kubernetes HPA使用及测试
Horizontal Pod Autoscaling (HPA)控制器,根据预定义好的阈值及pod当前的资源利用率,自动控制在k8s集群中运行的pod数量(自动弹性水平自动伸缩).
一、安装metrics server
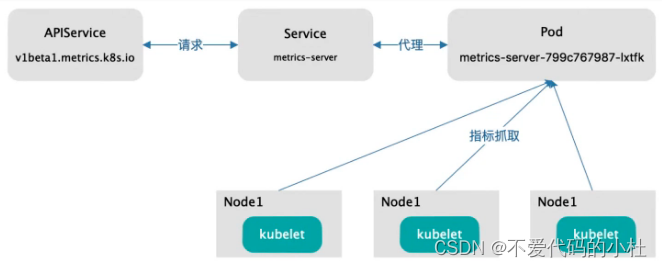
Metrics Server是Kubernetes内置的容器资源指标来源。
Metrics Server从node节点上的Kubelet收集资源指标,并通过Metrics API在 Kubernetes apiserver中公开指标数据,以供Horizontal Pod Autoscaler和Vertical Pod Autoscaler使用,也可以通过访问kubectl top node/pod查看指标数据。
使用Metrics-Server监控node和pod计算资源使用情况,并提供给第三方使用
下载地址:
gituhub地址

