
文献阅读:医学图像配准的深度学习方法综述
图像配准; 监督学习; 无监督学习;变换估计
本文介绍了医学图像配准在疾病诊断、手术引导和疾病治疗跟踪等方面具有重要应用价值。将深入介绍基于深度学习的医学图像配准现状和现存的配准方法技术,包括监督变换估计、无监督变换估计和使用生成对抗网络的配准方法。
首先图像配准是图像处理的一个重要领域,配准指的是将两个或多个图像进行几何对齐,使源图像( 移动图像) 上的每一个点在目标图像( 固定图像) 上都有唯一的点与其对应,旨在寻找不同图像之间的空间变换关系,去除或者抑制待配准图像之间的几何不一致。
配准技术可以提高检测治疗效果的效率,同时,该技术可以最大化地将不同模态或时间的医学图像融合,提高信息利用率和诊断的准确性。配准算法包括了变形模型、目标函数、 优化算法3个组成部分。其中,配准算法的效果主要依赖于定义变形模型和目标函数。
下面介绍基于深度学习的配准方法。
第一种是监督变换估计。基于监督变换估计的配准,就是在训练学习网络时需要提供与待配准图像对应的标准标签数据。它包括完全监督估计,弱监督估计和双重监督估计。
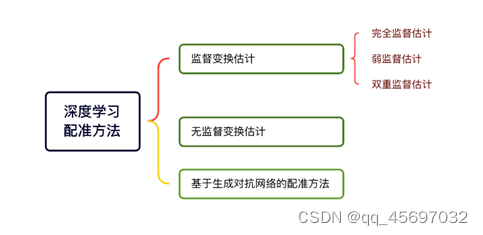
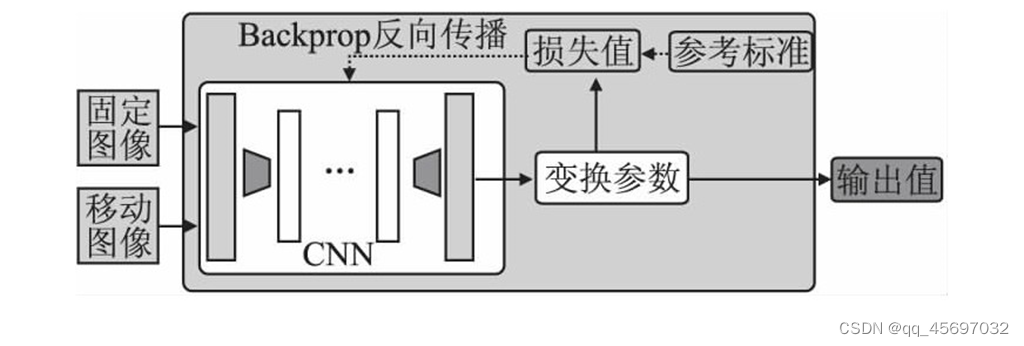
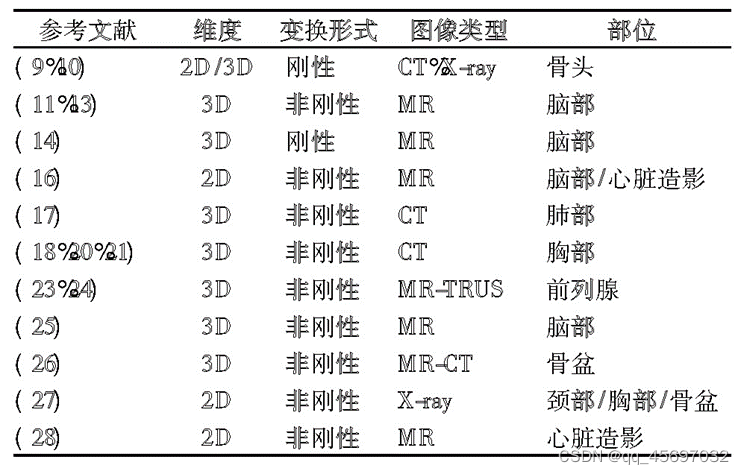
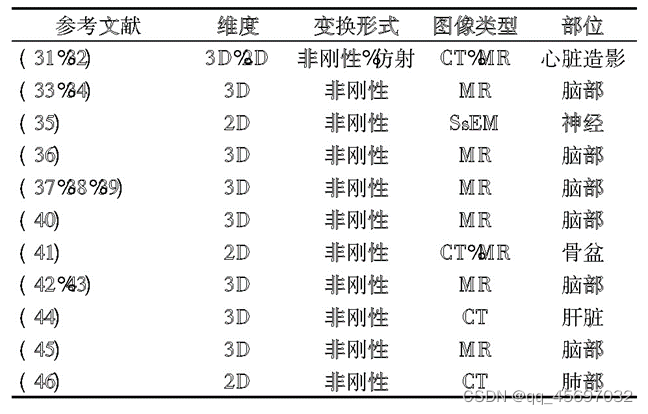
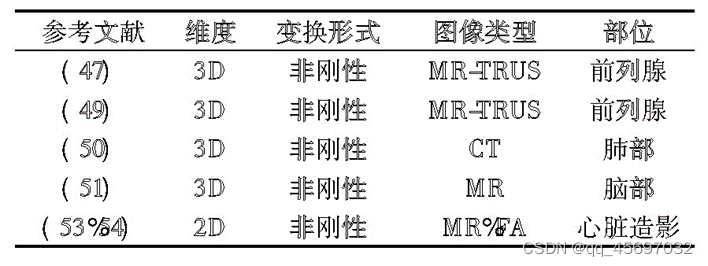
