

编码器-解码器(seq2seq)
文章目录1、编码器解码器架构1.1、概念1.2、代码1.2.1、编码器(Encoder)1.2.2、解码器(Decoder)1.2.3、合并编码器和解码器2、seq2seq模型2.1、编码器2.2、解码器2.3、编码器-解码器细节2.4、训练&推理2.5 评价指标-BLEU3、机器翻译代码3.1、机器翻译数据集3.1.1、下载和预处理数据集3.1.2、词元化3.1.3、词表3.1.4、截断
文章目录
在自然语言处理的很多应用中,输入和输出都可以是不定长序列。以机器翻译为例,输入可以是一段不定长的英语文本序列,输出可以是一段不定长的法语文本序列,例如:
英语输入:“They” “are” “watching” “.”
法语输出:“Ils” “regardent” “.”
当输入和输出都是不定长序列时,可以使用编码器-解码器(encoder-decoder)架构或seq2seq模型。这两个都由两部分组成,分别叫做编码器和解码器。编码器用来分析输入序列,解码器用来生成输出序列。
对于编码器-解码器(encoder-decoder)架构和seq2seq模型有啥联系和区别呢?
我的理解是,编码器-解码器更像是一个模型的抽象,一种大的架构,而seq2seq模型则是使用这种架构进行机器翻译的一个模型。因为现在比较火的transformer也是使用了编码器-解码器架构,因此我觉得编码器-解码器是一种抽象的结构,而seq2seq和transformer都是使用这种架构搭建用于具体任务的具体模型。像用于图像处理的CNN也可以看成一个编码器-解码器架构。
1、编码器解码器架构
1.1、概念
在CNN中
在卷积神经网络中,图片先经过卷积层,然后再经过线性层,最终输出分类结果。其中卷积层用于特征提取,而线性层用于结果预测。从另一个角度来看,可以把特征提取看成一个编码器,将原始的图片编码成有利于机器学习的中间表达形式,而解码器就是把中间表示转换成另一种表达形式。
- 编码器:将输入编程成中间表达特征。
- 解码器:将中间表示解码成输出。

在RNN中
RNN同样也可以看成一个编码器-解码器结构,编码器将文本编码成向量,而解码器将向量解码成我们想要的输出。
- 编码器:将文本表示成向量。
- 解码器:将向量表示成输出。

架构抽象
因此我么就可以把编码器-解码器抽象成一个框架。一个模型就可以分成两块,一部分叫做编码器,另一部分叫做解码器。编码器将输入编码成一个中间状态(或者中间语义表示),解码器将这些中间状态进行处理然后输出,当然解码器也可以获取输入与中间状态一起生成输出。编码器和解码器也可以由好多个编码器解码器组成,即由多层组成。其中编码器可以是各种网络,如线性网络,CNN,RNN,亦或是像transformer编码器那种复杂的结构;解码器与编码器也可以是一样的网络,也可以是不同的网络。

seq2seq中的编码器解码器
后面介绍的seq2seq用到的也是这种架构,seq2seq实现的功能是将一个序列转换成另一个序列。以英文翻译为法语为例,seq2seq中的编码器就是对输入的英语句子进行处理,将输入的英文句子
X
X
X进行编码,将输入句子通过非线性变换转化成中间语义表示C:
C
=
f
(
x
1
,
x
2
,
⋯
,
x
m
)
C=f(x_1,x_2,\cdots ,x_m)
C=f(x1,x2,⋯,xm)
而对于解码器是根据中间语义表示C和之前已经生成的历史信息
y
1
,
y
2
,
y
3
,
⋯
,
y
i
−
1
y_1,y_2,y_3,\cdots ,y_{i-1}
y1,y2,y3,⋯,yi−1来生成i时刻要生成的法语单词
y
i
y_i
yi:
y
i
=
g
(
C
,
y
1
,
y
2
,
y
3
,
⋯
,
y
i
−
1
)
y_i = g(C,y_1,y_2,y_3,\cdots ,y_{i-1})
yi=g(C,y1,y2,y3,⋯,yi−1)
每个
y
i
y_i
yi依次生成,就将英文句子
X
X
X翻译成了法语句子
Y
Y
Y
编码器-解码器模型应用十分的广泛,其应用场景也很多,比如对于机器翻译来说, < X , Y > <X,Y> <X,Y>就是对应的不同语言的句子;对于文本摘要来说, X X X为一篇文章, Y Y Y就是对应的摘要;对于问答系统来说, X X X为问题, Y Y Y是给出的回答。
1.2、代码
因为编码器-解码器是一种抽象的结构,因此它没有具体的实现,只有使用这种结构用于具体的业务中时才有具体实现,因此下面看看编码器-解码器的相应的抽象接口。
1.2.1、编码器(Encoder)
下面是编码器的接口实现,使用指定长度可变的序列作为编码器的输入,然后得到中间语义编码。
from torch import nn
#编码器-解码器的基本编码器接口
class Encoder(nn.Module):
def __init__(self):
super(Encoder, self).__init__()
def forward(self,X,*args):
#子类需要实现,不然报错
raise NotImplementedError
1.2.2、解码器(Decoder)
在解码器结构中,新增一个init_state函数,用于将编码器的输出(enc_output)转换解码器输入的状态。解码器中有时可能需要额外的输入。解码器在每个时间步都会将输入(前一个时间步生成的词元)和编码后的中间状态解码成当前时间步的输出词元。
#编码器-解码器的基本解码器接口
class Decoder(nn.Module):
def __init__(self,**kwargs):
super(Decoder, self).__init__()
def init_state(self,enc_outputs,*args):
raise NotImplementedError
def forward(self,X,state):
raise NotImplementedError
1.2.3、合并编码器和解码器
编码器和解码器中包含了一个编码器和一个解码器。在前向传播过程中,编码器的输出用于生成中间编码状态,这个状态又被解码器作为其输入的一部分。
#编码器-解码器架构的基类
class EncoderDecoder(nn.Module):
def __init__(self,encoder,decoder,**kwargs):
super(EncoderDecoder, self).__init__()
self.encoder = encoder
self.decoder = decoder
def forward(self,enc_X,dec_X,*args):
enc_outputs = self.encoder(enc_X,*args)
dec_state = self.decoder.init_state(enc_outputs,*args)
return self.decoder(dec_X,dec_state)
2、seq2seq模型
按照我的理解,seq2seq模型就是编码器-解码器抽象架构的一种具体实现,它主要用来做机器翻译的任务(也可以用于其他任务),包含了一个编码器和一个解码器。上一节对其进行了一个简单的描述,下面详细介绍seq2seq模型,并使用它实现一个机器翻译的任务。
下图为使用seq2seq模型将英文翻译成法语句子的过程图。在训练过程中,为每个句子后附加上特殊符号 < e o s > ( e n d o f s e q u e n c e ) <eos>(end of sequence) <eos>(endofsequence)表示序列的终止,在解码器的最初时间步用一个表示序列开始的特殊符号 < b o s > ( b e g i n i n g o f s e q u e n c e ) <bos>(begining of sequence) <bos>(beginingofsequence)。
-
编码器使用RNN处理输入信息,把最终时间步的隐藏状态作为输入信息的表征或编码信息。编码器由于能够看到句子的全部,因此编码器可以是双向的。
-
解码器也同样是一个RNN,它在各个时间步中使用输入句子的编码信息(编码器的输出)和解码器上个时间步输出合并作为输入,用来预测当前时间步的输出。由于解码器不能看到句子的全部,因此它不能是双向的。

