
linux内核源码分析之伙伴系统(三)
目录伙伴关系基础避免碎片1,依据可移动性组织页2、虚拟可移动内存域内核中不连续页的分配用vmalloc分配内存释放内存伙伴关系基础free_area[]数组中各个元素的索引也解释为阶,用于指定对应链表中的连续内存区包含多少页帧。第0个链表包含的内存区为单页(2的0次方),第一个链表管理的内存区为两页(2的1次方),第三个管理的内存区为4页,依次类推。order阶通常设置为11,这就意味着一次可请求
·
目录
伙伴关系基础
free_area[]数组中各个元素的索引也解释为阶,用于指定对应链表中的连续内存区包含多少页帧。第0个链表包含的内存区为单页(2的0次方),第一个链表管理的内存区为两页(2的1次方),第三个管理的内存区为4页,依次类推。
- order阶通常设置为11,这就意味着一次可请求的最大页数是2的11方=2048
- free_area空闲页的列表;
- 伙伴不必是彼此连接的;
查看有关伙伴系统当前状态信息,各个内存区域中每个分配阶中空闲项的数目,从左到右,阶依次升高
# cat /proc/buddyinfo
Node 0, zone DMA 0 0 0 1 2 1 1 0 1 1 3
Node 0, zone DMA32 5202 1301 575 315 221 105 48 22 8 4 656
Node 0, zone Normal 6912 5437 143 5020 2337 954 400 91 24 10 1
避免碎片
1,依据可移动性组织页
无论空闲页在物理内存中是如何分布,应用程序看到内存似乎总是连续的。对于内核来说,碎片是一个问题。
反碎片的工作原理
- 不可移动页:在内存中有固定位置,不能移动到其他地方。核心内核分配的大多数内存属于该类别
- 可回收页:不能直接移动,但可以删除,其内容可以从某些源重新生成。例如,映射文件的数据类别属于该类别。kswapd守护进程会根据可回收页访问的频繁程度,周期性释放此类内存。另外,内存短缺时也可以发起页面回收。
- 可移动页:可以随意地移动。属于用户空间应用程序的页属于该类别,他们是通过页表映射的。
由于页无法移动,导致在原本几乎全空的内存区中无法进行连续分配。根据页的可移动性,将其分配到不同的列表中,即可防止这种情形。
例如,不可移动的页不能位于可移动内存区的中间,否则就无法从该内存区分配较大的连续内存块。
在各个迁移链表之间,当前的页面分配状态可以从/proc/pagetypeinfo获得
root@ubuntu:~# cat /proc/pagetypeinfo
Page block order: 9
Pages per block: 512
Free pages count per migrate type at order 0 1 2 3 4 5 6 7 8 9 10
Node 0, zone DMA, type Unmovable 0 0 0 1 2 1 1 0 1 0 0
Node 0, zone DMA, type Movable 0 0 0 0 0 0 0 0 0 1 3
Node 0, zone DMA, type Reclaimable 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone DMA, type HighAtomic 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone DMA, type CMA 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone DMA, type Isolate 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone DMA32, type Unmovable 5 3 4 5 6 1 0 0 1 1 0
Node 0, zone DMA32, type Movable 5075 1219 534 262 192 100 47 21 6 2 656
Node 0, zone DMA32, type Reclaimable 122 79 37 48 23 4 1 1 1 1 0
Node 0, zone DMA32, type HighAtomic 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone DMA32, type CMA 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone DMA32, type Isolate 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone Normal, type Unmovable 0 10 0 1465 1433 744 391 85 19 10 1
Node 0, zone Normal, type Movable 6269 5299 115 3415 862 200 4 2 2 0 0
Node 0, zone Normal, type Reclaimable 335 137 30 126 42 10 5 4 3 0 0
Node 0, zone Normal, type HighAtomic 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone Normal, type CMA 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone Normal, type Isolate 0 0 0 0 0 0 0 0 0 0 0
Number of blocks type Unmovable Movable Reclaimable HighAtomic CMA Isolate
Node 0, zone DMA 1 7 0 0 0 0
Node 0, zone DMA32 12 1500 16 0 0 0
Node 0, zone Normal 505 1859 196 0 0 0 2、虚拟可移动内存域
根据可移动性组织页是防止物理内存碎片的一种可能方法,内核还提供了一种阻止该问题的手段:虚拟内存域ZONE_MOVABLE。
基本思想:可用的物理内存划分为两个内存域,一个用于可移动分配,一个用于不可移动分配。这会自动防止不可移动页向可移动内存域引入碎片。
内核中不连续页的分配
物理上连续的映射对内核是最好的,但并不总能成功地使用。在分配一大块内存时,可能竭尽全力也无法找到连续的内存块。在用户空间中这不是问题,因为普通进程设计为使用处理器的分页机制,当然这会降低速度并占用TLB。
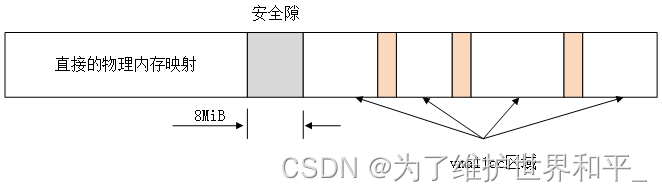
在 IA-32 系统中,紧随直接映射的前 892 MiB 物理内存,在插入的 8 MiB安全隙之后,是一个用于管理不连续内存的区域。这一段具有线性地址空间的所有性质

