论文笔记:主干网络——GoogLeNet-V3
Rethinking the Inception Architecture for Computer Vision重新思考计算机视觉中的Inception结构
Rethinking the Inception Architecture for Computer Vision
重新思考计算机视觉中的Inception结构
论文结构
摘要: 介绍CNN在CV的成功,存在计算量问题,本文提出提升计算效率的方法
1. Introduction: CNN广泛应用,变得越来越大,VGG和GoogLeNet-V1均不适用于真实场景,本文提出新技术解决上述问题。
2. General Design Principles: 通过总结大量实验,提出4个模型设计准则,为模型设计提供参考。
3. Factorizing Convolutions with Large Filter Size: 针对运算效率,提出分解卷积,在部分inception-module中使用分解的卷积,减少模型参数。
**4. Utility of Auxiliary Classifiers: ** 重新思考辅助分类层的作用,推翻V1论文中的部分结论,认为只存在正则的作用,不存在帮助低层特征提取的作用。
5. Efficient Grid Size Reduction: 针对直接池化产生信息瓶颈问题,提出新的特征图分辨率下降的操作,有效符合了设计准则1.
6. Inception - v2: 经过大量实验,改进Inception-v1,得到新的模型结构inception-v2。
7. Model Regularization via Label Smoothing: 提出基于标签平滑的正则化技术,提高模型的泛化能力,减轻过拟合。