2.1、编码器
编码器的作用是将长度可变的输入序列转换成一个定长的中间语义表示 c c c,可以用循环神经网络设计编码器。
考虑由一个序列组成的样本(批量大小为1)。假设输入序列是
x
1
,
⋯
,
x
T
x_1,\cdots ,x_T
x1,⋯,xT,其中
x
t
x_t
xt是输入文本序列中的第
t
t
t个词元。在时间步
t
t
t,循环神经网络将词元
x
t
x_t
xt的输入特征向量
x
t
x_t
xt和上一时间步的隐状态
h
t
−
1
h_{t-1}
ht−1,计算当前时间步的隐状态
h
t
h_t
ht。使用函数
f
f
f表示循环神经网络的循环层所做的变换:
h
t
=
f
(
x
t
,
h
t
−
1
)
h_t=f(x_t,h_{t-1})
ht=f(xt,ht−1)
而编码器所生成的中间语义表示
c
c
c为最后一个时间步
T
T
T的隐藏状态,这里最后一个时间步隐藏状态的输出为所有时间步隐藏状态的拼接,即:
c
=
h
T
c=h_T
c=hT
2.2、解码器
对于来自训练数据集的输出序列
y
1
,
y
2
,
⋯
,
y
T
y_1,y_2,\cdots ,y_T
y1,y2,⋯,yT,对于每个时间步
t
t
t,解码器的输出
y
t
y_t
yt的概率取决于先前的输出子序列
y
1
,
y
2
,
⋯
,
y
t
−
1
y_1,y_2,\cdots ,y_{t-1}
y1,y2,⋯,yt−1和中间语义表示
c
c
c,即:
P
(
y
t
∣
y
1
,
⋯
,
y
t
−
1
,
c
)
P(y_t|y_1,\cdots ,y_{t-1},c)
P(yt∣y1,⋯,yt−1,c)
为此,可以使用另一个循环神经网络作为解码器。在输出序列的时间步
t
t
t,解码器将上一时间步的输出
y
t
−
1
y_{t-1}
yt−1以及中间语义表示
c
c
c作为输入,并将它们与上一时间步的隐藏状态
s
t
−
1
s_{t-1}
st−1变换成当前时间步的隐藏状态
s
t
s_t
st。用函数g表示解码器隐藏层的变换:
s
t
=
g
(
y
t
−
1
,
c
,
s
t
−
1
)
s_t = g(y_{t-1},c,s_{t-1})
st=g(yt−1,c,st−1)
在获得解码器的隐状态之后,就可以使用输出层和softmax操作来计算在时间步
t
t
t的输出
y
t
y_t
yt和
y
t
y_t
yt的条件概率分布
P
(
y
t
∣
y
1
,
⋯
,
y
t
−
1
,
c
)
P(y_t|y_1,\cdots ,y_{t-1},c)
P(yt∣y1,⋯,yt−1,c)。
2.3、编码器-解码器细节
编码器是没有输出的RNN,它只需要把最后一层最后一个时间节点的隐藏状态输出给解码器就好了。而解码器RNN的初始隐藏状态就是编码器输出的中间语义表示,而在解码器的每个时间步都使用了编码器输出的中间语义表示,中间语义表示与解码器的输入(上一个时间步的输出)一起组成当前时间步的输入,与上一时间步的隐状态一起计算当前时间步的输出。
当循环神经网络是多层的时候,解码器的初始状态为编码器最后一个时间步所有层的输出。而解码器每一个时间步的输入则是编码器最后一层最后一个时间步的输出与解码器上一时间输出进行的合并。

2.4、训练&推理
seqseq模型在训练和推理的过程中是不一样的。编码器部分是一样的,因为都能看到所有的句子,不同的地方是在解码器部分。
- 训练过程中我们知道正确的句子是什么,因此无论解码器上一时间步的输出是否正确,当前时间步的输入永远都是正确的输入。,
- 推理过程我们的目的是为了预测整个句子,因此我们不知道正确的句子是什么,因此解码器当前时间步的输入是上一时间步的输出,然后依次预测下去。

2.5 评价指标-BLEU
通过预测序列与真实标签序列进行比较来评估预测序列,BLEU(Bilingual Evaluation Understudy)不仅可以用于评估机器翻译的结果,它还可以用于测量许多应用输出序列的质量。
对于预测序列中的任意 n n n元语法( n − g r a m s n-grams n−grams),BLEU的评估是这个 n n n元语法是否出现在标签序列中。
用 p n p_n pn表示 n n n元语法的精度,它是两个数量的比值,第一个数是预测序列与标签序列中匹配的 n n n元语法的数量,第二个是预测序列中 n n n元语法的数量。通过一个例子,给定标签序列 A 、 B 、 C 、 D 、 E 、 F A、B、C、D、E、F A、B、C、D、E、F和预测序列 A 、 B 、 B 、 C 、 D A、B、B、C、D A、B、B、C、D。对于一元语法,预测序列中一元语法的数量为5,而预测序列与标签序列中匹配的n元语法的数量为4,则 p 1 = 4 5 p_1 = \frac{4}{5} p1=54,依次类推 p 2 = 3 4 p_2=\frac{3}{4} p2=43, p 3 = 1 3 p_3=\frac{1}{3} p3=31, p 4 = 0 p_4=0 p4=0。
l
e
n
l
a
b
e
l
len_{label}
lenlabel和
l
e
n
p
r
e
d
len_{pred}
lenpred分别为标签序列中的词元数和预测序列中的词元数,下面公式为BLEU的定义:
e
x
p
(
m
i
n
(
0
,
1
−
l
e
n
l
a
b
e
l
l
e
n
p
r
e
d
)
)
∏
n
=
1
k
p
n
1
/
2
n
exp(min(0,1-\frac{len_{label}}{len_{pred}}))\prod_{n=1}^{k}p_n^{1/2^n}
exp(min(0,1−lenpredlenlabel))n=1∏kpn1/2n
因为在预测过程中,对较短的句子比较容易预测,而对于比较长的句子不容易预测,因此在BLEU中需要对过短的预测添加惩罚项,对长的匹配分配高的权重:
-
其中如 e x p ( m i n ( 0 , 1 − l e n l a b e l l e n p r e d ) ) exp(min(0,1-\frac{len_{label}}{len_{pred}})) exp(min(0,1−lenpredlenlabel))为惩罚过短的预测,当标签序列大于预测序列的时候,该项的值会很小。例如当 k = 2 k=2 k=2时,给定标签序列 A 、 B 、 C 、 D 、 E 、 F A、B、C、D、E、F A、B、C、D、E、F和预测序列 A 、 B A、B A、B,尽管 p 1 = p 2 = 1 p_1=p_2=1 p1=p2=1,乘法因子exp(1-6/2)=0.14会降低BLEU值。
-
n n n元语法的 1 / 2 n 1/2^n 1/2n方是为了对长匹配有更高权重,当长度n越大时, 1 / 2 n 1/2^n 1/2n会越小,则 p n 1 / 2 n p_n^{1/2^n} pn1/2n会越大。
BLEU的值越大,预测的结果就越好(最大值为1),当预测序列与标签序列完全相同的时候,BLUE的值为1。
3、机器翻译代码
下面使用使用Pytorch实现上面介绍的模型,并使用"英-法"数据集对模型进行训练,下面主要介绍以下两部分
- 加载并处理"英-法"数据集
- 搭建seq2seq模型并使用数据集进行训练。
3.1、机器翻译数据集
3.1.1、下载和预处理数据集
下载有Tatoeba项目的双语句子对中的"英-法"数据集,数据集的每一行都是制表符分割的文本序列对,序列对由英文文本序列和翻译后的法语文本序列组成。每个文本序列可以是一个句子,也可以是包含多个句子的一个段落。
import os
import torch
import collections
from torch.utils import data
#从文件中读取英文-法文数据集
def read_data_nmt():
with open('fra-eng/fra.txt', 'r',encoding='utf-8') as f:
return f.read()
raw_text = read_data_nmt()
print(raw_text[:75])
Go. Va !
