
文件乱码怎么办?
Linux和windows平台下乱码处理和使用总结
文件乱码怎么办?
这里写目录标题
个人建议
修改时尽量修改自定义选项例如.bash_profile,.vimrc文档,这样不会忘记自己修改了哪里,有时候某处的修改导致后面出现了新的问题,但却无法定位。
文件内容乱码
以.txt文档为例,直接打开是乱码,可通过下面方法查看情况,在vim软件中输入
#查看当前文件编码
:set fileencoding
fileencoding=gb18030
在.vimrc文档下加入
set fileencodings=utf-8,gb2312,gb18030,gbk,ucs-bom,cp936,latin1
set enc=utf8
set fencs=utf8,gbk,gb2312,gb18030
此时文档会正确显示。
解压文件夹文件名乱码
对于windows平台,编码格式是GBK,对应的汉字是两个字节长度。对于Linux平台,编码格式是UTF-8,对应的汉字是3个字节。
解压文件夹的命令
unzip -O CP936 testCode.zip
对应的解释
unzip --h
-O CHARSET specify a character encoding for DOS, Windows and OS/2 archives
命令行乱码怎么办?
执行以下命令
vim ~/.bash_profile
#添加下面的命令
export LANGUAGE=en_US.UTF-8
export LANG=en_US.UTF-8
export LC_ALL=en_US.UTF-8
#使得生效,有的让重启是一个意思
source ~/.bash_profile
使用命令查看当前编码
locale:local encode,即本地编码的意思。这个命令不带任何参数就是显示当前系统的字符集编码。也可以设置环境变量,全体参数man locale
在Linux中通过locale来设置程序运行的不同语言环境,locale由ANSI C提供支持。locale的命名规则为<语言>_<地区>.<字符集编码>,如zh_CN.UTF-8,zh代表中 文,CN代表大陆地区,UTF-8表示字符集。
locale
#LANG LC_*的默认值,是最低级别的设置,如果LC_*没有设置,则使用该值。类似于 LC_ALL。
LANG=en_US.UTF-8
LANGUAGE=en_US.UTF-8
#LC_CTYPE用于字符分类和字符串处理,控制所有字符的处理方式,包括字符编码,字符是单字节还是多字节,如何打印等。是最重要的一个环境变量。
LC_CTYPE="en_US.UTF-8"
# LC_NUMERIC 非货币的数字显示格式
LC_NUMERIC="en_US.UTF-8"
#LC_TIME 时间和日期格式
LC_TIME="en_US.UTF-8"
# LC_COLLATE定义该环境的排序和比较规则
LC_COLLATE="en_US.UTF-8"
#LC_MONETARY货币格式
LC_MONETARY="en_US.UTF-8"
#LC_MESSAGES提示信息的语言。另外还有一个LANGUAGE参数,它与LC_MESSAGES相似,但如果该参数一旦设置,则LC_MESSAGES参数就会失效。LANGUAGE参数可同时设置多种语言信息,如LANGUANE="zh_CN.GB18030:zh_CN.GB2312:zh_CN"。
LC_MESSAGES="en_US.UTF-8"
LC_PAPER="en_US.UTF-8"
LC_NAME="en_US.UTF-8"
LC_ADDRESS="en_US.UTF-8"
LC_TELEPHONE="en_US.UTF-8"
LC_MEASUREMENT="en_US.UTF-8"
LC_IDENTIFICATION="en_US.UTF-8"
#LC_ALL它是一个宏,如果该值设置了,则该值会覆盖所有LC_*的设置值。注意,LANG的值不受该宏影响。
LC_ALL=en_US.UTF-8
locale -a你可以看看目前系统里支持的字符集,如果不支持,还要安装奥。当前.bash_profile的设置是
#中文显示
if [ 1 -eq 1 ];then
LANG=zh_CN.GB18030
LANGUAGE=zh_CN.GB18030:zh_CN.GB2312:zh_CN
export LANG LANGUAGE
fi
#英文显示
if [ 0 -eq 1 ];then
export LANGUAGE=en_US.UTF-8
export LANG=en_US.UTF-8
export LC_ALL=en_US.UTF-8
fi
字符编码基础知识
最初的计算机字符编码是通过ASCII来编码的,是现今最通用的单字节编码系统,使用7位二进制数来表示所有的字母、数字、标点符号及一些特殊控制字符,作为美国编码标准来使用。
ISO-8859-1编码是单字节编码,向下兼容ASCII,是许多欧洲国家使用的编码标准。其编码范围是0x00-0xFF,0x00-0x7F之间完全和ASCII一致,0x80-0x9F之间是控制字符,0xA0-0xFF之间是文字符号。
