【Flink】Table API 和 SQL
目录Table API 和 SQL快速上手需要引入的依赖一个简单的事例基本API程序架构创建表环境创建表表的查询输出表表和流的转换流数据的表Table API 和 SQL直到Flink1.12版本才基本做到了功能上的完善,现在仍在不停地调整和更新中,所以这部分内容重点理解含义。快速上手需要引入的依赖planner-blinkstreaming-scala一个简单的事例基本API程序架构创建表环境创
目录
Table API 和 SQL
直到Flink1.12版本才基本做到了功能上的完善,现在仍在不停地调整和更新中,所以这部分内容重点理解含义。
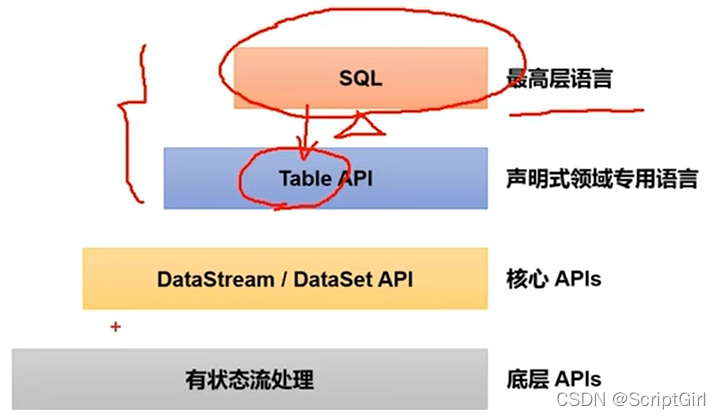
快速上手
需要引入的依赖
planner-blink
streaming-scala
一个简单的事例
env:流执行环境
eventStream:数据流
// 创建表执行环境
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 将DataStream转换成Table
Table eventTable = tableEnv.fromDataStream(eventStream);
// 直接写SQL进行转换
Table resultTable1 = tableEnv.sqlQuery("select use, url, `timestamp` from "+eventTable);
// 基于TABLE直接转换
Table resultTable2 = eventTable.select($("user"), $("url")).where($("user").isEqual("Alice"));
// 转回DataStream
tableEnv.toDataStream(resultTable1).print("result");
tableEnv.toDataStream(resultTable2).print("result");
// 执行
env.execute();
基本API
程序架构
env:流执行环境
eventStream:数据流
// 创建表执行环境
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 创建输入表
tableEnv.executeSql("create temporary table inputTable ... with('connector'=...)");
// 注册输出表
tableEnv.executeSql("create temporary table outputTable ... with('connector'=...)");
// 直接写SQL进行转换,得到一个新表
Table table1 = tableEnv.sqlQuery("select ... from inputTable ...");
// 使用Table API对表进行查询转换,得到一个新的表
Table table2 = tableEnv.from("inputTable").select(...);
// 将得到的结果写到输出表
Table tableResult = table1.executeInsert("outputTable");
创建表环境
(1)注册Catlog和表
(2)执行SQL查询
(3)注册用户自定义的函数UDF
(4)DataStream和表之间的转换
// 方法1:从原本流环境的基础上获得表环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 方法1延伸: 基于老版本计划器进行 批 处理
ExecutionEnvironment batchEnv = ExecutionEnvironment.getExecutionEnvironment();
BatchTableEnvironment batchTableEnvironment = BatchTableEnvironment.create(batchEnv);
// 方法2:独立创建:定义环境配置来创建表执行环境
EnvironmentSettings settings = EnvironmentSettings.newInstance()
.isStreamingMode()
.useBlinkPlanner()//基于flink版本流处理计划器
.build();
TableEnvironment tableEnv = TableEnvironment.create(settings);
// 方法2延伸:
EnvironmentSettings settings = EnvironmentSettings.newInstance()
.isStreamingMode()
.useOldPlanner() // 基于老版本计划器进行 流 处理
.build();
TableEnvironment tableEnv = TableEnvironment.create(settings);
// 方法2延伸:
EnvironmentSettings settings = EnvironmentSettings.newInstance()
.isBatchMode()
.useBlinkPlanner() // 基于新版本计划器进行 批 处理
.build();
TableEnvironment tableEnv = TableEnvironment.create(settings);
创建表
通过建表语句,with外部数据库,建造的表,是真实存在的表,可以直接执行SQL语句。
而从流转换过来的表,只是一个table对象,要想进一步使用SQL语句,那必须得注册到环境中成为环境中的一个虚拟表才行。
// 从流转换过来的表
Table enventTable = tableEnv.fromDataStream(eventStream);
// 直接使用字符串拼接的方式注册到环境中
Table resultTable = tableEnv.sqlQuery("select user, url, `timestamp` from "+eventTable);
Table resultTable = eventTable.select($("user"), $("url"))
.where($("user").isEqual("Alice"));
// 创建虚拟表