每个vmalloc分配的子区域都是自包含的,与其他vmalloc子区域通过一个内存页分隔
用vmalloc分配内存
vmalloc是一个接口函数,内核代码使用它来分配在虚拟内存中连续但在物理内存中不一定连续的内存。
特别是在设备和声音驱动程序中
void *vmalloc(unsigned long size);数据结构
内核在管理虚拟内存中的vmalloc
区域时,内核必须跟踪哪些子区域被使用、哪些是空闲的。为此定义了一个数据结构,将所有使用的部分保存在一个链表中。
struct vm_struct {
struct vm_struct *next;
void *addr;
unsigned long size;
unsigned long flags;
struct page **pages;
unsigned int nr_pages;
phys_addr_t phys_addr;
const void *caller;
};- addr:定义了分配的子区域在虚拟地址空间中的起始位置,size表示该子区域的长度。
- flags:存储了与该内存区关联的标志集合。它只用于指定内存区类型,可选值有以下3个VM_ALLOC指定由vmalloc产生的子区域;VM_MAP用于表示将现存的pages集合映射到连续的虚拟地址空间中; VM_IOREMAP:表示将几乎随机的物理内存区域映射到vmalloc区域中,这是一个特定于系统结构的操作。
- page是一个指针,指向page指针的数组,每个数组成员都表述一个映射到虚拟地址空间中物理内存页的page实例
- phys_addr仅当用ioremap映射了由物理地址描述的物理内存区域时才需要。
- next使得内核可以将vmalloc区域中的所有子区域保持在一个单链表上。
将物理内存页映射到vmalloc区域

vmalloc分配内存区的调用关系

核心源码
static void *__vmalloc_area_node(struct vm_struct *area, gfp_t gfp_mask,
pgprot_t prot, int node)
{
struct page **pages;
unsigned int nr_pages, array_size, i;
const gfp_t nested_gfp = (gfp_mask & GFP_RECLAIM_MASK) | __GFP_ZERO;
const gfp_t alloc_mask = gfp_mask | __GFP_NOWARN;
const gfp_t highmem_mask = (gfp_mask & (GFP_DMA | GFP_DMA32)) ?
0 :
__GFP_HIGHMEM;
nr_pages = get_vm_area_size(area) >> PAGE_SHIFT;
array_size = (nr_pages * sizeof(struct page *));
/* Please note that the recursion is strictly bounded. */
if (array_size > PAGE_SIZE) {
pages = __vmalloc_node(array_size, 1, nested_gfp|highmem_mask,
PAGE_KERNEL, node, area->caller);
} else {
pages = kmalloc_node(array_size, nested_gfp, node);
}
if (!pages) {
remove_vm_area(area->addr);
kfree(area);
return NULL;
}
area->pages = pages;
area->nr_pages = nr_pages;
for (i = 0; i < area->nr_pages; i++) {
struct page *page;
if (node == NUMA_NO_NODE)
page = alloc_page(alloc_mask|highmem_mask);
else
page = alloc_pages_node(node, alloc_mask|highmem_mask, 0);
if (unlikely(!page)) {
/* Successfully allocated i pages, free them in __vunmap() */
area->nr_pages = i;
atomic_long_add(area->nr_pages, &nr_vmalloc_pages);
goto fail;
}
area->pages[i] = page;
if (gfpflags_allow_blocking(gfp_mask))
cond_resched();
}
atomic_long_add(area->nr_pages, &nr_vmalloc_pages);
if (map_vm_area(area, prot, pages))
goto fail;
return area->addr;
fail:
warn_alloc(gfp_mask, NULL,
"vmalloc: allocation failure, allocated %ld of %ld bytes",
(area->nr_pages*PAGE_SIZE), area->size);
__vfree(area->addr);
return NULL;
}
- 如果显式指定了分配页帧的结点,则内核调用alloc_pages_node。否则,使用alloc_page从当 前结点分配页帧。
- 分配的页从相关结点的伙伴系统移除。在调用时,vmalloc将gfp_mask设置为GFP_KERNEL | __GFP_HIGHMEM,内核通过该参数指示内存管理子系统尽可能从ZONE_HIGHMEM内存域分配页帧。原因:低端内存域的页帧更为宝贵,因此不应该浪费到vmalloc的分配中,在此使用高 端内存域的页帧完全可以满足要求。
- 内核调用map_vm_area将分散的物理内存页连续映射到虚拟的vmalloc区域。该函数遍历分配的物理内存页,在各级页目录/页表中分配所需的目录项/表项。
释放内存
vfree用于释放
vmalloc
和
vmalloc_32
分配的区域,
vunmap用于释放由vmap或
ioremap
创建的映射。
这两个函数都会归结到__vunmap
。
void __vunmap(void *addr, int deallocate_pages)- addr表示要释放的区域的起始地址
- deallocate_pages指定了是否将与该区域相关的物理内存页返回给伙伴系统。

- 此__vunmap的第一个任务是在__remove_vm_area(由remove_vm_area在完成锁定之后调用)中扫描该链表,以找到相关项。
- unmap_vm_area使用找到的vm_area实例,从页表删除不再需要的项。
- 如果__vunmap的参数deallocate_pages设置为1(在vfree中),内核会遍历area->pages的所有元素,即指向所涉及的物理内存页的page实例的指针。然后对每一项调用__free_page,将页释放到伙伴系统。
- 释放用于管理该内存区的内核数据结构
参考
《深入Linux内核架构》
更多推荐
 1
1 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)