
Puppeteer之定位和操作页面元素
Puppeteer系列三之定位和操作页面元素
想利用框架写好UI层测试,首先需要熟悉框架提供的各种操作页面元素的api,然后利用这些api编写完整的测试案例。故此篇博客将介绍如何利用puppeteer定位和操作页面元素。在介绍如何定位和操作页面元素前,我们先对页面常用操作进行简单的梳理,梳理出的常用操作如下所示。

此章节只会讲解第一行中的前面三种场景,后续课程会讲解其他类型的操作。另外,puppeteer中如果需要操作的页面元素不在viewport中,当操作页面元素时会自动拖动滚动条,让页面元素显示到viewport中,基本无需自己编写脚本实现屏幕滚动,所以课程中不讲解如何在脚本中拖动滚动条。
接着我们再看下puppeteer提供的7种查找页面元素方式
- 1.通过id或者class或者标签定位元素;id是#id值;class是.class名字;标签直接使用标签名称即可
- 2.通过id或者class或者标签和属性共同定位元素
- 3.通过xpath定位元素,xpath可读性比较差,不建议大家使用该方式定位页面元素,故这里也不做介绍
- 4.先查找符合条件的多个元素,再在多个元素中按元素顺序进行筛选,即选择页面元素的某个子元素
- 5.先查找父元素,再在父元素基础上继续定位元素
- 6.通过元素包含的text定位元素(仅expect-puppeteer才提供)
- 7.通过document定位元素
使用puppeteer查找元素可以用page$(selector)或者page$$(selector),两者的区别是:如果selector匹配到多个页面元素,那么前者是取第一个页面元素,后者是取出所有页面元素。获取元素后对元素进行操作有两种方式,一种是查找和操作页面元素分开写,一种是查找和操作页面元素连成一行代码编写。下面是两种写法的例子。
同样,执行 “npm run basic-find-element” 即可运行所有查找、操作页面元素的案例。
通过上面的例子可以看到,使用puppeteer时既可以将定位元素和操作写到同一行代码,也可以先找出页面元素,再对该元素进行操作,这里的建议是能写到一行的就写到一行,这样代码更简洁。
it('should type text successfully', async() => {
await page.goto('http://juliemr.github.io/protractor-demo/');
const elementHandle = await page.$('input[ng-model="first"]');
//使用page$(selector)查找页面元素,这里使用标签+属性共同定位页面元素
//将查询到的页面元素赋值给常量elementHandle
await elementHandle.type('5');
//page对象提供的查找和操作页面元素的api,在elementHandle对象上基本都可以使用,这里调用elementHandle.type('xxx')模拟输入数字5