8. Training Methodology: 介绍训练模型的设置。
9. Performance on Lower Resolution Input: 探讨如何有效对低分辨率图像进行分类,为目标检测等任务提供思路。
10. Experimental Results and Comparisons: 实验结果及对比分析。
11. Conclusions: 总结本文工作
一、摘要核心
① 介绍背景:2014年以来,CNN成为主流,在多个任务中获得优异成绩。
② 提出问题: 目前精度高的CNN,参数多,计算量大,存在落地困难的问题。
③ 解决问题:本文提出分解卷积及正则化策略,提升CNN速度和精度。
④ 本文成果
二、4个网络结构设计准则(论文中的2)
① 避免特征表示瓶颈如pool,将特征图减半,信息量变少。
要避免过度压缩;通常分辨率是缓慢下降的
② 采用更高维的表示方法,更容易处理网络局部信息
③ 大的卷积核可以分解为数个小卷积核,且不会降低网络能力。(论文的3.1详细解释)
④ 平衡好深度和宽度。
三、卷积分解(论文中的3)
① 分解成小卷积核(论文中3.1)
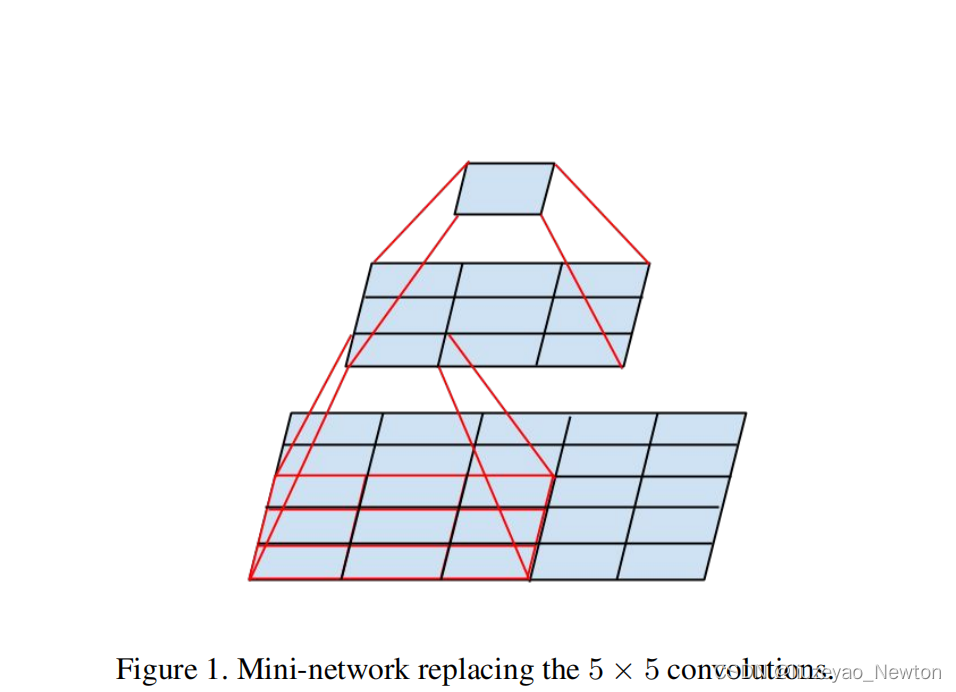
(1)小卷积核和大卷积核的优缺点:
- 小卷积核,计算量小;
- 大卷积核,感受野大,可捕获更多信息
- 小卷积核会降低表达能力
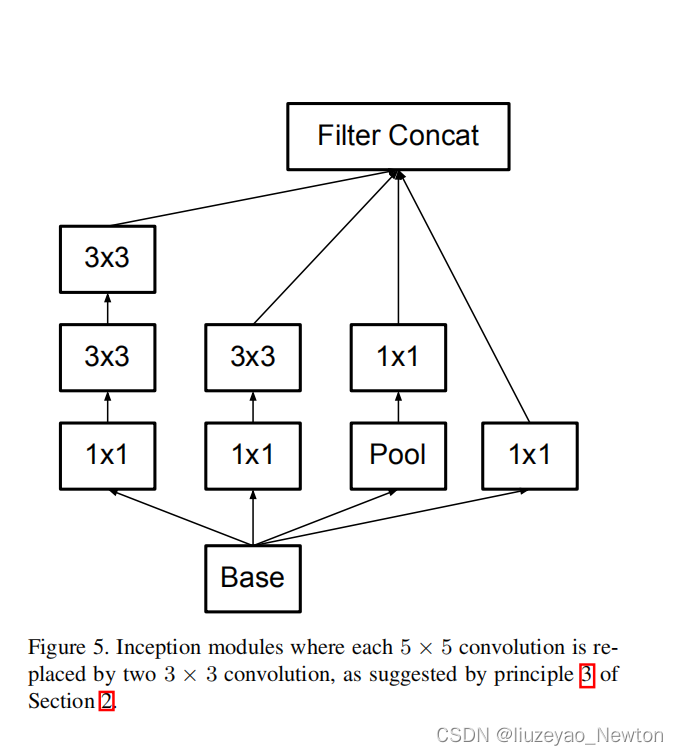
(2)将大的堆叠—>小堆叠,用两个3×3网络层替换5*5卷积可具备相同输入和输出深度。
(3)存在2个问题是否有表征损失?第一层是否需要线性激活?
