NER 原理及 TENER 模型搭建
参考:论文地址:https://arxiv.org/pdf/1911.04474.pdf参考 Github 代码实现:https://github.com/fastnlp/TENER用到的 fastNLP Github:https://github.com/fastnlp/fastNLPfastNLP 模型 save:https://fastnlp.readthedocs.io/zh/latest
参考:
NER 原理:https://paddlepedia.readthedocs.io/en/latest/tutorials/natural_language_processing/ner/bilstm_crf.html
NER 多种实现(浅显):https://zhuanlan.zhihu.com/p/88544122
论文地址:https://arxiv.org/pdf/1911.04474.pdf
参考 Github 代码实现:https://github.com/fastnlp/TENER
用到的 fastNLP Github:https://github.com/fastnlp/fastNLP
fastNLP 模型 save:https://fastnlp.readthedocs.io/zh/latest/fastNLP.io.model_io.html
需要保存 Vocabulary:https://fastnlp.readthedocs.io/zh/latest/fastNLP.core.vocabulary.html
NER 原理
NER 包括两个方面:BILSTM / Bert / Transform + Linear(softmax) + CRF
- 其中神经网络层:主要是 input(文本) -> embedding 化 -> 通过 lstm / transformer 等提取特征信息 --> softmax 得到每个字符(char)的 label(B-xx、I-xx、O…)概率([context_size,tag_size] 的矩阵,其中每个字词对应一行标签 softmax 分数)
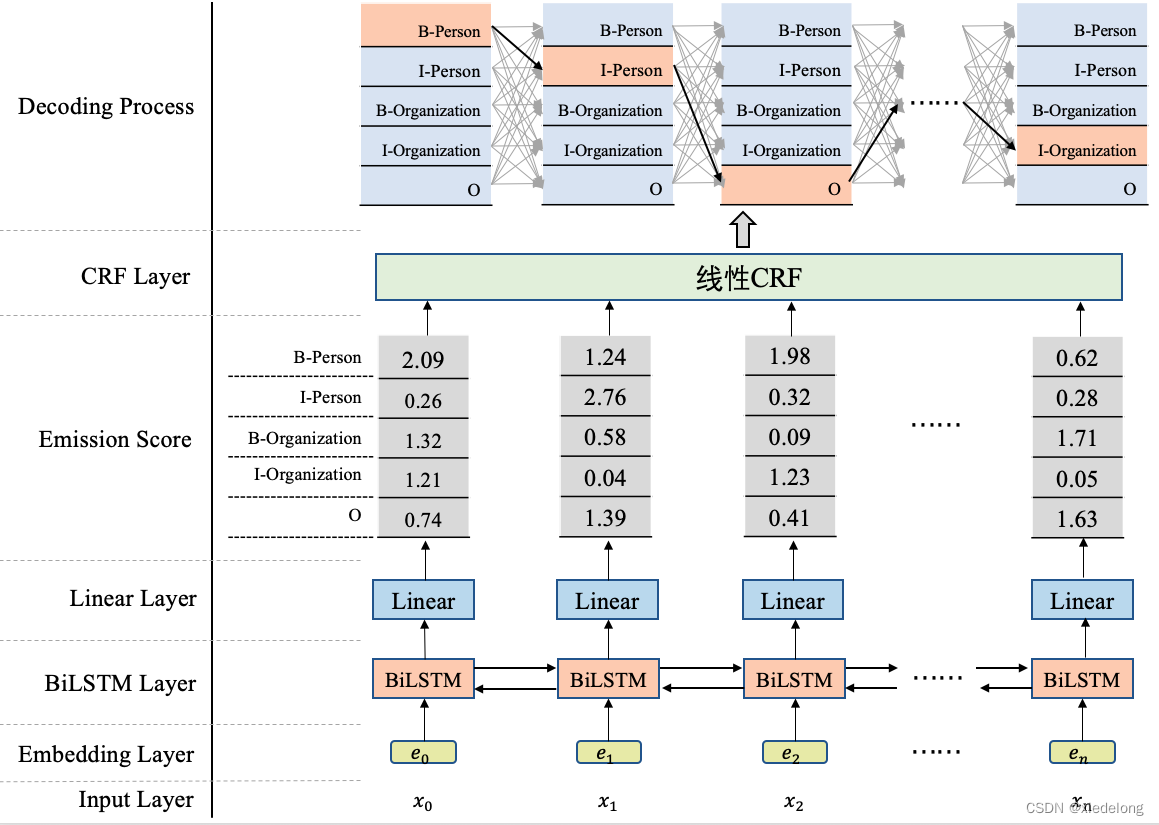
- CRF 层:是
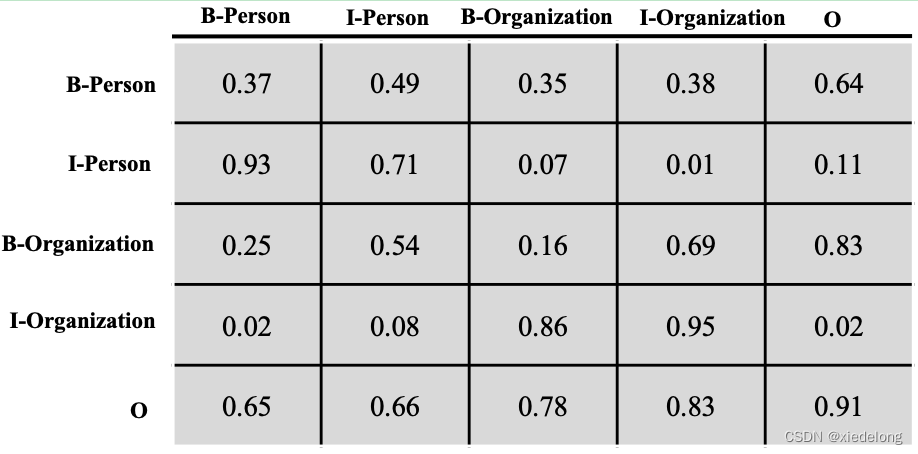
tag_size * tag_size的可学习概率矩阵
- 损失函数:模型学习到了第一步的
[context_size, tag_size]概率矩阵,也就是每个字符(xi)都得到一个属于哪种 tag 的概率值,如果没有 CRF,那么对每个字符的概率向量,计算 argmax 得到的就是最终的 Y 序列。但是每个字符都是最大概率值,不等于最后的 Y 序列概率最大(最大似然),所以需要找到概率最大的路径(也就是y1 -> y2 -> y3 -> ...概率最大):CRF的解码策略就是在所有可能的路径中,找出得出概率最大,效果最优的一条路径,那这个标签序列就是模型的最终输出 Y。
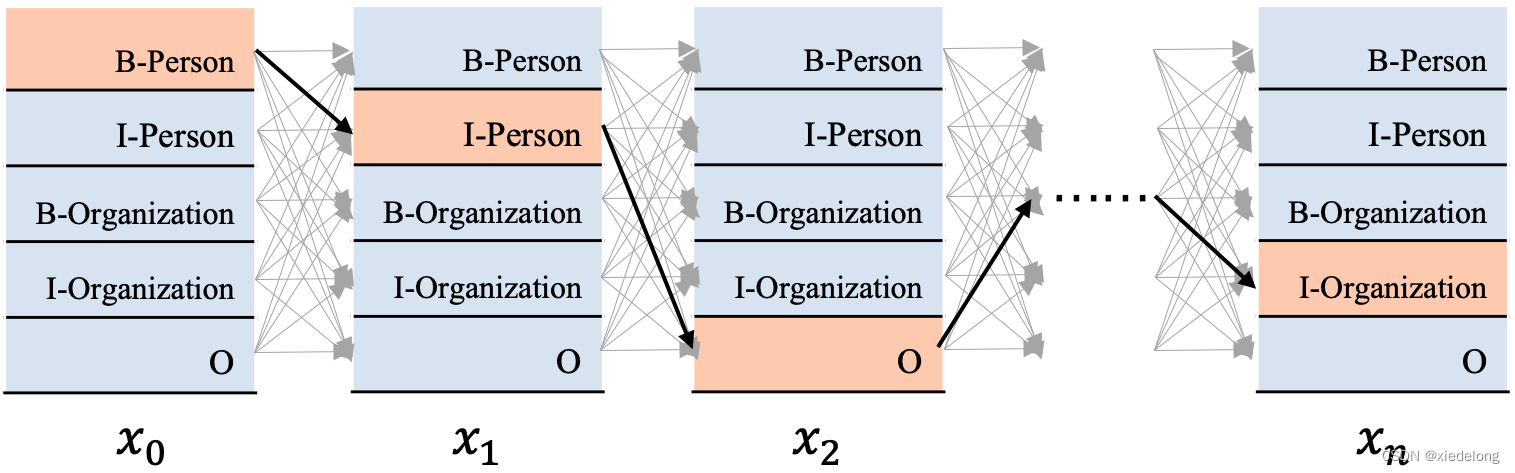
假设标签数量是k,文本长度是n,显然会有N=k**n (k 的 n 次方)条路径,若用 Si 代表第i条路径的分数,那我们可以这样去算一个标签序列出现的概率:
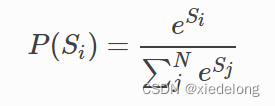
显然,我们需要让 Real 真实的那条路径概率最大,也就是:
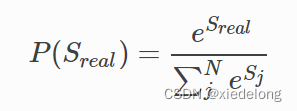
因此,我们建模学习的目的就是为了不断的提高 P(Sreal) 的概率值,这就是我们的目标函数,当目标函数越大时,它对应的损失就应该越小,所以我们可以这样去建模它的损失函数:
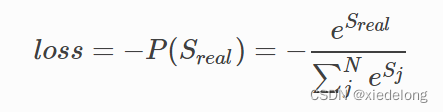
放到log空间去求解后:
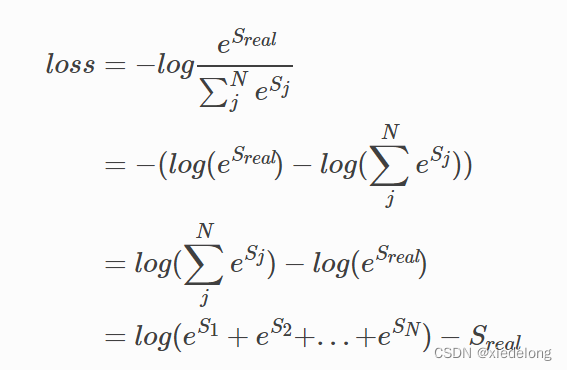
省略一系列推导,可以参考:https://paddlepedia.readthedocs.io/en/latest/tutorials/natural_language_processing/ner/bilstm_crf.html
对于只有两个 tag 的例子,到 x1 位置的概率为log(ex00+t00+x10+ex01+t01+x10+ex00+t10+x11+ex01+t11+x11),其中 x00 表示 x0 这个字符(索引为 0 的字符)属于 tag0 的概率,也就是 lstm 网络第一行的 softmax 概率向量,t00 表示从 tag1 转移到 tag0 的概率,见下图公式

因此模型的损失是综合了 lstm 的 softmax 概率,以及 CRF 的 tag 转移概率,两个损失得到的,因此模型的前向传播就可以在这两部分中进行了。
TENER
下面是 TENER (CRF 的一种最新实现,主要思想是去除 / √dk 归一化的 transformer + softmax + CRF)的代码整理,CRF 是个数据概率算法,所以无论任何模型都是固定的,优化的方向就是如何让文本的信息提取能力更强(transformer),如何让各个 tag 的区分度更大(去除归一化)
主代码:train_tener_cn.py
from models.TENER import TENER
from fastNLP import cache_results
from fastNLP import Trainer, GradientClipCallback, WarmupCallback
from torch import optim
from fastNLP import SpanFPreRecMetric, BucketSampler