await page.type('input[ng-model="second"]', '3');
//操作页面元素第二种写法,将定位和操作页面元素连成一行代码
});接下来看看,对于下面的web页面,如何编写UI层脚本实现运算和校验的过程。下图是web页面的详细信息,可以看到运算符是个下拉的多选按钮,计算结果存放在table对象中。
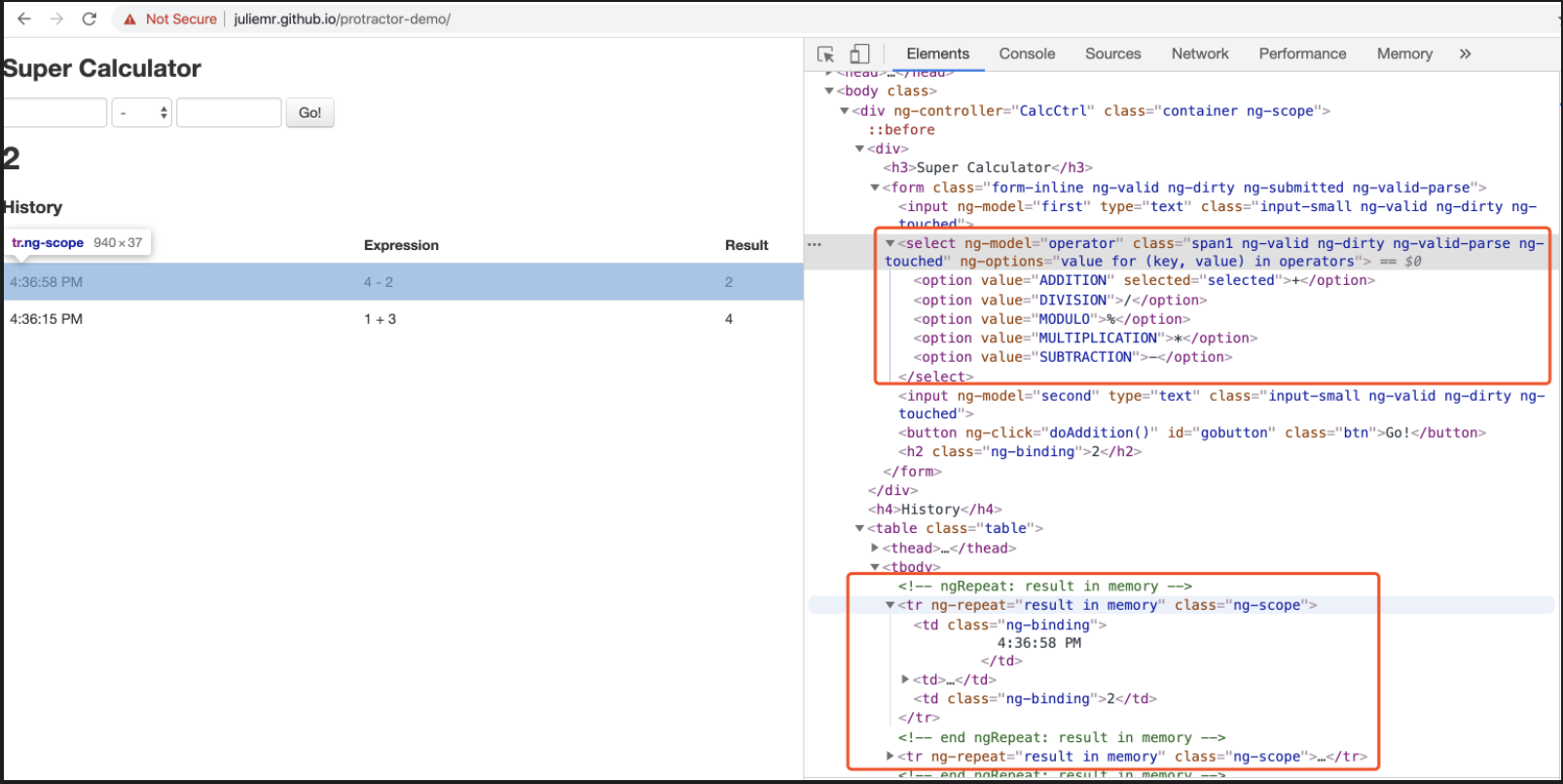
下面的自动化脚本实现了减法运算,并对运算结果进行校验。实际上节课程中演示自动等待时已运行过这个自动化案例,这里我们再分析下每行代码是如何实现定位和操作页面元素的。
it('should add numbers correctly', async () => {
await page.goto('http://juliemr.github.io/protractor-demo/');
await page.type('input[ng-model="first"]', '5');
//可以看到打开应用页面后,没有添加等待语句也正常,因为puppeteer提供的goto()方法会等待页面加载成功后才会进行下一步操作
await page.select('select[ng-model="operator"]','SUBTRACTION');
//下拉列表选择,puppeteer对于下拉列表的选择已经封装了很好的方法,第一个参数通过tag+属性值定位select element,第二个参数传入下拉列表中要选的值即可
await page.type('input[ng-model="second"]', '3');
await page.click('#gobutton');
await page.waitForSelector('h2',{timeout: 3000});
//在校验结果前添加等待语句,且设置了等待超时时间
expect(await page.$eval('h2', el => el.innerText)).toContain('2');
//校验结果的两种写法,这里是把获取结果以及校验写到一行代码中,校验相关的内容下节课程还会详细讲解
let value = await page.$eval('tbody tr:nth-child(1) td:nth-child(3)',el=> {return el.innerText});
expect(value).toContain('2');
//这里先获取table中的计算结果列的值,即tbody tr:nth-child(1) td:nth-child(3)的innerText,然后调用expect进行校验
});上面的案例脚本没有使用expect-puppeteer,接下来我们再看看如果要使用自动等待,上面的自动化案例如何实现。
可以看到引入expect-puppeteer后,只是写法上有些变化,定位页面元素的selector无任何变化,那么expect-puppeteer总共提供了哪些api呢?expect-puppeteeer总共提供了8个api,这8个api都实现了自动等待机制。