Hi. Salut !
Run! Cours !
Run! Courez !
Who? Qui ?
Wow! Ça alors !
读取到数据集之后,下面对数据进行预处理。有以下处理步骤:
- 首先使用空格代替不间断(连续)空格。
- 使用小写字符替换大写字。
- 在单词和标点符号之间插入空格。
def preprocess_nmt(text):
def no_space(char,prev_char):
return char in set(',.!?') and prev_char != ' '
#使用空格替换不间断空格
#使用小写字母替换大写字母
text = text.replace('\u202f',' ').replace('\xa0',' ').lower()
#在单词和标点符号之间插入空格
out = [' ' + char if i > 0 and no_space(char,text[i - 1]) else char for i,char in enumerate(text)]
return ''.join(out)
text = preprocess_nmt(raw_text)
print(text[:80])
go . va !
hi . salut !
run ! cours !
run ! courez !
who ? qui ?
wow ! ça alors !
3.1.2、词元化
下面对数据进行词元化,文本序列中每个词元(tokenize)要么是一个词,要么是一个标点符号。此函数返回两个词元列表source和target:source[i]是第i个文本序列的词元列表,target[i]是目标语言的第i个序列的词元列表。
#num_examples 样本的数量
def tokenize_nmt(text,num_examples = None):
source,target = [],[]
#按行分割成一个一个列表
for i,line in enumerate(text.split('\n')):
#大于样本数量,停止添加
if num_examples and i > num_examples:
break
#按照\t将英文和法语分割开
parts = line.split('\t')
if len(parts) == 2:
source.append(parts[0].split(' '))
target.append(parts[1].split(' '))
return source,target
source,target = tokenize_nmt(text)
source[:6],target[:6]
([['go', '.'],
['hi', '.'],
['run', '!'],
['run', '!'],
['who', '?'],
['wow', '!']],
[['va', '!'],
['salut', '!'],
['cours', '!'],
['courez', '!'],
['qui', '?'],
['ça', 'alors', '!']])
3.1.3、词表
下面为源语言和目标语言构建两个词表,使用单词级词元化时,词表大小明显大于使用字符集级的词表大小。为了缓解这一问题,将出现次数少于两次的低频词元视为未知(“<unk>”)词元。然后还指定了额外的特定词元,例如在小批量时用于将序列填充到相同长度的填充词元(“<pad>”),以及序列的开始词元(“<bos>”)和结束词元(“<eos>”)
词元的类型是字符串,而模型需要的输入是数字,因此这种类型不方便模型使用。下面,构建一个字典,通常也叫作词表,用来将字符串类型的词元映射到从0开始的数字索引中。我理解词表就是一个字典,可以通过索引查词元或者词元查索引。
下面的函数将统计词元的频率,即某个词元在训练集中出现的次数,最后以一个列表的形式返回。
#统计词元的频率,返回每个词元及其出现的次数,以一个字典形式返回。
def count_corpus(tokens):
#这里的tokens是一个1D列表或者是2D列表
if len(tokens) == 0 or isinstance(tokens[0], list):
#将词元列表展平为一个列表
tokens = [token for line in tokens for token in line]
#该方法用于统计某序列中每个元素出现的次数,以键值对的方式存在字典中。
return collections.Counter(tokens)
corpus_num=count_corpus(source)
print(corpus_num['the'])
33263
下面定义的Vocab类,用于构建词表,并支持查询词表长度、通过索引查询词元、词元查询索引的功能
#文本词表
class Vocab:
def __init__(self,tokens = None, min_freq = 0, reserved_tokens = None):
if tokens is None:
tokens = []
if reserved_tokens is None:
reserved_tokens = []
#按照单词出现频率排序
counter = count_corpus(tokens)
#counter.items():为一个字典
#lambda x:x[1]:对第二个字段进行排序
#reverse = True:降序
self._token_freqs = sorted(counter.items(),key = lambda x:x[1],reverse = True)
#未知单词的索引为0
#idx_to_token用于保存所有未重复的词元
self.idx_to_token = ['<unk>'] + reserved_tokens
#token_to_idx:是一个字典,保存词元和其对应的索引
self.token_to_idx = {token:idx for idx,token in enumerate(self.idx_to_token)}
for token, freq in self._token_freqs:
#min_freq为最小出现的次数,如果小于这个数,这个单词被抛弃
if freq < min_freq:
break
#如果这个词元未出现在词表中,将其添加进词表
if token not in self.token_to_idx:
self.idx_to_token.append(token)
#因为第一个位置被位置单词占据
self.token_to_idx[token] = len(self.idx_to_token) - 1
#返回词表的长度
def __len__(self):
return len(self.idx_to_token)
#获取要查询词元的索引,支持list,tuple查询多个词元的索引
def __getitem__(self, tokens):
if not isinstance(tokens,(list,tuple)):
#self.unk:如果查询不到返回0
return self.token_to_idx.get(tokens,self.unk)
return [self.__getitem__(token) for token in tokens]
# 根据索引查询词元,支持list,tuple查询多个索引对应的词元
def to_tokens(self,indices):
if not isinstance(indices,(list,tuple)):
return self.idx_to_token[indices]
return [self.idx_to_token[index] for index in indices]
@property
def unk(self):
return 0
@property
def token_freqs(self):
return self._token_freqs
测试一下源语言的词表
src_vocab = Vocab(source, min_freq=2,reserved_tokens=['<pad>', '<bos>', '<eos>'])
#返回前十个词元及其对应的索引
print(list(src_vocab.token_to_idx.items())[:10])
#输出词元及其对应的索引
print(source[0])
print(src_vocab[source[0]])
[('<unk>', 0), ('<pad>', 1), ('<bos>', 2), ('<eos>', 3), ('.', 4), ('i', 5), ('you', 6), ('to', 7), ('the', 8), ('?', 9)]
['go', '.']
[47, 4]
3.1.4、截断和填充文本序列
在语言模型中的序列样本都有一个固定的长度,这个固定的长度是由时间步数(词元数量)指定的。在机器翻译中,源和目标文本序列具有不同的长度,为了提高学习效率,使用截断和填充的方式处理序列使其具有相同的长度。
假设同一个小批量每个序列有应该有相同的长度num_steps,那么如果文本序列的词元数目小于num_steps时,将在其末尾添加特定的"<pad>"词元,直到其长度达到num_steps;如果文本序列的词元数目大于num_steps,那么只取前num_steps个词元,并且丢弃剩余的词元。
为什么序列长度需要一样?