from fastNLP.embeddings import StaticEmbedding
from fastNLP.io.model_io import ModelSaver, ModelLoader
from modules.pipe import CNNERPipe
import argparse
from modules.callbacks import EvaluateCallback
device = 0
parser = argparse.ArgumentParser()
# choices 里需要加上自己业务(模型)的定义名,如我这里是门票 ner 模型,加了一个 ticket
# 在当前代码目录执行:sudo python train_tener_cn.py --dataset ticket 开始训练
parser.add_argument('--dataset', type=str, default='resume', choices=['weibo', 'resume', 'ontonotes', 'msra', 'ticket'])
args = parser.parse_args()
# 前面四个 dataset 是一些开源数据,根据自己业务的数据量,修改定义自己网络的参数
dataset = args.dataset
if dataset == 'resume':
n_heads = 4
head_dims = 64
num_layers = 2
lr = 0.0007
attn_type = 'adatrans'
n_epochs = 50
elif dataset == 'weibo':
n_heads = 4
head_dims = 32
num_layers = 1
lr = 0.001
attn_type = 'adatrans'
n_epochs = 100
elif dataset == 'ontonotes':
n_heads = 4
head_dims = 48
num_layers = 2
lr = 0.0007
attn_type = 'adatrans'
n_epochs = 100
elif dataset == 'msra':
n_heads = 6
head_dims = 80
num_layers = 2
lr = 0.0007
attn_type = 'adatrans'
n_epochs = 100
elif dataset == 'ticket':
n_heads = 6
head_dims = 80
num_layers = 2
lr = 0.0007
attn_type = 'adatrans'
n_epochs = 100
# 一些通用的参数,可根据自己业务进行修改
pos_embed = None
batch_size = 16
warmup_steps = 0.01
after_norm = 1
model_type = 'transformer'
normalize_embed = True
dropout=0.15
fc_dropout=0.4
# 踩坑1:根据样本的标注形式,修改这里的 Encoding_type:['bmeso', 'bio', 'bioes'] 这三种,我用的是 BIO 也即是 begin、inside、other 三种类型
encoding_type = 'bio'
# 踩坑2:这里是 CNNERPipe 处理数据后,存放的数据文件,迭代训练前需要删除,否则会导致仍然使用上一版样本
name = 'caches/{}_{}_{}_{}.pkl'.format(dataset, model_type, encoding_type, normalize_embed)
d_model = n_heads * head_dims
dim_feedforward = int(2 * d_model)
@cache_results(name, _refresh=False)
def load_data():
# 替换路径
if dataset == 'ontonotes':
paths = {'train':'../data/OntoNote4NER/train.char.bmes',
"dev":'../data/OntoNote4NER/dev.char.bmes',
"test":'../data/OntoNote4NER/test.char.bmes'}
min_freq = 2
elif dataset == 'weibo':
paths = {'train': '../data/WeiboNER/train.all.bmes',
'dev':'../data/WeiboNER/dev.all.bmes',
'test':'../data/WeiboNER/test.all.bmes'}
min_freq = 1
elif dataset == 'resume':
paths = {'train': '../data/ResumeNER/train.char.bmes',
'dev':'../data/ResumeNER/dev.char.bmes',
'test':'../data/ResumeNER/test.char.bmes'}
min_freq = 1
elif dataset == 'msra':
paths = {'train': '../data/MSRANER/train_dev.char.bmes',
'dev':'../data/MSRANER/test.char.bmes',
'test':'../data/MSRANER/test.char.bmes'}
min_freq = 2
# 自定义自己业务数据的目录
elif dataset == 'ticket':
paths = {'train': '../data/train.all.bmes',