完全监督估计根据下面的框架图就是将固定图像和移动图像输入到卷积神经网络当中,然后进行一系列操作得到变换参数,再通过和标准参数的差值得到的损失值反向传播回卷积神经网络,不断的进行迭代,最后得到输出值。后面是研究人员在此基础上进行改进等操作后的数据,这里分别在维度、变换形式、图像 类型以及部位做出了概述。双重监督通常是指使用标准标签数据和一些图像相似性度量共同产生的损失函数对网络进行训练,双重监督可以减轻对标准标签的依赖性。弱监督通常指的是在训练数据集中提供精确输出以外的标准标签数据值并用于计算损失函数。
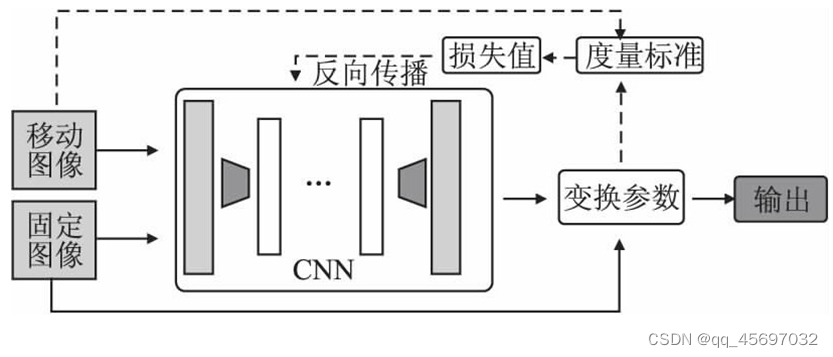
第二种方法是无监督变换估计。相较于监督学习,基于无监督学习的配准方法就是在训练学习网络时,只需要提供配准对,不需要标准标签数据( 即真实的变形场) 。下面是给出的框架图和方法概览。
第三种方法是基于生成对抗网络的配准方法。目前常见的方法是:通过引入基于网络的损失来训练对抗网络,训练鉴别器区分输入类型,区分该变换是预测还是真实标签、图像是真实还是由预测变换扭曲的图像、图像对齐是正对齐还是负对齐。

下面是配准方法评价指标的介绍。
目前,配准方法使用的评价指标有: 目标配准误差( TRE) 、DICE 相似性系数(DSC,DICE) 、HD95 ( Hausdorff_95) 、雅可比行列式等。
①目标配准误差指的是配准后基准点与相应点之间的距离,通常建议使用金标准的点和与之对应转换的点用于计算 TRE 值。
②DICE 相似性系数是一种集合相似度度量指标,通常用于计算两个样本的相似度,值的范围为( 0,1) ,其值越趋于 1 时两个样本的重合度越高。DICE = 2( A∩B) /( A + B) .
