基于深度强化学习的完全AI自动的俄罗斯方块游戏
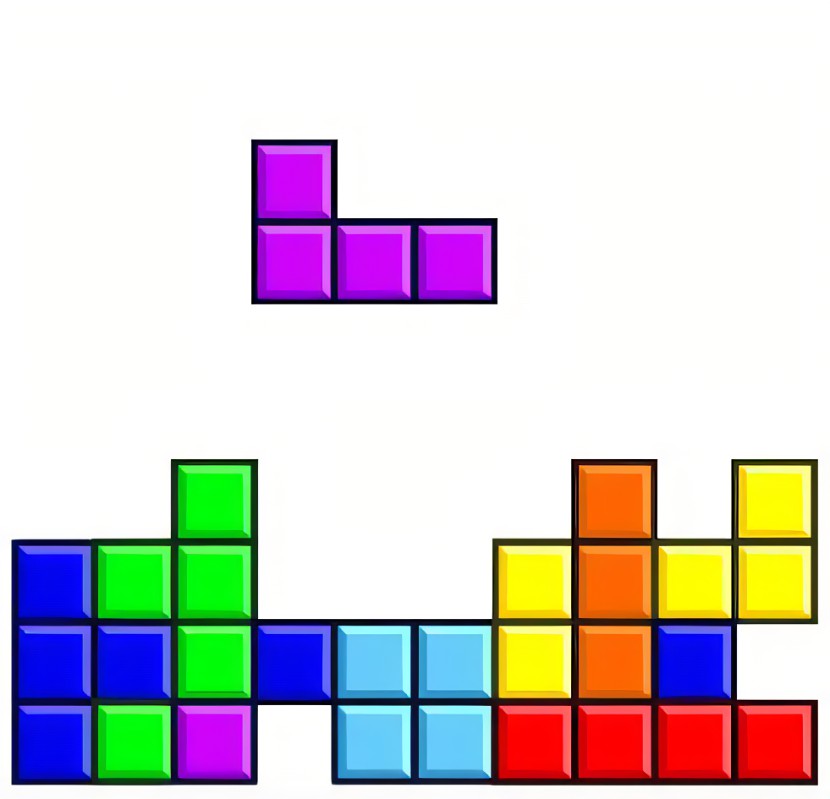
最近在接触深度强化学习的概念,特地也实现了一个基于深度强化学习的俄罗斯方块游戏,这个游戏是完全基于AI自动的,自动学习一个最佳策略,来代替我们完成每一步的选择,还是蛮有意思的。先上个效果图吧,如下所示:自从20世纪80年代以来,游戏AI产生巨大的变化,诞生了“自主思考型AI”,游戏中的NPC会在游戏中观察及分析,根据玩家的行为做出针对性的应对,不再只是按照一个目标一直走下去,而是更加灵活多样。自主
最近在接触深度强化学习的概念,特地也实现了一个基于深度强化学习的俄罗斯方块游戏,这个游戏是完全基于AI自动的,自动学习一个最佳策略,来代替我们完成每一步的选择,还是蛮有意思的。先上个效果图吧,如下所示:

自从20世纪80年代以来,游戏AI产生巨大的变化,诞生了“自主思考型AI”,游戏中的NPC会在游戏中观察及分析,根据玩家的行为做出针对性的应对,不再只是按照一个目标一直走下去,而是更加灵活多样。
自主思考性的AI是基于有限状态机与行为树,也就是多个if-else的组合。有限状态机是以电脑AI的当前状态为主体,通过编写不同的状态之间的转换条件来控制电脑AI,不同的状态下拥有不同的目标、策略与行动。
目前来看的话,强化学习,尤其是深度强化学习是现在游戏的一个火热发展方向,比如围棋里面的阿尔法狗,已经是在围棋界乱杀了,逼得很多围棋手都来学习机器人的围棋策略。
1. 什么是DQN?
DQN(Deep Q-Learning)可谓是深度强化学习(Deep Reinforcement Learning,DRL)的开山之作,是将深度学习与强化学习结合起来从而实现从感知(Perception)到动作( Action )的端对端(End-to-end)学习的一种全新的算法。
2. DQN是如何运算的?
(1)通过Q-Learning使用reward来构造标签
(2)通过experience replay(经验池)的方法来解决相关性及非静态分布问题
(3)使用一个CNN(MainNet)产生当前Q值,使用另外一个CNN(Target)产生Target Q值
3、DQN的网络模型?