'dev': '../data/dev.all.bmes',
'test': '../data/test.all.bmes'}
# 如 word2vec 的思想,设置最小词频
min_freq = 2
# 数据处理,样本 train.all.bmes 等需要对空格进行删除,否则会导致“Invalid instance which ends at line: 56 has been dropped.”模型识别制表符分割错误
data_bundle = CNNERPipe(bigrams=True, encoding_type=encoding_type).process_from_file(paths)
# 踩坑3:在 train 的时候,带着 dropout,predict 的时候,需要把 dropout 删掉
# 字符级的预训练 embedding
embed = StaticEmbedding(data_bundle.get_vocab('chars'),
model_dir_or_name='../data/gigaword_chn.all.a2b.uni.ite50.vec',
min_freq=1, only_norm_found_vector=normalize_embed, word_dropout=0.01, dropout=0.3)
# bigram 级别(两个字符)的预训练 embedding
bi_embed = StaticEmbedding(data_bundle.get_vocab('bigrams'),
model_dir_or_name='../data/gigaword_chn.all.a2b.bi.ite50.vec',
word_dropout=0.02, dropout=0.3, min_freq=min_freq,
only_norm_found_vector=normalize_embed, only_train_min_freq=True)
return data_bundle, embed, bi_embed
data_bundle, embed, bi_embed = load_data()
# 这三个 vocabulary 需要存下来,线上使用的时候需要用到
# 存词库:字符 - index 的映射
data_bundle.get_vocab('chars').save('../model/chars_vocab_200.npy')
# 存词库:两个字符的词语 - index 的映射
data_bundle.get_vocab('bigrams').save('../model/bigrams_vocab_200.npy')
# 存 target:target(label:B-xx、I-xx、O、...) - index 的映射
data_bundle.get_vocab('target').save('../model/target_vocab_200.npy')
# 模型网络定义,需要传入 target、embed 模型、bi_embed 模型、网络参数等
model = TENER(tag_vocab=data_bundle.get_vocab('target'), embed=embed, num_layers=num_layers,
d_model=d_model, n_head=n_heads,
feedforward_dim=dim_feedforward, dropout=dropout,
after_norm=after_norm, attn_type=attn_type,
bi_embed=bi_embed,
fc_dropout=fc_dropout,
pos_embed=pos_embed,
scale=attn_type=='transformer')
# 定义优化器
optimizer = optim.SGD(model.parameters(), lr=lr, momentum=0.9)
# 定义 callback
callbacks = []
clip_callback = GradientClipCallback(clip_type='value', clip_value=5)
evaluate_callback = EvaluateCallback(data_bundle.get_dataset('test'))
if warmup_steps>0:
warmup_callback = WarmupCallback(warmup_steps, schedule='linear')
callbacks.append(warmup_callback)
callbacks.extend([clip_callback, evaluate_callback])
# 开始训练,使用的是 fastNLP 的框架,需要传入 data_bundle 训练/测试集,模型、训练参数等
trainer = Trainer(data_bundle.get_dataset('train'), model, optimizer, batch_size=batch_size, sampler=BucketSampler(),
num_workers=2, n_epochs=n_epochs, dev_data=data_bundle.get_dataset('dev'),
metrics=SpanFPreRecMetric(tag_vocab=data_bundle.get_vocab('target'), encoding_type=encoding_type),
dev_batch_size=batch_size, callbacks=callbacks, device=None, test_use_tqdm=False,
use_tqdm=True, print_every=300, save_path=None)