Table tViewTable = tableEnv.createTemporaryView("NewTable", newTable);//将表注册到环境中,其实是创建一个虚拟表
表的查询
Calcite是提供标准SQL查询的底层工具。
// 使用建表语句创建真实的SQL表
String createDDL = "create table clickTable("+
" url string, user_name string)"+
" with 'connector'='filesystem', 'path'='input/clinks.txt', 'format'='csv'";
tableEnv.executeSql(createDDL);
// 把SQL表读取成JAVA的Table对象,便于使用.where等Table API
Table clickTable = tableEnv.from("clickTable");
Table resultTable = clickTable.where($("user_name").isEqual("Bob"))
.select($("user_name"), $("url"));
// 把Table对象注册进当前环境,便于后面直接在SQL中使用result表
tableEnv.createTemporaryView("result", resultTable);
Table resultTable2 = tableEnv.sqlQuery("select url, user_name from result");
Table aggResult = tableEnv.sqlQuery("select user_name, count(url) as cnt from clickTable group by user_name");
输出表
// 创建一张用于输出的表
String createOutputDDL = "create table outTable("+
" url string, user_name string)"+
" with 'connector'='filesystem', 'path'='output.txt', 'format'='csv'";
tableEnv.executeSql(createOutputDDL);
// 把结果写入表中
resultTable.executeInsert("outTable");
表和流的转换
表转换成流:
// 普通的流直接打印输出即可
tableEnv.toDataStream(resultTable1).print("result1");
// 聚合转换
tableEnv.createTemporaryView("clickTable", eventTable);
Table aggTable = tableEnv.sqlQuery("select user, count(url) as cnt from clickTable group by user");
tableEnv.toChangelogStream(aggResult).print("agg");
流转换成表:
// 把pojo类的字段当做表的字段
Table enventTable = tableEnv.fromDataStream(eventStream);
// 指定提取哪些字段作为表的字段
Table enventTable = tableEnv.fromDataStream(eventStream, $("timestamp").as("ts"), $("url"));
原子类型:基础数据类型(Integer、Double、String)和通用数据类型(不可拆分)
// 将流转换成表,动态表只有一个字段,重命名为myLong
Table enventTable = tableEnv.fromDataStream(stream, $("myLong"));
Tuple类型:
// 只要f1字段
Table enventTable = tableEnv.fromDataStream(stream, $("f1"));
// f0和f1字段交换位置
Table enventTable = tableEnv.fromDataStream(stream, $("f1"), $("f0"));
// 将f1和f0重命名
Table enventTable = tableEnv.fromDataStream(stream, $("f1").as("myInt"), $("f0").as("myLong"));
POJO类型:常用
Row类型:长度固定,但无法直接推断出每个字段的类型。
附加RowKind属性,可以表示当前行在更新操作中的类型,这样Row就可以把流转换为表
fromChangelogStream()。
更新日志流中,元素的类型必须是Row。
DataStream<Rom> dataStream = env.fromElements(
Row.ofKind(RowKind.INSERT, "Alice", 12),
Row.ofKind(RowKind.INSERT, "Bob", 5),
Row.ofKind(RowKind.UPDATE_BEFORE, "Alice", 12),
Row.ofKind(RowKind.UPDATE_AFTER, "Alice", 100),
);
// 将更新日志流转换成表
Table table = tableEnv.fromChangelogStream(dataStream);
流处理中的表
动态表和持续查询
关系型数据库 的 更新日志流 changelog stream,结合某一时刻的快照,就可以得到表的变化过程和最终结果了。
高级数据库如Oracle中有物化视图的概念,可以缓存SQL查询的结果,其实就是不停地处理更新日志流的过程。
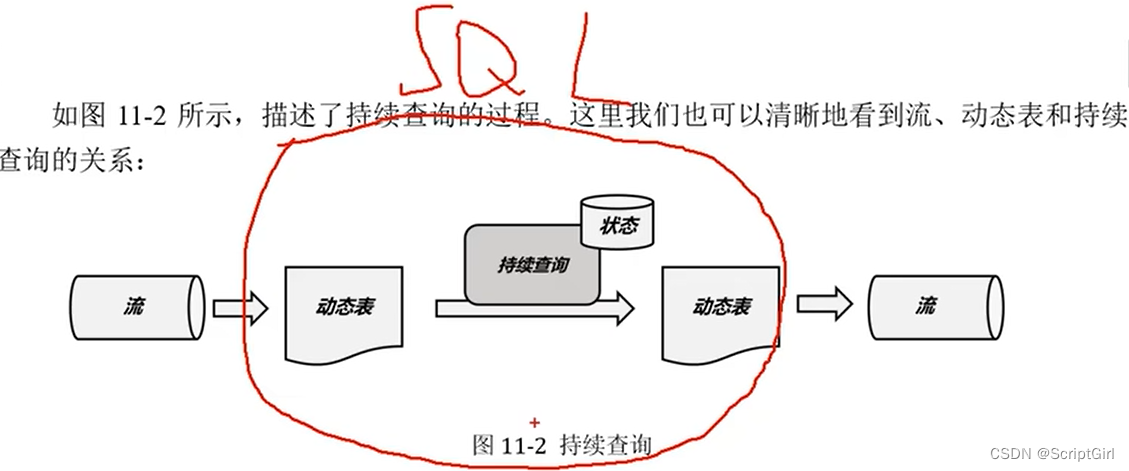
将流转换成动态表
更新查询:toChangelogStream
追加查询:toDataStream
用SQL持续查询
如果状态大小逐渐增长,或更新计算的复杂度越来越高,可能会耗尽内存空间,可能导致查询失败。
将动态表转换成流
仅追加流:仅通过Insert更改来修改的动态表,可以直接转换为append-only流。
撤回流:包含两类消息的流,添加add和撤回retract。增删改对应的操作:
增:add
删:retract
改:先删后增