通过图2的实验表明relu比linear要好
② 非对称卷积(论文中的3.2)
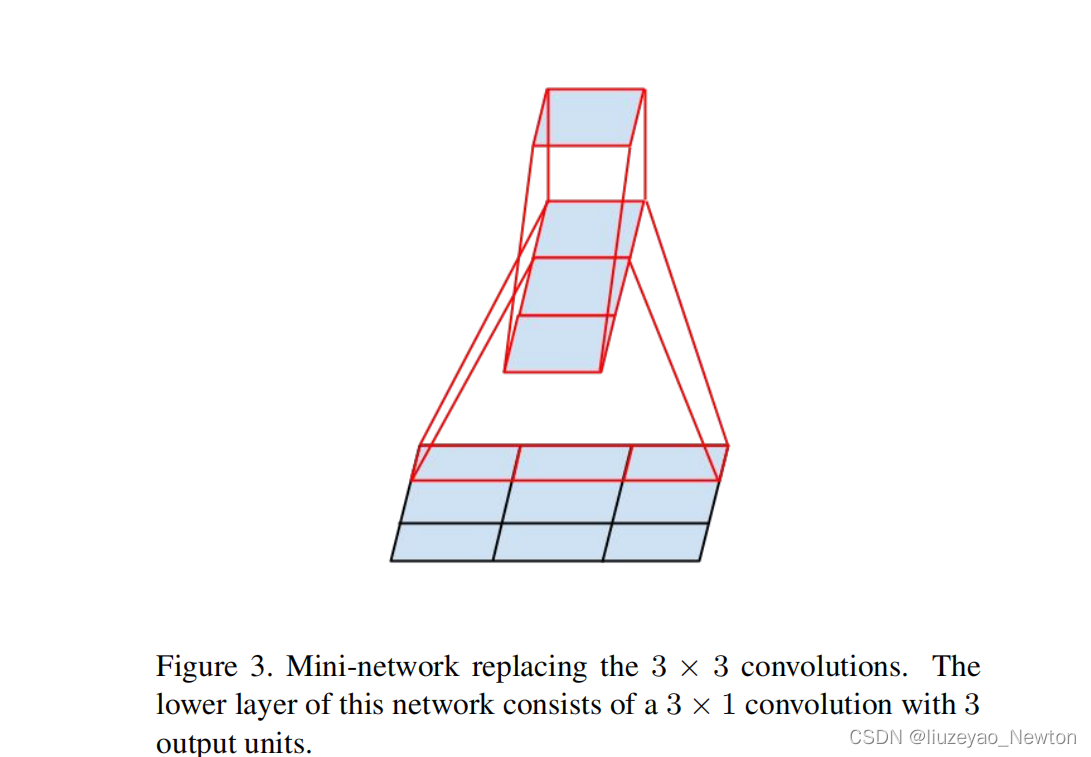
(1 )分解为非对称卷积
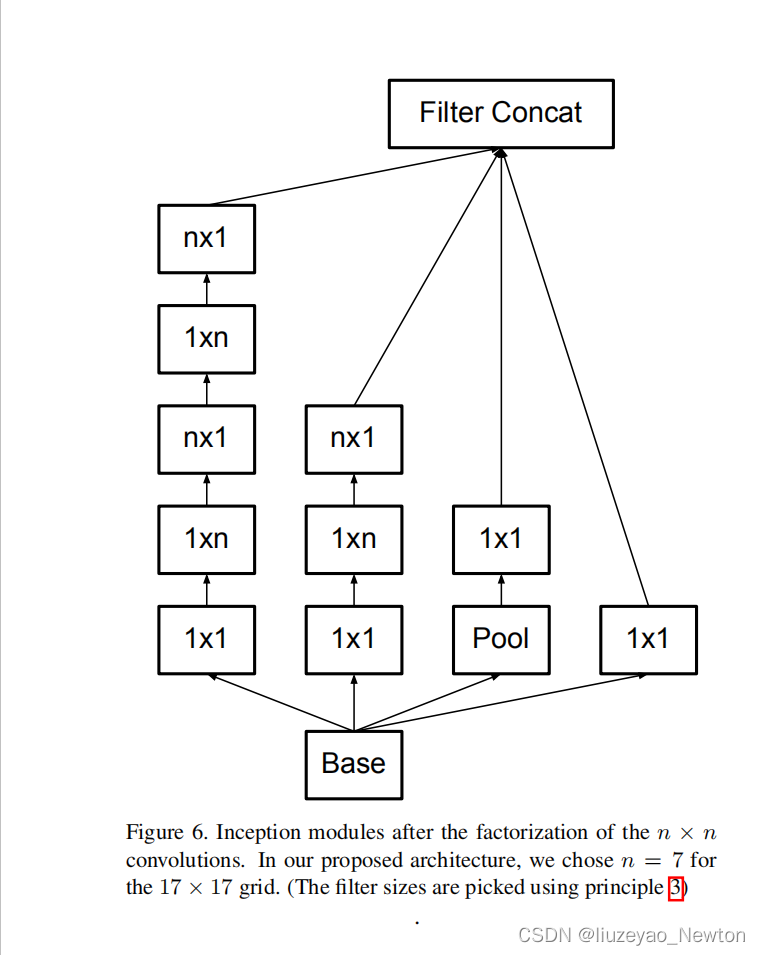
3×3卷积可以分解为1×3和3×1,或者两个2×2,但前者效果更好。
前者参数减少了1-(3+3)/ 9 =33%
后者参数减少了1-(4+4)/9 = 11%
(2)后半段使用效果才好,特征图分辨率在12-20之间
- 一开始不要分解,效果不好!
