过对于GloVe算法,我们可以定义上下文和目标词为任意两个位置相近的单词,假设是左右各10词的距离,那么X_ij就是一个能够获取单词i和单词j出现位置相近时或是彼此接近的频率的计数器
来源:GloVe 词向量(GloVe Word Vectors)_双木的木的博客-CSDN博客_glove词向量
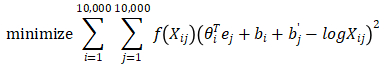
有两个作用,一个是当
是0时防止出现数学错误,另外一个是加权
有些词在英语里词频较高,比如说this,of,a等等,但是在频繁词和不常用词之间也会有一个连续统(continuum)。不过也有一些不常用的词,我们还是想将其考虑在内,但又不像那些常用词这样频繁。
因此,就可以是一个加权因子,对于不常用的词同样给大量有意义的运算,同时不会给在英语里出现更频繁的词过分大的权重。因此有一些对加权函数f的选择有着启发性的原则(heuristics),就是既不给词频高的词过分的权重,也不给这些不常用词(durion)太小的权值。

更多推荐


 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)