trainer.train(load_best_model=False)
# 模型保存
# 只保存参数
state_saver = ModelSaver("../model/ticket_ner_state_dict_200.pkl")
state_saver.save_pytorch(model, param_only=True)
# 保存整个模型
pkl_saver = ModelSaver("../model/ticket_ner_200.pkl")
pkl_saver.save_pytorch(model, param_only=False)
主模型网络:TENER.py
from fastNLP.modules import ConditionalRandomField, allowed_transitions
from modules.transformer import TransformerEncoder
from torch import nn
import torch
import torch.nn.functional as F
class TENER(nn.Module):
def __init__(self, tag_vocab, embed, num_layers, d_model, n_head, feedforward_dim, dropout,
after_norm=True, attn_type='adatrans', bi_embed=None,
fc_dropout=0.3, pos_embed=None, scale=False, dropout_attn=None):
"""
:param tag_vocab: fastNLP Vocabulary
:param embed: fastNLP TokenEmbedding
:param num_layers: number of self-attention layers
:param d_model: input size
:param n_head: number of head
:param feedforward_dim: the dimension of ffn
:param dropout: dropout in self-attention
:param after_norm: normalization place
:param attn_type: adatrans, naive
:param rel_pos_embed: position embedding的类型,支持sin, fix, None. relative时可为None
:param bi_embed: Used in Chinese scenerio
:param fc_dropout: dropout rate before the fc layer
"""
super().__init__()
# 字符预训练 embedding 模型
self.embed = embed
embed_size = self.embed.embed_size
# bigram 预训练 embedding 模型
self.bi_embed = None
if bi_embed is not None:
self.bi_embed = bi_embed
embed_size += self.bi_embed.embed_size
# 模型网络层
self.in_fc = nn.Linear(embed_size, d_model)
self.transformer = TransformerEncoder(num_layers, d_model, n_head, feedforward_dim, dropout,
after_norm=after_norm, attn_type=attn_type,
scale=scale, dropout_attn=dropout_attn,
pos_embed=pos_embed)
self.fc_dropout = nn.Dropout(fc_dropout)
self.out_fc = nn.Linear(d_model, len(tag_vocab))
trans = allowed_transitions(tag_vocab, include_start_end=True)
# crf 层
self.crf = ConditionalRandomField(len(tag_vocab), include_start_end_trans=True, allowed_transitions=trans)
def _forward(self, chars, target, bigrams=None):
# chars、target、bigrams 都是 Tensor,是映射后的 index
# print(chars)
# print(type(chars))
mask = chars.ne(0)
# 字符级别的 embedding
chars = self.embed(chars)
if self.bi_embed is not None:
# 词袋级别的 embedding,二者 concat,这个的作用是模拟LSTM,让模型学到字符之间的顺序(attention 是字符级的,学不到 bigram 顺序关系)
bigrams = self.bi_embed(bigrams)
chars = torch.cat([chars, bigrams], dim=-1)
# 网络结构,全连接 + transformer + dropout + 全连接 + softmax多分类
chars = self.in_fc(chars)
chars = self.transformer(chars, mask)
chars = self.fc_dropout(chars)