- 特征图在12到20之间是比较好的!
- 最好的参数是1×7,7×1
四、辅助分类层的探讨(论文的4)
再探讨:
- 辅助分类层在早期起不到加速收敛作用,在后期才能提升网络性能
- 收敛前,有无辅助分类,训练速度一样。V1中移除较低的辅助分类,并不影响精度
- 快收敛,有辅助分类的超过没有辅助分类的
- V1中提到的辅助分类层有助于低层特征提取的假设是不正确的
- 本文认为辅助分类起到正则的作用
- GoogLeNet-V3 在17×17特征图结束接入辅助分类层
五、高效特征图下降策略(论文中的5)

传统池化存在信息表征瓶颈问题,(违反模型设计准则1),即特征图信息变少了。
简单解决方法:先用卷积将特征图通道数翻倍,再用池化
存在问题:计算量过大
解决方法:用卷积得到一半特征图,用池化得到一半特征图
图10中的方法分两步走,卷积和池化分别得到k个特征图,这样就实现2K个特征图的获取。
卷积stride = 2,可以让特征图下降一半
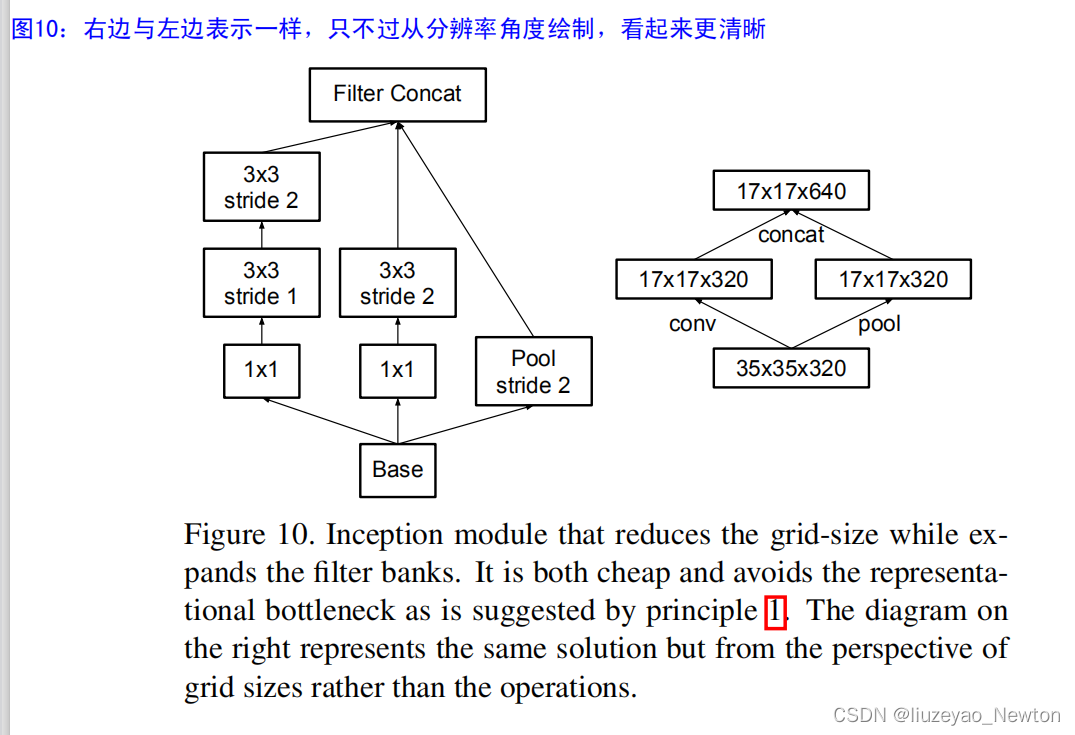
用较少的计算量获得较多的信息,避免信息表征瓶颈。
该Inception-module用于35×35下降至17×17,17×17下降至8×8(论文中的6)