Unicode,学名是Universal Multiple-Octet Coded Character Set(简称UCF),与ISO-8859-1标准兼容。由国际组织标准制定,作为一种国际语言编码标准,支持超过十万个字符,涵盖世界数十种文字系统,是一种通用字符编码标准。很多技术,如Java编程语言、现代操作系统都采用了Unicode编码。
UTF-8/UTF-16等则是对Unicode进行了编码,是其一种实现方式。UTF-8(8-bit Unicode Transformation Format),是一种变长的编码方式,它以8位为码元,用1-6个码元对Unicode进行编码,对英文字符使用单字节编码,对中文编码用到三个字节来编码。UTF-16(16-bit Unicode Transformation Format)是用16位为码元,用1个或2个码元对Unicode进行编码。
utf-16将字符集划分为基本多文中平面和辅助平面,基本多文中平面中的字符与Unicode是一致的,不需要转换;处在辅助平面中的码元(如一些拼音文字或者中日韩表意文字的扩充),需要2个码元进行编码。
GB2312是国家制定的汉字编码标准,使用双子节进行编码,共收入6763个汉字和682个非汉字图形字符。GBK即对国标编码的扩展,在GB2312的基础上进行扩展形成的,使用双子节编码方式,共收入21003个汉字,从而大大满足了汉字使用的需要。
总结:unicode是国际通用编码标准,可以表示全世界的字符,但其字符集也是最复杂、占用空间最大的。开发者可以根据需要进行选择编码方式。
参考文献
- 原文:https://blog.csdn.net/shijing_0214/article/details/50908144
关于文件编码的一些命令
查看文件的编码:编码为GB2512
#检查文件的编码
enca test1.txt
enca -L zh_CN fileName
Simplified Chinese National Standard; GB2312
CRLF line terminators
转换文件编码
enca -L 当前语言 -x 目标编码 文件名
enca -L zh_CN -x utf-8 * //例如要把当前目录下的所有文件都转成utf-8
enca -L zh_CN -x UTF-8 file //将文件编码转换为"UTF-8"编码
enca -L zh_CN -x UTF-8 < file1 > file2 //如果不想覆盖原文件可以这样
enca -L zh_CN -x utf8 <quad.c >quadTest.c
乱码-ubuntu下文档的文件名到windows下变为___下划线
现象:Windows下编辑过的中文文档,Ubuntu下会显示乱码。
原因:两个操作系统使用的编码不同。Ubuntu下使用的编码是utf-8,而Windows使用的是gb18030。
查看当前系统使用的字符编码
locale
LANG=zh_CN.UTF-8
LANGUAGE=zh_CN:en_US:en
LC_CTYPE="zh_CN.UTF-8"
LC_NUMERIC=zh_CN.UTF-8
LC_TIME=zh_CN.UTF-8
LC_COLLATE="zh_CN.UTF-8"
LC_MONETARY=zh_CN.UTF-8
LC_MESSAGES="zh_CN.UTF-8"
LC_PAPER=zh_CN.UTF-8
LC_NAME=zh_CN.UTF-8
LC_ADDRESS=zh_CN.UTF-8
LC_TELEPHONE=zh_CN.UTF-8
LC_MEASUREMENT=zh_CN.UTF-8
LC_IDENTIFICATION=zh_CN.UTF-8
LC_ALL=
查看当前系统支持的字符集
locale -a
C
C.UTF-8
en_AG
en_AG.utf8
en_AU.utf8
en_BW.utf8
en_CA.utf8
en_DK.utf8
en_GB.utf8
en_HK.utf8
en_IE.utf8
en_IL
en_IL.utf8
en_IN
en_IN.utf8
en_NG
en_NG.utf8
en_NZ.utf8
en_PH.utf8
en_SG.utf8
en_US.utf8
en_ZA.utf8
en_ZM
en_ZM.utf8
en_ZW.utf8
POSIX
zh_CN.utf8
zh_SG.utf8
执行locale-gen zh_CN.UTF-8拉取中文编码
sudo locale-gen zh_CN.*
Generating locales (this might take a while)...
zh_CN.GB18030... done
zh_CN.GB2312... done
zh_CN.GBK... done
zh_CN.UTF-8... done
Generation complete.