同一个batch在处理的时候都是处理相同的时间步,因此序列的长度一定得匹配,不然没办法进行训练。
def truncate_pad(line,num_steps,padding_token):
if len(line) > num_steps:
return line[:num_steps]
return line + [padding_token] * (num_steps - len(line))
#前两项为原本的序列,后面的1为填充的<pad>
truncate_pad(src_vocab[source[0]], 10, src_vocab['<pad>'])
[47, 4, 1, 1, 1, 1, 1, 1, 1, 1]
下面一个函数将词元序列转为索引序列,然后在序列末尾添加结束标志/对应的索引,以便于预测时生成/时代表序列输出结束,最后返回经过填充与截断操作后的序列以及为经过填充与截断操作的序列长度。
def build_array_nmt(lines,vocab,num_steps):
#将词元序列,转为词元对应的索引序列
lines = [vocab[l] for l in lines]
lines = [l + [vocab['<eos>']] for l in lines]
array = torch.tensor([truncate_pad(l,num_steps,vocab['<pad>']) for l in lines])
valid_len = (array != vocab['<pad>']).type(torch.int32).sum(1)
#array为经过截断与填充的序列
#valid_len为未经过截断与填充的序列的长度。
return array,valid_len
build_array_nmt(source, src_vocab,1000)
(tensor([[ 47, 4, 3, ..., 1, 1, 1],
[2944, 4, 3, ..., 1, 1, 1],
[ 435, 126, 3, ..., 1, 1, 1],
...,
[ 381, 60, 26, ..., 1, 1, 1],
[ 66, 295, 90, ..., 1, 1, 1],
[ 17, 176, 32, ..., 1, 1, 1]]),
tensor([ 3, 3, 3, ..., 47, 49, 52]))
3.1.5、构建数据迭代器
最后,定义一个函数用来返回数据迭代器,以及源语言和目标语言的两种词表。
#构造一个Pytorch数据迭代器
def load_array(data_arrays,batch_size,is_train=True):
dataset=data.TensorDataset(*data_arrays)
return data.DataLoader(dataset,batch_size,shuffle=is_train)
#返回翻译数据集的迭代器和词表
def load_data_nmt(batch_size,num_steps,num_examples = 600):
#加载并处理数据
text = preprocess_nmt(read_data_nmt())
#词元化
source,target = tokenize_nmt(text,num_examples)
#构建源语言和目标语言的词表
src_vocab = Vocab(source,min_freq=2,reserved_tokens=['<pad>','<bos>','<eos>'])
tgt_vocab = Vocab(target,min_freq=2,reserved_tokens=['<pad>','<bos>','<eos>'])
#生成词元对应索引构成的语言序列
src_array,src_valid_len = build_array_nmt(source,src_vocab,num_steps)
tgt_array,tgt_valid_len = build_array_nmt(target,tgt_vocab,num_steps)
#生成数据集的迭代器
data_arrays = (src_array,src_valid_len,tgt_array,tgt_valid_len)
data_iter = load_array(data_arrays,batch_size)
return data_iter,src_vocab,tgt_vocab
下面读出“英语-法语”数据集中的第一个小批量数据。
train_iter,src_vocab,tgt_vocab = load_data_nmt(batch_size=2,num_steps=8)
for X,X_valid_len,Y,Y_valid_len in train_iter:
print('X:',X.type(torch.int32))
print('X有效长度为:',X_valid_len)
print('Y:', Y.type(torch.int32))
print('Y有效长度为:', Y_valid_len)
break
X: tensor([[162, 9, 5, 3, 1, 1, 1, 1],
[ 6, 143, 4, 3, 1, 1, 1, 1]], dtype=torch.int32)
X有效长度为: tensor([4, 4])
Y: tensor([[171, 5, 3, 1, 1, 1, 1, 1],
[ 10, 0, 4, 3, 1, 1, 1, 1]], dtype=torch.int32)
Y有效长度为: tensor([3, 4])
现在数据已经处理好了,下面就可以搭建模型,并使用该数据集进行训练了。
3.2、seq2seq模型搭建与训练
导入使用的相关包
import collections
import math
import torch
from torch import nn
from d2l import torch as d2l
3.2.1、编码器
首先实现编码器部分,使用嵌入层来获得输入序列中每个词元的特征向量。嵌入层的权重时一个矩阵,其行数等于输入词表的大小,其列数等于特定向量的维度。对于任意输入词元的索引i,嵌入层获取权重矩阵的第i行以返回其特征向量。下面先介绍下pytorch中如何使用torch.nn.Embedding函数实现词嵌入:
其为一个简单的存储固定大小的词典的嵌入向量的查找表,意思就是说,给一个编号,嵌入层就能返回这个编号对应的嵌入向量,嵌入向量反映了各个编号代表的符号之间的语义关系。
在pytorch中的格式为:
torch.nn.Embedding(num_embeddings, embedding_dim, padding_idx=None, max_norm=None, norm_type=2.0,
scale_grad_by_freq=False, sparse=False, _weight=None, device=None, dtype=None)
参数说明:
- num_embeddings (int) - 嵌入字典的大小
- embedding_dim (int) - 每个嵌入向量的大小
- padding_idx (int, optional) - 如果提供的话,输出遇到此下标时用零填充
- max_norm (float, optional) - 如果提供的话,会重新归一化词嵌入,使它们的范数小于提供的值
- norm_type (float, optional) - 对于max_norm选项计算p范数时的p1
- scale_grad_by_freq (boolean, optional) - 如果提供的话,会根据字典中单词频率缩放梯度
输入输出形状:
- 输入:(N, W):N = mini-batch, W = 每个mini-batch中提取的下标数
- 输出:(N, W, embedding_dim):前一部分为输入的形状,后面为嵌入向量的大小
下面看看简单使用:
embeding = nn.Embedding(10,5)
input = torch.LongTensor([[1,2,4,5],[4,3,2,9]])
output = embeding(input)
input.shape,output.shape,output
(torch.Size([2, 4]),
torch.Size([2, 4, 5]),
tensor([[[-0.4725, 1.3666, 0.2446, 0.5467, 0.2617],
[ 0.6482, 0.0768, -1.3123, -1.4706, 0.3101],
[-0.4600, 1.2231, -0.0948, -2.0522, 0.0775],
[-0.7260, 0.2551, -0.4578, 1.1381, -0.2653]],
[[-0.4600, 1.2231, -0.0948, -2.0522, 0.0775],
[ 0.4369, 0.4180, -0.0175, 0.4675, 0.8469],
[ 0.6482, 0.0768, -1.3123, -1.4706, 0.3101],
[-0.2412, -0.3602, 1.2952, -0.5347, 0.9056]]],
grad_fn=<EmbeddingBackward0>))
然后就使用GRU来实现编码器,以获得输入序列的中间语义表示。
class Seq2SeqEncoder(nn.Module):
def __init__(self,vocab_size,embed_size,num_hiddens,num_layers,dropout = 0,**kwargs):
super(Seq2SeqEncoder, self).__init__(**kwargs)
#嵌入成
self.embedding = nn.Embedding(vocab_size,embed_size)
#循环曾
self.rnn = nn.GRU(embed_size,num_hiddens,num_layers,dropout=dropout)
def forward(self,X,*args):
#X的形状应该为(batch_size,num_steps,embed_size)
X = self.embedding(X)
#修改X的形状为(num_steps,batch_sizemembed_size)
#第一个维度对应于时间步
#permute:将tensor的维度换位。
X = X.permute(1,0,2)
#初始状态为传入,默认为0
output,state = self.rnn(X)
# output的形状:(num_steps,batch_size,num_hiddens)
# state[0]的形状:(num_layers,batch_size,num_hiddens)
return output, state
下面测试一下上面定义的编码器,其中GRU为2层,隐层特征数为16。给定一个小批量输入序列X(批量大小为4,时间步为7)。最后一个隐藏层的输入output形状为(时间步数,批量大小,隐藏特征数),而state保存的时当前时间步每一隐藏层的隐藏状态,其形状为(隐藏层数量,批量大小,隐藏特征数)。
encoder = Seq2SeqEncoder(vocab_size = 10,embed_size = 8,num_hiddens = 16,num_layers = 2)
#切换为测试模式
encoder.eval()
X = torch.zeros((4,7),dtype = torch.long)
output,state = encoder(X)
output.shape,state.shape
(torch.Size([7, 4, 16]), torch.Size([2, 4, 16]))
output = encoder(X)
output[0].shape,output[1].shape
(torch.Size([7, 4, 16]), torch.Size([2, 4, 16]))
output为所有时间步隐藏状态的集合,而state可以看成当前时间步所有隐藏层隐藏状态的集合,那么output最后一个元素和state最后一个元素都代表了当前时间步最后一层隐藏状态,那么它们应该相等,下面测试一下。
output[-1][-1]==state[-1]
tensor([[True, True, True, True, True, True, True, True, True, True, True, True,
True, True, True, True],
[True, True, True, True, True, True, True, True, True, True, True, True,
True, True, True, True],
[True, True, True, True, True, True, True, True, True, True, True, True,
True, True, True, True],
[True, True, True, True, True, True, True, True, True, True, True, True,
True, True, True, True]])
没错是一样的!