- toClick:自动等待的点击操作,即点击页面元素前会自动等待页面元素加载,直到达到超时等待时间,上面案例已使用过
- toDisplayDialog:期望进行某个操作后显示dialog框
- toFill:输入内容到页面输入框中,例如input上输入内容,上面案例已使用过
- toFillForm:填写表单内容
- toMatch:确认页面是否存在某个text文案信息
- toMatchElement:校验是否存在某个页面元素,上面案例已使用过
- toSelect:下拉列表选择,上面案例已使用过
- toUploadFile:上传文件
it('should add numbers correctly with auto wait', async () => { await page.goto('http://juliemr.github.io/protractor-demo/') await expect(page).toFill('input[ng-model="first"]','5'); //通过tag+属性值定位element await expect(page).toSelect('select[ng-model="operator"]','SUBTRACTION'); //下拉列表选择,puppeteer对于下拉列表的选择已经封装了很好的方法,第一个参数通过tag+属性值定位select element,第二个参数传入下拉列表中要选的值即可 await expect(page).toFill('input[ng-model="second"]', '3'); await expect(page).toClick('#gobutton'); //通过id定位element await expect(page).toMatchElement('h2',{text:'2'}); await expect(page).toMatchElement('tbody tr:nth-child(1) td:nth-child(3)',{text:'2'}); //这里先通过tag定位多个tr:tbody tr,然后通过顺序查找tr中第一个tr,在此基础上继续查找tr下第三个td //tag:nth-child(x)方式定位第x个element
上面案例调用expect-puppeteer提供的方法时,只输入了部分参数,实际每个api还可以传递其他可选参数。以toClick()为例:expect(page | elementHandle).toClick(selector|matchSelector,{options})。
-
expect()中可以传递page对象或者elementHandle对象,elementHanle对象即page$(selector)或者page$$(selector)返回的对象。
-