六、标签平滑(论文中的7)
传统的one-hot编码存在的问题——过度自信,导致过拟合
提出标签平滑,把one-hot中概率为1的那一项进行衰减,衰减的那部分confience平均分道每一个类别中。
在交叉熵公式中,将q进行标签平滑变成q’,让模型输出的p分布去逼近q’。
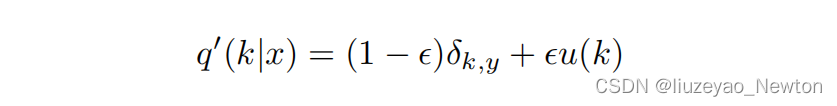
其中u(k)是概率分布,一般为均匀分布,则得到

标签平滑后的交叉熵损失函数:
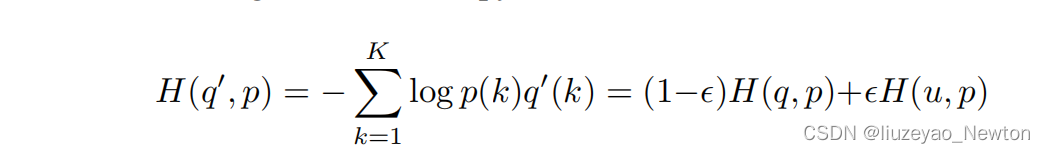
当k=y时,δk,y=1
否则,δk,y=0
p分布越逼近q’分布,越接近,交叉熵损失越小。
七、Inception-v2(论文中的6)
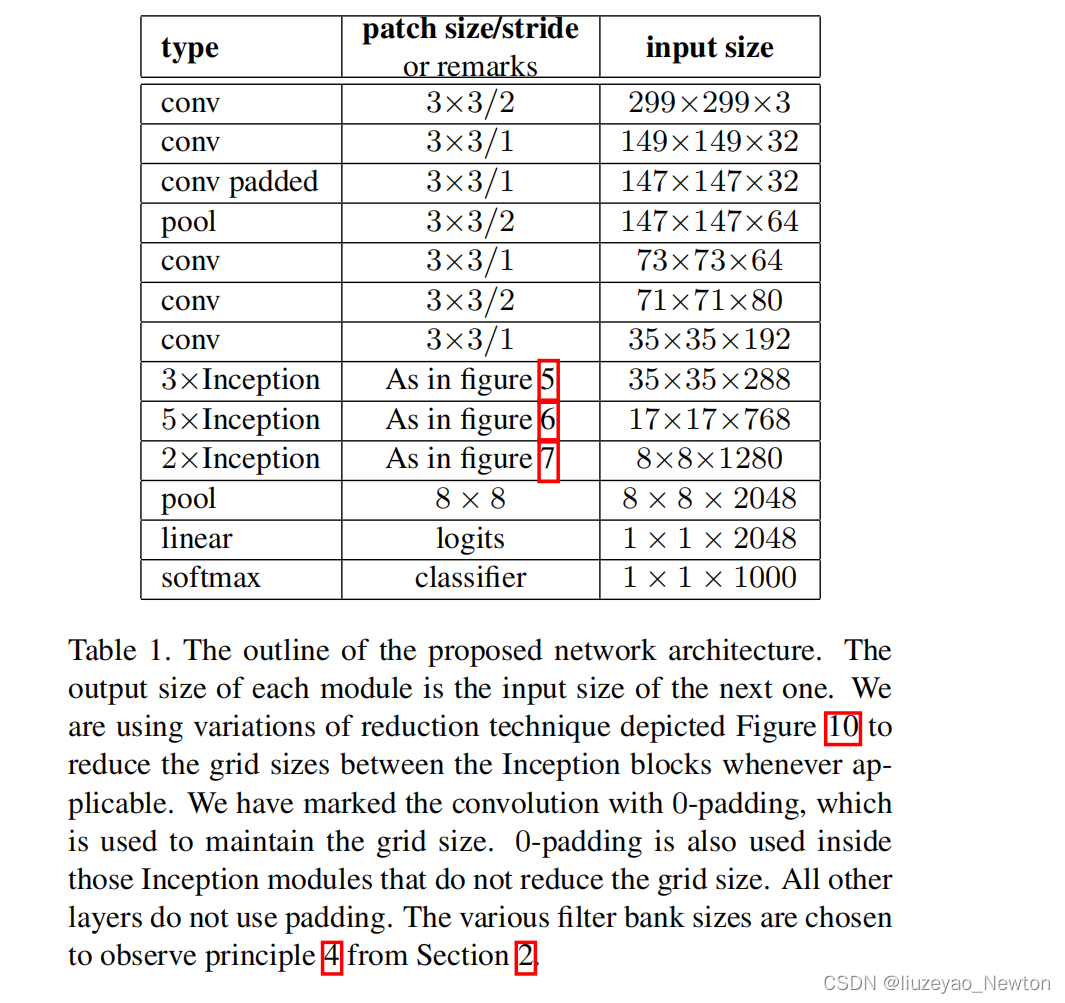
① 针对V1的主要变化:
- 7×7替换为3个3×3卷积,并且在第一个卷积就采用stride = 2来降低分辨率。
- 第二个3个3×3卷积,在第二个卷积才下降分辨率
- 第一个block增加一个inception-module,第一个inception-module只是把5×5卷积替换为2个3×3卷积
