计算机网络课程大作业
计算机网络大作业,先利用wireshark抓包保存文件,还有很多不足的地方,欢迎交流
·
要求:
1. 用tcpdump收集某个主机或者路由器所连接的某个物理网络上的traffic, 存放到文件 中以备进一步分析使用。 收集流量的时间长短可以选择三种规格之一: A. 5分钟; B. 15分钟; C. 1小时
2. 编写程序处理原始数据文件, 整理成你认为方便处理的数据格式(纯文本)
3. 利用Matlab或其它工具, 或自行编写程序, 分别就进出两个方向上的traffic, 至少分 析以下特征:
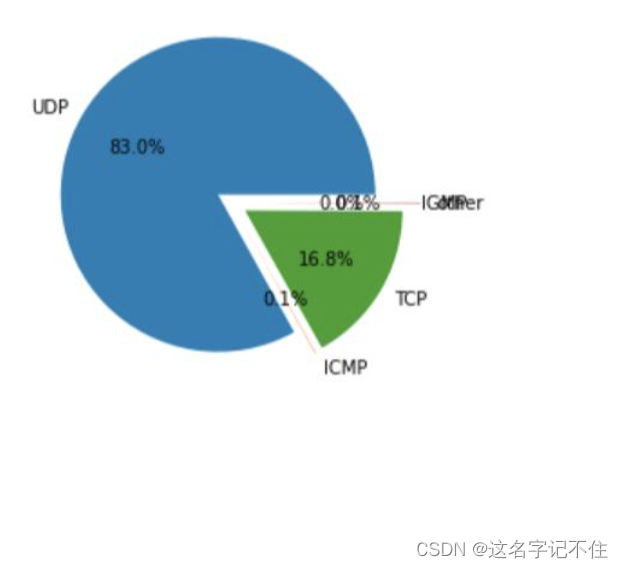
1) 给出IP分组携带不同协议的载荷的饼图, 分别按分组数和总数据量进行统计;
2) 有多少IP分组是片段(fragment) ? 有多少IP数据报被分片? 载荷为TCP和UDP的分别有多少 比例的IP数据报被分片?
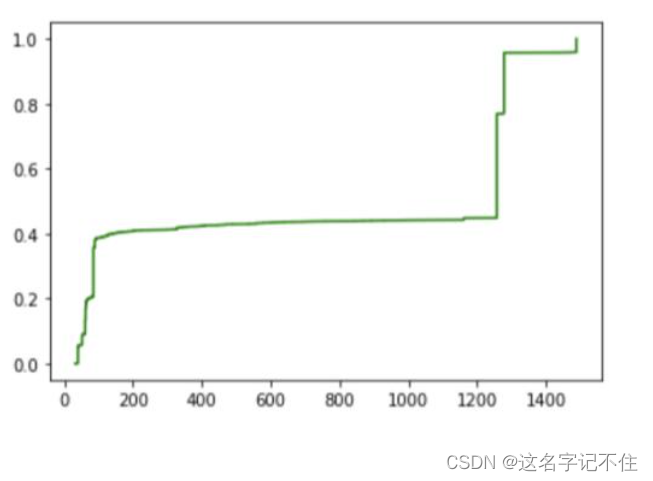
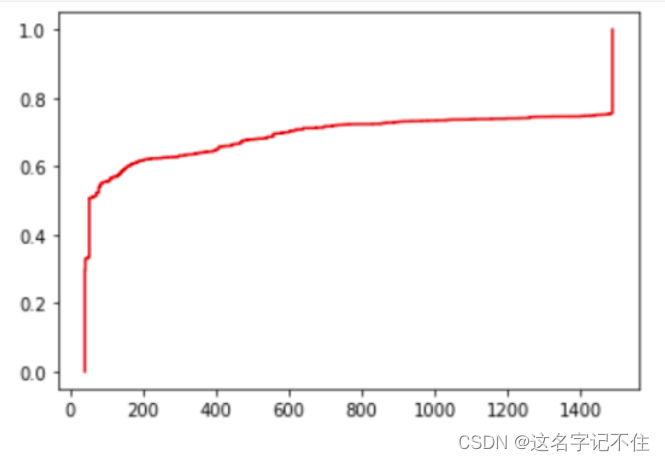
3) 给出IP数据报长度的累积分布曲线, 并分别比较载荷为TCP和UDP的IP数据报长度的累计分布;
4) 分别对TCP和UDP的traffic给出端口分布的直方图, 比较前10名端口上数据报长度的累计分布 曲线;
5) 对于载荷为TCP的报文, 给出其中各个控制位出现的百分比。
4. 撰写一份实验报告, 说明收集数据的时间、 地点、 工具、 方法、 数据结构及自行编写 的程序源代码; 给出所绘制的数据表格、 图形及曲线, 并注明分析的对象并归纳可能 得到的结论; 报告应包含原始数据用tcpdump不带-x参数读出的最初1000行和最末 1000行作为附录。
全部代码,一些要求没实现
#%%
from scapy.all import *
from scapy.utils import PcapReader
import scapy.all as scapy
import matplotlib.pyplot as plt
import numpy as np
b=0 #IP num
c=0 #ICMP num
# d=0 #ARP num
e=0 #UDP num
f=0 #TCP num
# g=0 #IPv6 num
h=0 #IGMP num