查看现在系统支持的字符集,发现多了zh_*等中文字符集
locale -a
C
C.UTF-8
en_AG
en_AG.utf8
en_AU.utf8
en_BW.utf8
en_CA.utf8
en_DK.utf8
en_GB.utf8
en_HK.utf8
en_IE.utf8
en_IL
en_IL.utf8
en_IN
en_IN.utf8
en_NG
en_NG.utf8
en_NZ.utf8
en_PH.utf8
en_SG.utf8
en_US.utf8
en_ZA.utf8
en_ZM
en_ZM.utf8
en_ZW.utf8
POSIX
zh_CN
zh_CN.gb18030
zh_CN.gb2312
zh_CN.gbk
zh_CN.utf8
zh_SG.utf8
乱码-windows下文档移到linux下文件显示乱码
上面的方法可以实现在gedit软件下,正确显示,但是在vim文档下显示如下
°üº¬µÄÐéÄâ»úID£¬¼°Æä·Ö²¼·½Ê½
但在gedit软件中打开实际上是
包含的虚拟机ID,及其分布方式
查看文件的编码方式
file debug_tran.cpp
debug_tran.cpp: C++ source, ISO-8859 text, with CRLF line terminators
由于我的vim 配置里面显示了文件的格式,我的vim显示如下
dos latin1 cpp
经过查询可知:Latin1是ISO-8859-1的别名,有些环境下写作Latin-1。此字符集支持部分于欧洲使用的语言,所以中文显示乱码。
可以采用下面的命令转换
iconv -f gbk -t utf8 debug_tran.cpp.gbk > debug_tran.cpp.utf
查找新产生的文件
file debug_tran.cpp.utf
debug_tran.cpp.utf: C++ source, UTF-8 Unicode text, with CRLF line terminators
使用下面的语句查看具体选项
iconv --help
在windows中打开linux文档建议使用notepad++文件打开,在里面可以修改不同编码。
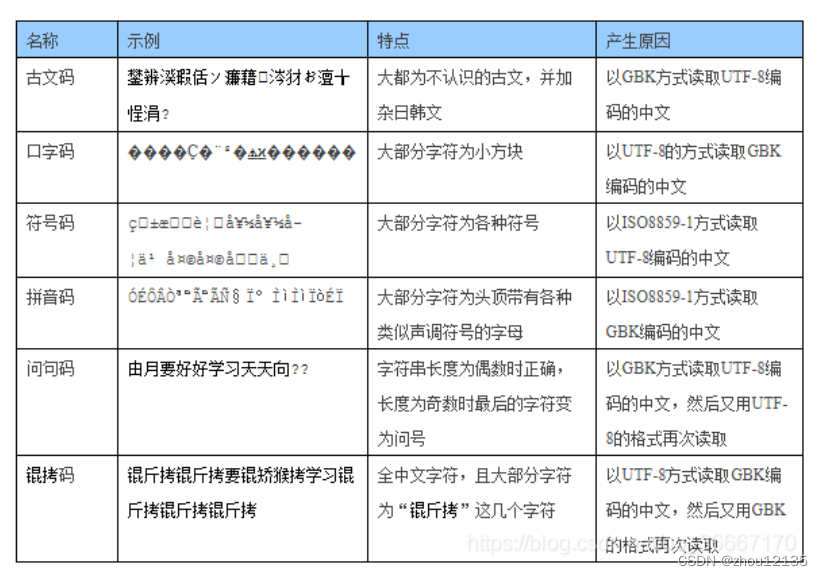
乱码分类表
Python报错:UnicodeDecodeError | 解决pycharm控制台乱码 | 修改pycharm编码方式 | 乱码分类图

更多推荐
 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)