# 最后 softmax 的时候是 target 的种类数(B-xx、I-xx、O...)
chars = self.out_fc(chars)
logits = F.log_softmax(chars, dim=-1)
# 发射分数(标签向量)(每个字符有一个 softmax 向量,所以是 len(chars) * len(tag_vocab) 维)导入 CRF 解码最优路径
if target is None:
# 预测的时候
paths, _ = self.crf.viterbi_decode(logits, mask)
return {'pred': paths}
else:
# 训练的时候
loss = self.crf(logits, target, mask)
return {'loss': loss}
# 训练
def forward(self, chars, target, bigrams=None):
return self._forward(chars, target, bigrams)
# 线上预测时使用的函数,target 为 None
def predict(self, chars, bigrams=None):
return self._forward(chars, target=None, bigrams=bigrams)
数据预处理:pipe.py
from fastNLP.io import Pipe, ConllLoader
from fastNLP.io import DataBundle
from fastNLP.io.pipe.utils import _add_words_field, _indexize
from fastNLP.io.pipe.utils import iob2, iob2bioes
from fastNLP.io.pipe.utils import _add_chars_field
from fastNLP.io.utils import check_loader_paths
from fastNLP.io import Conll2003NERLoader
from fastNLP import Const
def bmeso2bio(tags):
new_tags = []
for tag in tags:
tag = tag.lower()
if tag.startswith('m') or tag.startswith('e'):
tag = 'i' + tag[1:]
if tag.startswith('s'):
tag = 'b' + tag[1:]
new_tags.append(tag)
return new_tags
def bmeso2bioes(tags):
new_tags = []
for tag in tags:
lowered_tag = tag.lower()
if lowered_tag.startswith('m'):
tag = 'i' + tag[1:]
new_tags.append(tag)
return new_tags
class CNNERPipe(Pipe):
def __init__(self, bigrams=False, encoding_type='bmeso'):
super().__init__()
self.bigrams = bigrams
if encoding_type=='bmeso':
self.encoding_func = lambda x:x
elif encoding_type=='bio':
self.encoding_func = bmeso2bio
elif encoding_type == 'bioes':
self.encoding_func = bmeso2bioes
else:
raise RuntimeError("Only support bio, bmeso, bioes")
def process(self, data_bundle: DataBundle):
_add_chars_field(data_bundle, lower=False)
# 这里用的是 bmeso2bio 方法,所以只是把 target(bio label)都 lower 了一下,作为 target
data_bundle.apply_field(self.encoding_func, field_name=Const.TARGET, new_field_name=Const.TARGET)
# 将所有 digit(数字) 转为 '0',其余不变,作为 input
data_bundle.apply_field(lambda chars:[''.join(['0' if c.isdigit() else c for c in char]) for char in chars],
field_name=Const.CHAR_INPUT, new_field_name=Const.CHAR_INPUT)
input_field_names = [Const.CHAR_INPUT]
# bigrams 所以 c1 + c2 每两个字符构成一个词语
if self.bigrams:
data_bundle.apply_field(lambda chars:[c1+c2 for c1,c2 in zip(chars, chars[1:]+['<eos>'])],
field_name=Const.CHAR_INPUT, new_field_name='bigrams')
input_field_names.append('bigrams')
# index
_indexize(data_bundle, input_field_names=input_field_names, target_field_names=Const.TARGET)
# data 有四列:target、seq_len、chars、bigrams
input_fields = [Const.TARGET, Const.INPUT_LEN] + input_field_names
target_fields = [Const.TARGET, Const.INPUT_LEN]
for name, dataset in data_bundle.datasets.items():
dataset.add_seq_len(Const.CHAR_INPUT)
data_bundle.set_input(*input_fields)
data_bundle.set_target(*target_fields)
return data_bundle
def process_from_file(self, paths):
paths = check_loader_paths(paths)
# 构造 dataset,默认分隔符是:制表符/空格, raw_chars 是中文字符,target是每个bio(B-xx、I-xx、O)label
loader = ConllLoader(headers=['raw_chars', 'target'])
data_bundle = loader.load(paths)
return self.process(data_bundle)
训练
sudo python train_tener_cn.py --dataset ticket
线上使用(& 离线预测)
from __future__ import division
from copy import deepcopy
import math
import torch
import torch.nn.functional as F
from fastNLP.core import Vocabulary
from fastNLP.embeddings import StaticEmbedding
from fastNLP.modules import ConditionalRandomField, allowed_transitions
from torch import nn
class RelativeEmbedding(nn.Module):
def forward(self, input):
"""Input is expected to be of size [bsz x seqlen].
"""
bsz, seq_len = input.size()
max_pos = self.padding_idx + seq_len
if max_pos > self.origin_shift:
# recompute/expand embeddings if needed
weights = self.get_embedding(
max_pos * 2,
self.embedding_dim,
self.padding_idx,
)
weights = weights.to(self._float_tensor)
del self.weights
self.origin_shift = weights.size(0) // 2
self.register_buffer('weights', weights)
positions = torch.arange(-seq_len, seq_len).to(input.device).long() + self.origin_shift # 2*seq_len
embed = self.weights.index_select(0, positions.long()).detach()
return embed
class RelativeSinusoidalPositionalEmbedding(RelativeEmbedding):
"""This module produces sinusoidal positional embeddings of any length.
Padding symbols are ignored.
"""
def __init__(self, embedding_dim, padding_idx, init_size=1568):
"""
:param embedding_dim: 每个位置的dimension
:param padding_idx:
:param init_size:
"""
super().__init__()
self.embedding_dim = embedding_dim
self.padding_idx = padding_idx
assert init_size % 2 == 0
weights = self.get_embedding(
init_size + 1,
embedding_dim,
padding_idx,
)
self.register_buffer('weights', weights)
self.register_buffer('_float_tensor', torch.FloatTensor(1))
def get_embedding(self, num_embeddings, embedding_dim, padding_idx=None):
"""Build sinusoidal embeddings.
This matches the implementation in tensor2tensor, but differs slightly
from the description in Section 3.5 of "Attention Is All You Need".