toClick()的第一个参数可以输入selector或者matchSelector,matchSelector即“ {type:'css', value:'form[name="myForm"]'} ”或者 “{type:'xpath', value:'.\a'}”,css方式和直接输入selector效果是一样的,对于xpath方式,因为可读性差,所以不建议使用此方式定位页面元素,故这里掌握selector写法即可。
-
toClick()的第二个参数options,可以传入的options包含button、clickCount、delay、text,如果传入多个options参数用逗号隔开。例如{delay:10,text:'innerTextValue'}。options中最常用的是text,通过添加text参数,可以查到innerText等于text的页面元素,后面会单独对text参数进行讲解。
上面是toClick()各个参数的说明,其他方法的参数很多和toClick()类似,这里不再重复说明,如果想了解其他方法可传入的参数详细信息,可查看官方文档“ jest-puppeteer/packages/expect-puppeteer at master · smooth-code/jest-puppeteer · GitHub ”
上面案例中演示了如何通过class、id、标签名称、属性值等方式查找页面元素。另外,也演示了如何通过nth-child的方式查找页面元素的子元素。接下来我们看看如何查找父元素后,在父元素基础上继续查找期望匹配的页面元素。
it("use puppeteer-expect under elementHandle", async() => {
await page.goto('http://juliemr.github.io/protractor-demo/');
//find parent element
const elementHandle = await page.$('.container.ng-scope');
await expect(elementHandle).toFill('input[ng-model="first"]','55');
//所有在page对象上能调用的方法,例如toFill,toClick等,在elementHandle中都可以使用,page.$('selector')返回elementHandle
}) 可以看到通过将elementHandle赋值给常量的方式可以很容易实现基于父元素定位查找页面元素,实际项目中,如果定位页面元素的selector很长,那么可以通过此方式逐级定位,简化selector复杂程度。另外,上面案例只写了一层,实际elementHandle.$(selector)返回的对象仍然是个elementHandle,所以,再复杂的selector都可以通过此方式逐层查找进行简化。
