机器人学习算法基础:决策树、随机森林
文章目录决策树信息的度量与作用信息熵信息增益信息增益计算常见决策树使用的算法sklearn决策树API泰坦尼克号生存预测案例决策树决策树思想的来源非常朴素,程序设计中的条件分支结构就是if-then结构,最早的决策树就是利用这类结构分割数据的一种分类学习方法信息的度量与作用每猜一次给一块钱,告诉我是否猜对了,那么我需要掏多少钱才能知道谁是冠军?我可以把球编上号,从1到32,然后提问:冠 军在1-1
文章目录
决策树
决策树思想的来源非常朴素,程序设计中的条件分支结构就是if-then结构,最早的决策树就是利用这类结构分割数据的一种分类学习方法
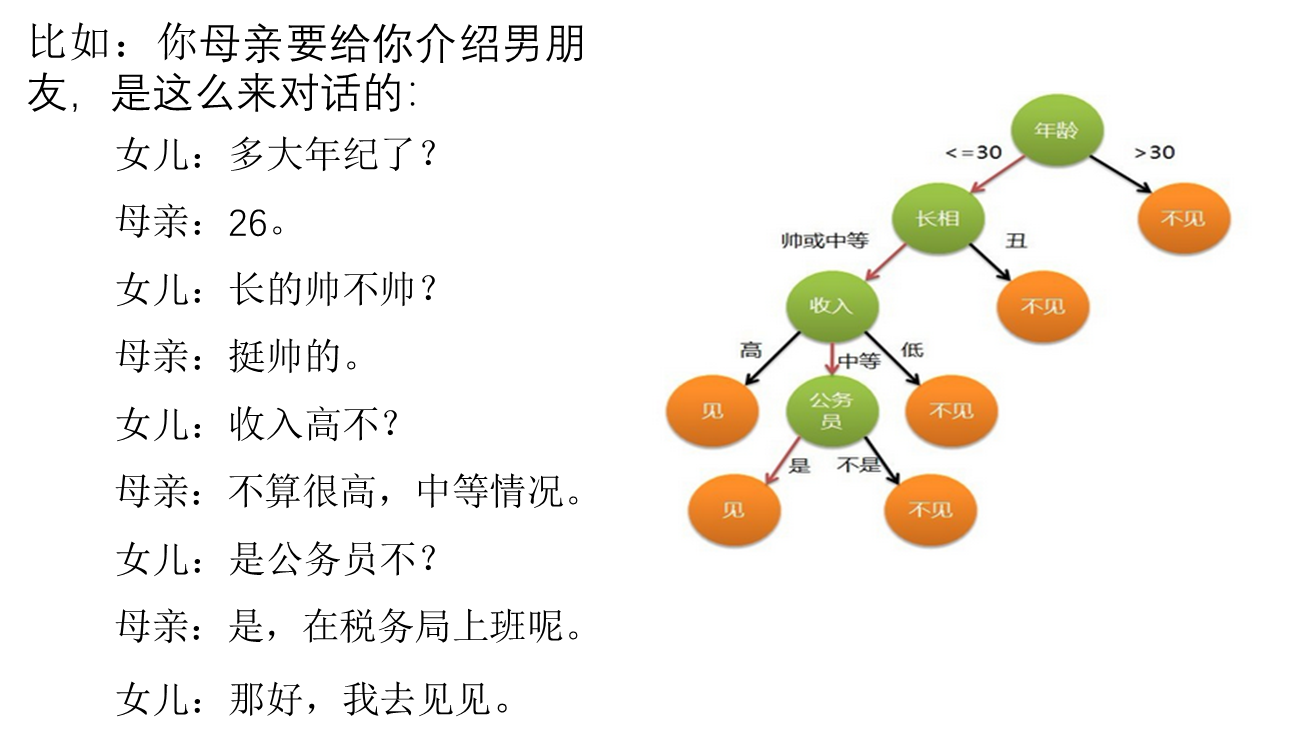
信息的度量与作用

每猜一次给一块钱,告诉我是否猜对了,那么我需要掏多少钱才能知道谁是冠军?我可以把球编上号,从1到32,然后提问:冠 军在1-16号吗?依次询问,只需要五次,就可以知道结果。
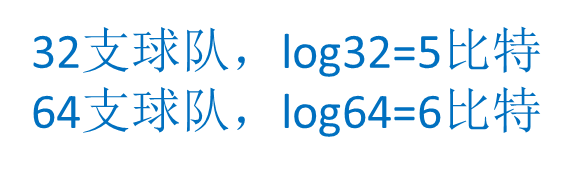

信息熵

信息和消除不确定性是相联系的
信息增益
得知特征X的信息而使得类Y的信息的不确定性减少的程度
特征A对训练数据集D的信息增益g(D,A),定义为集合D的**信息熵H(D)与特征A给定条件下D的信息条件熵H(D|A)**之差,即公式为:

信息增益计算
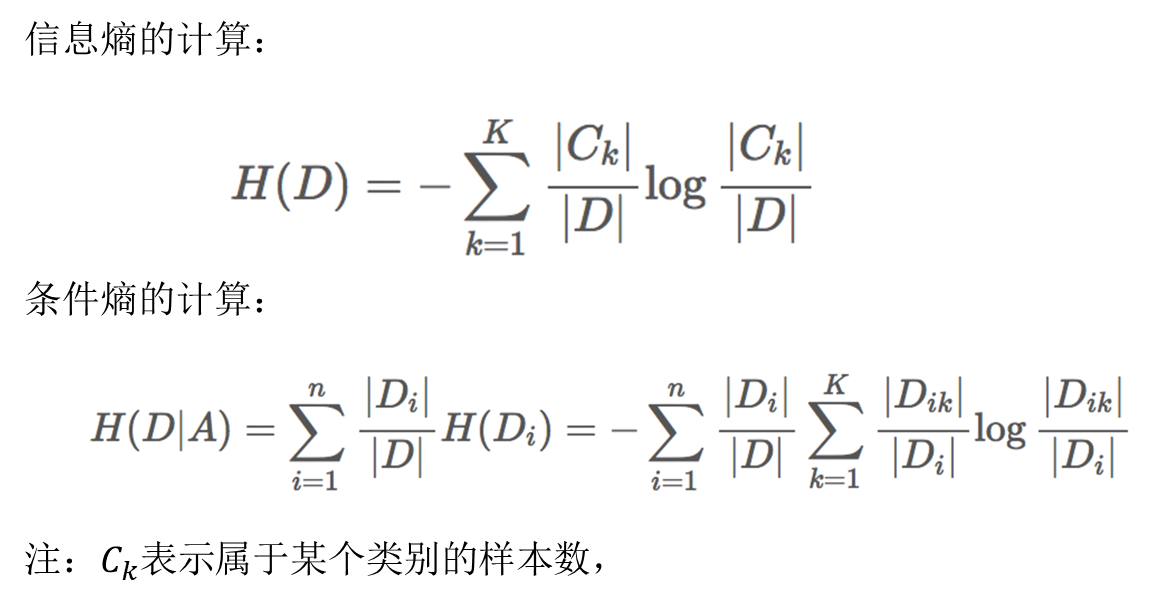

常见决策树使用的算法
ID3
信息增益 最大的准则
C4.5
信息增益比 最大的准则
CART
回归树: 平方误差 最小
分类树: 基尼系数 最小的准则 在sklearn中可以选择划分的原则
sklearn决策树API

泰坦尼克号生存预测案例
泰坦尼克号数据
在泰坦尼克号和titanic2数据帧描述泰坦尼克号上的个别乘客的生存状态。在泰坦尼克号的数据帧不包含从剧组信息,但它确实包含了乘客的一半的实际年龄。关于泰坦尼克号旅客的数据的主要来源是百科全书Titanica。这里使用的数据集是由各种研究人员开始的。其中包括许多研究人员创建的旅客名单,由Michael A. Findlay编辑。
我们提取的数据集中的特征是票的类别,存活,乘坐班,年龄,登陆,home.dest,房间,票,船和性别。乘坐班是指乘客班(1,2,3),是社会经济阶层的代表。
其中age数据存在缺失。

分类模型

决策树的结构、本地保存

决策树的优缺点以及改进
优点:
简单的理解和解释,树木可视化。
需要很少的数据准备,其他技术通常需要数据归一化,
缺点:
决策树学习者可以创建不能很好地推广数据的过于复杂的树,
这被称为过拟合。
决策树可能不稳定,因为数据的小变化可能会导致完全不同的树
被生成
改进:
减枝cart算法
随机森林
from sklearn.datasets import load_iris, fetch_20newsgroups, load_boston
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import StandardScaler
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import classification_report
from sklearn.feature_extraction import DictVectorizer
from sklearn.tree import DecisionTreeClassifier, export_graphviz
from sklearn.ensemble import RandomForestClassifier
import pandas as pd
def decision():
"""
决策树对泰坦尼克号进行预测生死
:return: None
"""
# 获取数据
titan = pd.read_csv("http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic.txt")
# 处理数据,找出特征值和目标值
x = titan[['pclass', 'age', 'sex']]
y = titan['survived']
print(x)
# 缺失值处理
x['age'].fillna(x['age'].mean(), inplace=True)
# 分割数据集到训练集合测试集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.25)
# 进行处理(特征工程)特征-》类别-》one_hot编码
dict = DictVectorizer(sparse=False)
x_train = dict.fit_transform(x_train.to_dict(orient="records"))
print(dict.get_feature_names())
x_test = dict.transform(x_test.to_dict(orient="records"))
print(x_train)
# 用决策树进行预测
dec = DecisionTreeClassifier()
dec.fit(x_train, y_train)
# 预测准确率
print("预测的准确率:", dec.score(x_test, y_test))
#
# 导出决策树的结构
export_graphviz(dec, out_file="./tree.dot", feature_names=['年龄', 'pclass=1st', 'pclass=2nd', 'pclass=3rd', '女性', '男性'])
# 随机森林进行预测 (超参数调优)
# rf = RandomForestClassifier(n_jobs=-1)
param = {"n_estimators": [120, 200, 300, 500, 800, 1200], "max_depth": [5, 8, 15, 25, 30]}
# 网格搜索与交叉验证
gc = GridSearchCV(rf, param_grid=param, cv=2)
gc.fit(x_train, y_train)
print("准确率:", gc.score(x_test, y_test))
print("查看选择的参数模型:", gc.best_params_)
return None
if __name__ == "__main__":
decision()
随机森林
集成学习通过建立几个模型组合的来解决单一预测问题。它的工作原理是生成多个分类器/模型,各自独立地学习和作出预测。这些预测最后结合成单预测,因此优于任何一个单分类的做出预测。

定义
定义:在机器学习中,随机森林是一个包含多个决策树的分类器,并且其输出的类别是由个别树输出的类别的众数而定。
例如, 如果你训练了5个树, 其中有4个树的结果是True, 1个数的结果是False, 那么最终结果会是True.


集成学习API

优点
- 在当前所有算法中,具有极好的准确率
- 能够有效地运行在大数据集上
- 能够处理具有高维特征的输入样本,而且不需要降维
- 能够评估各个特征在分类问题上的重要性
- 对于缺省值问题也能够获得很好得结果

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)