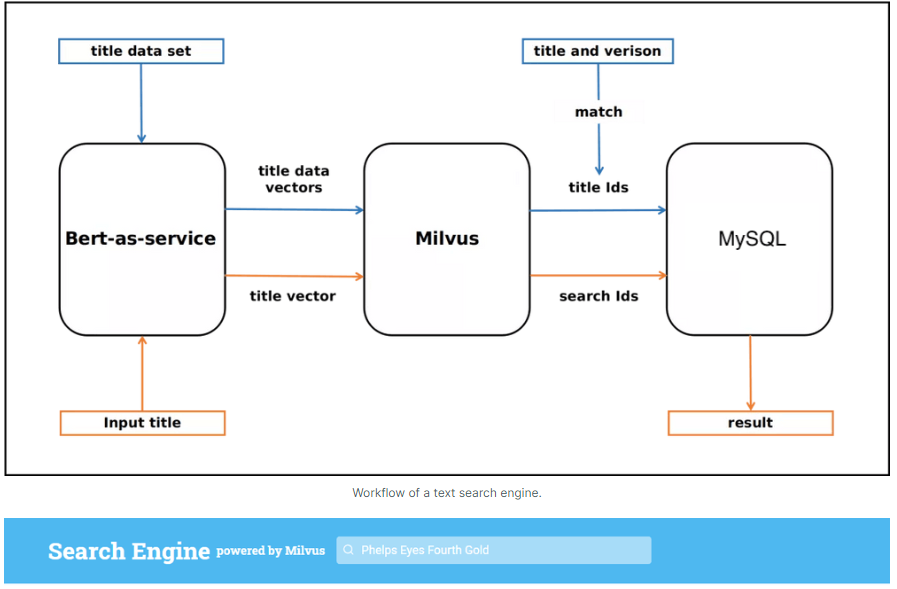
从零开始构建基于milvus向量数据库的文本搜索引擎
在这篇文章中,我们将手动构建一个语义相似性搜索引擎,该引擎将单个论文作为“查询”输入,并查找Top-K的最类似论文。主要包括以下内容:1.搭建milvus矢量数据库2.使用MILVUS矢量数据库搭建语义相似性搜索引擎3.从Kaggle下载ARXIV数据,使用dask将数据加载到Python中,并构建一个论文搜索引擎...
在这篇文章中,我们将手动构建一个语义相似性搜索引擎,该引擎将单个论文作为“查询”输入,并查找Top-K的最类似论文。主要包括以下内容:
1.搭建milvus矢量数据库
2.使用MILVUS矢量数据库搭建语义相似性搜索引擎
3.从Kaggle下载ARXIV数据,使用dask将数据加载到Python中,并构建一个论文搜索引擎
1. 搭建milvus矢量数据库
milvus数据库的安装比较简单,可以直接使用docker安装,建议安装2.1.x以上版本,功能更丰富,其分为标准版和集群版本,这里只安装标准版本。
① docker 在线安装:
https://milvus.io/docs/v2.1.x/install_standalone-docker.md
② docker 离线安装:若服务器存在网络限制,可使用离线安装策略,官方文档如下:
https://milvus.io/docs/v2.1.x/install_offline-docker.md
这里展示我自己参考官方离线安装文档,但有些不同的的安装方式,即自己手动下载容器,在手动上传至服务器:
(1)首先在这里下载docker-compose.yml,查看需要的容器:
主要包括以下三个:
image: quay.io/coreos/etcd:v3.5.0
image: minio/minio:RELEASE.2022-03-17T06-34-49Z
image: milvusdb/milvus:v2.1.1
