K8S集群
k8s相关内容
概念:
- cluster:计算,存储和网络资源的集合,kubernetes通过这些资源管理容器
- master:cluster的大脑,负责调度,决定pod在哪个node上运行
- node:pod运行的地方,node负责监控容器的状态,并向master汇报,并根据master的要求管理容器的生命周期
- pod:kubernetes的最小工作单元,pod中运行着一个或多个容器,这些容器会作为一个整体被master调度到node上运行
- controller:kubernetes通过controller管理pod
- service:service为外界提供访问pod的ip,pod可能会被频繁的创建和销毁,但service不变
- namespace:可以将cluster划分为多个cluster(default、system、public)
master:
- kube-apiserver:k8s的前端接口和其他组件通过apiserver管理集群各种资源
- kube-scheduler:决定pod在哪个node上运行
- kube-controller-manager:管理集群的各种资源,使其处于一个预期的状态
- etcd: 相当于数据库,保存着节点的各种配置信息,如:kubectl get po时从etcd中获取到资源信息
- pod:flannel为pod分配网络
node:
- kubelet:node的agent,当pod被调度到某个node上运行的时候,node将该节点的配置信息发送给kubelet,kubelet依据这些配置信息创建和运行容器
- kube-porxy:外界通过访问service访问pod,service收到的请求由proxy完成,proxy还可以实现k8s集群的负载均衡
- pod:flannel为pod分配网络
搭建过程
要求:cpu,memory最低2c4g
1.关闭防火墙(所有节点)
systemctl stop firewalld
systemctl disable firewalld
setenforce 0
sed -i "s/enforcing/disabled/g" /etc/selinux/config2.域名解析(所有节点)
vim /etc/hosts
192.168.31.11 hp1
192.168.31.12 hp2
192.168.31.13 hp3
192.168.31.14 hp4echo "1" > /proc/sys/net/bridge/bridge--nf-call-iptables使用scp命令发送到其他节点
scp /etc/hosts 192.168.31.12:/etc/hosts
scp /etc/hosts 192.168.31.13:/etc/hosts
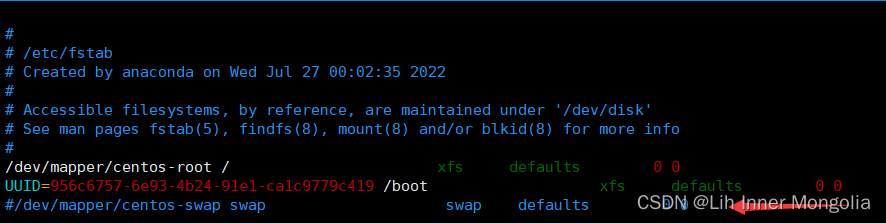
scp /etc/hosts 192.168.31.14:/etc/hosts3.关闭交换分区(所有节点)
vim /etc/fstab
swapoff -afree -h检查是否已没有swap交换分区
4.配置docker源,docker加速器(阿里云官网,镜像服务,加速器),下载docker-ce(所有节点)
wget -O /etc/yum.repos.d/docker-ce.repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repoyum clean all && yum makecache && yum install docker-ce -y
systemctl restart docker && systemctl enable docker 5.配置k8s源,下载k8s组件,kubectl、kubeadm、kubelet(所有节点)
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpgyum clena all && yum makecache && yum install kubectl-1.15.2 kubelet-1.15.2 kubeadm-1.15.2 -y注:此处下载时可根据自行情况下载版本
6.启动kubelet(所有节点)
systemctl restart kubelet && systemctl enable kubelet7.在master节点初始化集群
kubeadm init --apiserver-advertise-address 192.168.31.11 --image-repository registry.aliyuncs.com/google_containers --kubernetes-version v1.15.2 --pod-network-cidr 10.244.0.0/16 --service-cidr 10.96.0.0/12
--image-repository:这个用于指定从什么位置来拉取镜像(1.13版本才有的),默认值是k8s.gcr.io,我们将其指定为国内镜像地址:registry.aliyuncs.com/google_containers
--kubernetes-version:指定kubenets版本号,默认值是stable-1,会导致从https://dl.k8s.io/release/stable-1.txt下载最新的版本号,我们可以将其指定为固定版本(最新版:v1.13.2)来跳过网络请求。
--apiserver-advertise-address:指明用 Master的哪个interface与Cluster的其他节点通信。如果 Master 有多个 interface,建议明确指定,如果不指定,kubeadm会自动选择有默认网关的interface。
--pod-network-cidr:指定 Pod 网络的范围。Kubernetes 支持多种网络方案,而且不同网络方案对 --pod-network-cidr有自己的要求,这里设置为10.244.0.0/16 是因为我们将使用flannel网络方案,必须设置成这个 CIDR。

8.复制方框内的内容挨个执行即可,kubeadm join部分为加入从节点加入使用,默认有效期为24小时

9.为pod分配flannel网络
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml![]()
出现上图报错,原因:dns服务器没有找到raw.githubusercontent.com的ip地址
解决方法:
方法一:
去IP/服务器raw.githubusercontent.com的信息 - 站长工具 (chinaz.com)中解析地址