"""
half_dim = embedding_dim // 2
emb = math.log(10000) / (half_dim - 1)
emb = torch.exp(torch.arange(half_dim, dtype=torch.float) * -emb)
emb = torch.arange(-num_embeddings // 2, num_embeddings // 2, dtype=torch.float).unsqueeze(1) * emb.unsqueeze(0)
emb = torch.cat([torch.sin(emb), torch.cos(emb)], dim=1).view(num_embeddings, -1)
if embedding_dim % 2 == 1:
# zero pad
emb = torch.cat([emb, torch.zeros(num_embeddings, 1)], dim=1)
if padding_idx is not None:
emb[padding_idx, :] = 0
self.origin_shift = num_embeddings // 2 + 1
return emb
class RelativeMultiHeadAttn(nn.Module):
def __init__(self, d_model, n_head, dropout, r_w_bias=None, r_r_bias=None, scale=False):
"""
:param int d_model:
:param int n_head:
:param dropout: 对attention map的dropout
:param r_w_bias: n_head x head_dim or None, 如果为dim
:param r_r_bias: n_head x head_dim or None,
:param scale:
:param rel_pos_embed:
"""
super().__init__()
self.qkv_linear = nn.Linear(d_model, d_model * 3, bias=False)
self.n_head = n_head
self.head_dim = d_model // n_head
self.dropout_layer = nn.Dropout(dropout)
self.pos_embed = RelativeSinusoidalPositionalEmbedding(d_model // n_head, 0, 1200)
if scale:
self.scale = math.sqrt(d_model // n_head)
else:
self.scale = 1
if r_r_bias is None or r_w_bias is None: # Biases are not shared
self.r_r_bias = nn.Parameter(nn.init.xavier_normal_(torch.zeros(n_head, d_model // n_head)))
self.r_w_bias = nn.Parameter(nn.init.xavier_normal_(torch.zeros(n_head, d_model // n_head)))
else:
self.r_r_bias = r_r_bias # r_r_bias就是v
self.r_w_bias = r_w_bias # r_w_bias就是u
def forward(self, x, mask):
"""
:param x: batch_size x max_len x d_model
:param mask: batch_size x max_len
:return:
"""
batch_size, max_len, d_model = x.size()
pos_embed = self.pos_embed(mask) # l x head_dim
qkv = self.qkv_linear(x) # batch_size x max_len x d_model3
q, k, v = torch.chunk(qkv, chunks=3, dim=-1)
q = q.view(batch_size, max_len, self.n_head, -1).transpose(1, 2)
k = k.view(batch_size, max_len, self.n_head, -1).transpose(1, 2)
v = v.view(batch_size, max_len, self.n_head, -1).transpose(1, 2) # b x n x l x d
rw_head_q = q + self.r_r_bias[:, None]
AC = torch.einsum('bnqd,bnkd->bnqk', [rw_head_q, k]) # b x n x l x d, n是head
D_ = torch.einsum('nd,ld->nl', self.r_w_bias, pos_embed)[None, :, None] # head x 2max_len, 每个head对位置的bias
B_ = torch.einsum('bnqd,ld->bnql', q, pos_embed) # bsz x head x max_len x 2max_len,每个query对每个shift的偏移
E_ = torch.einsum('bnqd,ld->bnql', k, pos_embed) # bsz x head x max_len x 2max_len, key对relative的bias
BD = B_ + D_ # bsz x head x max_len x 2max_len, 要转换为bsz x head x max_len x max_len
BDE = self._shift(BD) + self._transpose_shift(E_)
attn = AC + BDE
attn = attn / self.scale
attn = attn.masked_fill(mask[:, None, None, :].eq(0), float('-inf'))
attn = F.softmax(attn, dim=-1)
attn = self.dropout_layer(attn)
v = torch.matmul(attn, v).transpose(1, 2).reshape(batch_size, max_len, d_model) # b x n x l x d
return v
def _shift(self, BD):
"""
类似
-3 -2 -1 0 1 2
-3 -2 -1 0 1 2
-3 -2 -1 0 1 2
转换为
0 1 2
-1 0 1
-2 -1 0
:param BD: batch_size x n_head x max_len x 2max_len
:return: batch_size x n_head x max_len x max_len
"""
bsz, n_head, max_len, _ = BD.size()
zero_pad = BD.new_zeros(bsz, n_head, max_len, 1)
BD = torch.cat([BD, zero_pad], dim=-1).view(bsz, n_head, -1, max_len) # bsz x n_head x (2max_len+1) x max_len
BD = BD[:, :, :-1].view(bsz, n_head, max_len, -1) # bsz x n_head x 2max_len x max_len
BD = BD[:, :, :, max_len:]
return BD
def _transpose_shift(self, E):
"""
类似
-3 -2 -1 0 1 2
-30 -20 -10 00 10 20
-300 -200 -100 000 100 200
转换为
0 -10 -200
1 00 -100
2 10 000
:param E: batch_size x n_head x max_len x 2max_len
:return: batch_size x n_head x max_len x max_len
"""
bsz, n_head, max_len, _ = E.size()
zero_pad = E.new_zeros(bsz, n_head, max_len, 1)
# bsz x n_head x -1 x (max_len+1)
E = torch.cat([E, zero_pad], dim=-1).view(bsz, n_head, -1, max_len)
indice = (torch.arange(max_len) * 2 + 1).to(E.device)
E = E.index_select(index=indice, dim=-2).transpose(-1, -2) # bsz x n_head x max_len x max_len
return E
class MultiHeadAttn(nn.Module):
def __init__(self, d_model, n_head, dropout=0.1, scale=False):
"""
:param d_model:
:param n_head:
:param scale: 是否scale输出
"""
super().__init__()
assert d_model % n_head == 0
self.n_head = n_head
self.qkv_linear = nn.Linear(d_model, 3 * d_model, bias=False)
self.fc = nn.Linear(d_model, d_model)
self.dropout_layer = nn.Dropout(dropout)
if scale:
self.scale = math.sqrt(d_model // n_head)
else:
self.scale = 1
def forward(self, x, mask):
"""
:param x: bsz x max_len x d_model
:param mask: bsz x max_len
:return:
"""
batch_size, max_len, d_model = x.size()
x = self.qkv_linear(x)
q, k, v = torch.chunk(x, 3, dim=-1)
q = q.view(batch_size, max_len, self.n_head, -1).transpose(1, 2)
k = k.view(batch_size, max_len, self.n_head, -1).permute(0, 2, 3, 1)
v = v.view(batch_size, max_len, self.n_head, -1).transpose(1, 2)
attn = torch.matmul(q, k) # batch_size x n_head x max_len x max_len
attn = attn / self.scale
attn.masked_fill_(mask=mask[:, None, None].eq(0), value=float('-inf'))
attn = F.softmax(attn, dim=-1) # batch_size x n_head x max_len x max_len