- 第二个block,处理17×17特征图,采用非对称卷积,用5个卷积分解的module。
- 第三个block,处理8×8特征图,遵循准则2,提出拓展的卷积。8. 最后输出2048个神经元,V1是1024个神经元。 8×8×1280时用图6所示的2个module进行处理最终输出8×8×2048
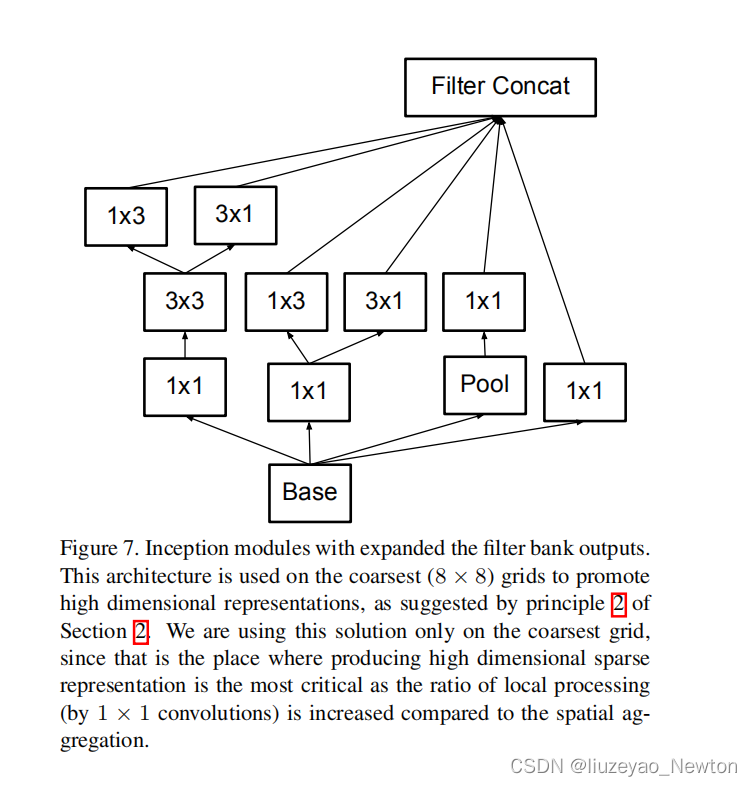
② Inception-V3: 在v2的基础上改进4点。
- 采用RMSProp优化方法
- 采用标签平滑正则化方法
- 采用非对称卷积提取17×17特征图
- 采用带BN的辅助分类层。
八、低分辨率图像分类策略(论文中的9)
低分辨率图像分类在目标检测中广泛应用,需要有效对低分辨率图像进行分类。
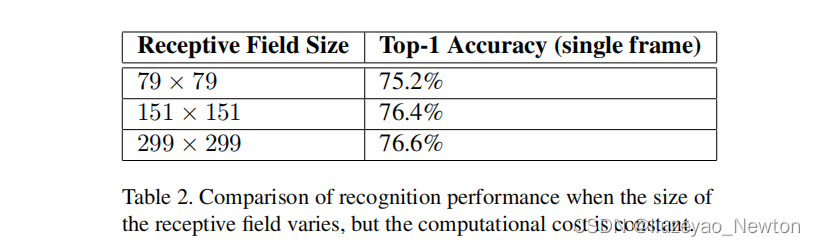
本文方案:
将第一个卷积层stride = 2改为stride = 1,用于151×15的图像
将第一个卷积层stride = 2改为stride = 1,移除第一个池化层,用于79×79的图像
借鉴思路:
修改网络模型头部stride和池化,来处理低分辨率图片,可尽可能的保留原网络模型结构,不损失网络精度。