编辑/etc/hosts文件
vim /etc/hosts
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
方法二:直接vim flannel.yaml
---
apiVersion: policy/v1beta1
kind: PodSecurityPolicy
metadata:
name: psp.flannel.unprivileged
annotations:
seccomp.security.alpha.kubernetes.io/allowedProfileNames: docker/default
seccomp.security.alpha.kubernetes.io/defaultProfileName: docker/default
apparmor.security.beta.kubernetes.io/allowedProfileNames: runtime/default
apparmor.security.beta.kubernetes.io/defaultProfileName: runtime/default
spec:
privileged: false
volumes:
- configMap
- secret
- emptyDir
- hostPath
allowedHostPaths:
- pathPrefix: "/etc/cni/net.d"
- pathPrefix: "/etc/kube-flannel"
- pathPrefix: "/run/flannel"
readOnlyRootFilesystem: false
# Users and groups
runAsUser:
rule: RunAsAny
supplementalGroups:
rule: RunAsAny
fsGroup:
rule: RunAsAny
# Privilege Escalation
allowPrivilegeEscalation: false
defaultAllowPrivilegeEscalation: false
# Capabilities
allowedCapabilities: ['NET_ADMIN', 'NET_RAW']
defaultAddCapabilities: []
requiredDropCapabilities: []
# Host namespaces
hostPID: false
hostIPC: false
hostNetwork: true
hostPorts:
- min: 0
max: 65535
# SELinux
seLinux:
# SELinux is unused in CaaSP
rule: 'RunAsAny'
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: flannel
rules:
- apiGroups: ['extensions']
resources: ['podsecuritypolicies']
verbs: ['use']
resourceNames: ['psp.flannel.unprivileged']
- apiGroups:
- ""
resources:
- pods
verbs:
- get
- apiGroups:
- ""
resources:
- nodes
verbs:
- list
- watch
- apiGroups:
- ""
resources:
- nodes/status
verbs:
- patch
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: flannel
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: flannel
subjects:
- kind: ServiceAccount
name: flannel
namespace: kube-system
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: flannel
namespace: kube-system
---
kind: ConfigMap
apiVersion: v1
metadata:
name: kube-flannel-cfg
namespace: kube-system
labels:
tier: node
app: flannel
data:
cni-conf.json: |
{
"name": "cbr0",
"cniVersion": "0.3.1",
"plugins": [
{
"type": "flannel",
"delegate": {
"hairpinMode": true,
"isDefaultGateway": true
}
},
{
"type": "portmap",
"capabilities": {
"portMappings": true
}
}
]
}
net-conf.json: |
{
"Network": "10.244.0.0/16",
"Backend": {
"Type": "vxlan"
}
}
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: kube-flannel-ds
namespace: kube-system
labels:
tier: node
app: flannel
spec:
selector:
matchLabels:
app: flannel
template:
metadata:
labels:
tier: node
app: flannel
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/os
operator: In
values:
- linux
hostNetwork: true
priorityClassName: system-node-critical
tolerations:
- operator: Exists
effect: NoSchedule
serviceAccountName: flannel
initContainers:
- name: install-cni-plugin
#image: flannelcni/flannel-cni-plugin:v1.0.1 for ppc64le and mips64le (dockerhub limitations may apply)
image: rancher/mirrored-flannelcni-flannel-cni-plugin:v1.0.1
command:
- cp
args:
- -f
- /flannel
- /opt/cni/bin/flannel
volumeMounts:
- name: cni-plugin
mountPath: /opt/cni/bin
- name: install-cni
#image: flannelcni/flannel:v0.16.3 for ppc64le and mips64le (dockerhub limitations may apply)
image: rancher/mirrored-flannelcni-flannel:v0.16.3
command:
- cp
args:
- -f
- /etc/kube-flannel/cni-conf.json
- /etc/cni/net.d/10-flannel.conflist
volumeMounts:
- name: cni
mountPath: /etc/cni/net.d
- name: flannel-cfg
mountPath: /etc/kube-flannel/
containers:
- name: kube-flannel
#image: flannelcni/flannel:v0.16.3 for ppc64le and mips64le (dockerhub limitations may apply)
image: rancher/mirrored-flannelcni-flannel:v0.16.3
command:
- /opt/bin/flanneld
args:
- --ip-masq
- --kube-subnet-mgr
resources:
requests:
cpu: "100m"
memory: "50Mi"
limits:
cpu: "100m"
memory: "50Mi"
securityContext:
privileged: false
capabilities:
add: ["NET_ADMIN", "NET_RAW"]
env:
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
volumeMounts:
- name: run
mountPath: /run/flannel
- name: flannel-cfg
mountPath: /etc/kube-flannel/
- name: xtables-lock
mountPath: /run/xtables.lock
volumes:
- name: run
hostPath:
path: /run/flannel
- name: cni-plugin
hostPath:
path: /opt/cni/bin
- name: cni
hostPath:
path: /etc/cni/net.d
- name: flannel-cfg
configMap:
name: kube-flannel-cfg
- name: xtables-lock
hostPath:
path: /run/xtables.lock
type: FileOrCreate10.在主节点复制kubeadm join ***到从节点加入