最后,我们再看看如何通过页面元素的containText定位页面元素。此方式在实际项目中很常用,因为很多页面元素的innerText可以作为区别元素的标识,例如button的名字,多选、单选按钮的名字,不同的按钮代表不同的业务操作,他们的名字往往都和业务含义绑定,故基本不存在相同名字的页面元素(除确认、取消等通用性的按钮)。但实际web应用中往往innertText左右存在空格,此时如果用完全匹配定位页面元素,那么text也需要输入空格,为了脚本稳定性考虑,更好的方式是局部匹配,即containText方式。
如下图所示,如果要点击“sign in”链接,可以通过innertText定位该链接,但innerText左右存在空格。
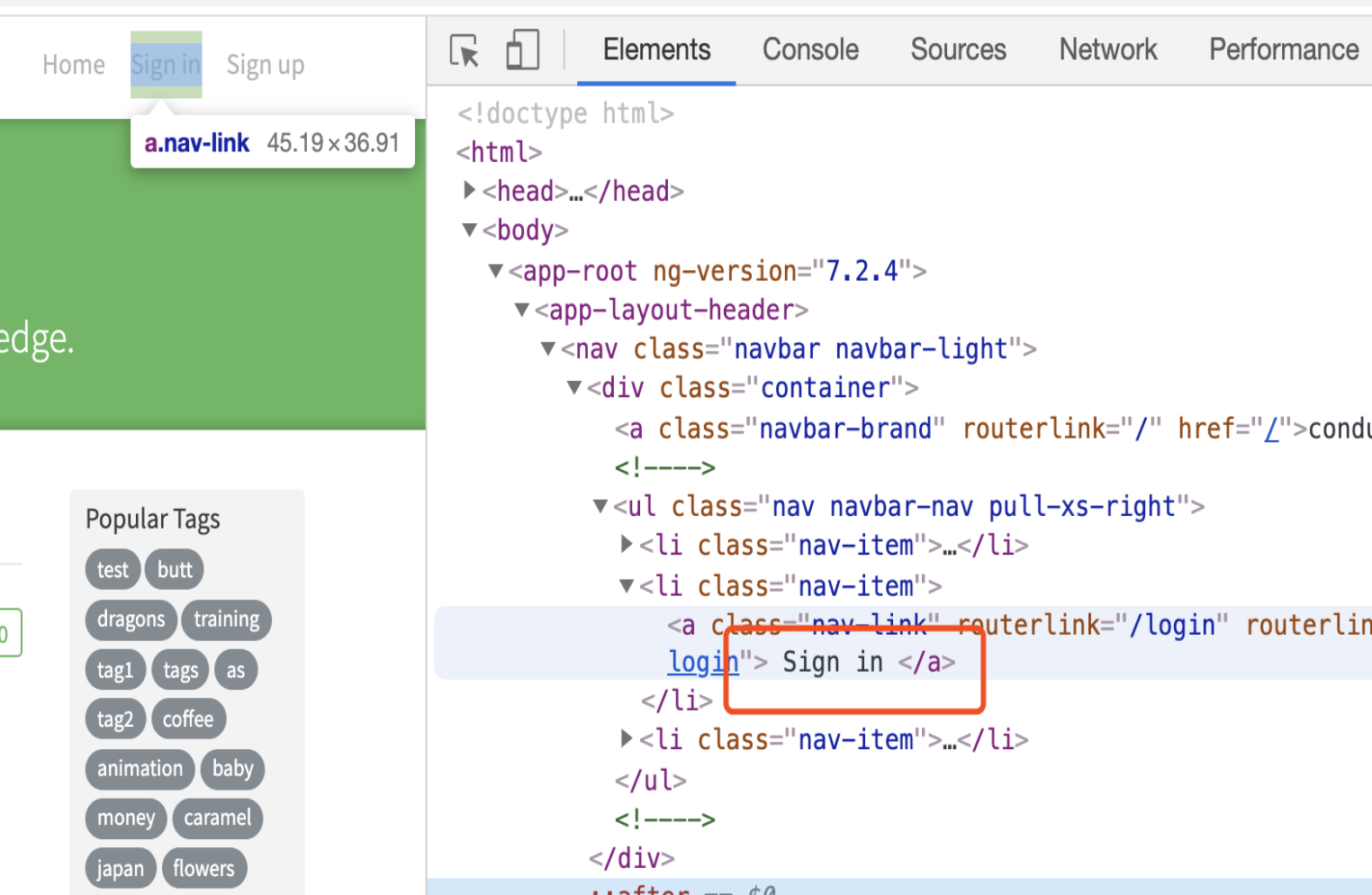
以下是定位“sign in”的脚本,同样,执行“npm run containText-find-element”即可运行下面的脚本。
it("find element with contain text", async()=> {
await page.goto('https://angular.realworld.io/');
await expect(page).toClick('app-home-page li a',{text:/.*Global Feed.*/});
await expect(page).toClick('app-layout-header li a',{text: /.*Sign in.*/})
//采用正则表达式进行匹配{text:/.*textContent.*/}
})可以看到,采用expect(page|elementHandle).toClick(selector,{text:regex})方式可以很容易实现containText定位页面元素。需要注意一点是:只有expect-puppeteer提供传入正则表达式参数,故如果要使用containText方式定位页面元素必须使用expect-puppeteer。
上面讲解的都是puppeteer或者expect-puppeteer提供的定位页面元素api。实际项目中,个别情况下某些页面元素直接通过puppeteer提供的方法可能无法定位,如果遇到此情况,还可以尝试调用document对象定位页面元素。
例如,下面应用中,“Global Feed”页面中存放了所有人创建的帖子,如果测试场景是点赞自己创建的帖子,那么如何实现呢?页面元素如下图所示
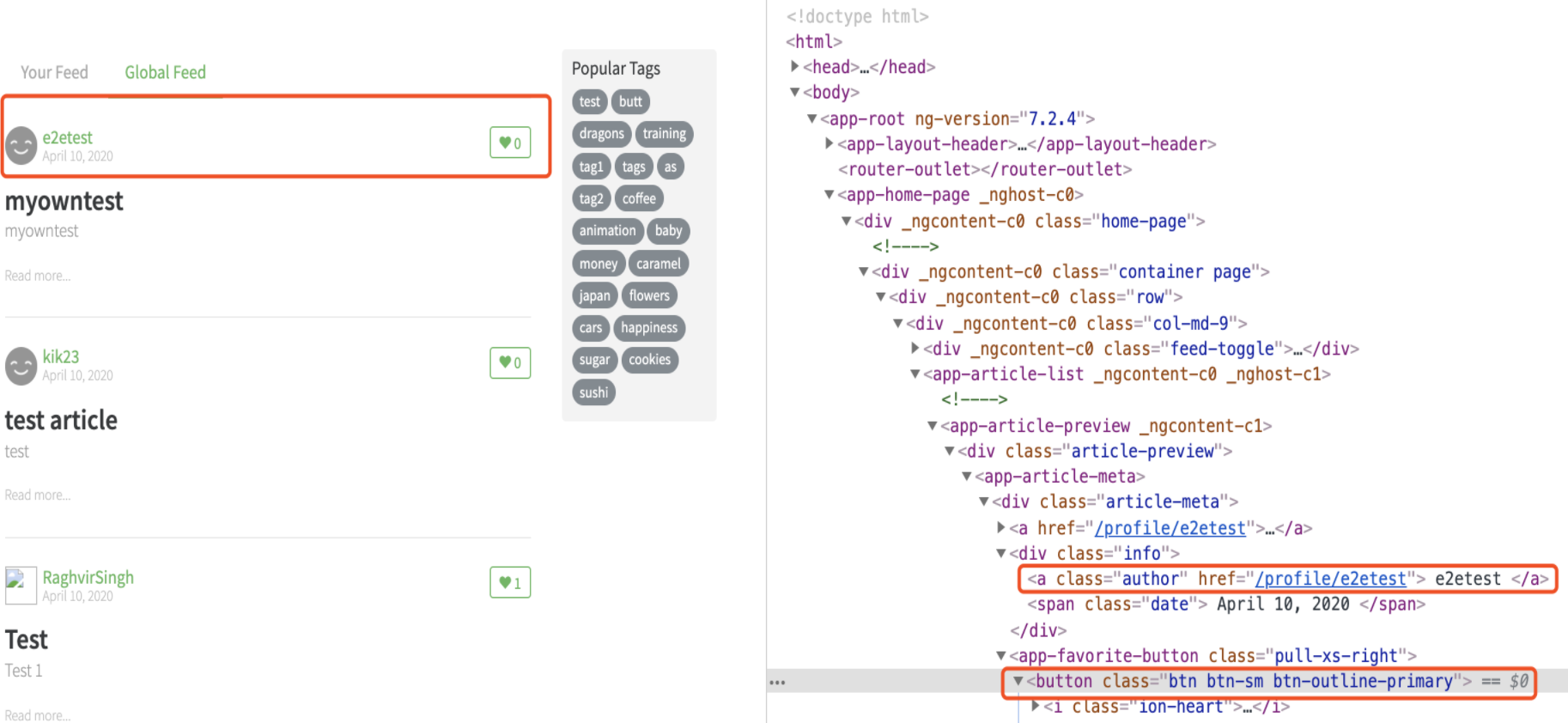
可以看到如果要点赞自己的帖子,只有通过登陆的用户名称先定位到 < a class="author"> 标签,定位到此标签后,为了点击右边的“点赞”按钮,需要先找到上面的 < app-article-preview> 标签,然后在此层标签下查找 < button> 标签完成点击操作。Puppeteer提供了 “page.evalute(()=>{})” 的方式连接document对象,具体实现的代码如下所示,同样,执行“npm run document-query-element” 即可运行下面的案例。
