机器学习入门之莺尾花训练
机器学习1.sklearn1.1 莺尾花数据集from sklearn import datasets# 引入数据集,sklearn包含众多数据集from sklearn.model_selection import train_test_split# 将数据分为测试集和训练集from sklearn.neighbors import KNeighborsClassifier# 利用邻近点方式训练
·
机器学习
1.sklearn
1.1 莺尾花数据集
致谢
探索sklearn | 鸢尾花数据集 -薛定谔的小猫咪-2019-博客园
sklearn iris(鸢尾花)数据集应用 -狼之鸿-2018-博客园
笔记篇二:鸢尾花数据集分类 -一罐趣多多-2022-博客园
原始数据画图
from sklearn import datasets # 引入数据集,sklearn包含众多数据集
from sklearn.model_selection import train_test_split # 将数据分为测试集和训练集
from sklearn.neighbors import KNeighborsClassifier # 利用邻近点方式训练数据
import matplotlib.pyplot as plt
def datasets_demo():
###引入数据###
iris = datasets.load_iris() # 引入iris鸢尾花数据,iris数据包含4个特征变量
iris_X = iris.data # 特征变量
iris_y = iris.target # 目标值
# 利用train_test_split进行将训练集和测试集进行分开,test_size占30%
X_train, X_test, y_train, y_test = train_test_split(iris_X, iris_y, test_size=0.25)
# print(y_train) # 我们看到训练数据的特征值分为3类
###训练数据###
# knn = KNeighborsClassifier() # 引入训练方法
# knn.fit(X_train, y_train) # 进行填充测试数据进行训练
###预测数据###
# print(knn.predict(X_test)) # 预测特征值
# print(y_test) # 真实特征值
return iris
def plot_iris_projection(data, feature_names, target, x_index, y_index):
for t, marker, c in zip([0, 1, 2], '>ox', 'rgb'):
plt.scatter(data[target == t, x_index], data[target == t, y_index], marker=marker, c=c)
plt.xlabel(feature_names[x_index])
plt.ylabel(feature_names[y_index])
pass
def main1():
data_ = datasets_demo()
data = data_['data'] # 为numpy.ndarray类型
feature_names = data_['feature_names']
target = data_['target']
seq = [(0, 1), (0, 2), (0, 3), (1, 2), (1, 3), (2, 3)]
for i, (x_index, y_index) in enumerate(seq):
plt.subplot(2, 3, i+1)
plot_iris_projection(data, feature_names, target, x_index, y_index)
pass
plt.show()
pass
main1()
训练测试
import numpy as np
from sklearn import datasets # 引入数据集,sklearn包含众多数据集
from sklearn.model_selection import train_test_split # 将数据分为测试集和训练集
from sklearn.linear_model import LogisticRegression
import matplotlib.pyplot as plt
def load_data():
# 共150条数据,训练120条,测试30条,进行2,8分进行模型训练
# 每条数据类型为 x{nbarray} [6.4, 3.1, 5.5, 1.8]
inputdata = datasets.load_iris()
# 切分,测试训练2,8分
x_train, x_test, y_train, y_test = \
train_test_split(inputdata.data, inputdata.target, test_size=0.2, random_state=1)
return x_train, x_test, y_train, y_test
def main():
# 训练集x ,测试集x,训练集label,测试集label
x_train, x_test, y_train, y_test = load_data()
# l2为正则项
model = LogisticRegression(penalty='l2', max_iter=10000) # 引入训练方法
model.fit(x_train, y_train) # 进行填充测试数据进行训练
print("w: ", model.coef_) # “斜率”参数(w,也叫作权重或系数)被保存在 coef_ 属性中
print("b: ", model.intercept_) # 偏移或截距(b)被保存在 intercept_ 属性中
# 准确率
print("precision: ", model.score(x_test, y_test)) # 1-残差平方和/总误差平方和 (若残差大,则数据预测不准)
print("MSE: ", np.mean((model.predict(x_test) - y_test) ** 2)) # 均方误差(Mean squared error)
pass
main()
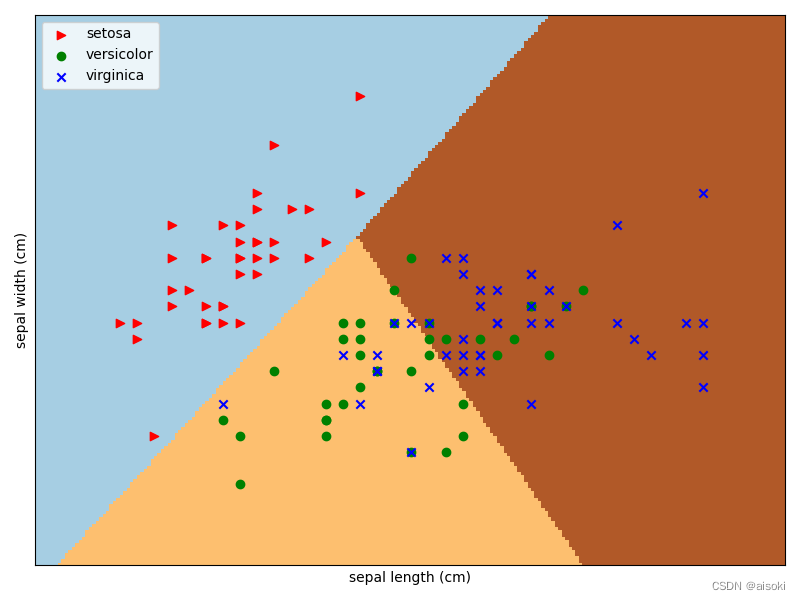
画出预测分类结果
因为难以画出4个特征分割的图,因此这里截取2个特征进行训练,画出的分类图也就容易展现了。
def test_plot():
# 载入数据集
iris = datasets.load_iris()
x_train, x_test, y_train, y_test = train_test_split(iris.data[:, :2], iris.target, test_size=0.2, random_state=1)
X = x_train # 获取花卉两列数据集
Y = y_train
# 逻辑回归模型
lr = LogisticRegression(C=1e5) # c=1e5是目标函数
lr.fit(X, Y)
# meshgrid函数生成两个网格矩阵
h = .02
# 初始化逻辑回归模型并进行训练
x_min, x_max = X[:, 0].min() - .5, X[:, 0].max() + .5
y_min, y_max = X[:, 1].min() - .5, X[:, 1].max() + .5
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
# pcolormesh函数将xx,yy两个网格矩阵和对应的预测结果Z绘制在图片上
Z = lr.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.figure(1, figsize=(8, 6))
plt.pcolormesh(xx, yy, Z, cmap=plt.cm.Paired)
plot_iris_projection(X, iris['feature_names'], Y, 0, 1)
plt.legend(iris['target_names'], loc=2)
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
plt.xticks(())
plt.yticks(())
plt.show()
print("precision: ", lr.score(x_test, y_test)) # 1-残差平方和/总误差平方和 (若残差大,则数据预测不准)
print("MSE: ", np.mean((lr.predict(x_test) - y_test) ** 2)) # 均方误差(Mean squared error)
pass
test_plot()
结果如图:

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)