11.在主节点运行命令
kubectl get no -o wide 
notready为节点在拉取镜像,等待完成即可
若长时间未完成大概率为po中前两个镜像拉取失败

原因1:flannel拉取失败导致
原因2:没有做域名解析
原因3:镜像两个镜像拉取失败
解决办法1:做域名解析后重新拉取,或直接写入flannely.yaml文件
解决办法2:编辑/etc/hosts对节点做域名解析
解决办法3:手动导入镜像
补充:
1.kubeadm join信息没有保存或过期如何加入?
systemctl stop kubelet
rm -rf /etc/kubernetes/*
kubeadm token create -ttl0 -print-join-command2.删除node节点
kubectl drain 节点名 --delete-local-date --force --ignore-daemonsets
kubectl delete no 节点名3.启动pod(命令行模式)
kubectl run deploy名 --image=镜像名 --replicas=pod数量
kubectl run deploy名 --image=镜像名 -r pod数量

imagePullPolicy:(镜像拉取规则)
IfNotPresent:本地镜像仓库没有去dockerhub拉取
Always:无论本地有没有镜像,都去dockerhub拉取
Never:本地仓库没有镜像不去dockerhub拉取,容器启动失败
4.删除pod
kubectl delete deploy deploy名(命令行)
kubectl delete -f *.yml5.对node打标签,删除标签
kubectl label no 节点名 标签
kubectl label no hp2 disktype=ssd
kubectl label no 节点名 标签-
kubectl label no hp2 disktype-6.标签使用,可以使yml文件中创建的pod到某个node上运行

7.pod的创建过程:
用户通过kubectl或者是yml文件指定创建n个pod
kube-apiserver会通知deploy
deploy通知rs去创建pod
pod被调度,node节点通过kubelet创建运行容器
应用及配置信息存储在etcd中
flannel为每个pod分配网络
service创建后可外界访问
8.pod的生命周期:pod被创建,pod被调度,pod一旦被分配到node上就不会离开node,除非被删除
9.滚动更新
kubectl create deploy deploy名 --image=镜像名 --dry-run -o yaml > *.yml
kubectl create deploy nginx --image=nginx --dry-run -o yaml > *.yml
kubectl apply -f *.yml --record
kubectl rollout history deploy名
kubectl rollout undo deploy deploy名 --to-revision=值10.pod的动态伸缩
kubectl run deploy名 --image=镜像名 --replicas=pod数量
kubectl run deploy名 --image=镜像名 -r pod数量
kubectl scale --replicas pod数量 deploy deploy名yml文件动态收缩只需要修改replicas后面的值,重新kubectl apply -f *.yml即可
11.job和crontab启动为Never和OnFailure


12.secret和configmap


![]()
13.k8s的数据卷:emptyDir、hostpath、nfs、pvpvc
14.探针
Liveness 探测让用户可以自定义判断容器是否健康的条件。如果探测失败,Kubernetes 就会重启容器。

启动进程首先创建文件/tmp/healthy,30秒后删除,在我们的设定中,如果/tmp/healthy文件存在,则认为容器处于正常状态,反则发生故障。
livenessProbe 部分定义如何执行Liveness探测:
探测的方法是:通过cat命令检查/tmp/healthy文件是否存在。如果命令执行成功,返回值为零,Kubernetes则认为本次Liveness探测成功;如果命令返回值非零,本次Liveness探测失败。
initialDelaySeconds: 10 指定容器启动10秒之后开始执行Liveness探测,我们一般会根据应用启动的准备时间来设置。比如某个应用正常启动要花30秒,那么initialDelaySeconds的值就应该大于30。
periodSeconds: 5指定每5秒执行一次Liveness探测。Kubernetes如果连续执行3次Liveness探测均失败,则会杀掉并重启容器。
Readiness:用户通过Liveness探测可以告诉Kubernetes什么时候通过重启容器实现自愈;Readiness探测则是告诉Kubernetes什么时候可以将容器加入到Service负载均衡池中,对外提供服务。

Liveness探测和Readiness探测做个比较:
(1)Liveness探测和Readiness探测是两种Health Check机制,如果不特意配置,Kubernetes将对两种探测采取相同的默认行为,即通过判断容器启动进程的返回值是否为零来判断探测是否成功。
(2)两种探测的配置方法完全一样,支持的配置参数也一样。不同之处在于探测失败后的行为:Liveness探测是重启容器;Readiness探测则是将容器设置为不可用,不接收Service转发的请求。
(3)Liveness探测和Readiness探测是独立执行的,二者之间没有依赖,所以可以单独使用,也可以同时使用。用Liveness探测判断容器是否需要重启以实现自愈;用Readiness探测判断容器是否已经准备好对外提供服务。

K8S/Kubernetes社区为您提供最前沿的新闻资讯和知识内容
更多推荐
 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)