describe("querySelector demo ", ()=>{
it("use parentNode to find element", async()=> {
await page.goto('https://angular.realworld.io/');
await expect(page).toClick('app-layout-header li a[href="/login"]');
await expect(page).toFill('app-auth-page form input[formcontrolname="email"]','e2etest@163.com');
await expect(page).toFill('app-auth-page form input[formcontrolname="password"]','12345678');
await expect(page).toClick('app-auth-page button[type="submit"]');
await expect(page).toClick('app-home-page li a',{text:/.*Global Feed.*/});
await page.waitForSelector('app-article-meta a[href="/profile/e2etest"]');
//在执行page.evaluate()方法之前,一定要加waitForSelector()保证后面要查找的元素已经显示在页面上
await page.evaluate(() => {
document.querySelector('app-article-meta a[href="/profile/e2etest"]').parentElement.querySelector('button').click();
//这里.parentElement()是获取最近的parentElement,如果期望获取的父元素不是最近的父元素,那么需要多次调用parentElement
});
// 通过page.evaluate()即可连接document对象,使用该对象对外提供api
})
});在使用document.querySelector()时,可以利用浏览器的console进行实时调试。例如,下面案例中点击右上角的“Sign in”菜单,除前面介绍的方法外,还可以通过先获取< li a >标签数组的方式筛选查找,在编写脚本时利用console进行调试,下面是调试结果图
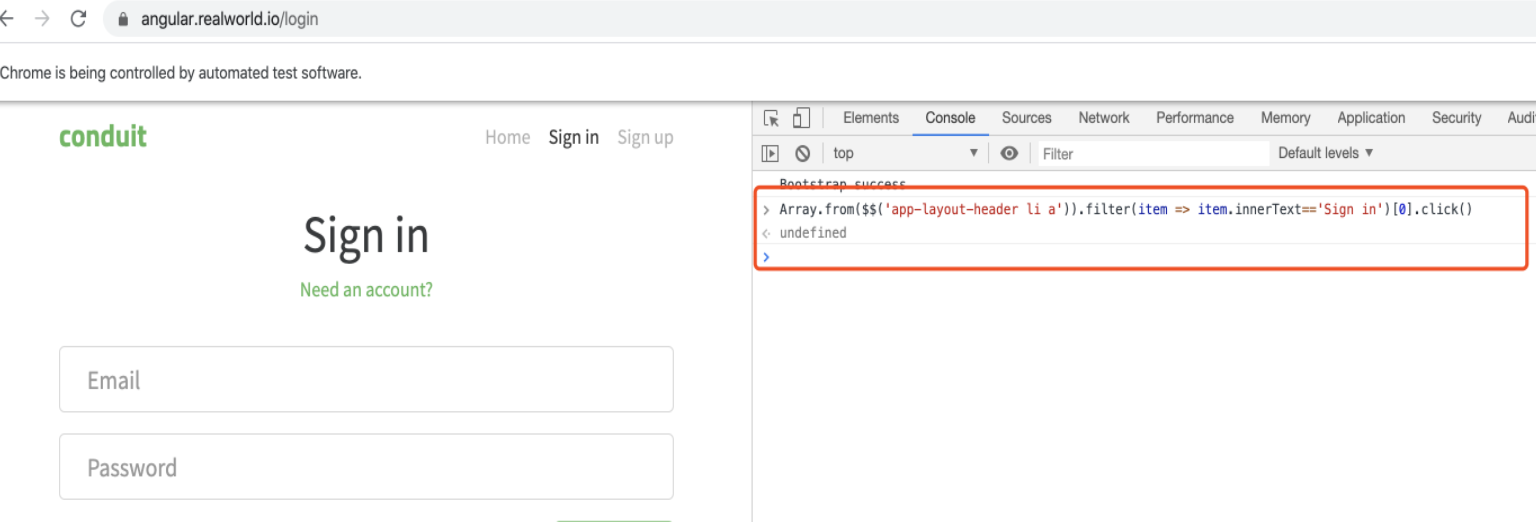
console中输入脚本,确实点击了右上角的“ Sign in”链接,说明脚本正确。此时将脚本迁移到自动化案例中,案例运行成功,迁移后的脚本如下图所示
it("filter element with document querySelector", async() => {
await page.goto('https://angular.realworld.io/');