# id数组存储ip的id,为判断是否分片
ip_id=[]
udp_id=[]
tcp_id=[]
# len字段,数据报长度
ip_len=[]
tcp_len=[]
udp_len=[]
# tcp udp 的端口
tcp_src=[]
tcp_dst=[]
udp_src=[]
udp_dst=[]
# tcp的控制位
lis=[]
lissname=[]
# 读取文件
# wireshark 抓包保存的文件
pkts = rdpcap('./5minutes.pcapng')
for pkt in pkts:
if 'IP' in pkt:
ip_id.append(pkt['IP'].id)
ip_len.append(pkt.len)
b+=1
if pkt.payload.payload.name == 'ICMP':
c+=1
if pkt.payload.payload.name == 'TCP':
tcp_id.append(pkt.id)
tcp_len.append(pkt.len)
tcp_src.append(pkt.sport)
tcp_dst.append(pkt.dport)
f+=1
if pkt.payload.payload.name == 'UDP':
udp_id.append(pkt.id)
udp_len.append(pkt.len)
udp_src.append(pkt.sport)
udp_dst.append(pkt.dport)
e+=1
if pkt.payload.payload.name =='IGMP':
h+=1
else:
lissname.append(pkt.payload.payload.name)
# 控制位
if 'TCP' in pkt:
lis.append(pkt['TCP'].flags)
other = b - e - c - f -h # 其他包
x=[e,c,f,other,h]
plt.pie(x,autopct='%1.1f%%',labels=['UDP','ICMP','TCP','other','IGMP'],explode=[0.1,0.1,0.1,0.2,0.1])
plt.show()
# len()-len(set())
# set() 去重
ipfnum=len(ip_id)-len(set(ip_id))
