
【领域泛化论文阅读】Learning to Diversify for Single Domain Generalization
论文提出了style-complement模块增强模型的泛化能力,将与源域分布互补的多种不同分布的图像进行合成,生成具有原始分布之外的不可见样式的样本。通过最小化样本对的MI上界,使生成图像从源样本多样化;通过最大化来自相同语义类别的样本之间的MI,使网络能学习来自不同图像的可区分的feature,获得style-invariant feature。样式补充模块和任务模型通过最小-最大互信息优化策
论文提出了style-complement模块增强模型的泛化能力,将与源域分布互补的多种不同分布的图像进行合成,生成具有原始分布之外的不可见样式的样本。
通过最小化样本对的MI上界,使生成图像从源样本多样化;通过最大化来自相同语义类别的样本之间的MI,使网络能学习来自不同图像的可区分的feature,获得style-invariant feature。
样式补充模块和任务模型通过最小-最大互信息优化策略,通过迭代逐渐扩大生成图像和源图像之间的分布偏移,同时使来自同一语义类别的样本在潜在空间靠近,提高任务模型的泛化能力。
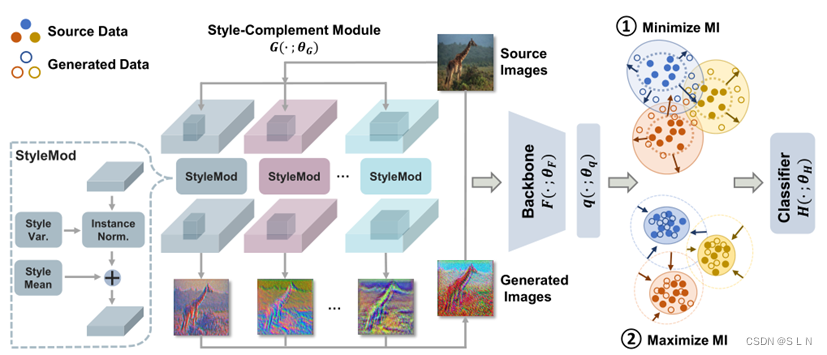
(1)Style-Complement Module
G(·;θG)包括K次变换,变换由a convolutional layer, a style learning layer,and a transposed convolutional layer组成,将源图像从原始分布投影到具有任意样式偏移的新分布。style learning layer如式(6)所示,

得到k个的xi,k+经过线性组合得到源域样本xi所对应的xi+,如式(7)所示,

(2)Synthesizing Novel Styles
为了增加创建的样式的多样性,生成的图像和源图像之间的相关性应该最小化。互信息MI可以衡量图像之间的相关性。
源域图像x和生成图像x+经过F (·; θF)映射为feature z和z+,通过最小化I(z,z+)的上界式(8),减小相关性,MI最小上界算法可见[4],

(3)Semantic Consistency
为了防止生成具有扭曲语义信息的图像,最小化类别条件下的最大均值差异MMD,这样可以限制属于同一类别的样本的分布偏移来缓解潜在语义信息的失真。

样式补足模块的目标是生成具有最少源图像信息的不同图像,而任务模型可以在嵌入空间中对具有相同语义标签的图像进行聚类。
(4)MI Maximization
使用监督对比损失式(11)来增加来自同一类别的样本之间的互信息,

为了进一步增强语义一致性,最小化源图像x和生成图像x+上的交叉熵损失,

训练F的目标函数是

训练G的目标函数是


鸿蒙生态一站式服务平台。
更多推荐

 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)