更新插入流:包含更新插入upsert消息和删除delete消息,前提是要有唯一的key,upsert时,相同key的value发生变化。
时间属性和窗口
多加一列时间属性,时间属性的数据类型:TIMESTAMP
事件时间
处理乱序数据和延迟数据,要设置水位线,基于当前数据本身自带的最大时间戳。
事件时间语义下定义时间属性:
(1)在建表语句的DDL中定义
create table EventTable(
user STRING,
url STRING,
ts TIMESTAMP(3),//精确到秒后3位,也就是毫秒值
WATERMARK for ts as ts - INTERVAL '5' SECOND) // 延迟5秒作为水位线
WITH(...);
若原始时间戳是一个长整型的毫秒值,时间戳应该这样定义:
create table EventTable(
user STRING,
url STRING,
ts BIGINT, // 长整型的类型表示事件属性
ts_ltz AS TO_TIMESTAMP_LTS(ts, 3),//精确到秒后3位,也就是毫秒值
WATERMARK for ts_ltz as ts_ltz - INTERVAL '5' SECOND) // 延迟5秒作为水位线
WITH(...);
create table EventTable(
user STRING,
url STRING,
ts BIGINT, // 长整型的类型表示毫秒值
et AS TO_TIMESTAMP(ts / 1000),
WATERMARK for et as et - INTERVAL '5' SECOND) // 延迟5秒作为水位线
WITH(...);
(2)在流转换成Table的时候定义时间属性
先得到ClickStream
Table clickTable = tableEnv.fromDataStream(clickStream,
$("user"),
$("url"),
$("timestamp").as("ts"),
$("et").rowtime()
);
处理时间
窗口
滚动窗口:每天滚动
滑动窗口:窗口大小是1天,每隔1小时滑动一次
累计窗口:最大窗口长度1天,累积步长1小时,这样的话每天统计,但结果每小时更新累积结果
聚合查询 Aggregation
分两种:
(1)流处理中特有的聚合,就是窗口聚合;
(2)SQL原生的聚合查询。
分组聚合
普通分组聚合:
Table aggTable = tableEnv.sqlQuery("select user_name, count(1) from clickTable");
tableEnv.toChangelogStream(aggTable).print("agg");
可能用到的聚合函数:
sum()
max()
min()
avg()
count()
配置状态保存时间,如果超过一定时间,这个状态没有被使用到,就清除。这样结果可能会不太准确,牺牲结果正确性换资源。
tableConfig.setIdleStateRetention(Duration.ofMinutes(60));
分组窗口的聚合:
Table growWindowTable = tableEnv.sqlQuery(
"select " +
" user_name, count(1) as cnt, TUMBLE_END(et, INTERVAL '10' SECOND) as entT " +
" from clickTable " +
" group by " + // 以什么分组
" user_name, TUMBLE(et, INTERVAL '10' SECOND)" + // 当前用户名、当前窗口
);
tableEnv.toChangelogStream(growWindowTable).print("growWindow");
窗口聚合
滚动窗口聚合:
Table tumbleWindowResultTable = tableEnv.sqlQuery(
"select user_name, count(1) as cnt, window_end as endT " +
" from table(TUMBLE(TABLE clickTable, DESCRIPTOR(et), INTERVAL '10' SECOND))"+
" GROUP BY user_name, window_end, window_start"
);
tableEnv.toChangelogStream(grotumbleWindowResultTable wWindowTable).print("tumbleWindow");
滑动窗口聚合:
Table hopWindowResultTable = tableEnv.sqlQuery(
"select user_name, count(1) as cnt, window_end as endT " +
// 窗口大小是10s,每隔5s输出一次
" from table(HOP(TABLE clickTable, DESCRIPTOR(et), INTERVAL '5' SECOND, INTERVAL '10' SECOND))"+
" GROUP BY user_name, window_end, window_start"
);
tableEnv.toChangelogStream(hopWindowResultTable ).print("hopWindow");
累积窗口聚合:
Table cumulateWindowResultTable = tableEnv.sqlQuery(
"select user_name, count(1) as cnt, window_end as endT " +
// 窗口大小是10s,每隔5秒输出一次累积结果
" from table(CUMULATE(TABLE clickTable, DESCRIPTOR(et), INTERVAL '5' SECOND, INTERVAL '10' SECOND))"+
" GROUP BY user_name, window_end, window_start"
);
tableEnv.toChangelogStream(cumulateWindowResultTable).print("cumulateWindow");
开窗聚合 Over
select
<聚合函数> over ([partition by <字段1> [, <字段2>, ...]]