3.2.2、解码器
使用编码器最后一个时间步(所有层)的隐藏状态来初始化解码器隐藏状态,这就要求编码器和解码器具有相同的隐藏特征数和隐藏层数。使用编码器最后一个时间步最后一层的输出与解码器的输入进行拼接最为新的输入。为了预测词元的概率分布,在解码器的最后一层使用全连接层输出最终结果。
class Seq2SeqDecoder(nn.Module):
def __init__(self,vocab_size,embed_size,num_hiddens,num_layers,dropout = 0,**kwargs):
super(Seq2SeqDecoder, self).__init__(**kwargs)
self.embedding = nn.Embedding(vocab_size,embed_size)
self.rnn = nn.GRU(embed_size + num_hiddens,num_hiddens,num_layers,dropout = dropout)
self.dense = nn.Linear(num_hiddens,vocab_size)
def init_state(self,enc_outputs,*args):
#返回最后一个时间步的隐藏状态(包含多个层的隐藏状态)
return enc_outputs[1]
def forward(self,X,state):
X = self.embedding(X).permute(1,0,2)
#首先只取最后一个时间步,最后一层隐藏状态的值,形状为(1,批量大小,隐藏特征数),需要和输入进行拼接
#因此使用广播变成(时间步长度,批量大小,隐藏特征数)的形状,每一时间步都是一样的,因此可以看出编码器的输出
#作用到了解码器每一时间步
context = state[-1].repeat(X.shape[0],1,1)
#进行拼接,因此解码器的输入为embed_size + num_hiddens
X_and_context = torch.cat((X,context),2)
output,state = self.rnn(X_and_context,state)
#传入线性层
output = self.dense(output).permute(1,0,2)
# output的形状:(batch_size,num_steps,vocab_size)
# state[0]的形状:(num_layers,batch_size,num_hiddens)
return output,state
下面实例化一下解码器,检查一下输入,使用和解码器中相同的超参数。由于最后一层使用了线性层,因此解码器的输出编程(批量大小,时间步数,词表大小),张量的最后一个维度存储预测的词元分布。
decoder = Seq2SeqDecoder(vocab_size = 10,embed_size = 8,num_hiddens = 16,num_layers = 2)
decoder.eval()
state = decoder.init_state(encoder(X))
output,state = decoder(X,state)
output.shape,state.shape
(torch.Size([4, 7, 10]), torch.Size([2, 4, 16]))
3.2.3、编码器-解码器
编码器-解码器中包含了一个编码器和一个解码器。在前向传播过程中,编码器的输出用于生成中间编码状态,这个状态又被解码器作为其输入的一部分。下面将编码器解码器整合起来。
class EncoderDecoder(nn.Module):
def __init__(self,encoder,decoder,**kwargs):
super(EncoderDecoder, self).__init__()
self.encoder = encoder
self.decoder = decoder
def forward(self,enc_X,dec_X,*args):
enc_outputs = self.encoder(enc_X,*args)
dec_state = self.decoder.init_state(enc_outputs,*args)
return self.decoder(dec_X,dec_state)
3.2.4、损失函数
在每个时间步,解码器预测了输出词元的分布。与语言模型类似,可以使用softmax来获得分布,并计算交叉熵损失函数来进行优化。而在前面处理数据集的时候,我们在序列的末尾添加了特定的填充词元,将不同长度的序列变为了相同的长度。但是,填充的词元的预测应该排除在损失函数的计算之内。
使用下面的函数通过零值话屏蔽不相关的项,以便后面任何不相关预测的计算都是与零的乘积,结果都为0。就是把有效长度之后的项全部清除为0。
def sequence_mask(X,valid_len,value = 0):
#词表大小序列长度
maxlen = X.size(1)
#构建遮罩
mask = torch.arange((maxlen),dtype = torch.float32,device=X.device)[None:] < valid_len[:,None]
X[~mask] = value
return X
X = torch.tensor([[1,2,3],[4,5,6]])
sequence_mask(X,torch.tensor([1,2]))
tensor([[1, 0, 0],
[4, 5, 0]])
还可以使用次函数屏蔽最后几个轴上的所有项,也可以使用非零值来替换这些项。
X = torch.ones(2,3,4)
sequence_mask(X,torch.tensor([1,2]),value = -1)
tensor([[[ 1., 1., 1., 1.],
[-1., -1., -1., -1.],
[-1., -1., -1., -1.]],
[[ 1., 1., 1., 1.],
[ 1., 1., 1., 1.],
[-1., -1., -1., -1.]]])
下面就可以扩展softmax交叉熵损失函数来遮蔽不相关的预测。
#带mask的交叉熵损失函数
class MaskedSoftmaxCELoss(nn.CrossEntropyLoss):
# pred的形状:(batch_size,num_steps,vocab_size)
# label的形状:(batch_size,num_steps)
# valid_len的形状:(batch_size,)
def forward(self,pred,label,valid_len):
weights = torch.ones_like(label)
weights = sequence_mask(weights,valid_len)
self.reduction = 'none'
#计算真实损失
unweighted_loss = super(MaskedSoftmaxCELoss,self).forward(pred.permute(0,2,1),label)
#使用mask进行处理
weighted_loss = (unweighted_loss * weights).mean(dim = 1)
return weighted_loss
下面使用三个全为0的相同的序列来检查自定义交叉熵损失函数的结果,然后分别指定这些有效序列的长度为4,2,0。结果应该是第一个序列是第二个序列的两倍,而第三个序列为0。
loss = MaskedSoftmaxCELoss()
loss(torch.ones(3,4,10),torch.ones((3,4),dtype = torch.long),torch.tensor([4,2,0]))
tensor([2.3026, 1.1513, 0.0000])
3.2.5、训练
在循环训练过程中,序列开始词元(“<bos>”)和原始输出序列拼接在一起作为解码器的输入。解码器的每一个输入都是当前步真实的翻译值与解码器的输出进行拼接的。
模型计算出的值的长度为词表大小(每一个值代表为该词的概率),而标签值则是一个索引(词表中的第一个词)为一个数值(pytorch中不需要转为one-hot),使用自定义的带遮罩的交叉熵损失函数计算损失。
#使用GPU
def try_gpu(i=0):
if torch.cuda.device_count()>=i+1:
return torch.device(f'cuda:{i}')
return torch.device('cpu')
#梯度截断
def grad_clipping(net,theta):
if isinstance(net,nn.Module):
params = [p for p in net.parameters() if p.requires_grad]
else:
params = net.params
norm = torch.sqrt(sum(torch.sum((p.grad ** 2)) for p in params))
if norm > theta:
for param in params:
param.grad[:] *= theta / norm