attn = self.dropout_layer(attn)
v = torch.matmul(attn, v) # batch_size x n_head x max_len x d_model//n_head
v = v.transpose(1, 2).reshape(batch_size, max_len, -1)
v = self.fc(v)
return v
class TransformerLayer(nn.Module):
def __init__(self, d_model, self_attn, feedforward_dim, after_norm, dropout):
"""
:param int d_model: 一般512之类的
:param self_attn: self attention模块,输入为x:batch_size x max_len x d_model, mask:batch_size x max_len, 输出为
batch_size x max_len x d_model
:param int feedforward_dim: FFN中间层的dimension的大小
:param bool after_norm: norm的位置不一样,如果为False,则embedding可以直接连到输出
:param float dropout: 一共三个位置的dropout的大小
"""
super().__init__()
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.self_attn = self_attn
self.after_norm = after_norm
self.ffn = nn.Sequential(nn.Linear(d_model, feedforward_dim),
nn.ReLU(),
nn.Dropout(dropout),
nn.Linear(feedforward_dim, d_model),
nn.Dropout(dropout))
def forward(self, x, mask):
"""
:param x: batch_size x max_len x hidden_size
:param mask: batch_size x max_len, 为0的地方为pad
:return: batch_size x max_len x hidden_size
"""
residual = x
if not self.after_norm:
x = self.norm1(x)
x = self.self_attn(x, mask)
x = x + residual
if self.after_norm:
x = self.norm1(x)
residual = x
if not self.after_norm:
x = self.norm2(x)
x = self.ffn(x)
x = residual + x
if self.after_norm:
x = self.norm2(x)
return x
class TransformerEncoder(nn.Module):
def __init__(self, num_layers, d_model, n_head, feedforward_dim, dropout, after_norm=True, attn_type='naive',
scale=False, dropout_attn=None, pos_embed=None):
super().__init__()
if dropout_attn is None:
dropout_attn = dropout
self.d_model = d_model
if pos_embed is None:
self.pos_embed = None
elif pos_embed == 'sin':
self.pos_embed = SinusoidalPositionalEmbedding(d_model, 0, init_size=1024)
elif pos_embed == 'fix':
self.pos_embed = LearnedPositionalEmbedding(1024, d_model, 0)
if attn_type == 'transformer':
self_attn = MultiHeadAttn(d_model, n_head, dropout_attn, scale=scale)
elif attn_type == 'adatrans':
self_attn = RelativeMultiHeadAttn(d_model, n_head, dropout_attn, scale=scale)
self.layers = nn.ModuleList([TransformerLayer(d_model, deepcopy(self_attn), feedforward_dim, after_norm, dropout)
for _ in range(num_layers)])
def forward(self, x, mask):
"""
:param x: batch_size x max_len
:param mask: batch_size x max_len. 有value的地方为1
:return:
"""
if self.pos_embed is not None:
x = x + self.pos_embed(mask)
for layer in self.layers:
x = layer(x, mask)
return x
def make_positions(tensor, padding_idx):
"""Replace non-padding symbols with their position numbers.
Position numbers begin at padding_idx+1. Padding symbols are ignored.
"""
# The series of casts and type-conversions here are carefully
# balanced to both work with ONNX export and XLA. In particular XLA
# prefers ints, cumsum defaults to output longs, and ONNX doesn't know
# how to handle the dtype kwarg in cumsum.
mask = tensor.ne(padding_idx).int()
return (
torch.cumsum(mask, dim=1).type_as(mask) * mask
).long() + padding_idx
class SinusoidalPositionalEmbedding(nn.Module):
"""This module produces sinusoidal positional embeddings of any length.
Padding symbols are ignored.
"""
def __init__(self, embedding_dim, padding_idx, init_size=1568):
super().__init__()
self.embedding_dim = embedding_dim
self.padding_idx = padding_idx
self.weights = SinusoidalPositionalEmbedding.get_embedding(
init_size,
embedding_dim,
padding_idx,
)
self.register_buffer('_float_tensor', torch.FloatTensor(1))
@staticmethod
def get_embedding(num_embeddings, embedding_dim, padding_idx=None):
"""Build sinusoidal embeddings.
This matches the implementation in tensor2tensor, but differs slightly
from the description in Section 3.5 of "Attention Is All You Need".
"""
half_dim = embedding_dim // 2
emb = math.log(10000) / (half_dim - 1)
emb = torch.exp(torch.arange(half_dim, dtype=torch.float) * -emb)
emb = torch.arange(num_embeddings, dtype=torch.float).unsqueeze(1) * emb.unsqueeze(0)
emb = torch.cat([torch.sin(emb), torch.cos(emb)], dim=1).view(num_embeddings, -1)
if embedding_dim % 2 == 1:
# zero pad
emb = torch.cat([emb, torch.zeros(num_embeddings, 1)], dim=1)
if padding_idx is not None:
emb[padding_idx, :] = 0
return emb
def forward(self, input):
"""Input is expected to be of size [bsz x seqlen]."""
bsz, seq_len = input.size()
max_pos = self.padding_idx + 1 + seq_len
if max_pos > self.weights.size(0):
# recompute/expand embeddings if needed
self.weights = SinusoidalPositionalEmbedding.get_embedding(
max_pos,
self.embedding_dim,
self.padding_idx,
)
self.weights = self.weights.to(self._float_tensor)
positions = make_positions(input, self.padding_idx)
return self.weights.index_select(0, positions.view(-1)).view(bsz, seq_len, -1).detach()
def max_positions(self):
"""Maximum number of supported positions."""
return int(1e5) # an arbitrary large number
class LearnedPositionalEmbedding(nn.Embedding):
"""
This module learns positional embeddings up to a fixed maximum size.
Padding ids are ignored by either offsetting based on padding_idx
or by setting padding_idx to None and ensuring that the appropriate
position ids are passed to the forward function.