(2)在docker hub找到需要下载的容器:
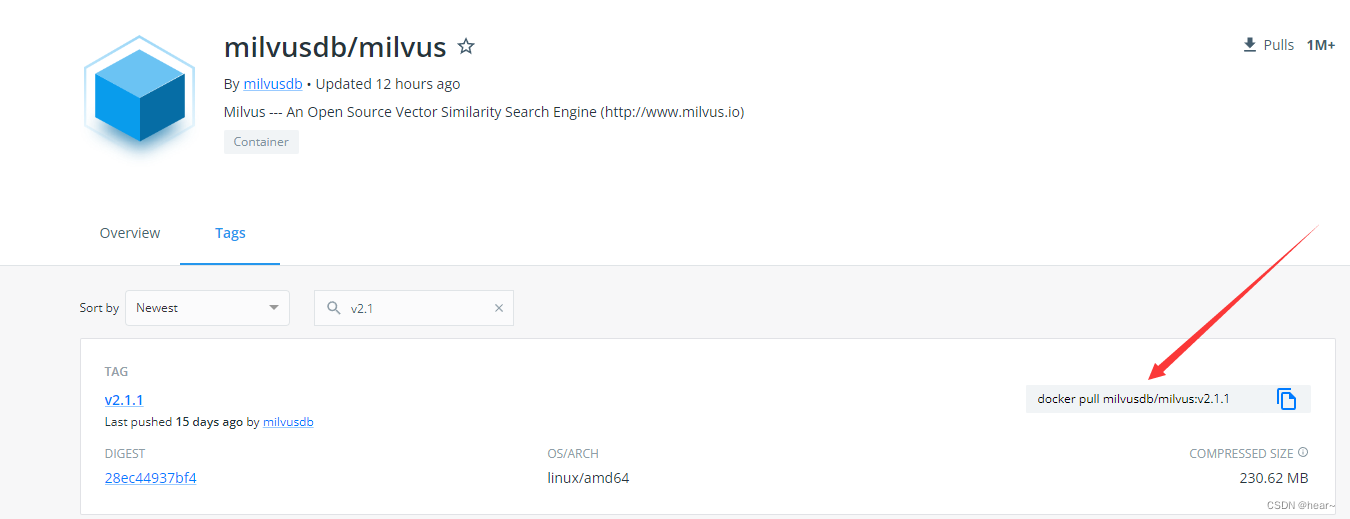
(3)复制pull命令到如下网址进行在线下载,并打包成tar:
https://pullimage.passerma.com/
这一步可参考博客:
在线下载Docker Hub镜像,打成tar包下载_passerma的博客-CSDN博客_dockerhub下载镜像
(4)后续步骤按照离线官方文档下这一步开始执行:
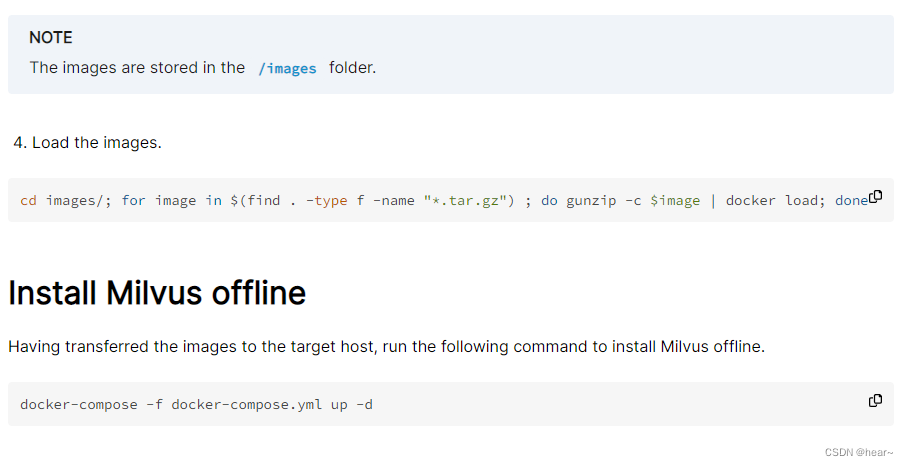
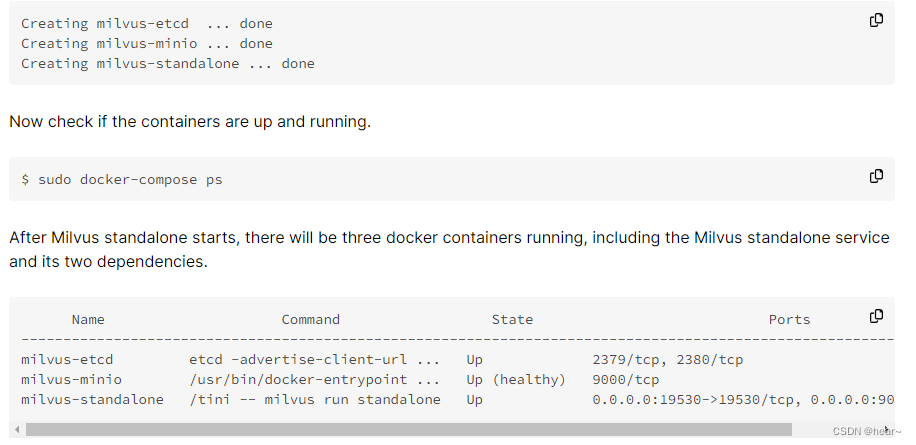
出现以下显示,并通过docker-compose ps查看容器状态,出现以下结果则安装成功:
2.使用MILVUS矢量数据库搭建语义相似性搜索引擎
参考官方文档:
https://github.com/milvus-io/bootcamp/tree/master/solutions/text_search_engine/quick_deploy
我这里由于服务器网络限制原因没有用第一种方案,如果使用第一种方案,前面的步骤1:搭建milvus矢量数据库,可直接跳过:
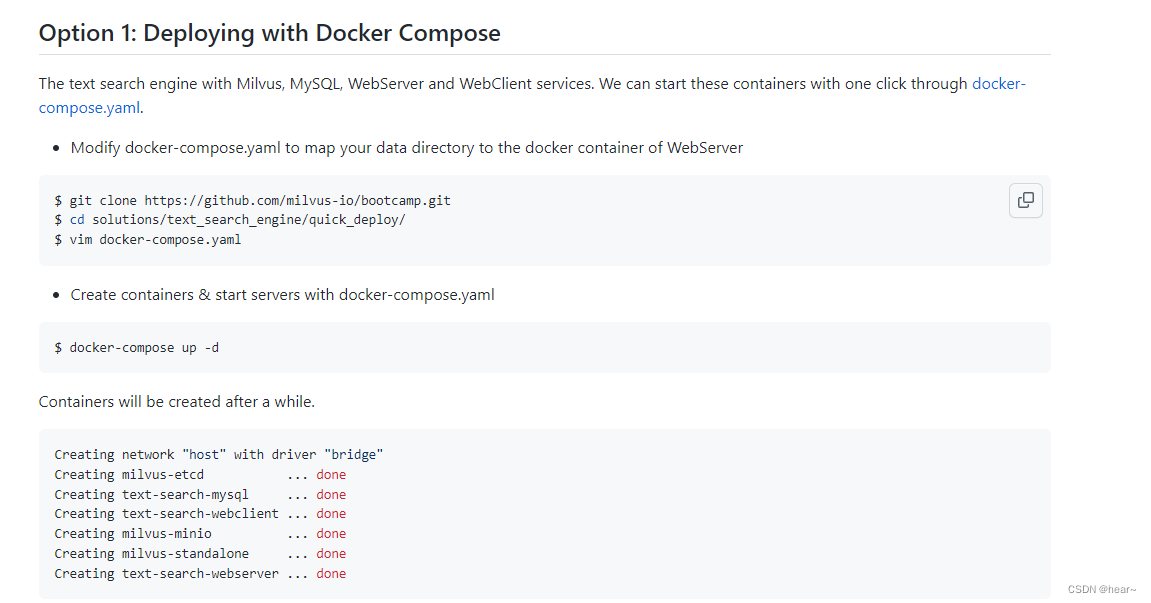
第二种方案:以源码部署
第一步安装milvus已经在步骤一完成,跳过:
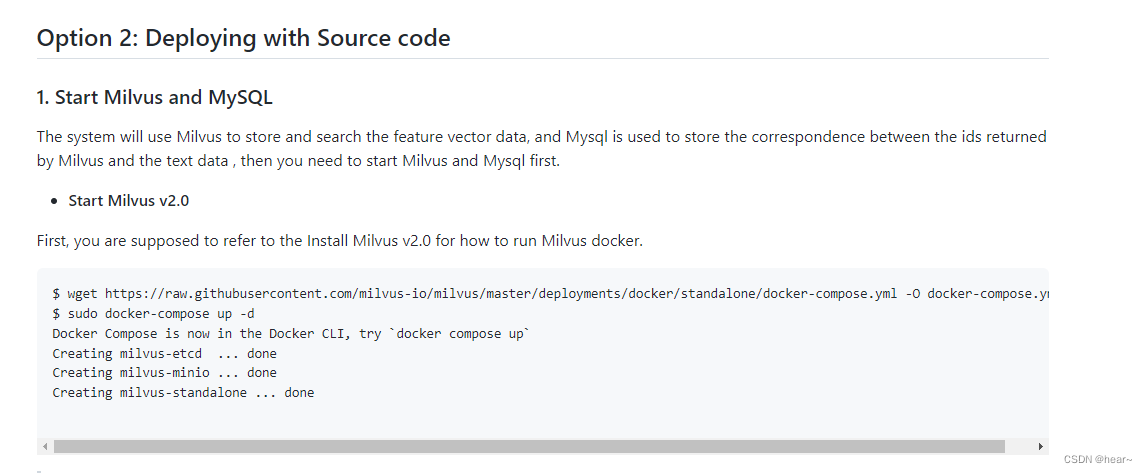
第二步:使用docker安装mysql,离线安装和在线安装都可以,离线安装参照上面miluv安装步骤,下载mysql5.7.tar包,上传至服务器,然后加载容器:
docker load -i mysql:5.7.tar开启mysql服务:
docker run -p 3306:3306 -e MYSQL_ROOT_PASSWORD=123456 -d mysql:5.7后续步骤按照教程走即可。
注意事项:

这里的let endpoint 要填服务器地址加端口号。示例:http://12.88.8.104:8000
3.从Kaggle下载ARXIV数据,使用dask将数据加载到Python中,并构建一个论文搜索引擎
这个可参考文章:https://blog.csdn.net/deephub/article/details/126343422
我这里的改进如下:
可以直接将arxiv的json格式通过dask包读取后另存为csv格式,然后将数据通过serverapi上传即可:
papers_df = papers_db.to_dataframe(meta=schema)
在这后面加上一句:
papers_df.to_csv(path,single_file=True)
出现的问题:
1.加载arxiv.csv文件时由于其源码是使用pandas一次转化为一个list,一次上传,这样会导致内存暴:milvus docker 会出现 exit(137)错误
2.使用dask加载csv文件出现乱码的问题。
解决方法:
使用dask库加载:
dd_file = dask.dataframe.read_csv(file_dir,blocksize='10MB')blocksize表示一次加载的分片大小
for partition in tqdm(range(dd_file.npartitions)):
subset_df = dd_file.get_partition(partition)
if len(subset_df.index) !=0:
data = [subset_df[col].values.compute().tolist() for col in ['title','text']]
#若使用上述方法出现乱码,可使用下述方法:
#先使用pandas加载
pd_file = pd.read_csv(file)
dd_file = dask.dataframe.from_pandas(pd_file, npartitions=10)
for partition in tqdm(range(dd_file.npartitions)):
subset_df = dd_file.get_partition(partition)
if len(subset_df.index) !=0:
data = [subset_df[col].values.compute().tolist() for col in ['title','text']]附dask官方文档:
https://docs.dask.org/en/latest/dataframe-create.html
3.在将数据进行上传时,出现mysql数据库 1366编码错误的问题:
在mysql_helpers.py修改如下两个地方:
def __init__(self):
self.conn = pymysql.connect(host=MYSQL_HOST, user=MYSQL_USER, port=MYSQL_PORT,
password=MYSQL_PWD,
#1. 增加charset='utf8mb4'
charset='utf8mb4',
local_infile=True)
def create_mysql_table(self, table_name):
self.test_connection()
sql = "create table if not exists " + table_name +"(milvus_id TEXT, title TEXT, text TEXT);"
try:
self.cursor.execute(sql)
#使用sql语句改变表编码格式
self.cursor.execute("alter table "+table_name + " convert to charcter set utf8mb4;")

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)