def train_seq2seq(net,data_iter,lr,num_epochs,tgt_vocab,device):
#初始化模型参数
def xavier_init_weights(m):
if type(m) == nn.Linear:
nn.init.xavier_uniform_(m.weight)
if type(m) == nn.GRU:
for param in m._flat_weights_names:
if "weight" in param:
nn.init.xavier_uniform_(m._parameters[param])
net.apply(xavier_init_weights)
net.to(device)
#优化器和损失函数
optimizer = torch.optim.Adam(net.parameters(),lr = lr)
loss = MaskedSoftmaxCELoss()
#开启训练模式
net.train()
animator = d2l.Animator(xlabel = 'epoch',ylabel = 'loss',xlim=[10,num_epochs])
for epoch in range(num_epochs):
timer = d2l.Timer()
#训练损失总和,词元数量
metric = d2l.Accumulator(2)
for batch in data_iter:
X,X_valid_len,Y,Y_valid_len = [x.to(device) for x in batch]
#将开始符号添加到目标语言序列上
bos = torch.tensor([tgt_vocab['<bos>']] * Y.shape[0],device = device).reshape(-1,1)
dec_input = torch.cat([bos,Y[:,:-1]],1)
#计算真实值
Y_hat,_ = net(X,dec_input,X_valid_len)
#计算损失
l = loss(Y_hat,Y,Y_valid_len)
l.sum().backward()
grad_clipping(net,1)
num_tokens = Y_valid_len.sum()
optimizer.step()
with torch.no_grad():
metric.add(l.sum(),num_tokens)
if (epoch + 1) % 10 == 0:
animator.add(epoch + 1,(metric[0]/metric[1],))
print(f'loss {metric[0] / metric[1]:.3f},{metric[1]/timer.stop():.1f} tokens.sec on {str(device)}')
下面定义相关的变量,使用数据集对模型进行训练,
#词嵌入大小,隐藏层特征数,rnn层数,丢弃值
embed_size,num_hiddens,num_layers,dropout = 32,32,2,0.1
#批量大小,时间步
batch_size,num_steps = 64,10
#学习率,训练轮次,训练使用的设备
lr,num_epochs,device = 0.005,300,try_gpu()
#获取数据集和词表
train_iter,src_vocab,tgt_vocab = load_data_nmt(batch_size,num_steps)
#实例化编码器-解码器模型
encoder = Seq2SeqEncoder(len(src_vocab),embed_size,num_hiddens,num_layers,dropout)
decoder = Seq2SeqDecoder(len(tgt_vocab),embed_size,num_hiddens,num_layers,dropout)
net = EncoderDecoder(encoder,decoder)
#进行训练
train_seq2seq(net,train_iter,lr,num_epochs,tgt_vocab,device)
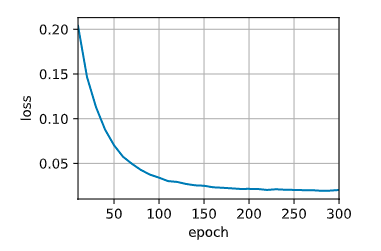
loss 0.020,7732.0 tokens.sec on cuda:0
3.2.6、预测
解码器当前时间步的输入都来自与前一时间步的预测词元。而开始词元是<bos>,当输出的序列遇到序列结束词元<eos>时,预测就结束了。
def predict_seq2seq(net,src_sentence,src_vocab,tgt_vocab,num_steps,device):
#设置为评估模式
net.eval()
#对句子进行预处理 然后在后面添加<eos>,预测到eos时结束,
src_tokens = src_vocab[src_sentence.lower().split(' ')] + [src_vocab['<eos>']]
#句子的长度
enc_valid_len = torch.tensor([len(src_tokens)],device = device)
#对句子进行截断和填充处理
src_tokens = truncate_pad(src_tokens,num_steps,src_vocab['<pad>'])
#添加批量轴
#添加一个指定维度,因为训练的时候有三个维度(批量,时间步,词向量),因此推理时也需要添加批量那一个维度
enc_X = torch.unsqueeze(torch.tensor(src_tokens,dtype = torch.long,device = device),dim = 0)
#获得编码器输出
enc_outputs = net.encoder(enc_X,enc_valid_len)
#获得解码器初始状态
dec_state = net.decoder.init_state(enc_outputs,enc_valid_len)
#添加批量轴
#解码器的输入也是三个维度,因此添加一个批量维度,加码器的第一个输入为序列开始词元<bos>
dec_X = torch.unsqueeze(torch.tensor([tgt_vocab['<bos>']],dtype = torch.long,device = device),dim = 0)
#保存输出内容
output_seq = []
for _ in range(num_steps):
#获得解码器输出
Y,dec_state = net.decoder(dec_X,dec_state)
#使用具有预测可能性最高的词元,作为解码器在下一时间步的输入
dec_X = Y.argmax(dim = 2)
#去除第0维所在的维度,并转为python数据类型
pred = dec_X.squeeze(dim = 0).type(torch.int32).item()
if pred == tgt_vocab['<eos>']:
break
output_seq.append(pred)
#通过构建的词表,将索引转为单词
return ' '.join(tgt_vocab.to_tokens(output_seq))
3.2.7、评估预测的词元
根据上面定义的BLEU的定义,通过代码实现BLEU然后对预测的结果进行评估。
def bleu(preq_seq,label_seq,k):
#对预测序列和标签序列进行分词
pred_tokens,label_tokens = preq_seq.split(' '),label_seq.split(' ')
#计算预测序列和标签序列的长度
len_pred,len_label = len(pred_tokens),len(label_tokens)
#惩罚果断的预测
score = math.exp(min(0,1 - len_label / len_pred))
for n in range(1,k + 1):
#定义一个统计值和字典
num_matches,label_subs = 0,collections.defaultdict(int)
#统计n元语法所有对应的词及其数量
for i in range(len_label - n + 1):
label_subs[''.join(label_tokens[i : i + n])] +=1
#在预测序列中找是否与标签序列中对应的n元语法
for i in range(len_pred - n + 1):
if label_subs[''.join(pred_tokens[i : i + n])] > 0:
num_matches +=1
label_subs[''.join(pred_tokens[i : i + n])] -= 1
score *= math.pow(num_matches / (len_pred - n + 1),math.pow(0.5,n))
return score
engs = ['go .', "i lost .", 'he\'s calm .', 'i\'m home .']
fras = ['va !', 'j\'ai perdu .', 'il est calme .', 'je suis chez moi .']