③Hausdorff 距离是用于描述两组点集之间相似性程度的一种度量,由其距离公式可以看出它可以度量两个点集之间的最大不匹配程度。
④在配准后会得到图像的变形场,即图像的每个像素的位移形变的场,简称为密集变形场(DVF) 。以三维数据为例,假设 DVF 上存在点 J( i,j, k) ,则雅可比行列式可以写为:
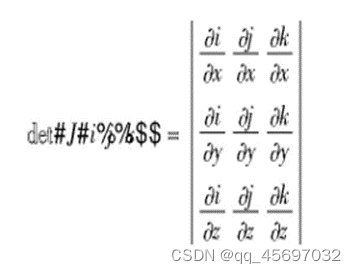
通过计算雅各比行列式的值可以判断该点是否发生折叠,从而量化 DVF 的质量、判断配准结果的优劣程度。
下面是配准数据集、指标与方法效果比较分析。
1.主要数据集:目前用于医学图像处理领域的数据集很多,简单介绍 DIRLAB、LPBA40、SCD、ADNI 和 OASIS 这 5 个数据集。
2.评价指标与金标准:常见的性能评价指标有: 鲁棒性、精度、抗噪性等。鲁棒性是指配准算法精确度的稳定性,也可以认为是算法的可靠性。精确度是指进行配准计算后得到的估计值与金标准之间的差异,差值越小说明配准效果越好。金标准是用来衡量配准算法实验效果的重要依据,它可以评价配准方法是否达到临床需求以及方法的性能优劣。
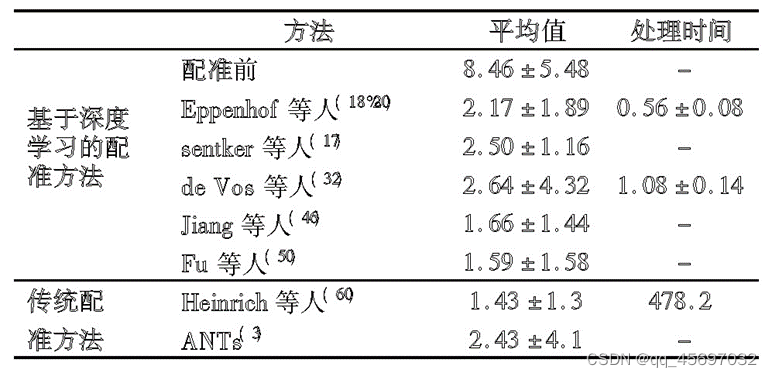
3.效果比较与分析
基于深度学习的配准方法已经达到甚至优于传统的配准方法,具有较好的发展前景。

最后总结一下。
基于深度学习的方法目前大多尚未在精度上优于传统的图像配准方法,但是由于基于深度学习的配准方法借助 GPU 进行直接估计,在计算成本和效率上,基于深度学习的方法比传统的配准方法要有优势得多。
目前基于深度学习方法进行配准是大势所趋,配准方法逐渐由部分依赖深度学习转向完全依赖深度学习,其性能和效果由逐渐达到传统配准方法的效果逐渐转为超越配准方法 的效果。然而,对于配准方法的性能进行评判的标准还需进一步研究,不仅缺少包括具有代表性、专家标注的图像公共数据集,也缺乏一个业界统一的评估标准。
论文来源:中国知网,作者莫晓盈

更多推荐


 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)