order by <时间属性字段>
<开窗范围>),...
from ...
开窗范围:从之前某一行到当前行
范围间隔:
开窗范围选择当前行之前1h的数据
range between interval '1' hour preceding and current row
行间隔:
开窗范围选择当前行之前的5行数据,包括当前行
rows between 5 preceding and current row
开窗聚合(over):
当前这次访问以及之前3次访问的时间戳平均值
Table overWindowResultTable = tableEnv.sqlQuery("select user_name, avg(ts) over(" +
" partition by user_name order by et rows between 3 preceding and current row)" +
" as avg_ts" +
" from clickTable");
tableEnv.toChangelogStream(overWindowResultTable ).print("overWindow");
多个聚合函数使用同一个window窗口
Table overWindowResultTable = tableEnv.sqlQuery(
"select user_name, avg(ts) over w , count(url) over w as cnt " +
" from clickTable "
// 单独定义window
" window w as( " +
" partition by user_name "+
" order by et "+
" rows between 3 preceding and current row)"
);
应用实例–Top N
多对多,表聚合,窗口TVF。
普通Top N(对得到的表中的全部数据计算Top N)
不涉及窗口操作,可以通过over聚合,再加一个条件筛选实现。
flink sql 先排序并赋予行号,再获取行号小于等于N的那些行返回。
select ...
from(
select ...,
row_number() over([partition by col1,col2... order by cola,colb...]) as row_num
from ...
)
where row_num <= N [and 其他条件]
求总浏览量Top N的url
tableEnv.sqlQuery(
"select user, cnt, row_num " +
" from( " +
" select *, row_number() over( order by cnt desc ) as row_num " +
" from (" +
" select user, count(url) as cnt from clickTable group by user " +
")" +
") where row_num <= 2"
);
窗口Top N(先开窗口,再统计Top N)
每个小时内,访问次数Top N的用户。一段时间内活跃用户的统计。
String subQuery = "select user, count(url) as cnt, window_start, window_end "+
" from table( TUMBLE( table clickTable, descriptor(et), interval '10' second) )"+
" group by user, window_start, window_end";
tableEnv.sqlQuery(
"select user, cnt, row_num " +
" from( " +
" select *, row_number() over( "+
" partition by window_start, window_end "+//必须这么写
" order by cnt desc ) as row_num " +
" from (" + subQuery ")" +
") where row_num <= 2"
);
联结查询 Join
常规联结查询
仅支持等值作为联结条件。
等值内连接
select *
from table1
inner join table2
on table1.id = table2.id
等值外连接
左外连接
select *
from table1
left join table2
on table1.id = table2.id
右外连接
select *
from table1
right join table2
on table1.id = table2.id
全外连接
select *
from table1
full outer join table2
on table1.id = table2.id
间隔联结查询
两表的联结,不需要join关键字。
联结条件用where定义,用等值表达式描述。
时间间隔限制,联结条件后用and追加一个时间间隔的限制条件。
(1)ltime = rtime
(2)ltime >= rtime and ltime < rtime + interval '10' minute
(3)ltime between rtime - interval '10' second and rtime + interval '5' second
收到订单4小时内要发货:
select *
from table1, table2
where table1.id = table2.id
and table1.order_time between table2.time-interval '4' hour

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 0
0 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)