"""
def __init__(
self,
num_embeddings: int,
embedding_dim: int,
padding_idx: int,
):
super().__init__(num_embeddings, embedding_dim, padding_idx)
def forward(self, input):
# positions: batch_size x max_len, 把words的index输入就好了
positions = make_positions(input, self.padding_idx)
return super().forward(positions)
# In[13]:
class TENER(nn.Module):
def __init__(self, tag_vocab, embed, num_layers, d_model, n_head, feedforward_dim, dropout,
after_norm=True, attn_type='adatrans', bi_embed=None,
fc_dropout=0.3, pos_embed=None, scale=False, dropout_attn=None):
"""
:param tag_vocab: fastNLP Vocabulary
:param embed: fastNLP TokenEmbedding
:param num_layers: number of self-attention layers
:param d_model: input size
:param n_head: number of head
:param feedforward_dim: the dimension of ffn
:param dropout: dropout in self-attention
:param after_norm: normalization place
:param attn_type: adatrans, naive
:param rel_pos_embed: position embedding的类型,支持sin, fix, None. relative时可为None
:param bi_embed: Used in Chinese scenerio
:param fc_dropout: dropout rate before the fc layer
"""
super().__init__()
self.embed = embed
embed_size = self.embed.embed_size
self.bi_embed = None
if bi_embed is not None:
self.bi_embed = bi_embed
embed_size += self.bi_embed.embed_size
self.in_fc = nn.Linear(embed_size, d_model)
self.transformer = TransformerEncoder(num_layers, d_model, n_head, feedforward_dim, dropout,
after_norm=after_norm, attn_type=attn_type,
scale=scale, dropout_attn=dropout_attn,
pos_embed=pos_embed)
self.fc_dropout = nn.Dropout(fc_dropout)
self.out_fc = nn.Linear(d_model, len(tag_vocab))
trans = allowed_transitions(tag_vocab, include_start_end=True)
self.crf = ConditionalRandomField(len(tag_vocab), include_start_end_trans=True, allowed_transitions=trans)
def _forward(self, chars, target, bigrams=None):
mask = chars.ne(0)
# 字符级别的 embedding
chars = self.embed(chars)
if self.bi_embed is not None:
# 词袋级别的 embedding,二者 concat
bigrams = self.bi_embed(bigrams)
chars = torch.cat([chars, bigrams], dim=-1)
# 网络结构,全连接 + transformer + dropout + 全连接 + softmax多分类
chars = self.in_fc(chars)
chars = self.transformer(chars, mask)
chars = self.fc_dropout(chars)
# 最后 softmax 的时候是 target 的种类数(B-xx、I-xx、O...)
chars = self.out_fc(chars)
logits = F.log_softmax(chars, dim=-1)
# 发射分数(标签向量)(每个字符有一个 softmax 向量,所以是 len(chars) * len(tag_vocab) 维)导入 CRF 解码最优路径
if target is None:
paths, _ = self.crf.viterbi_decode(logits, mask)
return {'pred': paths}
else:
loss = self.crf(logits, target, mask)
return {'loss': loss}
def forward(self, chars, target, bigrams=None):
return self._forward(chars, target, bigrams)
def predict(self, chars, bigrams=None):
return self._forward(chars, target=None, bigrams=bigrams)
# In[9]:
min_freq = 2
n_heads = 6
head_dims = 80
num_layers = 2
lr = 0.0007
attn_type = 'adatrans'
n_epochs = 100
pos_embed = None
batch_size = 16
warmup_steps = 0.01
after_norm = 1
model_type = 'transformer'
normalize_embed = True
dropout = 0.15
fc_dropout = 0.4
encoding_type = 'bio'
d_model = n_heads * head_dims
dim_feedforward = int(2 * d_model)
# In[26]:
# 单字符的 embedding
chars_vocab = Vocabulary().load('./model/chars_vocab.npy')
chars_vocab_dict = dict(chars_vocab)
embed = StaticEmbedding(chars_vocab,
model_dir_or_name='./data/gigaword_chn.all.a2b.uni.ite50.vec',
min_freq=1, only_norm_found_vector=normalize_embed, word_dropout=0.01, dropout=0.3)
# word 的 embedding
bigrams_vocab = Vocabulary().load('./model/bigrams_vocab.npy')
bigrams_vocab_dict = dict(bigrams_vocab)
bi_embed = StaticEmbedding(bigrams_vocab,
model_dir_or_name='./data/gigaword_chn.all.a2b.bi.ite50.vec',
word_dropout=0.02, dropout=0.3, min_freq=min_freq,
only_norm_found_vector=normalize_embed, only_train_min_freq=True)
# 训练集中没有的字符,使用 <unk> 对应的 index 填充
chars_unk_index = chars_vocab_dict['<unk>']
bigrams_unk_index = bigrams_vocab_dict['<unk>']
# label
target_vocab = Vocabulary().load('./model/target_vocab.npy')
target_vocab_dict = dict(target_vocab)
target_vocab_dict_reverse = dict({v: k for k, v in target_vocab_dict.items()})
model = TENER(tag_vocab=target_vocab, embed=embed, num_layers=num_layers,
d_model=d_model, n_head=n_heads,
feedforward_dim=dim_feedforward, dropout=dropout,
after_norm=after_norm, attn_type=attn_type,
bi_embed=bi_embed,
fc_dropout=fc_dropout,
pos_embed=pos_embed,
scale=attn_type == 'transformer')
# 模型类必须在此之前被定义
model.load_state_dict(torch.load('./model/ticket_ner_100.pkl'))
# 待预测的单条样本
chars = ['x', 'x', 'x', 'x'] # ...
# 按照 CNNERPipe 的方法进行预处理,需要传入 chars 和 bigram
input_chars = [''.join(['0' if c.isdigit() else c for c in char]) for char in chars]
input_bigrams = [c1 + c2 for c1, c2 in zip(chars, chars[1:] + ['<eos>'])]
# 使用映射字典,转成 Tensor
tensor_input_chars = torch.Tensor([[chars_vocab_dict[i] if i in chars_vocab_dict else chars_unk_index for i in input_chars]]).long()
tensor_input_bigrams = torch.Tensor([[bigrams_vocab_dict[i] if i in bigrams_vocab_dict else bigrams_unk_index for i in input_bigrams]]).long()
# 预测,得到结果
preds = [target_vocab_dict_reverse[i] for i in model.predict(tensor_input_chars, tensor_input_bigrams)['pred'][0].tolist()]
# ['b-poi', 'i-poi', 'i-poi', 'i-poi', 'i-poi', 'i-poi', 'i-poi', 'i-poi', 'i-poi', 'o', 'b-project', 'i-project', 'b-people_number', 'i-people_number', 'b-project', 'i-project', 'o', 'o', 'b-people', 'i-people', 'i-people']
模型成功加载:

预测结果:


CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 5
5 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)