修改资源定义文件
root@master:~/.kube# vim components.yaml
修改镜像位置:
image: k8s.gcr.io/metrics-server/metrics-server:v0.6.1
修改为:
registry.cn-hangzhou.aliyuncs.com/liangxiaohui/metrics-server:0.6.1
部署:
kubectl apply -f components.yaml
serviceaccount/metrics-server created
clusterrole.rbac.authorization.k8s.io/system:aggregated-metrics-reader created
clusterrole.rbac.authorization.k8s.io/system:metrics-server created
rolebinding.rbac.authorization.k8s.io/metrics-server-auth-reader created
clusterrolebinding.rbac.authorization.k8s.io/metrics-server:system:auth-delegator created
clusterrolebinding.rbac.authorization.k8s.io/system:metrics-server created
service/metrics-server created
deployment.apps/metrics-server created
apiservice.apiregistration.k8s.io/v1beta1.metrics.k8s.io created
验证:
root@deploy:~/yaml# kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
calico-kube-controllers-7ff47c8649-mnwjh 1/1 Running 31 (69m ago) 21d
calico-node-8pqgz 1/1 Running 21 (69m ago) 21d
calico-node-bqbj8 1/1 Running 21 (69m ago) 21d
calico-node-zjrwp 1/1 Running 21 (69m ago) 21d
coredns-778797657-zct55 1/1 Running 18 (69m ago) 21d
coredns-778797657-zlgfg 1/1 Running 14 (69m ago) 21d
metrics-server-597c6f68ff-68hpv 1/1 Running 0 63s
root@deploy:~/yaml# kubectl top nodes
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
192.168.100.2 76m 3% 1073Mi 64%
192.168.100.5 141m 7% 1543Mi 20%
192.168.100.6 50m 2% 652Mi 8%
验证:查看可以采集pods和nodes节点资源
root@deploy:~/yaml# kubectl top pod -n test
NAME CPU(cores) MEMORY(bytes)
dubbo-consumer-deployment-b55c7cdff-k8lm7 1m 3Mi
dubbo-provider-deployment-5cc994c8b4-sd72z 1m 6Mi
dubboadmin-deployment-d98765c7-mwt5v 71m 717Mi
zookeeper1-654c4f44c-9cbqb 1m 80Mi
zookeeper2-645fdbd686-rmwrl 2m 81Mi
zookeeper3-b879d8d8f-prhmb 2m 74Mi
二、HPA自动伸缩
HorizontalPodAutoscaler(简称HPA)自动更新工作负载资源(例如Deployment或者StatefulSet),基于pod资源利用率横向调整pod副本数量。目的是自动扩缩工作负载以满足需求。
根据当前pod的负载,动态调整pod副本数量,业务高峰期自动扩容pod的副本数以尽快相应pod的请求。
水平扩缩意味着对增加的负载的响应是部署更多的Pods。这与“垂直(Vertical)”扩缩不同,对于Kubernetes,垂直扩缩意味着将更多资源(例如:内存或CPU)分配给已经为工作负载运行的Pod。
如果负载减少,并且Pod的数量高于配置的最小值, HorizontalPodAutoscaler会指示工作负载资源(Deployment、StatefulSet或其他类似资源)缩减。
相关的其他动态伸缩控制器类型
垂直pod自动缩放器(VPA):基于pod资源利用率,调整对单个pod的最大资源限制,不能与HPA同时使用
集群伸缩(Cluster Autoscaler,CA):基于集群中node资源使用情况,动态伸缩node节点,从而保证有CPU和内存资源用于创建pod。
HPA控制器简介:
Horizontal Pod Autoscaling (HPA)控制器,根据预定义好的阈值及pod当前的资源利用率,自动控制在k8s集群中运行的pod数量(自动弹性水平自动伸缩).
HPA重要参数:
使用kube-controller-manager --help|grep <options>,进行查询
##默认每隔15s,可以通过此选项修改查询metrics的资源使用
--horizontal-pod-autoscaler-sync-period
#缩容间隔周期,默认5分钟。
--horizontal-pod-autoscaler-downscale-stabilization
#HPA控制器同步pod副本数的间隔周期
--horizontal-pod-autoscaler-sync-period
#初始化延迟时间,在此时间内pod的CPU资源指标将不会生效,默认为5分钟。
--horizontal-pod-autoscaler-cpu-initialization-period
#用于设置pod准备时间,在此时间内的pod统统被认为未就绪及不采集数据,默认为30秒。
--horizontal-pod-autoscaler-initial-readiness-delay
#HPA控制器能容忍的数据差异(浮点数,默认为0.1),即新的指标要与当前的阈值差异在0.1或以上,即要大于1+0.1=1.1,或小于1-0.1=0.9,比如阈值为CPU利用率50%,当前为80%,那么80/50=1.6 > 1.1则会触发扩容,反之会缩容。
--horizontal-pod-autoscaler-tolerance
即触发条件:avg(CurrentPodsConsumption) / Target >1.1 或 <0.9=把N个pod的数据相加后根据pod的数量计算出平均数除以阈值,大于1.1就扩容,小于0.9就缩容。
计算公式:TargetNumOfPods = ceil(sum(CurrentPodsCPUUtilization) / Target) #ceil是一个向上取整的目的pod整数。
指标数据需要部署metrics-server,即HPA使用metrics-server作为数据源。
https://github.com/kubernetes-sigs/metrics-server
在k8s 1.1引入HPA控制器,早期使用Heapster组件采集pod指标数据,在k8s 1.11版本开始使用Metrices Server完成数据采集,然后将采集到的数据通过API(Aggregated API,汇总API),例如metrics.k8s.io、custom.metrics.k8s.io、external.metrics.k8s.io,然后再把数据提供给HPA控制器进行查询,以实现基于某个资源利用率对pod进行扩缩容的目的。
根据cpu利用率伸缩
创建deployment
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: nginx
name: nginx
spec:
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- image: nginx
name: nginx
imagePullPolicy: IfNotPresent
创建hpa
[root@master10 hpa]# kubectl autoscale deployment nginx --max=5 --min=2 --cpu-percent=80 --dry-run=client -o yaml > hpa.yaml
[root@master10 hpa]# vim hpa.yaml
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
creationTimestamp: null
name: nginx
spec:
maxReplicas: 5
minReplicas: 2
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: nginx
targetCPUUtilizationPercentage: 80
status:
currentReplicas: 0
desiredReplicas: 0
要想看到HPA的TARGETS值必须满足2个条件:
- 安装metric server
- 为pod设定资源限制。
配置deployment 限制cpu和内存
添加resource资源限制
kubectl edit deployments.apps nginx
spec:
containers:
- image: nginx
imagePullPolicy: IfNotPresent
name: nginx
resources:
limits:
memory: "200m"
cpu: "100m"
修改后,自动创建两个新的pod来替换旧的pod资源限制
暴露deployment端口,创建svc
kubectl expose deployment nginx --port=80 --target-port=80

apt-install httpd-tools 安装ab工具进行压力测试
[root@master10 hpa]# ab -n 300000 -c 100 http://10.102.118.93/

容器cpu达到80%则hpa自动水平伸缩,扩容pods,直到扩容到cpu负载均匀到各个pods中,或者hpa扩容到最大pods数量。


K8S/Kubernetes社区为您提供最前沿的新闻资讯和知识内容
更多推荐
 1
1 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)