
机器学习入门:第三章 逻辑(Logistic)回归 计算公式推导(3)
很多问题都属于分类的问题,邮件(垃圾邮件/非垃圾邮件),肿瘤(良性/恶性)。二分类问题,可以用如下形式来定义它:y∈(0,1)y\in{(0,1)}y∈(0,1),其中x0属于负例,1属于正例。现在来构造一种状态,一个向量来代表肿瘤(良性/恶性)和肿瘤大小的关系。其中表示结果,这样良性结果和肿瘤大小关系就为:构造函数:f(x,θ)=θTxf(x,\theta) = \theta ^Txf(x,θ)
很多问题都属于分类的问题,邮件(垃圾邮件/非垃圾邮件),肿瘤(良性/恶性)。二分类问题,可以用如下形式来定义它:
y
∈
(
0
,
1
)
y\in{(0,1)}
y∈(0,1),其中x0属于负例,1属于正例。
现在来构造一种状态,一个向量来代表肿瘤(良性/恶性)和肿瘤大小的关系。
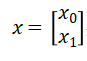
其中表示结果,这样良性结果和肿瘤大小关系就为:
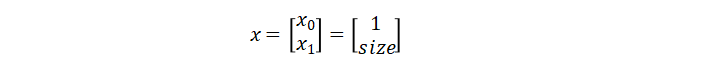
构造函数:
f ( x , θ ) = θ T x f(x,\theta) = \theta ^Tx f(x,θ)=θTx
对于两个变量来说,可以表示为:
θ T x = θ 0 T x 0 + θ 1 T x 1 + θ 2 T x 2 \theta ^Tx = \theta_0 ^Tx_0 +\theta_1 ^Tx_1+\theta_2 ^Tx_2 θTx=θ0Tx0+θ1Tx1+θ2Tx2
对于正例来说为1,表示为:
θ T x = θ 0 + θ 1 T x 1 + θ 2 T x 2 \theta ^Tx = \theta_0 +\theta_1 ^Tx_1+\theta_2 ^Tx_2 θTx=θ0+θ1Tx1+θ2Tx2
这也是工程中经常碰到的问题,即一些特征影响到分类的结果,而这种分类只有两类,即正例和负例。从分类的结果来看,就是0-1分布,如何利用0-1分布的思想来考虑这个问题呢?即把所有的特征转换为概率,归一化到某一个范围里,寻找归一化函数。
寻找一个函数
h
θ
(
x
)
=
g
(
θ
T
x
)
h_\theta(x) = g(\theta^T x)
hθ(x)=g(θTx),使得它的取值在0到1之间,
如果
h
θ
(
x
)
≥
0.5
h_\theta(x)\ge 0.5
hθ(x)≥0.5,则预测y=1,既y属于正例;
如果
h
θ
(
x
)
<
0.5
h_\theta(x)\lt 0.5
hθ(x)<0.5,则预测y=0,既y属于负例;
在Logistic回归中取得函数为Sigmoid 函数
h θ ( x ) = g ( θ T x ) h_\theta(x)=g(\theta^Tx) hθ(x)=g(θTx)
这里称为Sigmoid function或者Logistic function, 具体表达式为:
g ( x ) = 1 1 + e − z g(x) = \frac{1}{1+e^{-z}} g(x)=1+e−z1
Sigmoid 函数在有个很漂亮的“S"形,如下图所示:

综合上述两式,我们得到逻辑回归模型的数学表达式:
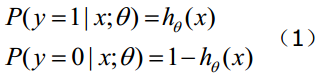
其中θ是参数。 Hypothesis输出的直观解释: h θ ( x ) h_\theta(x) hθ(x)对于给定的输入x,y=1时估计的概率,容易理解的话,套用刚才正品率的检查,就是p。
函数 h θ ( x ) h_\theta(x) hθ(x)的值有特殊的含义,它表示结果取1的概率,因此对于输入x分类结果为类别1和类别0的概率分别为:
构造损失函数J
Cost函数和J函数如下,它们是基于最大似然估计推导得到的。

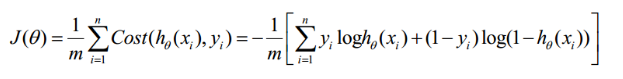
下面详细说明推导的过程:
(1)式综合起来可以写成:
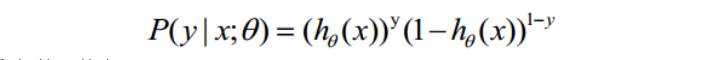
取似然函数为:
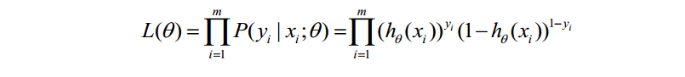
对数似然函数为:
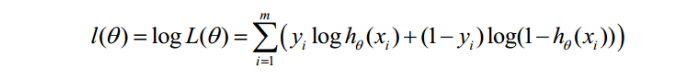
最大似然估计就是求使lθ)取最大值时的θ,其实这里可以使用梯度上升法求解,求得的θ就是要求的最佳参数。但是,在Andrew Ng的课程中将J(θ)取为下式,即:
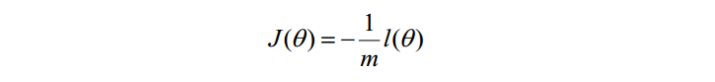
因为乘了一个负的系数-1/m,所以取J(θ)最小值时的θ为要求的最佳参数。
梯度下降法求的最小值
按照梯度下降的方法,求解θ更新过程:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-h2fV6ADh-1649904028340)(/images/kuxue/machine_learning/pp5.png)]](https://img-blog.csdnimg.cn/e05d8c30a8b74589b787d5ca39f79ef7.png)
其中α为学习参数,求解θ的过程,就转换到了求解
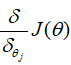
的过程,

θ更新过程可以写成:
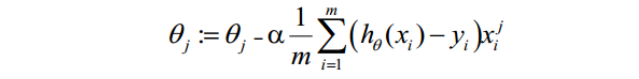
这个公式就是最后的计算公式,如果对上述公式的推导过程看起来较为费劲,先记住这个计算结果,接着在编程的过程中,需要用到。
更多推荐

 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)