九、实验结果对比
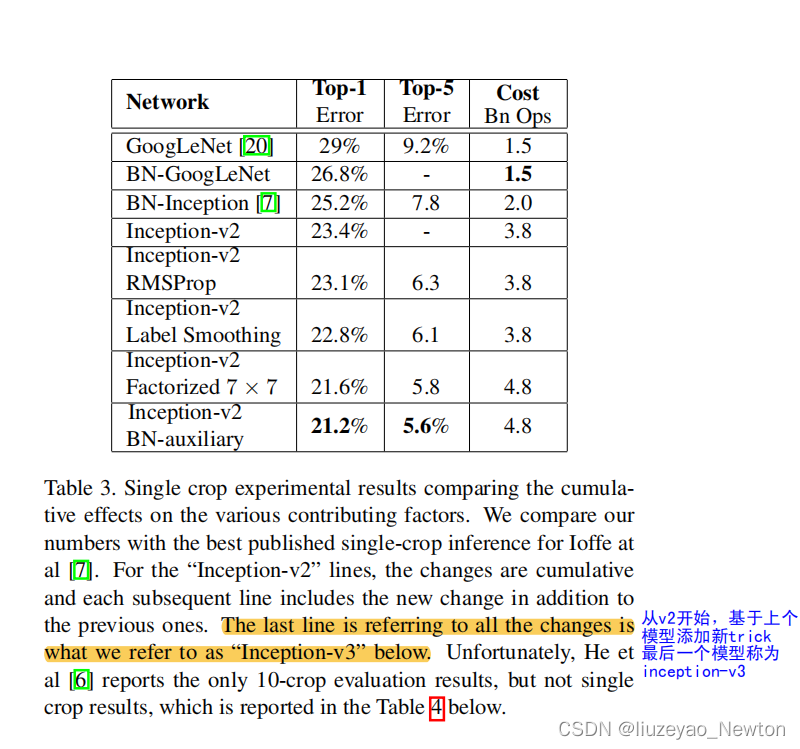
① GoogLeNet系列对比,得到最优的模型:inception-V2 BN auxiliary(inception-V3)
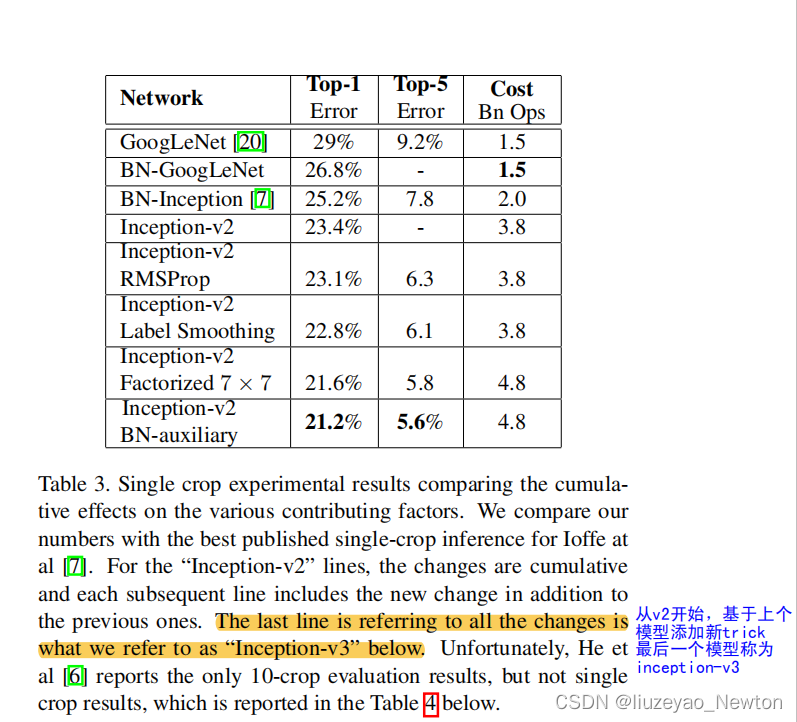
② 单模型对比
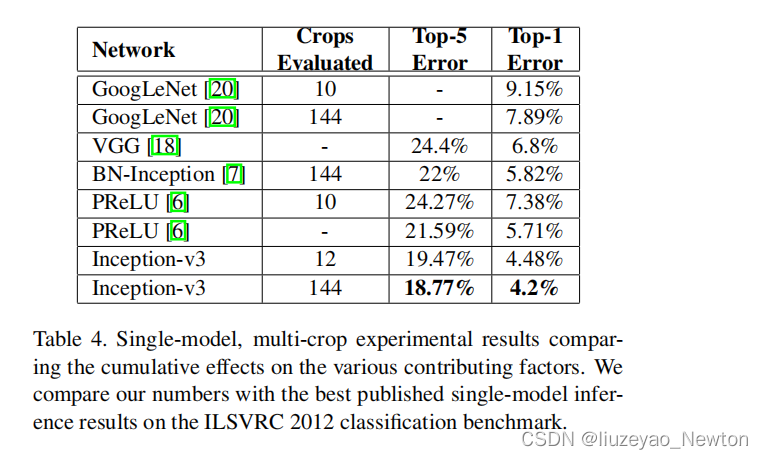
单模型上横向对比,Inception-V3优于目前各模型。
十、论文总结
① 关键点、创新点
- 非对称卷积分解:减少参数计算量,为卷积结构设计提供新思路
- 高效特征秃下降策略:利用stride = 2的卷积和池化,避免信息表征瓶颈
- 标签平滑:避免网络过度自信,减轻过拟合
② 备用参考文献知识点:
-
非对称卷积分解在分辨率为12-20的特征图上效果较好,且用1×7和7×1进行特征提取。
In practice, we have found that employing this factorization does not work well on early layers, but it gives very good results on medium grid-sizes (On m×m feature maps, where m ranges between 12 and 20). On that level, very good results can be achieved by using 1 × 7 convolutions followed by 7 × 1 convolutions. (论文3.2的第二段) -
移除两个辅助分类层的第一个,并不影响网络性能。
The removal of the lower auxiliary branch did not have any adverse effect on the final quality of the network.(论文4的第二段) -
标签平滑参数设置,让非标签的概率保持在10-4左右
In our ImageNet experiments with K = 1000 classes, we used u(k) = 1/1000 and ∈= 0.1. (论文7的第六段)

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)