4. 以下是本项目的一些配置环境
OS: Windows10
Python: Python3.8(have installed necessary dependencies)
PyQT:PyQt5是Qt v5的Python版本,功能强大复杂,提供QT Designer设计UI(版本无限制)
5. 核心代码展示
5.1 获取下一步的行动
'''获得下一步的行动'''
def getNextAction(self):
if self.inner_board.current_tetris == tetrisShape().shape_empty:
return None
action = None
# 当前可操作的俄罗斯方块的direction范围
if self.inner_board.current_tetris.shape in [tetrisShape().shape_O]:
current_direction_range = [0]
elif self.inner_board.current_tetris.shape in [tetrisShape().shape_I, tetrisShape().shape_Z, tetrisShape().shape_S]:
current_direction_range = [0, 1]
else:
current_direction_range = [0, 1, 2, 3]
# 下一个可操作的俄罗斯方块的direction范围
if self.inner_board.next_tetris.shape in [tetrisShape().shape_O]:
next_direction_range = [0]
elif self.inner_board.next_tetris.shape in [tetrisShape().shape_I, tetrisShape().shape_Z, tetrisShape().shape_S]:
next_direction_range = [0, 1]
else:
next_direction_range = [0, 1, 2, 3]
# 简单的AI算法
for d_now in current_direction_range:
x_now_min, x_now_max, _, _ = self.inner_board.current_tetris.getRelativeBoundary(d_now)
for x_now in range(-x_now_min, self.inner_board.width - x_now_max):
board = self.getFinalBoardData(d_now, x_now)
for d_next in next_direction_range:
x_next_min, x_next_max, _, _ = self.inner_board.next_tetris.getRelativeBoundary(d_next)
distances = self.getDropDistances(board, d_next, range(-x_next_min, self.inner_board.width-x_next_max))
for x_next in range(-x_next_min, self.inner_board.width-x_next_max):
score = self.calcScore(copy.deepcopy(board), d_next, x_next, distances)
if not action or action[2] < score:
action = [d_now, x_now, score]
return action5.2 计算某一方案的得分
def calcScore(self, board, d_next, x_next, distances):
# 下个俄罗斯方块以某种方式模拟到达底部
board = self.imitateDropDown(board, self.inner_board.next_tetris, d_next, x_next, distances[x_next])
width, height = self.inner_board.width, self.inner_board.height
# 下一个俄罗斯方块以某方案行动到达底部后的得分(可消除的行数)
removed_lines = 0
# 空位统计
hole_statistic_0 = [0] * width
hole_statistic_1 = [0] * width
# 方块数量
num_blocks = 0
# 空位数量
num_holes = 0
# 每个x位置堆积俄罗斯方块的最高点
roof_y = [0] * width
for y in range(height-1, -1, -1):
# 是否有空位
has_hole = False
# 是否有方块
has_block = False
for x in range(width):
if board[x + y * width] == tetrisShape().shape_empty:
has_hole = True
hole_statistic_0[x] += 1
else:
has_block = True
roof_y[x] = height - y
if hole_statistic_0[x] > 0:
hole_statistic_1[x] += hole_statistic_0[x]
hole_statistic_0[x] = 0
if hole_statistic_1[x] > 0:
num_blocks += 1
if not has_block:
break
if not has_hole and has_block:
removed_lines += 1
# 数据^0.7之和
num_holes = sum([i ** .7 for i in hole_statistic_1])
# 最高点
max_height = max(roof_y) - removed_lines
# roof_y做差分运算
roof_dy = [roof_y[i]-roof_y[i+1] for i in range(len(roof_y)-1)]
# 计算标准差E(x^2) - E(x)^2
if len(roof_y) <= 0:
roof_y_std = 0
else:
roof_y_std = math.sqrt(sum([y**2 for y in roof_y]) / len(roof_y) - (sum(roof_y) / len(roof_y)) ** 2)
if len(roof_dy) <= 0:
roof_dy_std = 0
else:
roof_dy_std = math.sqrt(sum([dy**2 for dy in roof_dy]) / len(roof_dy) - (sum(roof_dy) / len(roof_dy)) ** 2)
# roof_dy绝对值之和
abs_dy = sum([abs(dy) for dy in roof_dy])
# 最大值与最小值之差
max_dy = max(roof_y) - min(roof_y)
# 计算得分
score = removed_lines * 1.8 - num_holes * 1.0 - num_blocks * 0.5 - max_height ** 1.5 * 0.02 - roof_y_std * 1e-5 - roof_dy_std * 0.01 - abs_dy * 0.2 - max_dy * 0.3
return score至于后面如果有心得了会进一步补充的!

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)