for eng, fra in zip(engs, fras):
translation = predict_seq2seq(
net, eng, src_vocab, tgt_vocab, num_steps, device)
print(f'{eng} => {translation}, bleu {bleu(translation, fra, k=2):.3f}')
go . => va !, bleu 1.000
i lost . => j'ai perdu payé ., bleu 0.658
he's calm . => il court ., bleu 0.000
i'm home . => je suis chez moi paresseux ., bleu 0.803
3.2.8、代码整合
下面对所有的代码进行整合
import os
import torch
import collections
from torch.utils import data
import math
from torch import nn
from d2l import torch as d2l
#1.处理数据集部分
#从文件中读取英文-法文数据集
def read_data_nmt():
with open('fra-eng/fra.txt', 'r',encoding='utf-8') as f:
return f.read()
#预处理数据
def preprocess_nmt(text):
def no_space(char, prev_char):
return char in set(',.!?') and prev_char != ' '
# 使用空格替换不间断空格
# 使用小写字母替换大写字母
text = text.replace('\u202f', ' ').replace('\xa0', ' ').lower()
# 在单词和标点符号之间插入空格
out = [' ' + char if i > 0 and no_space(char, text[i - 1]) else char for i, char in enumerate(text)]
return ''.join(out)
#对数据集进行词元化
def tokenize_nmt(text,num_examples = None):
source,target = [],[]
#按行分割成一个一个列表
for i,line in enumerate(text.split('\n')):
#大于样本数量,停止添加
if num_examples and i > num_examples:
break
#按照\t将英文和法语分割开
parts = line.split('\t')
if len(parts) == 2:
source.append(parts[0].split(' '))
target.append(parts[1].split(' '))
return source,target
#统计词元的频率,返回每个词元及其出现的次数,以一个字典形式返回。
def count_corpus(tokens):
#这里的tokens是一个1D列表或者是2D列表
if len(tokens) == 0 or isinstance(tokens[0], list):
#将词元列表展平为一个列表
tokens = [token for line in tokens for token in line]
#该方法用于统计某序列中每个元素出现的次数,以键值对的方式存在字典中。
return collections.Counter(tokens)
#文本词表
class Vocab:
def __init__(self,tokens = None, min_freq = 0, reserved_tokens = None):
if tokens is None:
tokens = []
if reserved_tokens is None:
reserved_tokens = []
#按照单词出现频率排序
counter = count_corpus(tokens)
#counter.items():为一个字典
#lambda x:x[1]:对第二个字段进行排序
#reverse = True:降序
self._token_freqs = sorted(counter.items(),key = lambda x:x[1],reverse = True)
#未知单词的索引为0
#idx_to_token用于保存所有未重复的词元
self.idx_to_token = ['<unk>'] + reserved_tokens
#token_to_idx:是一个字典,保存词元和其对应的索引
self.token_to_idx = {token:idx for idx,token in enumerate(self.idx_to_token)}
for token, freq in self._token_freqs:
#min_freq为最小出现的次数,如果小于这个数,这个单词被抛弃
if freq < min_freq:
break
#如果这个词元未出现在词表中,将其添加进词表
if token not in self.token_to_idx:
self.idx_to_token.append(token)
#因为第一个位置被位置单词占据
self.token_to_idx[token] = len(self.idx_to_token) - 1
#返回词表的长度
def __len__(self):
return len(self.idx_to_token)
#获取要查询词元的索引,支持list,tuple查询多个词元的索引
def __getitem__(self, tokens):
if not isinstance(tokens,(list,tuple)):
#self.unk:如果查询不到返回0
return self.token_to_idx.get(tokens,self.unk)
return [self.__getitem__(token) for token in tokens]
# 根据索引查询词元,支持list,tuple查询多个索引对应的词元
def to_tokens(self,indices):
if not isinstance(indices,(list,tuple)):
return self.idx_to_token[indices]
return [self.idx_to_token[index] for index in indices]
@property
def unk(self):
return 0
@property
def token_freqs(self):
return self._token_freqs
#截断和填充文本
def truncate_pad(line,num_steps,padding_token):
if len(line) > num_steps:
return line[:num_steps]
return line + [padding_token] * (num_steps - len(line))
#为每一个序列添加结束符,并返回索引序列和未经截断的序列长度
def build_array_nmt(lines, vocab, num_steps):
# 将词元序列,转为词元对应的索引序列
lines = [vocab[l] for l in lines]
lines = [l + [vocab['<eos>']] for l in lines]
array = torch.tensor([truncate_pad(l, num_steps, vocab['<pad>']) for l in lines])
valid_len = (array != vocab['<pad>']).type(torch.int32).sum(1)
# array为经过截断与填充的序列
# valid_len为未经过截断与填充的序列的长度。
return array, valid_len
#构造一个Pytorch数据迭代器
def load_array(data_arrays,batch_size,is_train=True):
dataset=data.TensorDataset(*data_arrays)
return data.DataLoader(dataset,batch_size,shuffle=is_train)
#返回翻译数据集的迭代器和词表
def load_data_nmt(batch_size,num_steps,num_examples = 600):
#加载并处理数据
text = preprocess_nmt(read_data_nmt())
#词元化
source,target = tokenize_nmt(text,num_examples)
#构建源语言和目标语言的词表
src_vocab = Vocab(source,min_freq=2,reserved_tokens=['<pad>','<bos>','<eos>'])
tgt_vocab = Vocab(target,min_freq=2,reserved_tokens=['<pad>','<bos>','<eos>'])
#生成词元对应索引构成的语言序列
src_array,src_valid_len = build_array_nmt(source,src_vocab,num_steps)
tgt_array,tgt_valid_len = build_array_nmt(target,tgt_vocab,num_steps)
#生成数据集的迭代器
data_arrays = (src_array,src_valid_len,tgt_array,tgt_valid_len)
data_iter = load_array(data_arrays,batch_size)
return data_iter,src_vocab,tgt_vocab
#2. 模型搭建部分
#编码器
class Seq2SeqEncoder(nn.Module):
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers, dropout=0, **kwargs):
super(Seq2SeqEncoder, self).__init__(**kwargs)
# 嵌入成
self.embedding = nn.Embedding(vocab_size, embed_size)
# 循环曾
self.rnn = nn.GRU(embed_size, num_hiddens, num_layers, dropout=dropout)
def forward(self, X, *args):
# X的形状应该为(batch_size,num_steps,embed_size)
X = self.embedding(X)
# 修改X的形状为(num_steps,batch_sizemembed_size)
# 第一个维度对应于时间步
# permute:将tensor的维度换位。
X = X.permute(1, 0, 2)
# 初始状态为传入,默认为0
output, state = self.rnn(X)
# output的形状:(num_steps,batch_size,num_hiddens)
# state[0]的形状:(num_layers,batch_size,num_hiddens)
return output, state
#解码器
class Seq2SeqDecoder(nn.Module):
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers, dropout=0, **kwargs):
super(Seq2SeqDecoder, self).__init__(**kwargs)
self.embedding = nn.Embedding(vocab_size, embed_size)
self.rnn = nn.GRU(embed_size + num_hiddens, num_hiddens, num_layers, dropout=dropout)
self.dense = nn.Linear(num_hiddens, vocab_size)
def init_state(self, enc_outputs, *args):
# 返回最后一个时间步的隐藏状态(包含多个层的隐藏状态)
return enc_outputs[1]
def forward(self, X, state):
X = self.embedding(X).permute(1, 0, 2)
# 首先只取最后一个时间步,最后一层隐藏状态的值,形状为(1,批量大小,隐藏特征数),需要和输入进行拼接
# 因此使用广播变成(时间步长度,批量大小,隐藏特征数)的形状,每一时间步都是一样的,因此可以看出编码器的输出
# 作用到了解码器每一时间步
context = state[-1].repeat(X.shape[0], 1, 1)
# 进行拼接,因此解码器的输入为embed_size + num_hiddens
X_and_context = torch.cat((X, context), 2)
output, state = self.rnn(X_and_context, state)
# 传入线性层
output = self.dense(output).permute(1, 0, 2)