tcpfnum=len(tcp_id)-len(set(tcp_id))
udpfnum=len(udp_id)-len(set(udp_id))
print("ip分片包数量:",len(ip_id)-len(set(ip_id)))
print("udp分片包数量:",len(udp_id)-len(set(udp_id)),"占比为:",round(udpfnum/ipfnum,2))
print("tcp分片包数量:",len(tcp_id)-len(set(tcp_id)),"占比为:",round(tcpfnum/ipfnum,2))
# 使用直方图确实是不必要的繁重和不精确(binning使数据变得模糊)
# 对所有x值进行排序
# 每个值的索引是较小的值的数目。
# 更合适的绘图样式实际上是plt.step()
# 因为数据位于离散位置
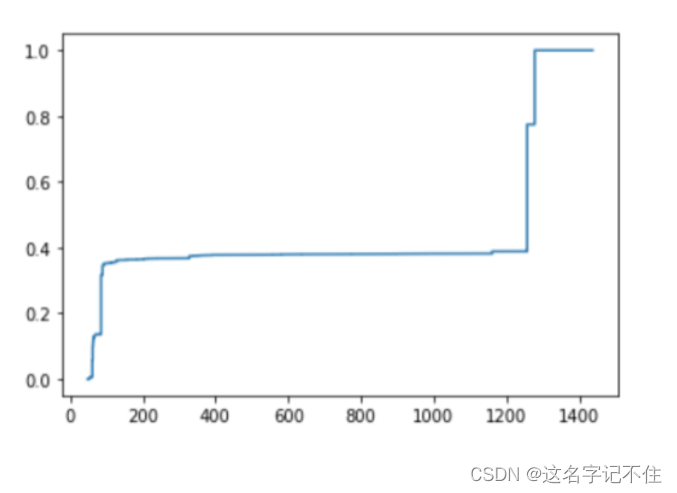
# IP数据报累积分布图
iplenlen=len(ip_len)
sorted_ip = np.sort(ip_len)
plt.step(sorted_ip, (np.arange(sorted_ip.size))/round(iplenlen,1),c='green')
plt.show()
# tcp数据报累积分布图
tcplenlen=len(tcp_len)
sorted_tcp = np.sort(tcp_len)
plt.step(sorted_tcp, (np.arange(sorted_tcp.size))/round(tcplenlen,1),c='red')
plt.show()
# udp数据报累积分布图
udplenlen=len(udp_len)
sorted_udp = np.sort(udp_len)
plt.step(sorted_udp, (np.arange(sorted_udp.size))/round(udplenlen,1))
plt.show()
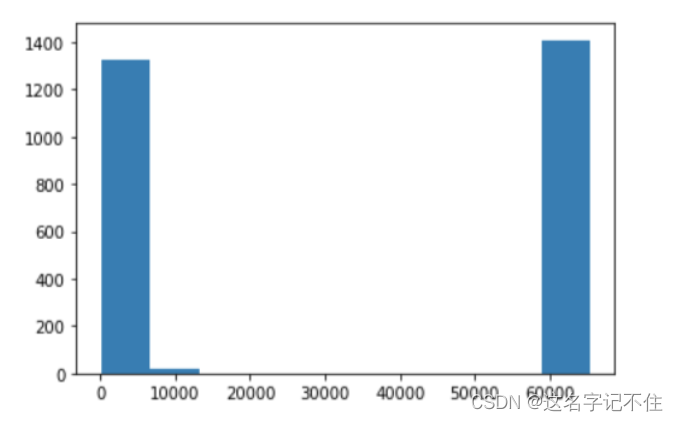
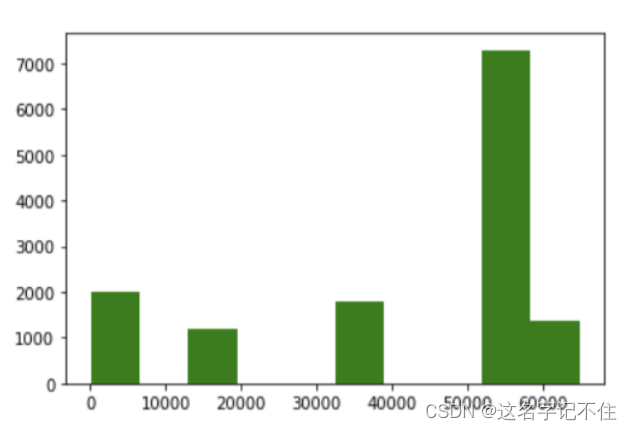
# TCP源端口分布的直方图
plt.hist(tcp_src)
plt.show()