await page.waitForSelector('app-layout-header li a[href="/login"]');
await page.evaluate(() => {
Array.from(document.querySelectorAll('app-layout-header li a')).filter(item => item.innerText=='Sign in')[0].click()
});
// 调用querySeelctorAll的方式查找所有符合条件的elements,通过Array.from将elements转换为数组对象,然后调用数组对象提供的filter()方法查找符合条件的元素并进行点击操作
})同时,还可以获取某个元素的子元素后,再调用querySelector()定位操作页面元素,脚本如下所示
it("get childElement with document querySelector", async () => {
await page.goto('https://angular.realworld.io/');
await page.waitForSelector('app-layout-header li a[href="/login"]');
await page.evaluate(() => {
document.querySelector('app-layout-header ul').firstElementChild.querySelector('li a').click();
document.querySelector('app-layout-header ul').lastElementChild.querySelector('li a').click();
//先通过querySelector定位某个元素,然后调用firstElementChild或者lastElementChild获取该元素的第一个或者最后一个子元素,在此基础上,再调用querySelector定位需要的元素
})
})以上就是通过获取document对象查找页面元素,总结而言,如果要获取document对象,那么需要调用page.evaluate()方法。在page.evaluate()方法内,调用querySelector()定位元素后,再调用parentEelment或者childElement获取父或者子元素。另外,在page.evaluate()方法内还可以调用querySelectorAll()获取elementList,然后调用find或者filter筛选符合条件的页面元素。学习了通过document对象定位页面元素后,基本可以覆盖UI层测试中所有定位页面元素场景了。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 1
1 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)