# output的形状:(batch_size,num_steps,vocab_size)
# state[0]的形状:(num_layers,batch_size,num_hiddens)
return output, state
#编码解码器
class EncoderDecoder(nn.Module):
def __init__(self,encoder,decoder,**kwargs):
super(EncoderDecoder, self).__init__()
self.encoder = encoder
self.decoder = decoder
def forward(self,enc_X,dec_X,*args):
enc_outputs = self.encoder(enc_X,*args)
dec_state = self.decoder.init_state(enc_outputs,*args)
return self.decoder(dec_X,dec_state)
#3.自定义损失函数
#给序列添加mask
def sequence_mask(X,valid_len,value = 0):
#词表大小序列长度
maxlen = X.size(1)
#构建遮罩
mask = torch.arange((maxlen),dtype = torch.float32,device=X.device)[None:] < valid_len[:,None]
X[~mask] = value
return X
#带mask的交叉熵损失函数
class MaskedSoftmaxCELoss(nn.CrossEntropyLoss):
# pred的形状:(batch_size,num_steps,vocab_size)
# label的形状:(batch_size,num_steps)
# valid_len的形状:(batch_size,)
def forward(self,pred,label,valid_len):
weights = torch.ones_like(label)
weights = sequence_mask(weights,valid_len)
self.reduction = 'none'
#计算真实损失
unweighted_loss = super(MaskedSoftmaxCELoss,self).forward(pred.permute(0,2,1),label)
#使用mask进行处理
weighted_loss = (unweighted_loss * weights).mean(dim = 1)
return weighted_loss
#4.模型训练部分
#使用GPU
def try_gpu(i=0):
if torch.cuda.device_count()>=i+1:
return torch.device(f'cuda:{i}')
return torch.device('cpu')
#梯度截断
def grad_clipping(net,theta):
if isinstance(net,nn.Module):
params = [p for p in net.parameters() if p.requires_grad]
else:
params = net.params
norm = torch.sqrt(sum(torch.sum((p.grad ** 2)) for p in params))
if norm > theta:
for param in params:
param.grad[:] *= theta / norm
#模型训练
def train_seq2seq(net,data_iter,lr,num_epochs,tgt_vocab,device):
#初始化模型参数
def xavier_init_weights(m):
if type(m) == nn.Linear:
nn.init.xavier_uniform_(m.weight)
if type(m) == nn.GRU:
for param in m._flat_weights_names:
if "weight" in param:
nn.init.xavier_uniform_(m._parameters[param])
net.apply(xavier_init_weights)
net.to(device)
#优化器和损失函数
optimizer = torch.optim.Adam(net.parameters(),lr = lr)
loss = MaskedSoftmaxCELoss()
#开启训练模式
net.train()
animator = d2l.Animator(xlabel = 'epoch',ylabel = 'loss',xlim=[10,num_epochs])
for epoch in range(num_epochs):
timer = d2l.Timer()
#训练损失总和,词元数量
metric = d2l.Accumulator(2)
for batch in data_iter:
X,X_valid_len,Y,Y_valid_len = [x.to(device) for x in batch]
#将开始符号添加到目标语言序列上
bos = torch.tensor([tgt_vocab['<bos>']] * Y.shape[0],device = device).reshape(-1,1)
dec_input = torch.cat([bos,Y[:,:-1]],1)
#计算真实值
Y_hat,_ = net(X,dec_input,X_valid_len)
#计算损失
l = loss(Y_hat,Y,Y_valid_len)
l.sum().backward()
grad_clipping(net,1)
num_tokens = Y_valid_len.sum()
optimizer.step()
with torch.no_grad():
metric.add(l.sum(),num_tokens)
if (epoch + 1) % 10 == 0:
animator.add(epoch + 1,(metric[0]/metric[1],))
print(f'loss {metric[0] / metric[1]:.3f},{metric[1]/timer.stop():.1f} tokens.sec on {str(device)}')
#5、定义参数,对模型进行训练
#词嵌入大小,隐藏层特征数,rnn层数,丢弃值
embed_size,num_hiddens,num_layers,dropout = 32,32,2,0.1
#批量大小,时间步
batch_size,num_steps = 64,10
#学习率,训练轮次,训练使用的设备
lr,num_epochs,device = 0.005,300,try_gpu()
#获取数据集和词表
train_iter,src_vocab,tgt_vocab = load_data_nmt(batch_size,num_steps)
#实例化编码器-解码器模型
encoder = Seq2SeqEncoder(len(src_vocab),embed_size,num_hiddens,num_layers,dropout)
decoder = Seq2SeqDecoder(len(tgt_vocab),embed_size,num_hiddens,num_layers,dropout)
net = EncoderDecoder(encoder,decoder)
#进行训练
train_seq2seq(net,train_iter,lr,num_epochs,tgt_vocab,device)
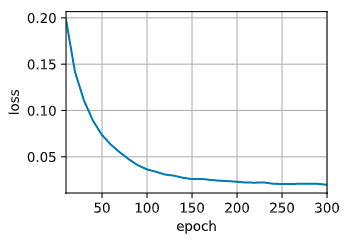
loss 0.020,11098.6 tokens.sec on cuda:0
#6、预测部分
def predict_seq2seq(net,src_sentence,src_vocab,tgt_vocab,num_steps,device):
#设置为评估模式
net.eval()
#对句子进行预处理 然后在后面添加<eos>,预测到eos时结束,
src_tokens = src_vocab[src_sentence.lower().split(' ')] + [src_vocab['<eos>']]
#句子的长度
enc_valid_len = torch.tensor([len(src_tokens)],device = device)
#对句子进行截断和填充处理
src_tokens = truncate_pad(src_tokens,num_steps,src_vocab['<pad>'])
#添加批量轴
#添加一个指定维度,因为训练的时候有三个维度(批量,时间步,词向量),因此推理时也需要添加批量那一个维度
enc_X = torch.unsqueeze(torch.tensor(src_tokens,dtype = torch.long,device = device),dim = 0)
#获得编码器输出
enc_outputs = net.encoder(enc_X,enc_valid_len)
#获得解码器初始状态
dec_state = net.decoder.init_state(enc_outputs,enc_valid_len)
#添加批量轴
#解码器的输入也是三个维度,因此添加一个批量维度,加码器的第一个输入为序列开始词元<bos>
dec_X = torch.unsqueeze(torch.tensor([tgt_vocab['<bos>']],dtype = torch.long,device = device),dim = 0)
#保存输出内容
output_seq = []
for _ in range(num_steps):
#获得解码器输出
Y,dec_state = net.decoder(dec_X,dec_state)
#使用具有预测可能性最高的词元,作为解码器在下一时间步的输入
dec_X = Y.argmax(dim = 2)
#去除第0维所在的维度,并转为python数据类型
pred = dec_X.squeeze(dim = 0).type(torch.int32).item()
if pred == tgt_vocab['<eos>']:
break
output_seq.append(pred)
#通过构建的词表,将索引转为单词
return ' '.join(tgt_vocab.to_tokens(output_seq))
#评估预测
def bleu(preq_seq,label_seq,k):
#对预测序列和标签序列进行分词
pred_tokens,label_tokens = preq_seq.split(' '),label_seq.split(' ')
#计算预测序列和标签序列的长度
len_pred,len_label = len(pred_tokens),len(label_tokens)
#惩罚果断的预测
score = math.exp(min(0,1 - len_label / len_pred))
for n in range(1,k + 1):
#定义一个统计值和字典
num_matches,label_subs = 0,collections.defaultdict(int)
#统计n元语法所有对应的词及其数量
for i in range(len_label - n + 1):
label_subs[''.join(label_tokens[i : i + n])] +=1
#在预测序列中找是否与标签序列中对应的n元语法
for i in range(len_pred - n + 1):
if label_subs[''.join(pred_tokens[i : i + n])] > 0:
num_matches +=1
label_subs[''.join(pred_tokens[i : i + n])] -= 1
score *= math.pow(num_matches / (len_pred - n + 1),math.pow(0.5,n))
return score
engs = ['go .', "i lost .", 'he\'s calm .', 'i\'m home .']
fras = ['va !', 'j\'ai perdu .', 'il est calme .', 'je suis chez moi .']
for eng, fra in zip(engs, fras):
translation = predict_seq2seq(
net, eng, src_vocab, tgt_vocab, num_steps, device)
print(f'{eng} => {translation}, bleu {bleu(translation, fra, k=2):.3f}')
go . => va au feu !, bleu 0.000
i lost . => j'ai perdu ., bleu 1.000
he's calm . => il est mouillé <unk> de question ., bleu 0.418
i'm home . => je suis libre !, bleu 0.418

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 27
27 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)