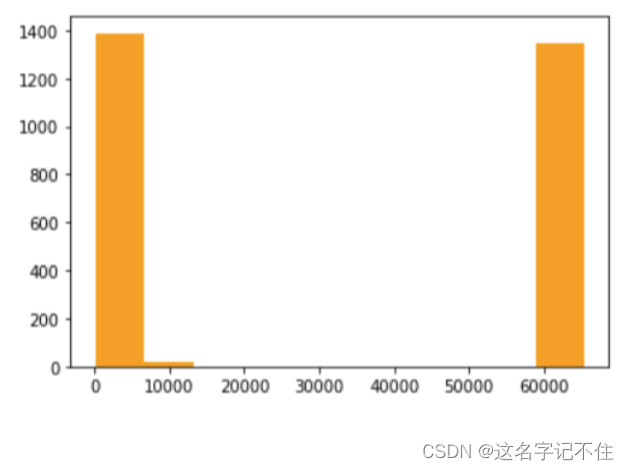
# TCP目标端口分布的直方图
plt.hist(tcp_dst,color='orange')
plt.show()
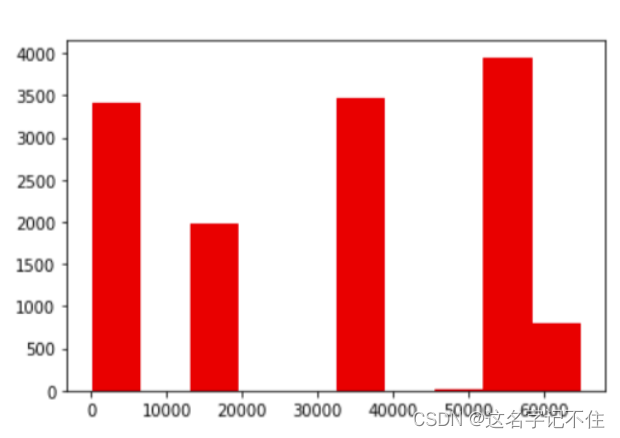
#UDP源端口分布的直方图
plt.hist(udp_src,color='red')
plt.show()
# UDP目标端口分布的直方图
plt.hist(udp_dst,color='green')
plt.show()
#tcp控制位的百分比
unum=0
anum=0
rnum=0
pnum=0
Fnum=0 #'F'+'Flag'
snum=0
lnum=0 #'Flag'='l'='a'='g'
mm=str(lis)
for item in mm:
if item=='S':
snum+=1
if item=='R':
rnum+=1
if item=='A':
anum+=1
if item=='F':
Fnum+=1
if item=='U':
unum+=1
if item=='P':
pnum+=1
if item=='l':
lnum+=1
fnum =Fnum-lnum # 实际F
sum=anum+rnum+pnum+snum+unum+fnum
# round(x,2) 保留两位小数
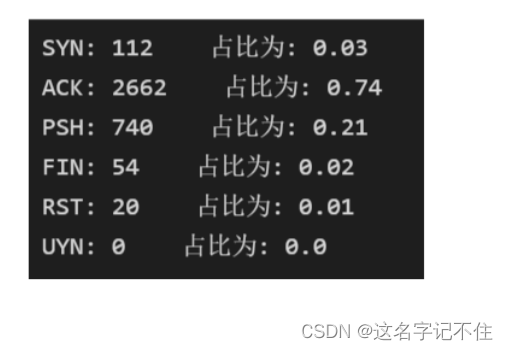
print("SYN:",snum," 占比为:",round(snum/sum,2))
print("ACK:",anum," 占比为:",round(anum/sum,2))
print("PSH:",pnum," 占比为:",round(pnum/sum,2))
print('FIN:',fnum," 占比为:",round(fnum/sum,2))
print("RST:",rnum," 占比为:",round(rnum/sum,2))
print("UYN:",unum," 占比为:",round(unum/sum,2))
实验截图

点击阅读全文

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐



 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)